NoSQL의 탄생
source: https://hanamon.kr/%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%B2%A0%EC%9D%B4%EC%8A%A4-sql-vs-nosql/
source: https://velog.io/@98kimjh/Database-NoSQL-Concept
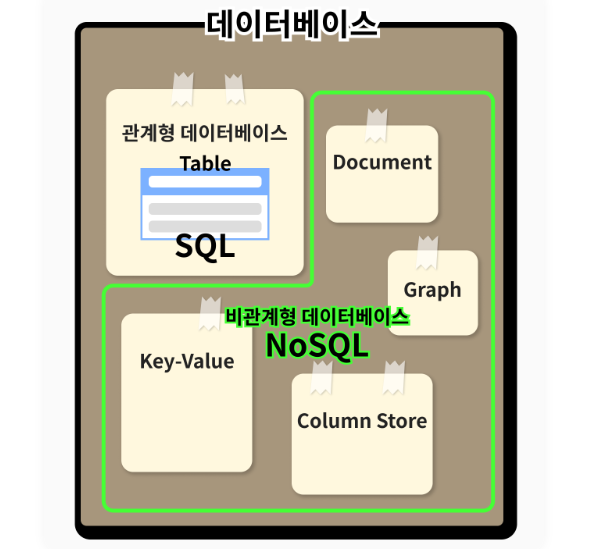
관계형 DB는 표, 즉 테이블과 외래키 등을 사용하고, 다양한 종류의 질의 구문(SQL)로 원하는 정보를 다각적으로 빠르게 추출할 수 있다. 또 관계형 DB는 데이터 일관성을 중요하게 생각한다.
이에 반해 NoSQL은 관계형 DB에서 전통적으로 중시하던 몇 가지를 포기하는 대신 다른 측면의 장점을 보인다.
관계형 DB의 문제점
관계형 DB는 특성 상황에서 몇가지 부족한 점이 있다. 한 예로 "한 테이블에 저장된 레코드들은 모두 같은 형태의 필드를 가져야 한다."란 약속이 있을 때 '로그 데이터'를 한 테이블에 기록할 때는 불편할 수 있다.
EX)
플레이어가 아이템을 구매한 로그를 담는 테이블
- 필드 1) 획득한 시간
- 필드 2) 플레이어 ID
- 필드 3) 획득한 아이템 종류
이 테이블에 1억 개의 레코드가 쌓인 후 필드를 추가하는 경우가 발생하였다.
- 필드 +) 구매 개수
이러한 경우 테이블의 필드를 추가하여 기존에 있던 레코드의 해당 필드는 NULL 값으로 채우면 된다.
하지만 문제는 플레이어 ID 대신 플레이어의 email 주소를 저장하는 상황이 되었거나, 아이템 종류에서 나아가 아이템 이름을 문자열 형태로 남겨야 하는 등의 추가 변경사항에는 로그 테이블 구조 변경은 복잡해 질 것이다.
NoSQL의 탄생(1): "테이블 수정의 복잡성에서 벗어날 수 있다."
관게형 DB의 레코드는 리스트나 배열구조의 데이터이고, NoSQL은 레코드가 리스트나 배열이 아닌 트리나 구조체 형태을 갖추어있다. 마치 필드 하나에 JSOM 문서 모두를 저장하는 것이다. 이러한 방식으로 테이블을 수정하는 복잡성에서 자유로워 질 수 있다.
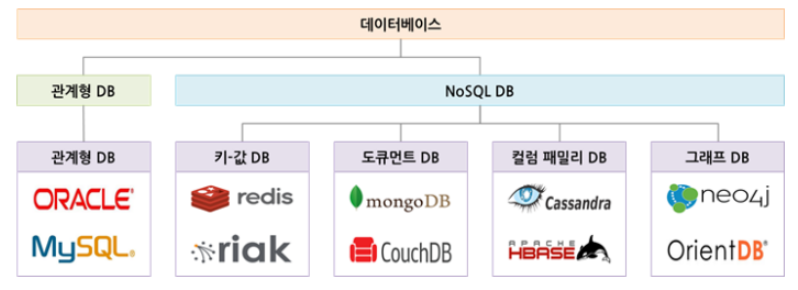
관계형 DB에서 확장성
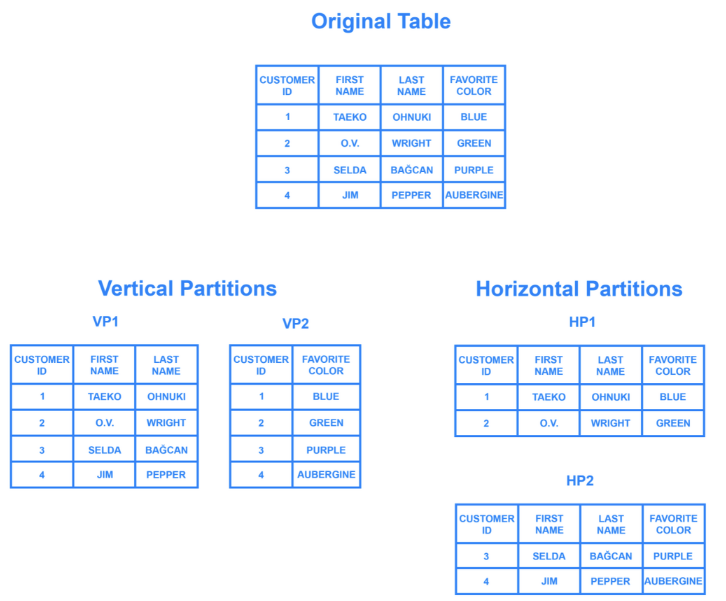
source: https://minkwon4.tistory.com/317
수직 분할
- 플레이어 정보가 테이블 여러 개로 구성됨
- 충분한 수의 플레이어를 처리하는 데 필요한 DB 컴퓨터 대수가 100대라 하면, 10개로 나뉘어진 테이블은 무의미함.
- 10개의 테이블 중 정작 엑세스되는 테이블이 하나뿐이라면 잘못된 설계 -> 수평 분활 필요
수평 분할
- 기존의 테이블이 1억개의 레코드를 가졌다고 가정하면, 100대의 DB 컴퓨터에 100만 개씩 레코드를 분배
- 수평으로 분산된 데이터베이스에서는 각 컴퓨터가 큰 테이블 1개를 조각 조각 가진 셈. 이를 샤드(shard, 큰 조각)라고 함.
수평 분할, 코디네이터, 로케이터 DB
수평 분할 후 DB에 액세스하려면 어떻게 해야 할까(찾고자하는 레코드가 어느 샤드에 존재할까)?
여러 방법 중 대표적으로 두 가지 방법이 있다.
-
해시 함수 사용: 레코드의 키 값을 입력 값으로 하여 해시 함수를 실행한다. 연산 후 얻은 정수 값으로 샤드 넘버로 사용한다.
-
로케이터(locator) DB 사용: 레코드가 어느 샤드에 저장되었는지를 담고 있는 테이블에 액세스하여 어느 샤드에 있는 파악한다.
로케이터 DB 사용 방식으로 설명을 이어나가겠다.
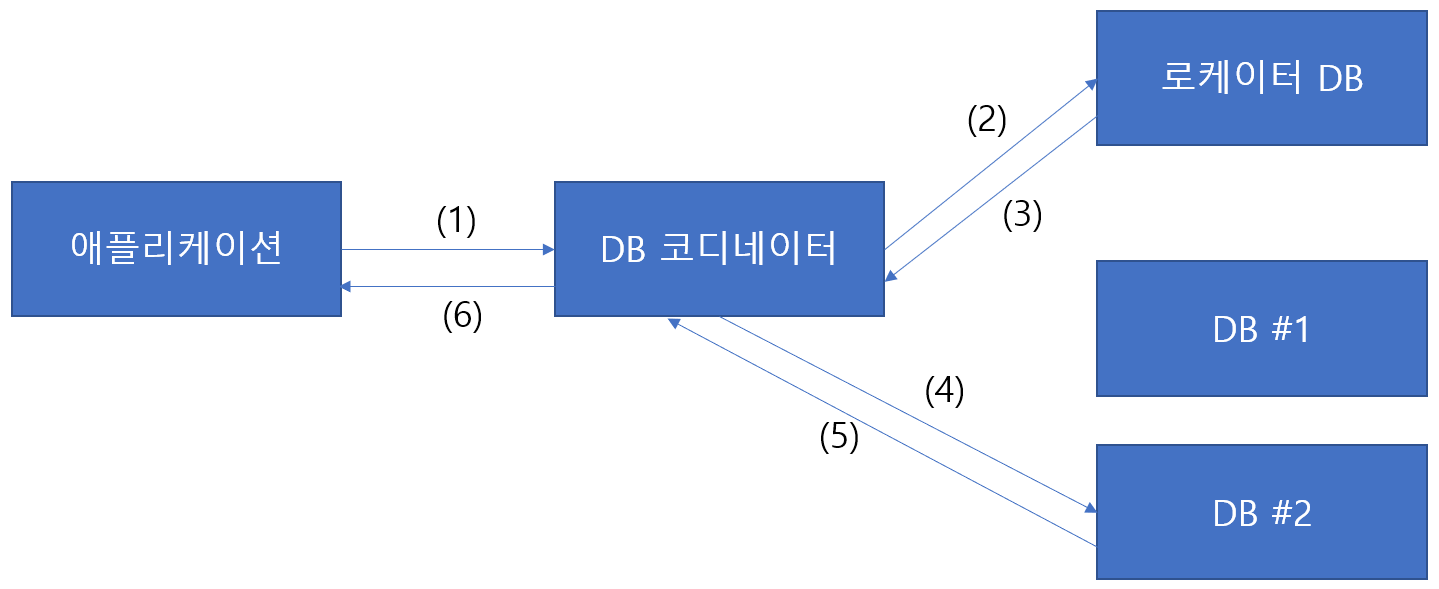
(1) 서버가 데이터베이스에 질의를 던진다.
(2) 질의를 수행하는 코디네이터(coordinator)는 질의에 관련된 레코드가 있는 위치를 로케이터 DB에 묻는다.
(3) 로케이터 DB로 부터 해당 샤드 위치를 파악한다.
(4) 샤드에서 레코드 액세스를 처리한다.
(5,6) 결과를 받는다.
분산 락과 처리 속도 저하
관계형 DB에서 샤딩을 하면 어떤 데이터는 두 대 이상의 기기에 나누어 저장된다. 관계형 DB는 기본적으로 데이터 일관성이라는 철학을 지키기에 기기 두 대 이상에 걸쳐 발견되어야 하는 데이터는 내부적으로 분산 락으로 보호되면서 액세스된다.
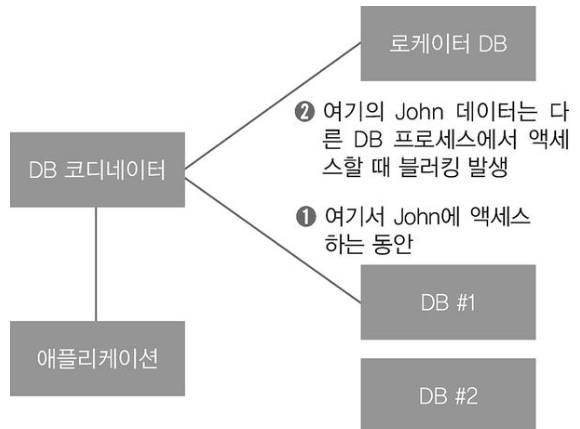
예를 들어 샤드 1에 있는 특정 레코드를 변경 및 삭제할 시 로케이트 DB에 있는 특정 레코드(샤드1 레코드 관련)도 삭제되어야 한다. 샤드1, 로케이트 DB의 데이터 일부는 마치 트랜잭션을 거는 것처럼 락 상태가 일시적으로 유지될 것이다.
문제는 DB 샤드가 많을 수록 분산 처리 효과가 퇴색되고, 처리 속도가 저하된다.
이를 단점이라 하기도 애매하다. 분산 관계형 DB의 결점이라기보다, 일관성을 중요하게 여기는 관계형 DB의 특성상 어쩔 수 없는 문제이기 때문이다.
NoSQL의 탄생(2): "데이터 원자성과 일관성을 어느정도 포기하면서(약한 락) 제약받지 않는 스케일 아웃을 통한 시스템 전체 성능 향상을 꾀한다."
반면 일관성과 원자성을 어느정도 포기하면서 성능 하락을 막는 방법이 있다. 샤드에 든 레코드를 액세스하는 동안 관련된 다른 기기에 락의 강도를 낮추면, 락이 그만큼 줄기에 수평 분산의 효과를 제대로 볼 수 있다.
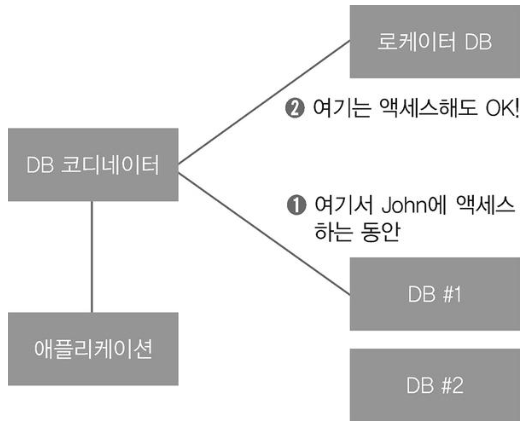
더 이상 관계형 DB로서 역할을 하지 못하는 것이기도 하지만, 그 대가로 락에 따른 성능 하락이 더 이상 발생하지 않는다. 처리할 양이 늘어나면 그만큼 샤드 개수를 늘리면 된다.
관계형 DB에서 고가용성
고가용성: HW 고장 또는 다른 이유로 서버 기기가 정상 작동을 하지 않을 때도 사용자 입장에서는 서비스가 지속되는 상태를 유지하는 것
고가용성을 위해 다양한 기법이 있는데 그 중 하나가 장애 극복(fail over)이다. 이를 위해 할 수 있는 것은 레코드의 상시 백업이 있다. 고가용성을 위해 DB1에 있는 레코드를 DB2에 항상 백업, 즉 미러링 복제를 수행한다.
결국 같은 데이터가 DB1과 DB2에 모두 있게 한다(이중화 혹은 다중화).
이 방식은 결과적으로 가용성을 높이고자 성능을 희생시킨 것이다.
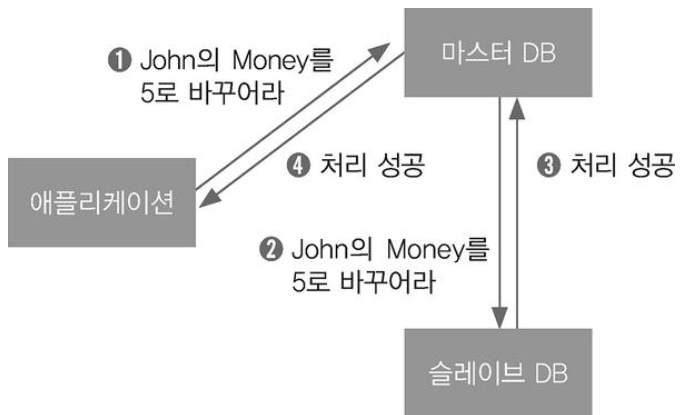
NoSQL의 탄생(3): "데이터 일관성을 어느정도 포기하면서 가용성을 높이는데 성능을 희생시키지 않는다."
슬레이브의 변경 전파 과정을 건너뛰고 서버에 바로 응답하는 방식으로 성능 문제를 해결할 순 있다.
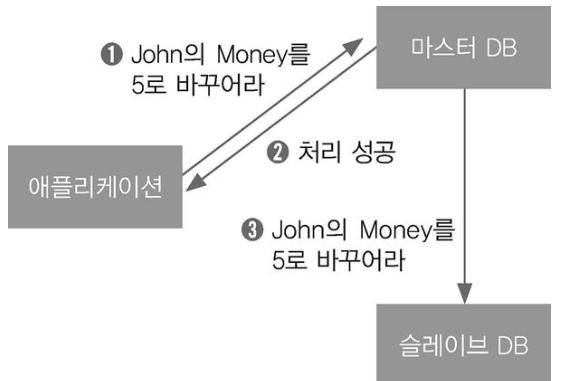
단 마스터와 슬레이브는 항상 같은 상태가 아니고 일시적으로 옛 데이터를 가지는 문제가 있을 수 있다. 즉, 일관성이 깨진다. 다른 표현으로 최신이 아닌 스테일 데이터(stale data)를 가져오는 문제가 있을 수 있다.
위와 같이 "락의 강도 줄이기", "슬레이브의 변경 전파 과정 생략" 방식은 관계형 DB의 ACID 중 A(원자성), C(일관성)과 I(고립성)을 어느 정도 포기하면서 '만족스러운 수준'의 스케일 아웃과 고가용성을 확보할 수 있는 것이다.
이러한 관계형 DB 입장에선 이단아는 ACID가 아닌 BASE라는 개념을 가진다. '기본적으로 가용성'이라는 의미이다.
이들의 데이터베이스는 소프트 스테이트(soft state)로 일시적으로 데이터 상태가 변화 중일 수 있다는 의미이다. (데이터 상태가 유연)
그리고 이들이 일관성을 결과적 일관성(evential consistency)이라고 한다. 일시적으로 데이터 일관성이 깨지지만, 언젠가는 일관성을 다시 구축하게 된다는 의미이다.
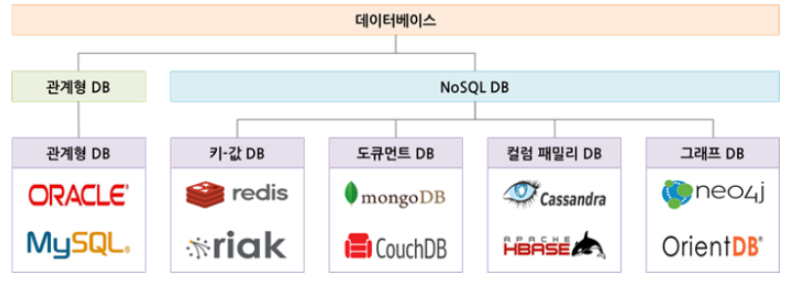
NoSQL 특징
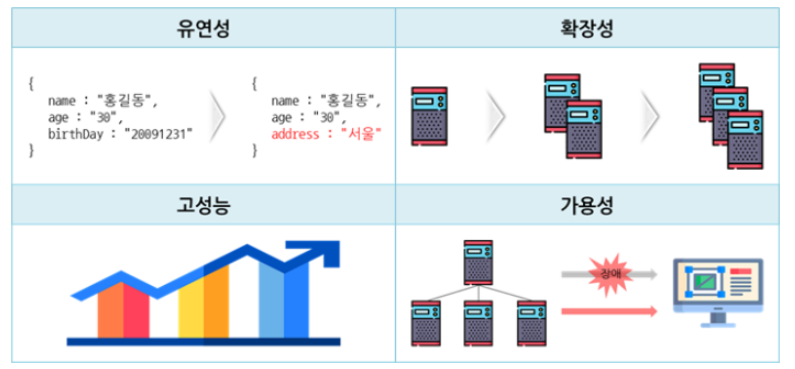
source: https://velog.io/@98kimjh/Database-NoSQL-Concept
정리
- 관계형 DB 진형에서의 이단아, BASE(<->ACID), "기본적으로 가용성"이라는 의미
- 일관성을 일부 희생하더라도 높은 확장성과 고가용성을 실현
- 탈 테이블 구조의 유연한 저장 방식을 이용하여 더 효율적인 프로그래밍을 추구(테이블 설계/수정의 번거로움에서 탈피)
=> 이러한 형태의 DB가 바로 "NoSQL"이다.
