reference: 시스템 프로그래밍 수업 / 최종무 교수님
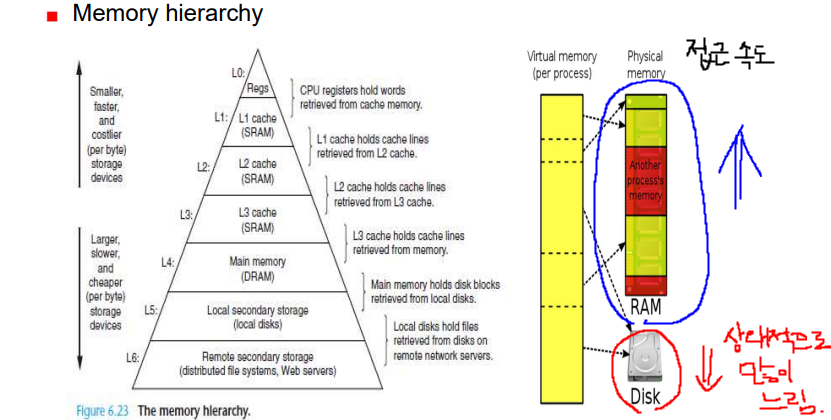
일반적으로 캐시는 코어와 밀접한 메모리 공간을 뜻하지만, 메인 메모리 또한 디스크의 딴의 관점에서 캐시로 볼 수 있다.
Cache effect
- Consider DRAM and Disk case (DRAM as a Disk's cache)
- Goal: Maximize cache hit(or minimize cache miss)
(Model)
- 평균 메모리 접근 시간(AMAT, Average Memory Access Time)
- AMAT = (P_hit x T_m) + (P_miss + T_d)
(T_m: 메모리 접근 레이턴시, T_d: 디스크 접근 레이턴시, P_hit: 캐시에서 데이터를 찾을 확률)
- AMAT = (P_hit x T_m) + (P_miss + T_d)
- Hit Ratio는 중요하다.
- 인간이 작성한 프로그램에는 locality라는 특성이 있다. 공간적 지역성과 시간적 지역성이 대표적이다. 공간적 지역성은 한 데이터가 사용되면, 이 데이터에 물리적으로 가까운 데이터가 다시 사용될 확률이 높다는 뜻이고, 시간적 지역성은 한 번 사용된 명령어 또는 데이터가 다시 사용될 확률이 높다는 것이다. 루프문이 그 예이다.
- 사용한 데이터와 명령어, 그리고 그 부근에 있는 데이터까지 모두 캐싱한다. 기본적인 특성인 locality에 따라 캐시 히트는 빈번히 발생한다.
- 프로그래밍적 최적화로 캐시 히트율을 더 높일 수 있다.
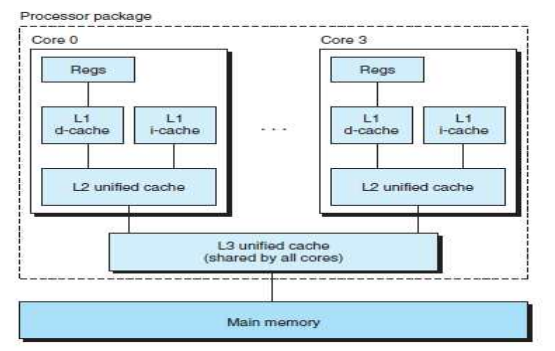
cf) Intel Core i7 캐시 계층 구조
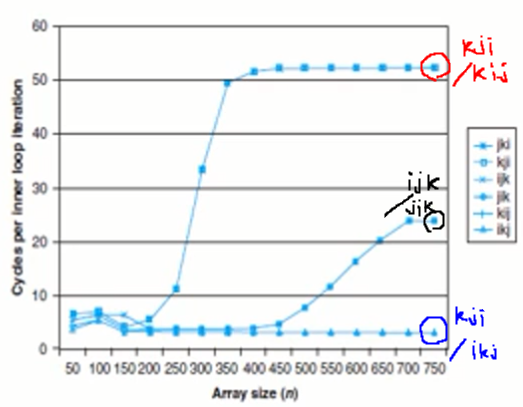
matrix multiplication의 연산 과정을 통한 캐시 성능 분석
- version_ijk
void multiplication_ijk(int n, int (*A)[N], int (*B)[N]){
int i, j, k, sum;
struct timeval stime, etime, gap;
int (*C)[N];
C = (int(*)[N])malloc(sizeof(int)*N*N);
gettimeofday(&stime, NULL);
for(i=0; i<N; i++){
for(j=0; j<N; j++){
sum = 0;
for(k=0; k<N; k++)
sum += A[i][k]*B[k][j];
C[i][j] = sum;
}
}
gettimeofday(&etime, NULL);
gap.tv_sec = etime.tv_sec - stime.tv_sec;
gap.tv_usec = etime.tv_usec - stime.tv_usec;
if (gap.tv_usec < 0) {
gap.tv_sec = gap.tv_sec - 1;
gap.tv_usec = gap.tv_usec + 1000000;
}
printf("[ijk]: Elapsed time %ldsec :%ldusec\n", gap.tv_sec, gap.tv_usec);
free(C);
}- version_jik
void multiplication_jik(int n, int (*A)[N], int (*B)[N]){
int i, j, k, sum;
struct timeval stime, etime, gap;
int (*C)[N];
C = (int(*)[N])malloc(sizeof(int)*N*N);
gettimeofday(&stime, NULL);
for(j=0; j<N; j++){
for(i=0; i<N; i++){
sum = 0;
for(k=0; k<N; k++)
sum += A[i][k]*B[k][j];
C[i][j] = sum;
}
}
gettimeofday(&etime, NULL);
gap.tv_sec = etime.tv_sec - stime.tv_sec;
gap.tv_usec = etime.tv_usec - stime.tv_usec;
if (gap.tv_usec < 0) {
gap.tv_sec = gap.tv_sec - 1;
gap.tv_usec = gap.tv_usec + 1000000;
}
printf("[jik]: Elapsed time %ldsec :%ldusec\n", gap.tv_sec, gap.tv_usec);
free(C);
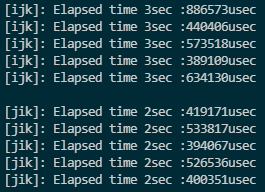
}version_ijk와 jik의 실행 시간
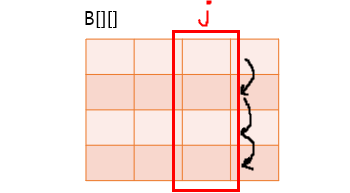
- 배열 B의 접근은 행우선 접근이므로 캐시 히트율 측면에서 나쁘다.
- version_jki
void multiplication_jki(int n, int (*A)[N], int (*B)[N]){
int i, j, k, r, sum;
struct timeval stime, etime, gap;
int (*C)[N];
C = (int(*)[N])malloc(sizeof(int)*N*N);
gettimeofday(&stime, NULL);
for(j=0; j<N; j++){
for(k=0; k<N; k++){
r = B[k][j];
for(i=0; i<N; i++)
C[i][j] += A[i][k]*r;
}
}
gettimeofday(&etime, NULL);
gap.tv_sec = etime.tv_sec - stime.tv_sec;
gap.tv_usec = etime.tv_usec - stime.tv_usec;
if (gap.tv_usec < 0) {
gap.tv_sec = gap.tv_sec - 1; gap.tv_usec = gap.tv_usec + 1000000;
}
printf("[jki]: Elapsed time %ldsec :%ldusec\n", gap.tv_sec, gap.tv_usec);
free(C);
}- version_kji
void multiplication_kji(int n, int (*A)[N], int (*B)[N]){
int i, j, k, r, sum;
struct timeval stime, etime, gap;
int (*C)[N];
C = (int(*)[N])malloc(sizeof(int)*N*N);
gettimeofday(&stime, NULL);
for(k=0; k<N; k++){
for(j=0; j<N; j++){
r = B[k][j];
for(i=0; i<N; i++)
C[i][j] += A[i][k]*r;
}
}
gettimeofday(&etime, NULL);
gap.tv_sec = etime.tv_sec - stime.tv_sec;
gap.tv_usec = etime.tv_usec - stime.tv_usec;
if (gap.tv_usec < 0) {
gap.tv_sec = gap.tv_sec - 1; gap.tv_usec = gap.tv_usec + 1000000;
}
printf("[kji]: Elapsed time %ldsec :%ldusec\n", gap.tv_sec, gap.tv_usec);
free(C);
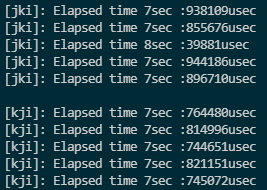
}version_jki와 kji의 실행 시간
배열 A에서 read, C에서 write 모두 행우선 접근 -> 캐시 히트율이 더 낮아진다. 결국 가장 안좋은 성능을 보인다.

- version_kij
void multiplication_kij(int n, int (*A)[N], int (*B)[N]){
int i, j, k, r, sum;
struct timeval stime, etime, gap;
int (*C)[N];
C = (int(*)[N])malloc(sizeof(int)*N*N);
gettimeofday(&stime, NULL);
for(k=0; k<N; k++){
for(i=0; i<N; i++){
r = A[i][k];
for(j=0; j<N; j++)
C[i][j] += r*B[k][j];
}
}
gettimeofday(&etime, NULL);
gap.tv_sec = etime.tv_sec - stime.tv_sec;
gap.tv_usec = etime.tv_usec - stime.tv_usec;
if (gap.tv_usec < 0) {
gap.tv_sec = gap.tv_sec - 1; gap.tv_usec = gap.tv_usec + 1000000;
}
printf("[kij]: Elapsed time %ldsec :%ldusec\n", gap.tv_sec, gap.tv_usec);
free(C);
}- version_ikj
void multiplication_ikj(int n, int (*A)[N], int (*B)[N]){
int i, j, k, r, sum;
struct timeval stime, etime, gap;
int (*C)[N];
C = (int(*)[N])malloc(sizeof(int)*N*N);
gettimeofday(&stime, NULL);
for(i=0; i<N; i++){
for(k=0; k<N; k++){
r = A[i][k];
for(j=0; j<N; j++)
C[i][j] += r*B[k][j];
}
}
gettimeofday(&etime, NULL);
gap.tv_sec = etime.tv_sec - stime.tv_sec;
gap.tv_usec = etime.tv_usec - stime.tv_usec;
if (gap.tv_usec < 0) {
gap.tv_sec = gap.tv_sec - 1; gap.tv_usec = gap.tv_usec + 1000000;
}
printf("[ikj]: Elapsed time %ldsec :%ldusec\n", gap.tv_sec, gap.tv_usec);
free(C);
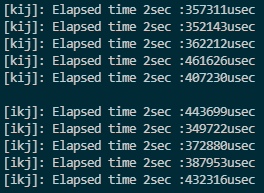
}version_kij와 ikj의 실행 시간
배열 B, C 모두 열우선 접근 -> 가장 성능이 좋다.