reference:
1) https://mangkyu.tistory.com/96
2) https://velog.io/@meme2367/DB%EC%9D%98-Index
3) https://nowes00.tistory.com/15
인덱스(Index)
만약 영한사전에 인덱스가 없으면 원하는 단어가 나올 때까지 모든 페이지를 다 훑어보아야 할 것이다. 반면 맨 뒤의 인덱스(index, 찾아보기)를 통해 원하는 단어를 찾은 후 그 단어가 나와있는 페이지를 펼치면 된다.
마찬가지로 DB에서도 이러한 인덱스 기능을 쓸 수 있다. 인덱스는 필드 단위로 설정할 수 있다. 인덱스를 설정해 놓으면 특정 조건에서 어마어마하게 빠른 속도로 원하는 레코드를 찾을 수 있다. 거의 O(n)과 O(logn)의 차이이다.
예를 들어 레코드가 1억 개인 테이블에서 인덱스 없이 검색하면 검색 연산을 1억 번 해야 하지만, 인덱스를 갖고 검색을 하면 몇십 번 이내에 검색이 끝난다.
균형 잡인 트리 구조와 트리 깊이의 대수확장성
인덱스는 select 구문, 즉 검색만을 위한 것은 아니다. 기존 레코드를 변경하거나 레코드를 삭제할 때도 인덱스는 빨리 찾는 데 큰 도움이 된다.
해당 연산을 수행하려면 해당 대상을 조회해야만 작업을 할 수 있기 때문이다.
delete from table1 where a=100예를 들어 위 구문을 실행하면 table1에 있는 모든 레코드를 다 순회하면서 a=100인 것을 찾지 않고, 인덱스를 이용해서 a=100인 것을 매우 적은 횟수의 순회만으로도 다 찾아내서 지울 것이다.
DB에서 자료를 검색하는 두 가지 방법
- FTS(Full Table Scan)
테이블을 처음부터 끝까지 검색하는 방법- Index Scan
인덱스를 검색하여 해당 자료의 테이블을 액세스하는 방법
인덱싱을 위한 내부 구조
인덱스는 추가적인 쓰기 작업과 저장 공간을 활용하여 데이터베이스의 테이블 검색 속도를 향상 시키기 위한 자료구조로 이루어졌다. DB의 테이블에서 모든 데이터를 검색하면 시간이 오래 걸리기에 데이터와 데이터의 위치를 포함한 자료구조를 생성하여 빠르게 조회할 수 있도록 한다.
1. 해시 테이블 기반
=> "동등 비교 조건(==)"을 갖는 검색에 유리
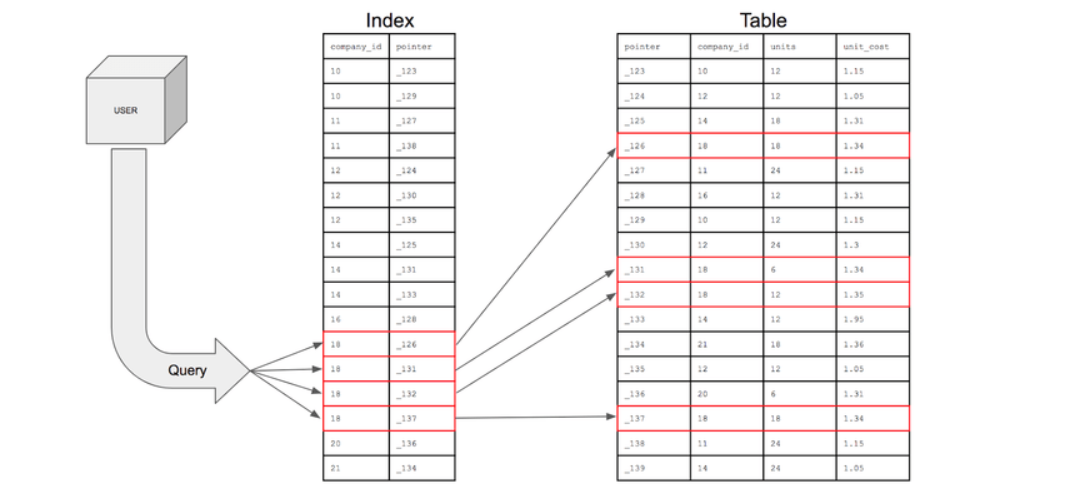
source: https://mangkyu.tistory.com/96
해시 테이블 기반의 DB 인덱스는 (인덱스를 적용한 필드의 값, 데이터 위치)를 (Key, Value)로 사용하여 필드 값을 해시 함수에 전달하여 반환된 해시 값을 통해 인덱스를 구현한다.
- 인덱스 구성 방법
- 인덱스 구성에 사용될 검색 키 필드 결정
- 레코드의 필드 값에 해시 함수를 적용하여 버켓 번호(해시 값) 생성
- 인덱스 엔트리({key: 필드 값, value: 레코드 주소} 쌍)를 생성하여 해당 버켓에 저장
- ex) {employ_id: 18, 테이블 필드 포인터} // {키, 값}
- 인덱스 사용 방법
- 검색할 필드 값을 해시 함수에 적용하여 버켓 번호 생성
- 해당 버켓 안에 들어 있는 인덱스 엔트리에 포함된 레코드 주소 이용
- 체인법을 적용한 해시 테이블의 경우 특정 필드 값에 매핑된 엔트리가 여러 개 있을 수 있음
- 해시 테이블 기반의 인덱스 특징
- 해시가 등호(=) 연산에만 특화되어있음
- 부등호 연산(>, <)이 자주 사용되는 DB 검색을 위해서는 적합하지 않음
2. B-트리 기반
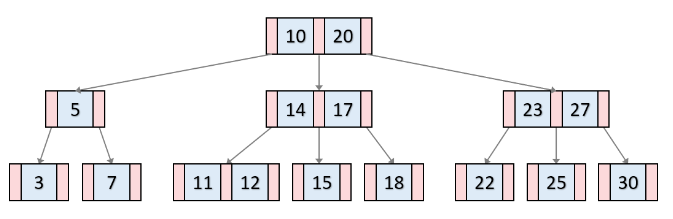
source: https://velog.io/@emplam27/%EC%9E%90%EB%A3%8C%EA%B5%AC%EC%A1%B0-%EA%B7%B8%EB%A6%BC%EC%9C%BC%EB%A1%9C-%EC%95%8C%EC%95%84%EB%B3%B4%EB%8A%94-B-Tree
예를 들어 '12를 찾는다고 할 때 전체 테이블을 탐색하는 것이 아니라 12가 있을 법한 리프 노드({11, 12})로 들어가서 12 쉽게 찾는 것이다.
위 그림의 자료구조에서 12를 탐색하고자 하면 {10, 20} -> {14, 17} -> {11, 12} 순으로 루프 노드, 하나의 브랜치 노드, 그리고 리프 노드로 3번만에 내려올 수 있다. 물론 각 노드에서 어느정도의 순차 탐색 오버헤드가 추가된다.
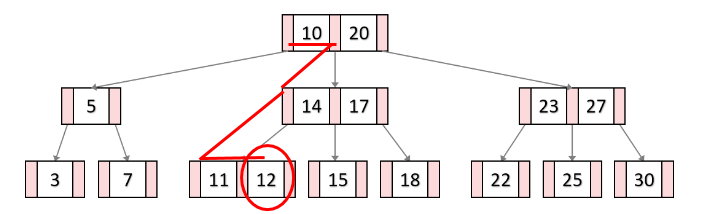
균형 잡힌 트리의 대수확장성
균형 잡힌 트리 구조와 트리 깊이의 대수확장성을 통해 효율적으로 검색이 가능하다.
대수확장성이란 트리 깊이가 리프 노드 수에 비해 매우 느리게 성장하는 것을 의미한다. 기본적으로 인덱스가 한 깊이씩 증가할 때마다 최대 인덱스 항목의 수는 4배씩 증가한다.
3. B+트리 기반
범위 조건을 포함한 검색에 유리
B+트리는 DB의 인덱스를 위해 자식 노드가 2개 이상인 B-트리를 개선시킨 자료구조이다. B+트리는 모든 노드에 데이터를 저장했던 B-트리와 다른 특성을 가진다.
- 리프노드(데이터 노드)만 인덱스와 함께 데이터를 가지고 있고, 나머지 노드(인덱스 노드)들은 데이터를 위한 인덱스(Key)만을 갖는다.
- 리프노드들은 Linked-List로 연결되어 있다.
- 데이터 노드 크기는 인덱스 노드의 크기와 같지 않아도 된다.
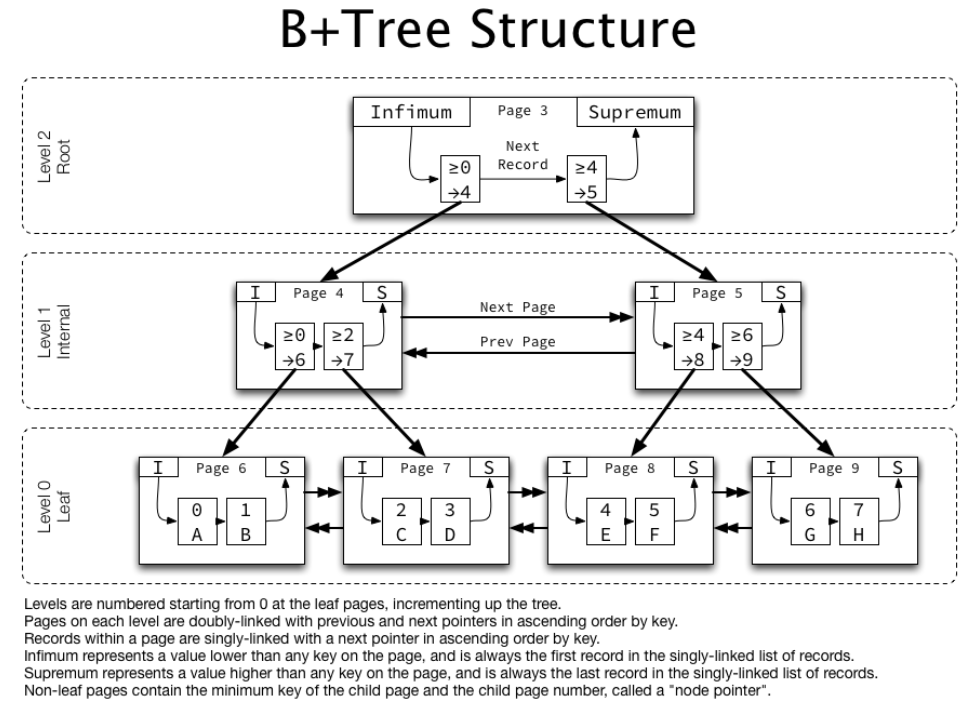
source: https://mangkyu.tistory.com/96
DB 인덱스 컬럼은 부등호를 이용한 순차검색 연산이 자주 발생될 수 있다. 이러한 이유로 B-트리의 리프노드들을 Linked-List로 연결하여 순차검색을 용이하게 하는 등 B-트리를 인덱스에 맞게 최적화하였다.
이러한 이유로 비록 B+트리는 O(logn)의 시간 복잡도를 갖지만 해시 테이블보다 인덱싱에 더욱 적합한 자료구조가 되었다.
정리하자면,
해시 테이블 기반 인덱스
-> 동등 비교 조건(=)을 갖는 검색에 유리
해시 함수를 통해 직접 인덱스 엔트리를 포함한 버켓을 찾음
B+트리 기반 인덱스
-> 범위 조건을 포함한 검색에 유리
단만 노드의 엔트리들이 검색 키 순서대로 정렬 및 연결되어 있음
인덱스 추가하기
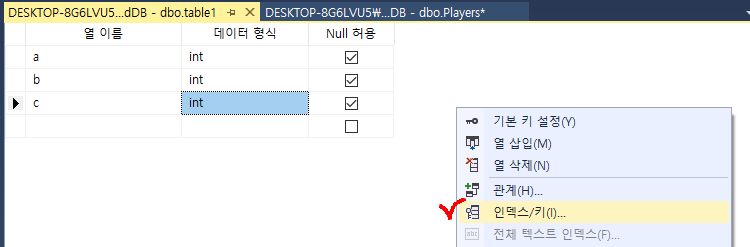
테이블 우 클릭 => "디자인(G)" => 디자인 창 우클릭 => "인덱스/키(I)" 클릭
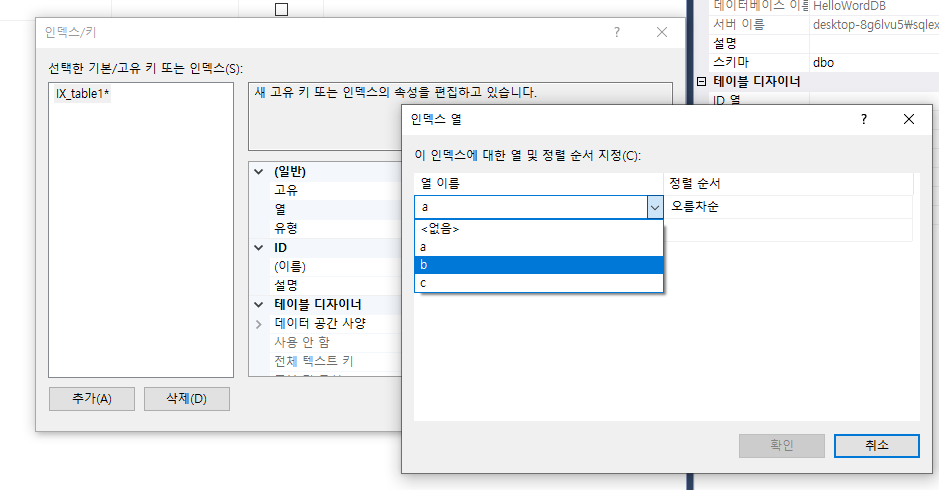
인덱스에 대한 열 및 정렬 순서 지정하면 된다.
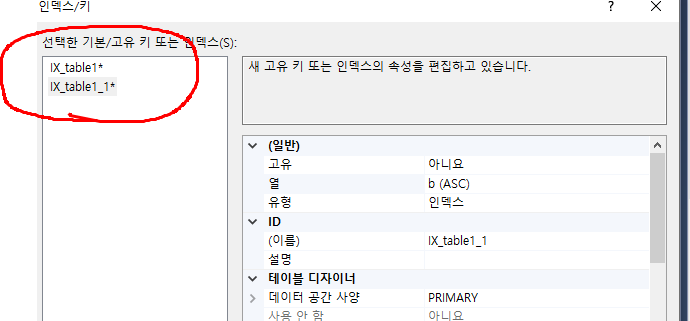
테이블 하나에 인덱스를 2개 이상 넣는 것도 가능하다. 예를 들어 table1의 필드 a, b, c 각각에 인덱스를 추가할 수 있다.
인덱스 생성 질의 구문
CREATE INDEX table1_myindex ON table1 (a ASC)
인덱스의 '유니크(unique)' 속성
인덱스는 빠른 검색 용도뿐만 아니라, 중복된 값을 방지하는 용도로도 사용한다. 인덱스에는 유니크라는 속성을 추가로 지정할 수 있다. 이 유니크 속성을 추가한 인덱스, 즉 유니크 인덱스가 있을 때, 인덱스에 해당하는 필드 값이 같은 레코드가 2개 이상 들어갈 수 없게 막아주는 역할을 한다.
예를 들어 table1의 필드 a에 유니크 인덱스가 설정되면, 다음과 같이 a=100인 레코드를 여럿 추가할 때 두 번째 추가 질의 구문에서 실패가 발생한다.
insert into table1 (a,b,c) values (100,200,300)
insert into table1 (a,b,c) values (100,210,310)
- 기본키 <- 유니크 인덱스
- 외래키 <- 논-유니크 인덱스
인덱스 관리와 단점
DBMS는 인덱스를 항상 최신의 상태로 유지시킨다.
데이터의 수정, 삽입, 삭제 시 인덱스와 관련된 추가적인 연산이 필요하기에 오버헤드가 발생한다.
- INSERT: 새로운 데이터에 대한 인덱스 추가
- DELETE: 삭제하는 데이터의 인덱스를 사용하지 않는다는 작업을 진행
- UPDATE: 기존의 인덱스를 사용하지 않음 처리하고, 갱신된 데이터에 대한 인덱스를 추가함
인덱스의 단점
인덱스가 걸쳐 있는 레코드에 변화가 일어날 때, 인덱스도 같이 업데이트해야 한다. 인덱스가 없을 때보다 기록할 때 더 많은 시간이 걸린다. 따라서 필요하지 않은 인덱스는 가급적 걸지 않는 것이 좋다.
(1) 추가적인 저장공간 필요: 인덱스를 관리하기 위해 DB의 약 10%에 해당하는 추가적인 저장공간이 필요하다.
(2)인덱스 관리로 인한 오버헤드: 인덱스 관리를 위한 추가적인 작업과 그에 따른 오버헤드가 발생한다.
인덱스를 잘못 사용할 경우 오히려 성능이 저하되는 역효과가 발생할 수 있다. 만약 CREATE, DELETE, UPDATE가 빈번한 속성에 인덱스를 걸게 되면 인덱스의 크기가 비대해져서 성능이 오히려 저하되는 역효과가 발생할 수 있다. 그러한 이유 중 하나는 DELETE와 UPDATE 연산 때문이다. 앞에서 설명한대로, UPDATE와 DELETE는 기존의 인덱스를 삭제하지 않고 '사용하지 않음' 처리를 해준다고 하였다. 만약 어떤 테이블에 UPDATE와 DELETE가 빈번하게 발생된다면 실제 데이터는 10만건이지만 인덱스는 100만 건이 넘어가게 되어, SQL문 처리 시 비대해진 인덱스에 의해 오히려 성능이 떨어지게 될 것이다.
인덱스를 사용하면 좋은 경우
- 규모가 작지 않은 테이블
- INSERT/UPDATE/DELETE가 자주 발생하지 않는 컬럼
- JOIN이나 WHERE(탐색 필요) 또는 ORDER BY(정렬 필요)에 자주 사용되는 컬럼 => 주로 key 필드
- 데이터의 중복도가 낮은 컬럼
- 기타 등등

I was looking for more information about nightlife in Suwon and found this discussion helpful. It’s sometimes difficult to find clear guides that explain the 분위기 and overall experience.
While searching, I also came across 수원가라오케 which provides a helpful overview for people visiting the area for the first time. Sharing in case others are also looking for Suwon nightlife information.