컴퓨터 아키텍처(컴퓨터 시스템)
1.명령어 집합 구조 (ISA)
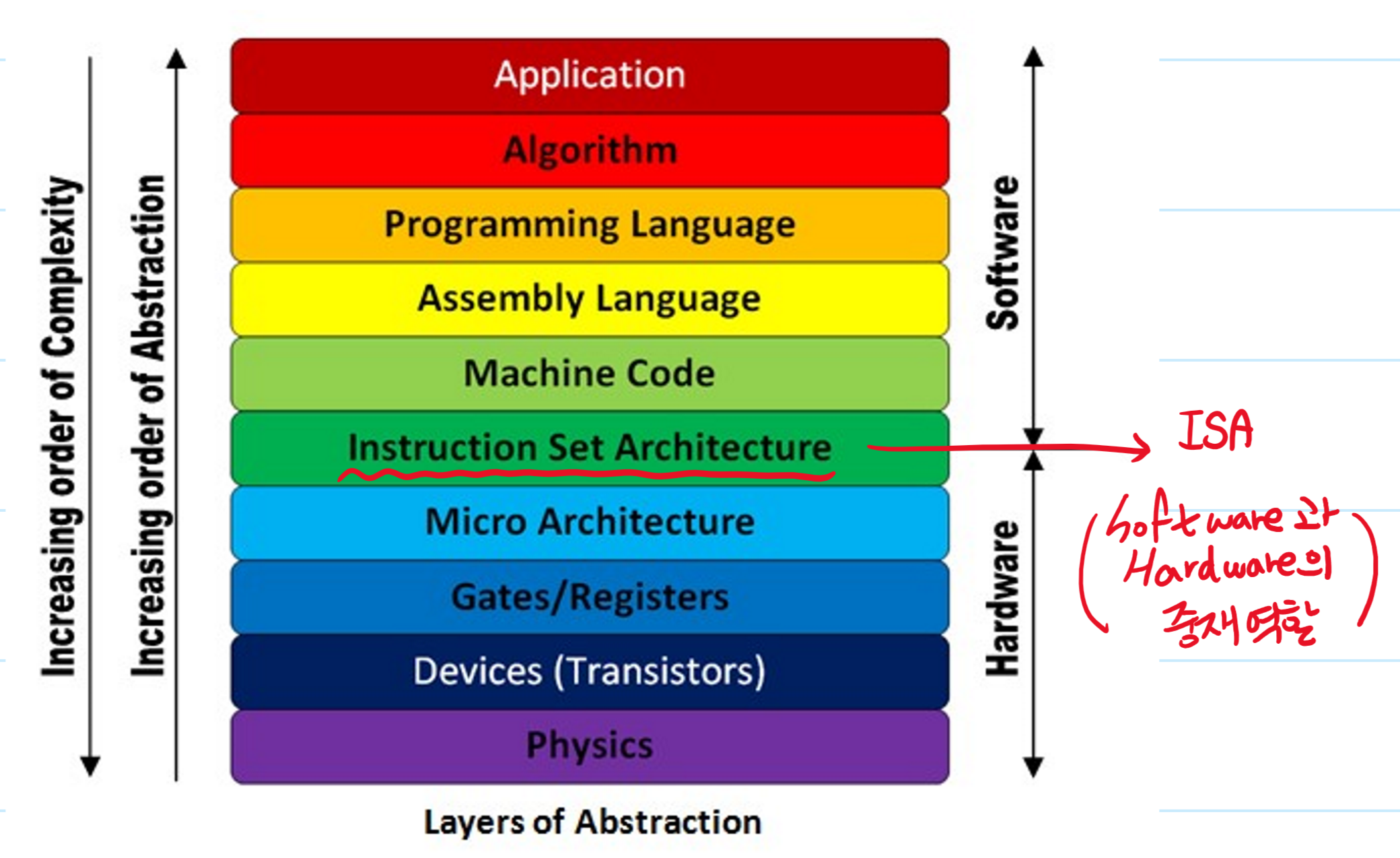
프로세서가 이해하는 언어, 명령어 집합 구조(Instruction Set Architecture). ISA는 프로그래머와 프로세서가 직접적으로 소통할 수 있는 언어.인텔 계열 프로세서와 AMD 계열 프로세서는 내부 구조가 사뭇 다르지만 같은 언어, 즉 같은 ISA(x8
2.프로세서의 기본 부품과 개념
마이크로프로세서 하나를 만드는데 필요한 알고리즘 및 회로 수준의 구조를 정의하는 것을 마이크로아키텍처라고 부름. 대표적인 마이크로아키텍처로는 인텔 펜티엄 프로의 P6 구조. P6 구조는 펜티엄 4를 제외한 거의 대부분의 인텔 프로세서 마이크로아키텍처의 근간이다. 마이크
3.암달의 법칙
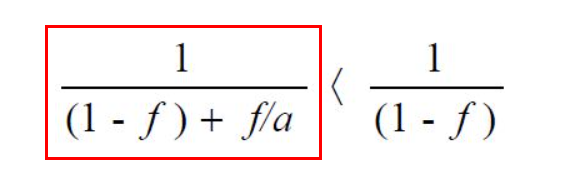
컴퓨터 공학전반에 적용할 수 있는 중요한 개념. 문제 예시프로그램을 분석해보니 80%의 부분을 병렬화할 수 있음을 알아냄. 프로세서가 2개, 4개, 8개, 16개일 때 성능은?전체 프로그램 수행 시간 1 중 0.8을 프로세서 N개로 완벽히 병렬 처리할 수 있다면,총 수
4.프로세서의 성능 지표 & 성능 향상을 위해 해야할 일
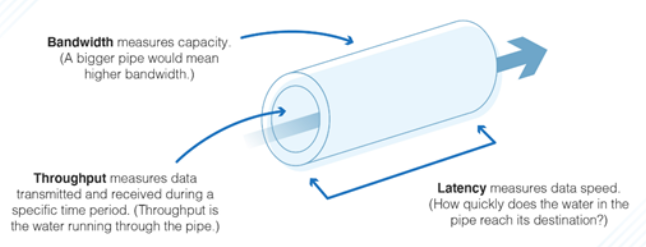
요즘의 프로세서는 전력을 어마나 절약하는가도 중요한 목표가 되었지만, 전통적으로 컴퓨터의 최고 가치는 속도로 대변된다. 컴퓨터의 속도를 더 정확히 정의하면 한 프로그램을 (1) 얼마나 빠르게 완료하는가 (latency), (2) 단위 시간당 얼마나 많이 처리할 수 있는
5.의존성(Dependency): 데이터 의존성

올바른 병렬 프로그램은 역시 순서를 지키며 실행. 의존성 개념은 파이프라인, 비순차 실행, 병렬 프로그래밍의 기초를 이해하는데 중요.데이터 의존성은 명령어들 사이의 데이터 흐름으로, 프로그램의 문맥을 결정하는데 중요한 요소. 특히 컴파일러에서도 최적화를 할 때 의존성
6.의존성(Dependency): 컨트롤 의존성 & 메모리 의존성

프로그램의 의미는 데이터 의존성 뿐 아니라 조건 분기문으로도 결정된다. (1),(2),(4) 명령어에는 실행 흐름(control flow) 때문에 의존성이 만들어짐. 이것을 컨트롤 의존성(control dependency)라 한다. 이렇듯 조건 분기문으로 인한 제어 프
7.프로세서 기본 동작
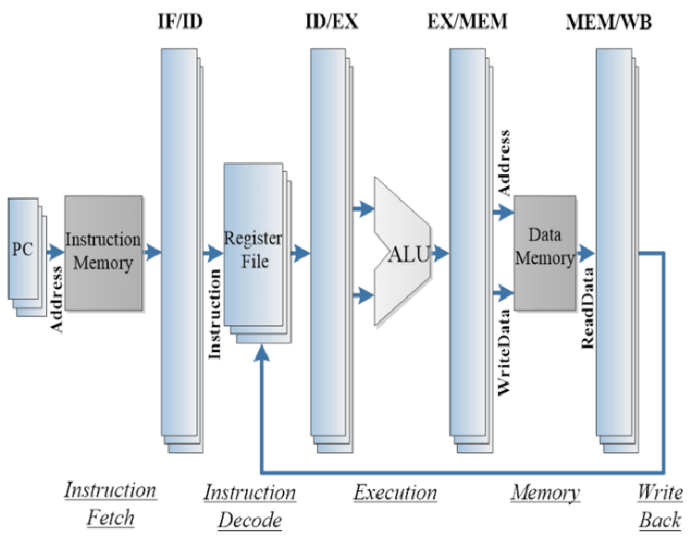
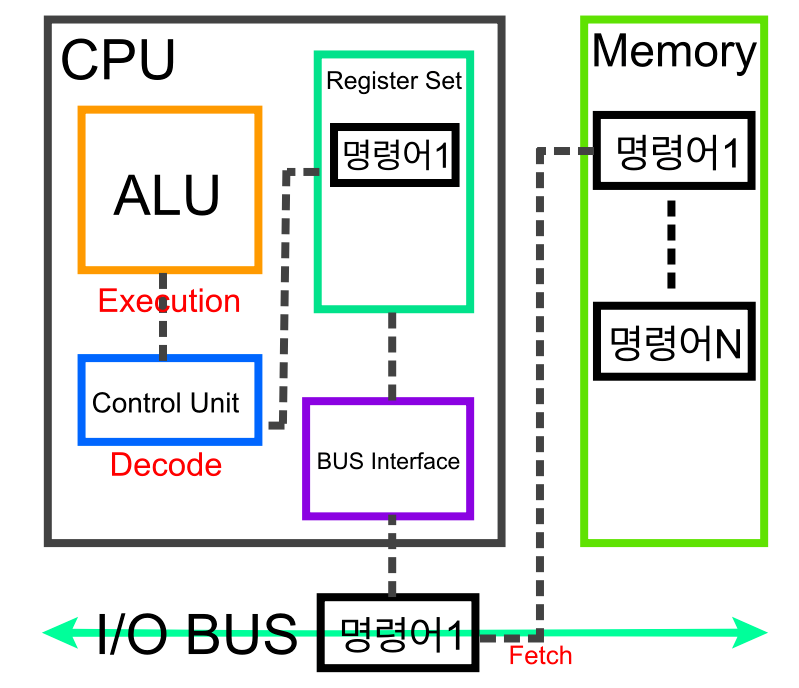
프로세서와 프로그래머 사이의 인터페이스를 결정짓는 명령어 집합 구조.각종 기본 부품: ALU, 레지스터, CU, 캐시마이크로프로세서는 (기계)명령어를 하나하나 처리하므로 명령어 집합 프로세서(Instruction Set Processor)라 부름. 프로세서가 하는 일이
8.예외 처리: 명령어 처리 과정의 예외 사항(인터럽트, 예외: 트랩, 폴트, 중단)
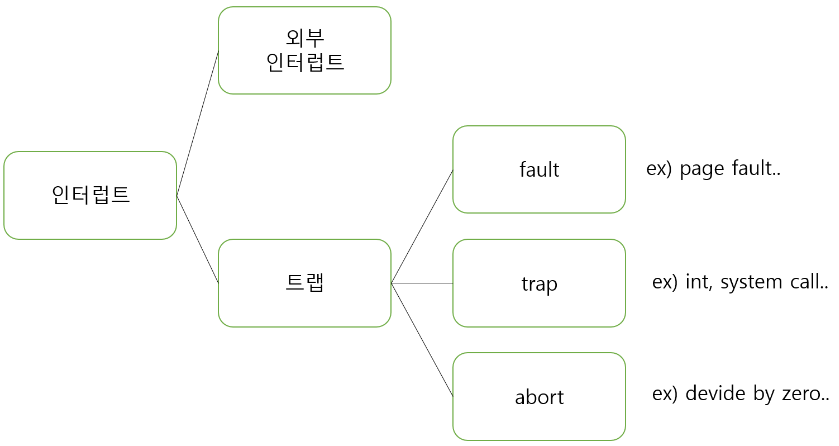
명령어를 처리하는 프로세서도 여러 예외사항이 벌어지고 이를 처리해야만 한다. 읽을 권한이 없는 엉뚱한 메모리 영역에 읽기를 시도하면 segment fault 오류나 윈도우의 오류 창(access violation)을 볼 수 있다. 이 오류는 프로세서가 가상 주소를 물리
9.명령어 파이프라인: 고성능 프로세서의 시작 / 명령어 수준의 병렬성 1

명령어 파이프라인은 캐시와 더불어 현대 고성능 프로세서를 가능케 한 일등 공신. 명령어 처리율을 극대화하여 프로세서의 성능을 크게 향샹시켰다. 마이크로프로세서(microprocessor)의 성능이 비약적으로 높아지는데 가장 핵심적인 기술로 파이프라인이 있다. 파이프라인
10.명령어 파이프라인: 파이프라인 해저드(Hazard)
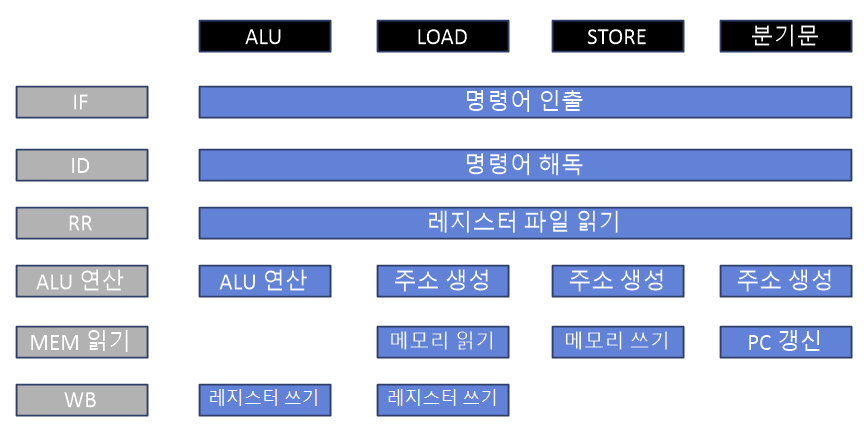
이상적인 파이프라인은 투입되는 작업 간에 서로 의존성이 없음을 가정한다. 그러나 실제 프로그램은 그렇지 않다. 명령어 사이에는 데이터 의존성, 컨트롤 의존성, 메모리 의존성이 있다.
11.비순차 실행(Out-of-Order, OOO)와 슈퍼스칼라(Superscalar) / 명령어 수준의 병렬성 2

파이프라인은 명령어를 순서대로만 처리했다. 이 방법은 사이클이 낭비될 수 있다는 단점을 가진다. 비순차 실행은 이런 단점을 극복한다. 비순차 실행 프로세서는 프로그램을 적혀 있는 순서대로 실행하는 것이 아니라, 프로세서가 직접 명령어 사이의 의존성을 분석하여 먼저 실행
12.비순차 실행의 구현: Register Renaming/Reservation Statation/Re-Order Buffer
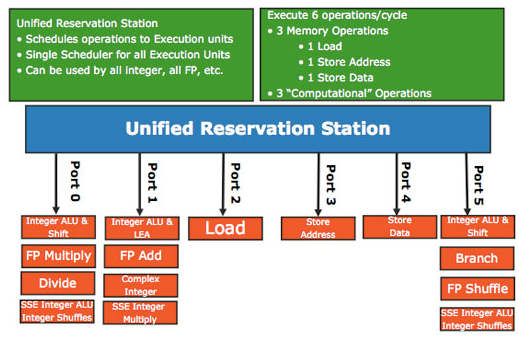
비순차 슈퍼스칼라 프로세서는 주어진 명령어에서 ILP를 찾아 실행 가능한 명령어부터 처리한다. 어떤 명령이 실행 가능하다는 이야기는 이 명령이 취하는 피연산자가 모두 연산을 마쳤을 때라는 의미다. 따라서 어떤 명령의 피연산자가 완료되는 것을 탐지한다면 비순차 실행이 가
13.하이퍼쓰레딩: 병렬성의 극대화 / 쓰레드 수준의 병렬성
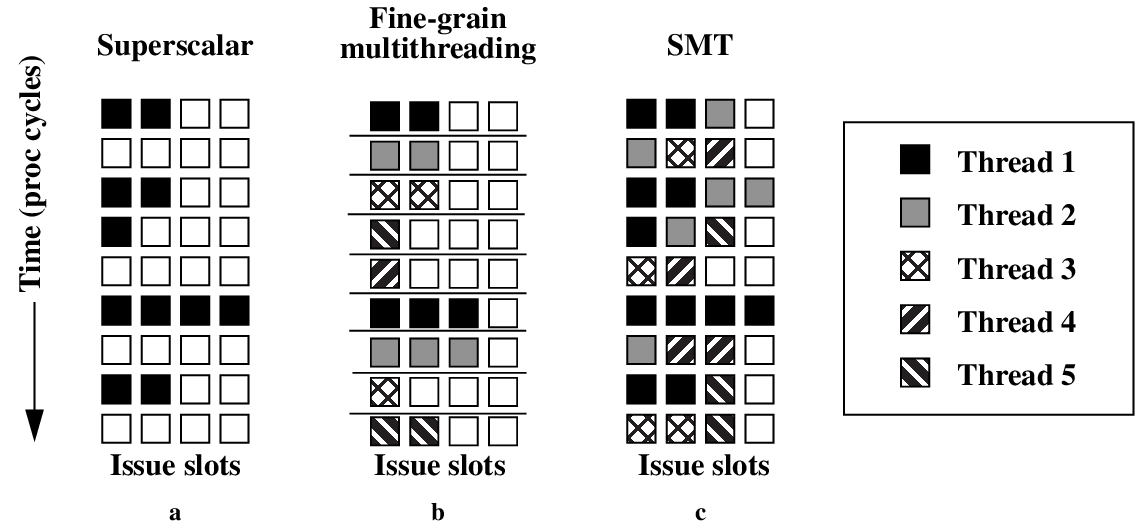
하이퍼쓰레딩은 하나의 물리 프로세서가 두 개의 논리 프로세서로 보이게 하는 기술이다. 하이퍼쓰레딩은 슈퍼스칼라 프로세서에서 동시에 두 쓰레드로부터 명령어를 가져와 파이프라인에 넣는 기술이다. 이렇게 하면 제대로 활용되지 않는 프로세서 자원을 더욱 더 효과적으로 쓸 수
14.멀티코어 혁명: 멀티코어 시대의 도입과 싱글쓰레드 한계
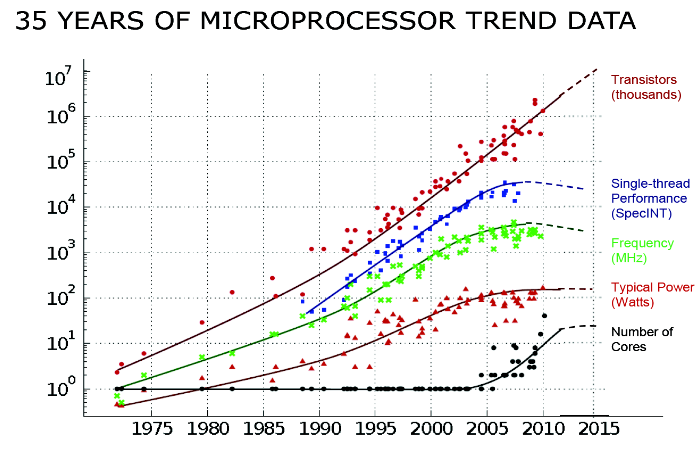
프로세서의 클록 속도는 크게 증가하지 못하고 있다. 과거에는 클록 속도도 계속 늘고 싱글쓰레드의 성능도 크게 발전했는데 에너지 효율이라는 장벽에 막혀 요즘은 그렇지 못하다.
15.멀티코어 혁명: 병렬 컴퓨터 개념과 구조 (멀티코어 프로세서에 앞서)
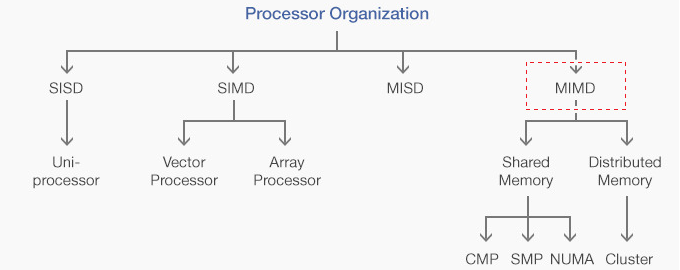
멀티코어는 전혀 새로운 것이 아니며, 결국 병렬 컴퓨터 구조의 새로운 제조 형태일 뿐이다. 과거에는 독립적으로 있었던 프로세서들이 반도체 기술 덕택에 하나의 칩에 제조될 수 있으니, 이것이 바로 멀티코어 프로세서의 탄생이다. 따라서 병렬 컴퓨터 구조 자체를 먼저 살펴볼
16.멀티코어 혁명: 멀티코어 구성 방식과 한계
일반적으로 많이 쓰는 듀얼코어, 쿼드코어 프로세서는 각 코어가 완전히 같다. 구조도 같을 뿐 아니라 클록 속도와 캐시 크기도 같다. 물론 (물론 최근에는 가변적인 클록이 코어마다 가능하도록 되어 있지만 근본적으로 같은 코어다.) 이러한 멀티코어를 호모지니어스(homog
17.CPU 캐시: 기본적인 개념/원리/설계 고려 사항

과거 1996년의 펜티엄 프로세서는 100MHz로 작동했고, 그때의 메모리 클록 속도는 66MHz, 100MHz 정도로 별 차이가 없었다. 그러나 프로세서의 클록 속도는 메모리보다 훨씬 빨라지기 시작했다. 2009년 프로세서는 2~3GHz인데 메모리의 클록 속도는 55
18.CPU 캐시: 사상(mapping) 함수 정리
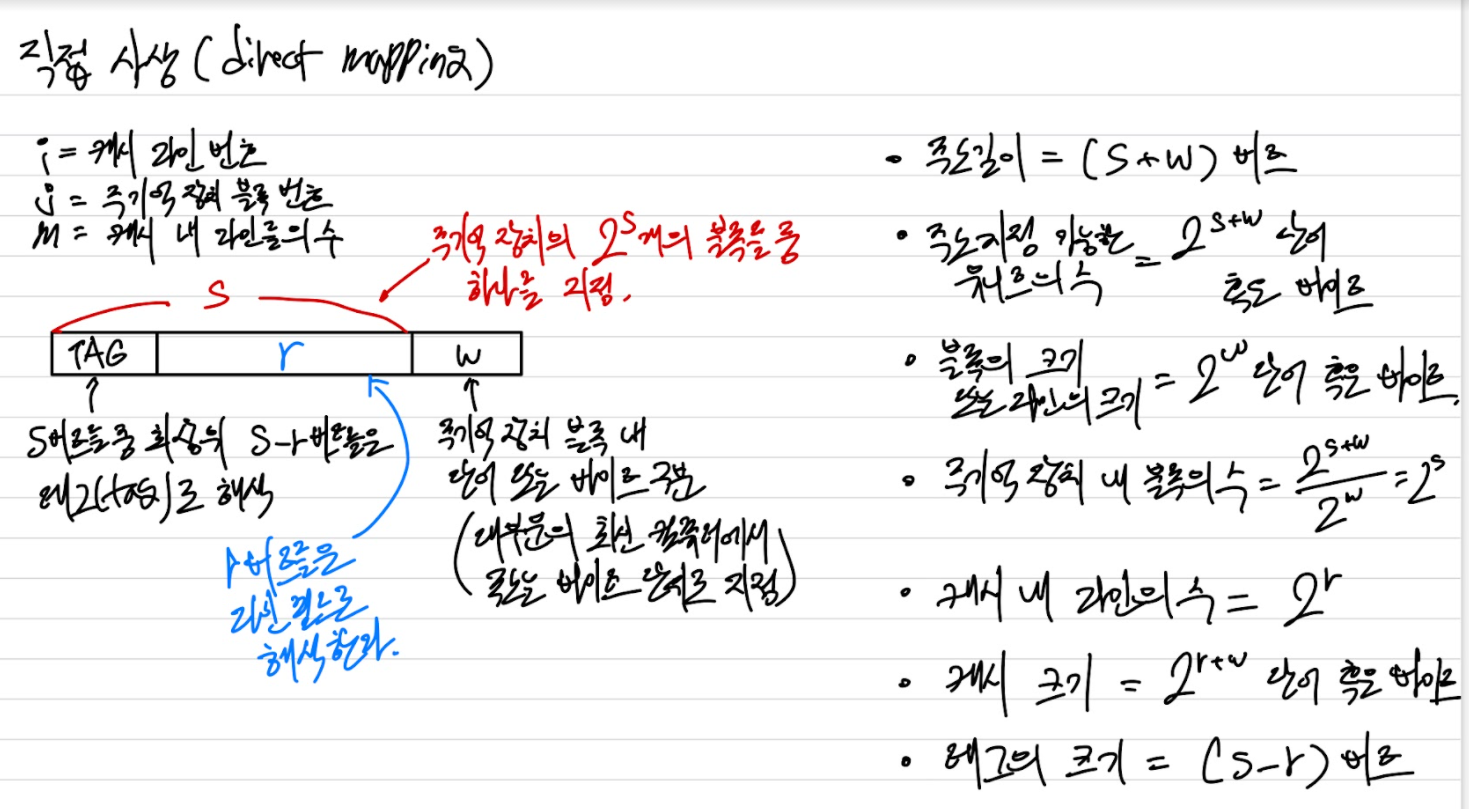
캐시 라인의 수는 주기억장치 블록의 수보다 적기 때문에 캐시 라인 배치를 위한 사상(mapping)해주는 알고리즘이 필요하다. 사상 함수의 선택에 따라 캐시의 조직(배치)가 결정된다. 직접(direct), 연관(associative) 및 세트 연관(set associa
19.Optimization - code motion/함수 호출 줄이기/불필요한 메모리 참조 제거
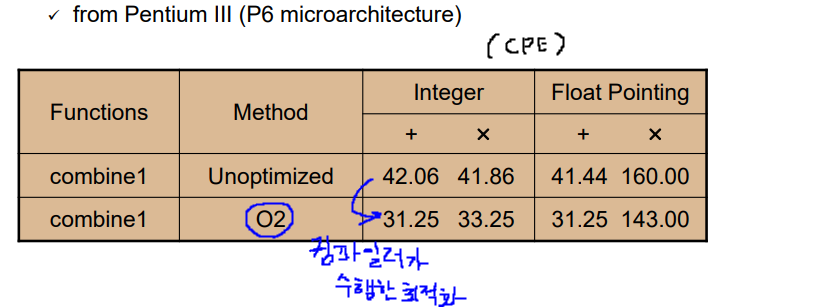
최적화에 대한 개념성능 표현 방법에 대한 이해CPU 독립 최적화 기법 <= 어느 CPU에서든 적용 가능하다.CPU 의존 최적화 기법 <= CPU 특성에 따라 다르다.메모리 계층 구조와 성능 효과최적화된 프로그램이란? 1) 문제 상황에 맞는 적절한 알고리즘과
20.Optimization - Loop unrolling/spilitting

code motion, 함수 호출 최소화, 불필요한 메모리 참조 방지 최적화 기법이 적용된 combine4여기에 컴퓨터 자원 특성에 대한 고려를 보다 반영한 최적화 기법 추가add 연산, Loop unrolling 적용 전 CPE는 2, 적용 후 1(이론상)로 감소.
21.Optimization - Branch Prediction (더 많은 분기 예측 유도하기)
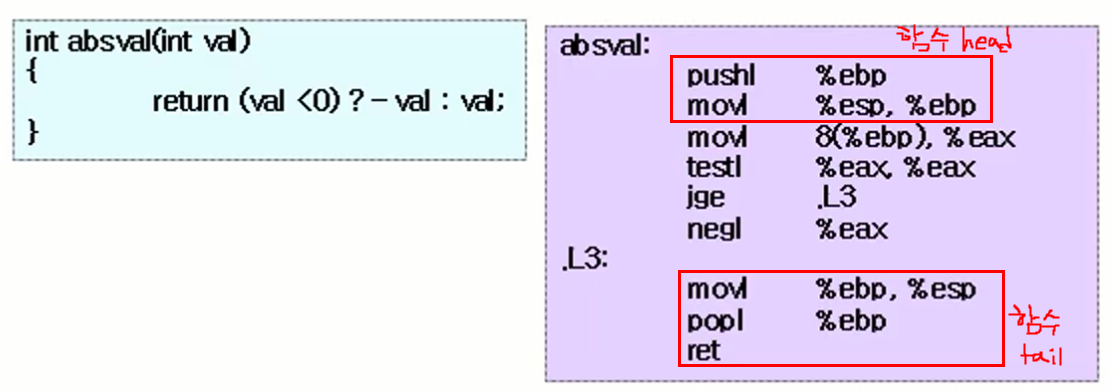
to be continued ..
22.Optimization - 메모리 계층 구조와 성능
일반적으로 캐시는 코어와 밀접한 메모리 공간을 뜻하지만, 메인 메모리 또한 디스크의 딴의 관점에서 캐시로 볼 수 있다. Consider DRAM and Disk case (DRAM as a Disk's cache)Goal: Maximize cache hit(or min