reference: "프로그래머가 몰랐던 멀티코어 CPU 이야기" / 김민장, "Computer System A Programmers'Perspective" / 랜달 E.브라이언트
이상적인 파이프라인은 투입되는 작업 간에 서로 의존성이 없음을 가정한다. 그러나 실제 프로그램은 그렇지 않다. 명령어 사이에는 데이터 의존성, 컨트롤 의존성, 메모리 의존성이 있다.
데이터 의존성: https://velog.io/@jinh2352/%EC%BB%A8%ED%8A%B8%EB%A1%A4-%EC%9D%98%EC%A1%B4%EC%84%B1Dependency
컨트롤/메모리 의존성: https://velog.io/@jinh2352/%EC%BB%A8%ED%8A%B8%EB%A1%A4-%EC%9D%98%EC%A1%B4%EC%84%B1-%EB%A9%94%EB%AA%A8%EB%A6%AC-%EC%9D%98%EC%A1%B4%EC%84%B1
따라서 명령어를 처리하는 파이프라인은 앞서 말한 이상적인 가정을 만족시킬 수 없고, 명령어 사이의 의존성을 최대한 잘 해결해야 파이프라인 비효율도 줄이고 정확한 실행을 보장할 수 있다.
파이프라인 프로세서에서 의존성으로 발생할 수 있는 문제를 파이프라인 해저드(hazard)라 한다. 가장 간단한 해결 방법은 해저드가 발생할 때마다 파이프라인을 멈추는 것(stall)이다. 그러나 이는 비효율적이다. 해저드에는 구조 해저드, 데이터 해저드, 컨트롤 해저드가 있다.
구조 해저드(structural hazard)
구조 해저드란 프로세서의 자원이 부족해서 발생하는 stall을 가리킨다. 해결책은 간단한데 자원을 늘리면 된다.
일반적으로 파이프라인화할 때 필요한 컴포넌트의 추가 비용을 생각해보면, 레지스터 파일과 메모리 장치는 구조 해저드를 발생시키지 않게 업그레이드 되어야 한다. 파이프라인이 k단계라고 한다면 최대 k개의 명령어가 동시에 프로세서의 각각 다른 파이프라인에서 처리된다. 그런데 최악의 경우, 파이프라인이 stall 없이 작동하려면 레지스터 파일, ALU, 메모리 같은 장치들이 최대 k개의 명령어를 감당할 수 있어야 한다.
레지스터 파일의 경우, ALU 명령어는 보통 두 개의 인자를 레지스터 파일에서 읽고 최종 결과 하나를 쓴다. 비파이프라인화 프로세서라면 읽기와 쓰기가 동시에 일어나지 않는다. 그런데 파이프라인 프로세서에서는 피연산자를 읽는 OF 단계에 있는 명령어와, 최종적으로 결과를 쓰는 OS(또는 WB) 명령어가 동시에 작동하므로 레지스터 파일은 반드시 최대 두 개의 읽기와 한 번의 쓰기가 동시에 가능해야 하며, 또 이 작업이 사이클마다 가능하게 지원해야 한다. 레지스터 파일에 많은 읽기와 쓰기를 동시에 처리하도록 하는 것(멀티 포트화)은 매우 어렵다. 반도체 설계 공간도 전력도 모두 많이 소비하게 된다. 캐시 및 메모리 장치도 같은 문제가 있다. 대안으로 아주 큰 하나의 레지스터 파일이나 캐시에 많은 수의 읽기/쓰기 포트를 제공하는 것보다 적은 수의 읽기/쓰기 포트를 가지는 작은 크기의 컴포넌트를 여러 개 두는 방법을 쓴다.(이 단위를 캐시에서는 뱅크(bank), 레지스터 파일은 클러스터(cluster)라 부름)
컨트롤 해저드(control hazard)
구조 해저드는 하드웨어 제약으로 발생한 문제였다면 컨트롤/데이터 해저드는 프로그램이 근본적으로 갖는 의존성 때문에 발생한다. IF 단계에서는 PC가 가리키는 주소에서 명령어를 읽어야 하는데, 다음 PC를 구하는 작업은 분기문으로 쉽지 않다.
1: if (z > 0) goto 4;
2: a = 1;
3: goto 5;
4: a = 0;
5: x = y + z; // 이 명령은 명령 1~4와 무관위 소스에서 1번 조건 분기문을 구하지 않고서는 2번 명령 아니면 4번 명령을 인출할지 알 수 없다. 즉 파이프라인은 분기문의 결과가 나올 때까지 기다려야 한다. 이전에 정의한 다섯 단계의 파이프라인 단계에서, EXE 단계를 지나면 분기문의 결과를 알 수 있어 다음 명령이 진행된다.
많은 stall이 발생하게 됨을 직관적으로 생각할 수 있다. 이러한 stall을 조금 에방할 수 있는 방법은,
(1) 분기문 계산을 EXE가 아닌 OF 단계에서 바로 하게 하는 법 => 그래도 파이프라인 stall은 하나밖에 줄일 수 없음
(2) 분기문의 결과와 상관없는 명령 5를 미리 실행시키기, 명령어 재배치(컴파일러가 수행) => 이 기법도 완벽하지는 않음. 실제 프로그램 순서와 다르게 완료되므로 프로그래머에게 혼동을 줄 수 있을 뿐 아니라 무엇보다 완벽히 파이프라인 stall을 제거할 수 없음.
(3) 분기 예측(branch prediction): 분기 또는 분기 하지 않는 다고 가정하고, 그에 따른 명령어를 예측에 기반해 인출한다. 분기문의 결과가 나오지 않아도 분기문의 분기 여부를 미리 예측해 파이프라인을 진행시키는 것. 이 예측이 옳으면 큰 성능 향상으로 이어지고 파이프라인 stall이 발생하지 않는다. 반면 분기 예측이 틀리면 파이프라인을 비우고 다시 진행해야함.
데이터 해저드(data hazard)
데이터 해저드는 RAW/WAW/WAR 데이터 의존성과 메모리 의존성으로 발생한다.
이전 파이프라인 5단계를 좀 더 세분화하여 설명을 돕는다. 앞서 정의한 OF(피연산자 인출) 단계는 지나치게 단순하다. 피연산자는 레지스터일 수도 있고, 메모리에 있는 데이터일 수도 있다. 논리적으로 피연산자를 읽는 것이지만 실제 다른 두 장치에 접근하므로 상당히 다른 연산을 포함하는 셈이다. 따라서 이 둘을 분리해 총 6단계의 파이프라인 단계를 구성해 가정한다.
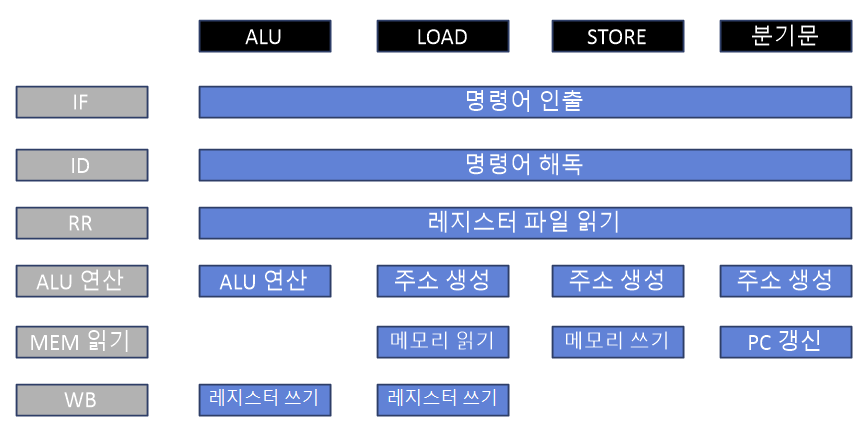
위 그림의 파이프라인은 메모리 읽기 단계(MEM)를 분리했다. 단, 모든 연산 종류가 이 과정을 거치는 것은 아니다. 메모리 로드와 스토어는 레지스터 파일 읽기 단계에서 베이스 주소나 오프셋 값을 읽고, ALU 단계에서 주소를 계산해 만든다. 각 명령어마다 파이프라인 단계가 다르고 그 의미도 차이난다.
// r: 레지스터
1: r1 = r2 + 1;
2: r3 = r1 + 1; // r1에 대해 RAW 의존성
3: r4 = r1 + 2;
4: r5 = r1 + 3;
2, 3, 4번 명령은 1번 명령에 RAW 의존성을 가진다. 파이프라인이 아무런 고려도 하지 않으면 역시 stall을 겪을 수 밖에 없다. 명령 1의 결과는 WB가 완료되어야 레지스터 파일에 최종 r1을 저장한다. 명령 2가 그냥 진행되면 최신 r1 값을 읽지 못하므로 정확한 결과를 얻지 못한다. 그러므로 명령 2의 레지스터 읽기 단계 RR은 명령 1의 WB 단계 이후로 늦춰져야 한다. 명령 3도 명령 1이 WB를 마칠 때까지 기다려야 하나, 명령 2와의 구조 해저드(자원 관련)로 역시 3 사이클을 쉬어야 한다.
그런데 살펴보면 명령 2가 명령 1이 WB를 마칠 때까지 꼭 기다릴 필요는 없다. 만일 명령 1이 ALU 단계에서 덧셈한 결과를 바로 명령 2로 전달하면 파이프라인 stall을 막을 수 있다. 이런 기법을 바이패스(bypass, 우회로)라 부른다. 명령 2는 데이터 해저드가 있을 때, 레지스터 파일에서 값을 읽지 않고, 바이패스에서 오는 값을 바로 취해 ALU 연산을 수행한다. 바이패스는 데이터 해저드를 해결하는 아주 중요한 장치이다.
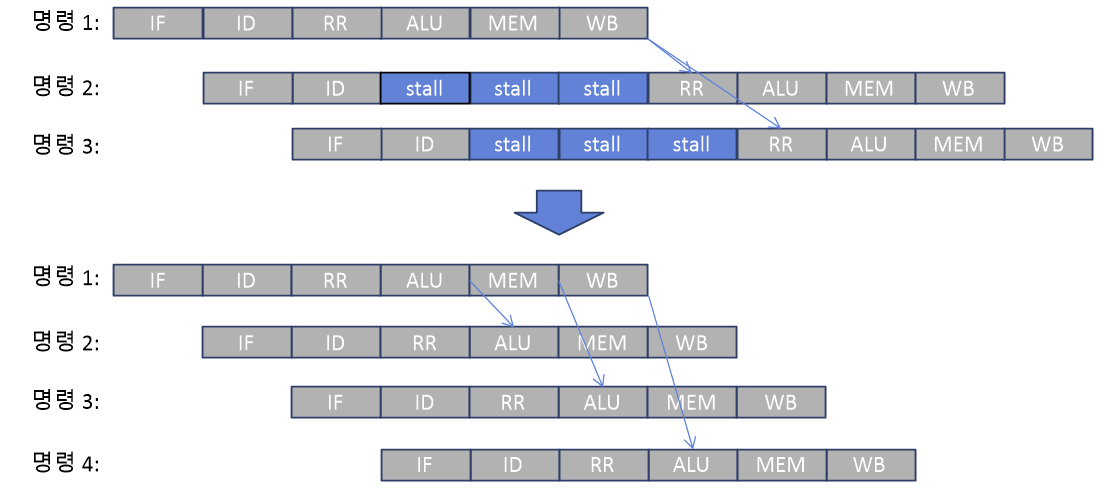
명령 1과 명령 3, 4 사이에도 바로 ALU 대 ALU 바이패스를 만들지 않은 이유는 시간적으로 2~3 사이클 간격이 있기 때문이다. 이 단계에서 바이패스를 만들려면 별도의 버퍼에 담아 명령 3, 4가 쓸 때까지 저장해야 하는 어려움이 있다. 바로 다음 파이프라인 단계로 임시 결과를 전하는 것이 바이패스 로직을 만들기에 용이한다.

명령어들이 바로 뒤따르면서 RAW 해저드를 가질 때, 이런 명령어를 흔히 백투백(Back-to-Back) 의존성을 가진 명령어라 부른다. 파이프라인을 설계할 때는 반드시 백투백 명령어가 stall 없이 처리되게 파이프라인 단계와 바이패스 로직을 만들어야 한다. WAW/WAR 의존성은 지금 다루는 파이프라인 구조에서는 해저드를 만들지 않는다. 그래서 WAW/WAR을 유발하는 명령어 사이에서 최종 결과를 쓰는 작업은 늘 마지막 파이프라인 단계이므로 실제로는 해저드를 만들지 않는다.
이와 비슷하게 메모리 로드로 인한 RAW 의존성도 해저드를 만든다. 특별히 이 해저드를 로드-유스(Load-Use) 데이터 해저드로 부른다.

명령 1은 메모리 로드 연산(memory-load)dlrh, 명령 2와 3은 명령 1에 대해 RAW 의존성을 가짐.
메모리 로드는 ALU 단계가 아닌 MEM 단계가 되어야 비로소 값을 읽어올 수 있다. 그런데, 뒤따르는 명령 2는 ALU 단계에서 이 값이 필요함. 따라서 파이프라인 구조에서는 바이패스를 이용해도 어쩔 수 없이 파이프라인stall이 하나 발생된다.
파이프라인 해저드 정리
하드웨어 자원이 부족해서, 또는 프로그램에 있는 의존성으로 파이프라인은 항상 진행하지 못하고 stall을 겪게 된다. 하드웨어 장치를 더 두거나 바이패스 로직과 분기 예측으로 최대한 stall을 줄이려 노력한다.
결론
파이프라인이 레이턴시를 개선하지는 못하지만 처리율은 크게 향상시킬 수 있는 일반적인 기술로 현대 프로세서의 기본 기술이다. 파이프라인이 이상적인 성능을 얻으려면 균형있게 파이프라인 단계와 깊이를 결정해야 한다. 명령어 파이프라인은 특히 처리하는 명령어 사이에 의존성이 있으므로 각종 해저드가 발생했다. 여러 기법을 동원하여 파이프라인 해저드로 인한 stall을 최소화한다. 파이프라인은 결국 파이프라인 단계가 동시에 작동한다는 점에서 병렬 프로그램 기법(S/W적 최적화 by 파이프라인 기법)으로도 활용된다.
