Datastructure and Algorithm (C++ STL 위주)
1.선형 자료구조: 연속형 vs 연결형

응용 프로그램에서 "데이터를 처리하기에 앞서 먼저 데이터를 어떻게 저장할 것인가 결정". 수행할 작업의 종류와 작업 빈도에 따라 달라진다.응용 프로그램이 제대로 동작해야 함은 물론이고, 지연 시간, 사용 메모리 또는 기타 매개변수 측면에서 최선의 성능을 제공하도록 구현
2.STL 컨테이너 개요 / 종류 / 복사 생성자, 대입 연산자

STL에서 제공하는 컨테이너는 array, bitset을 제외하고 모두 크기를 조절할 수 있고, 원소의 추가나 삭제에 따라 자동으로 크기가 늘어나거나 줄어든다. 경계값을 벗어나는 등의 이유로 메모리 공간을 오염시켜 프로그램을 죽게 만들 뿐 아니라 최악의 경우 보안의 위
3.반복자(iterator)
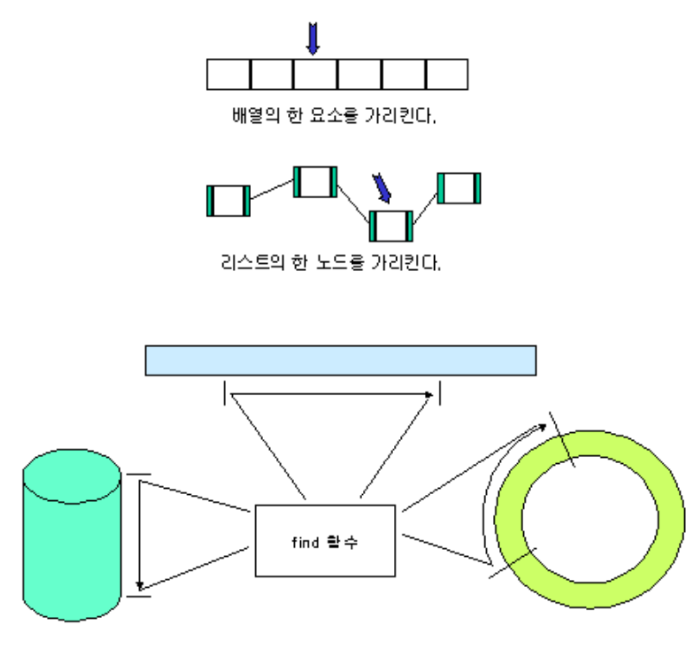
반복자는 포인터와 비슷하지만, STL 컨테이너에 대해 공통의 인터페이스를 제공한다. 반복자를 이용한 연산은 어떤 컨테이너에서 정의된 반복자인지에 따라 결정된다. 벡터(std::vector)와 배열(std::array)에서 사용되는 반복자는 기능 면에서 가장 유연하다.
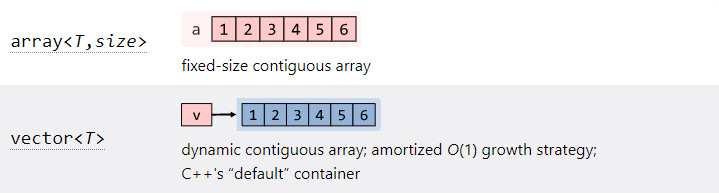
4.std::array (연속형)
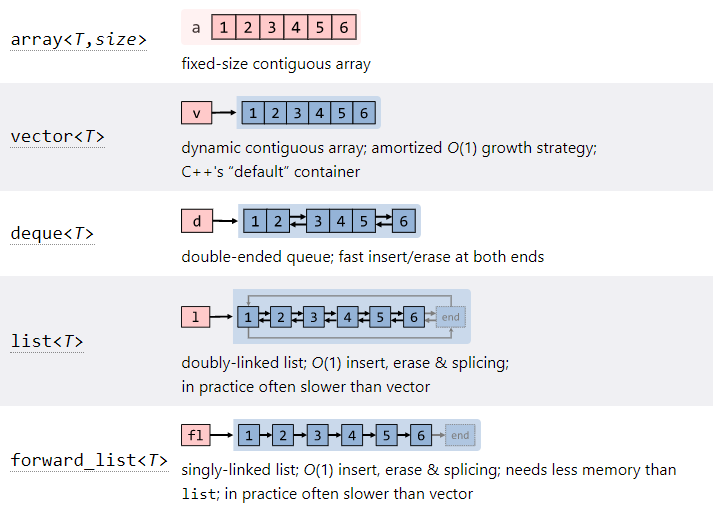
std::array는 메모리를 자동으로 할당하고 해제한다. std::array는 원소의 타입과 배열 크기를 매개변수로 사용하는 클래스 템플릿이다.std::array는 C 스타일 배열과 똑같은 방식으로 배열 원소에 접근할 수 있는 \[] 연산자를 제공한다. \[] 연산자
5.std::vector (연속형)
std::array는 C 스타일 배열의 향상된 버전. 그러나 std::array는 실제 응용 프로그램 개발에서 유용하게 사용할 수 있는 몇몇 기능을 제공하지 않는다는 단점이 있다. std::array의 크기는 컴파일 시간에 결정되는 상수이어야 한다. 따라서 프로그램 실
6.std::forward_list (연결형)

std::array나 std::vector와 같은 연속형 자료구조에서는 데이터 중간에 자료를 추가하거나 삭제하는 작업이 매우 비효율적이다(시간 복잡도: O(n)). 그래서 연결 리스트와 같은 형태의 자료 구조가 등장한다. 기본적인 연결 리스트로 구성하려면 포인터를 하나
7.std::list (연결형)

reference: "전문가를 위한 C++" / 마크 그레고리std::array나 std::vector와 같은 연속형 자료구조에서는 데이터 중간에 자료를 추가하거나 삭제하는 작업이 매우 비효율적이다(시간 복잡도: O(n)). 그래서 연결 리스트와 같은 형태의 자료 구조
8.std::deque (double-ended queue, 양방향 큐)
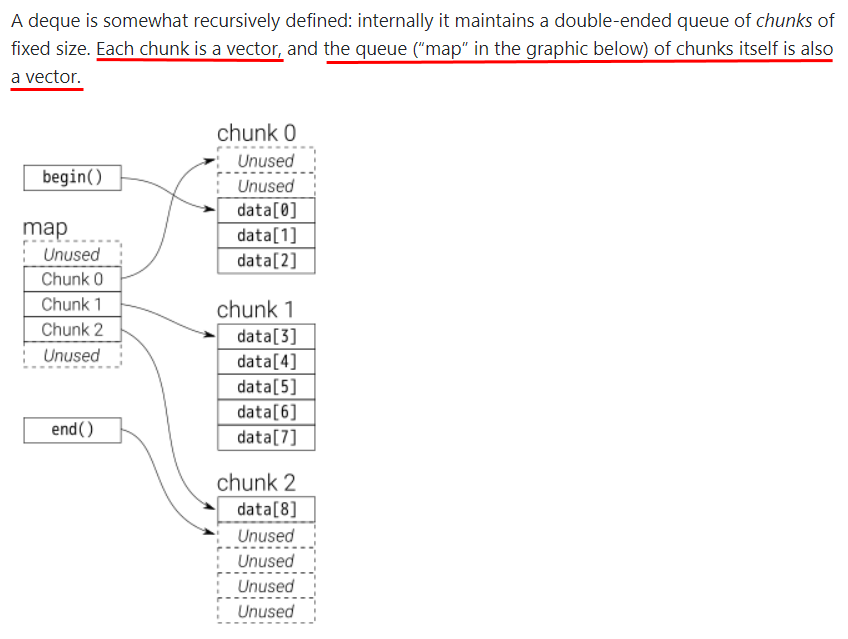
std::deque은 배열 기반과 연결 리스트 기반의 두 가지 방식이 섞여 있는 형태이며, 각각의 장점을 적당히 갖고 있다. 벡터는 가변 길이 배열이고, push_front(), pop_front() 같은 함수는 비용이 많이 든느 작업이다. std::deque는 이러한
9.컨테이너 어댑터: std::stack, std::queue, std::priority_queue
앞서의 컨테이너(array, vector, forward_list, deque..)는 완전히 바닥부터 만들어졌다. 컨테이너 어댑터는 이미 존재하는 컨테이너를 기반으로 만들어진 컨테이너이다. 기존 컨테이너를 감싸는 래퍼를 제공하는 데에는 몇 가지 이유가 있다.코드에 좀
10.[트리(Tree)] 이진 트리 형태의 회사 조직도와 트리 순회 방법(중위/전위/후위, 레벨 순회)
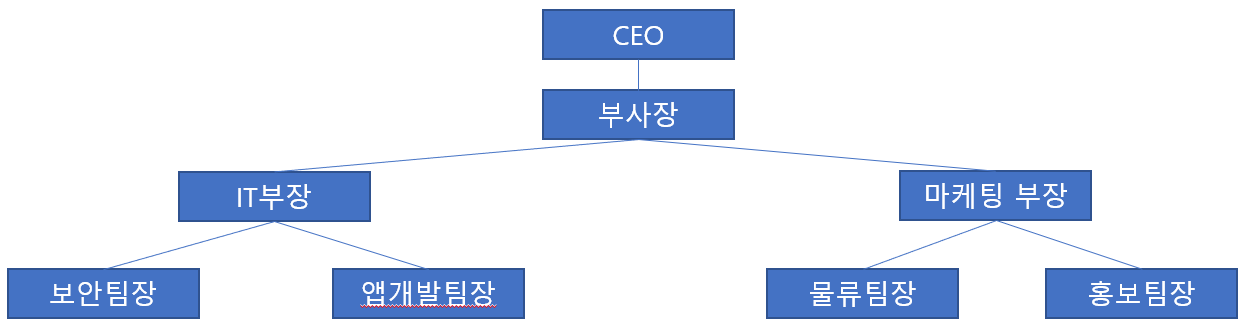
트리는 노드와 노드 사이를 연결하는 에지를 이용하여 계층을 구성함. 트리의 맨 위 레벨부터 아래 레벨까지, 왼쪽 노드에서 오른쪽 노드 순서로 방문.트리의 루트 노드부터 단계별로 차례대로 나열하는 것ex)CEO부사장IT부장 마케팅부장보안팀장 앱개발팀장 물류팀장 홍보팀장\
11.[트리(Tree)] 이진 검색 트리(Binary Search Tree)
부모 노드의 값 >= 왼쪽 자식 노드의 값부모 노드의 값 <= 오른쪽 자식 노드의 값BST가 완전 이진 트리 형태라면 검색 및 삽입 동작의 시간 복잡도는 O(logN)이다.BST에서 원소를 검색할 때는 트리의 모든 원소를 방문하지 않아도 된다. 현재 노드가 찾고자
12.[트리(Tree)] 이진 트리 종류
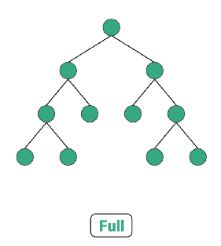
이전 포스팅에서 불균형 트리, 균형 트리, 완전 이진 트리에 대해 언급한 적이 있다. 본 포스팅은 트리의 종류에 대해 좀더 자세히 알고 추후 자료구조 공부에 활용하고자 한다. 그림 source: https://towardsdatascience.com/5-typ
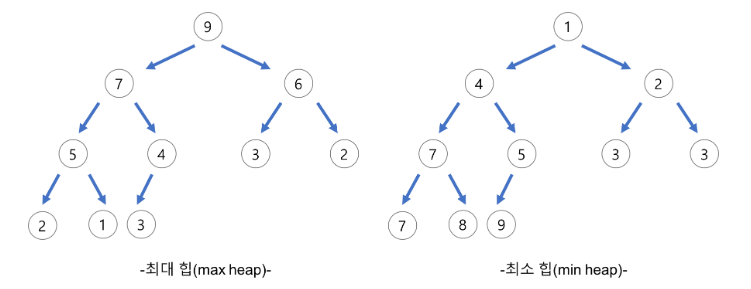
13.[힙(Heap), 힙 트리] 완전 이진 트리 기반의 최대/최소 힙
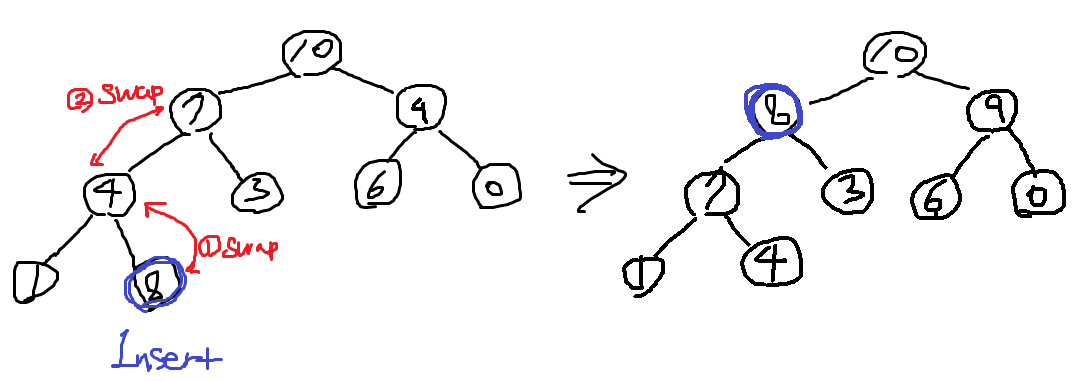
힙 연산은 아래와 같은 시간 복잡도를 만족해야 한다.최대/최소 원소 접근(pq.top()): O(1)원소 삽입에 대한 시간 복잡도(pq.push(..)): O(logN)최대 원소 삭제에 대한 시간 복잡도(pq.pop()): O(logN)
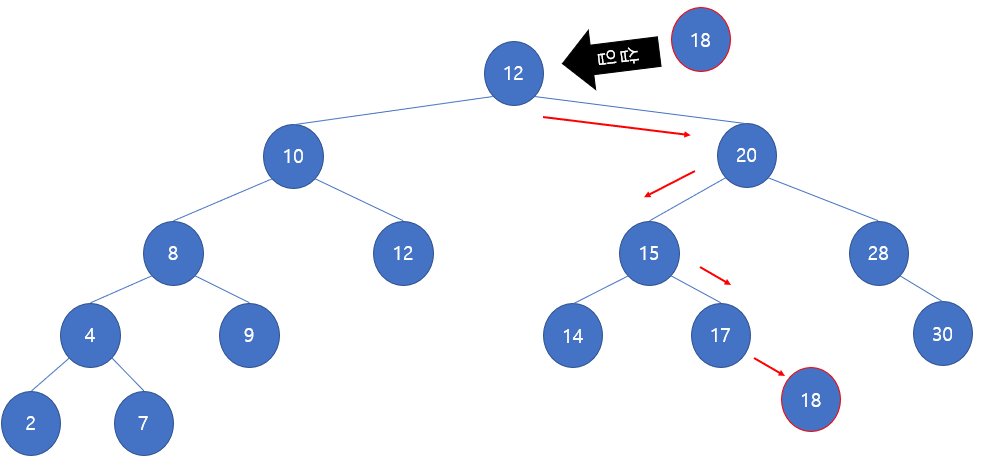
14.[힙(Heap)] 힙 기반 우선순위큐 구현 (with Heap Sort)
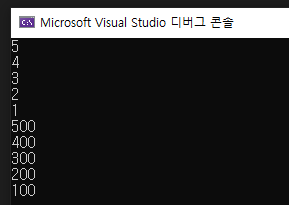
15.[맵(map)] 균형 이진 트리 기반의 std::map과 map을 사용하는 이유
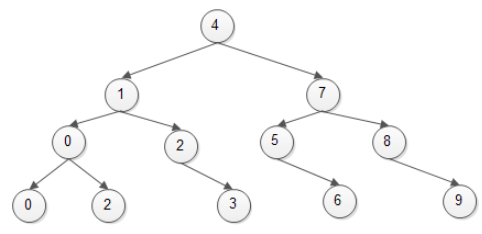
Key-Value 구조(또는 Key)만 존재하는 컨테이너인 '연관 컨테이너'의 일종이다.균형 이진 트리 기반 자료구조를 가진다. 우선순위 큐(std::priority_queue)의 경우 힙을 기반으로 하고, 힙은 내부적으로 '완전 균형 이진 트리'로 구성되어 있음vec
16.[맵(map)] 정렬 우선 순위

map은 키(key) 타입의 ', int> 순서 Ket type: pair (1) pair의 first 원소 기준 내림차순 (2) first가 같다면 second 원소 기준 내림차순 2. cmp 구조체 선언 및 operator() 오버로딩 활용
17.[해시(Hash)] 해시 관련 용어 및 충돌 발생 해결법(체이닝, 열린 주소 지정)

룩업은 특정 원소가 컨테이너에 있는지 확인하거나 또는 컨테이너에서 특정 키(key)에 해당하는 값(value)을 찾는 작업을 의미함.선형 자료구조인 경우 룩업 작업의 시간 복잡도는 O(N)연관 컨테이너의 일종인 map 또는 set의 경우 룩업 작업의 시간 복잡도는 O(
18.[해시(Hash)] STL 제공 해시 함수 객체: std::hash 및 해시 컨테이너: std::unordered_map/set
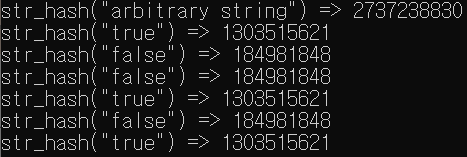
대부분의 응용 프로그램에서 룩업 연산은 매우 빈번하게 발생한다. 그러나 해시 구현에서 항상 양의 정수만을 취급할 수 없다. 오히려 문자열 데이터를 다루게 되는 경우가 더 많다. 예를 들어 단어 사전의 경우 영어 단어를 키(key)로 뜻을 값(value)로 사용해야 한다
19.[해시(Hash)] std::map vs std::unordered_map
to be..
20.Hash (with JAVA)

해시법은 데이터를 저장할 위치(인덱스)를 간단한 연산으로 구하는 것. 검색 뿐만 아니라 추가, 삭제도 효율적으로 수행할 수 있다. 예를 들어 배열의 각 요소 값으로 키 값이 있을 때 각 요솟수를 특정 수로 나눈 나머지를 해시 값(hash value)라고 할 수 있다.
21.std::unordered_map(해시 테이블)
STL에서 제공하는 해시 자료구조이다. 검색(find or at)/삭제(erase)/삽입(insert)이 O(1)에 처리될 수 있다. std::map보다 빠른 탐색을 할 수 있는 자료구조이며 이는 map은 내부가 이진탐색 트리로 이루어져 있으므로 탐색에서의 시간 복잡도
22.동적 크기 배열 구현하기 / (+) const 함수 / (+) 복사 생성자 vs 복사 대입 연산자

cf) const 함수 1\. 함수명 뒤의 const멤버변수를 읽기 전용으로 사용하겠다는 표시.2\. 매개변수에서 const복사 오버헤드 없이 참조하는 변수를 마찬가지로 읽기전용으로 사용하겠다는 표시.3\. 함수 반환타입 앞 const 함수의 반환값을 읽기 전용으로 사