base/limit 레지스터 기반 연속 할당의 문제점
주소 공간의 중간 부분에 큰 덩치의 "free" 공간이 있다. 이 공간은 사용되지 않지만 프로세스가 실행하면서 물리 메모리 공간을 차지하는 부분이다. 이 부분은 결국 낭비되는 공간인 셈이다.
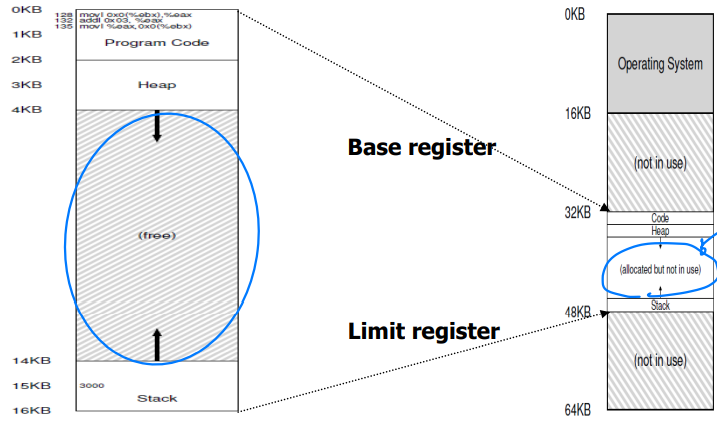
이에 따라 전체 주소 공간을 물리 메모리가 수용할 공간이 부족하다면 프로세스가 동작하기 어려워 진다.
이러한 연속 할당의 문제점을 불연속 할당 기법을 통해 해결할 수 있다.
Segmentation
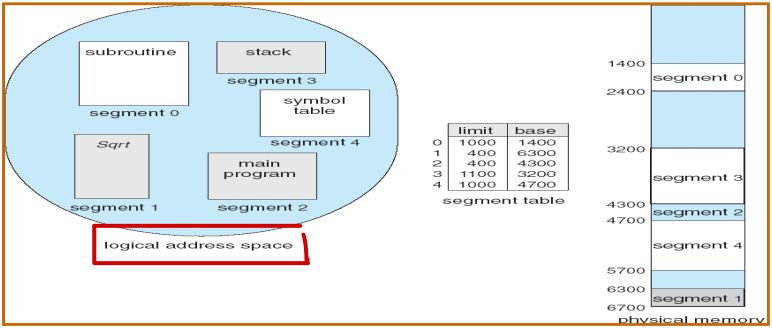
프로그램을 다수의 세그먼트로 나눈다.
이때 각 세그먼트는 주소 공간에서 연속적인 부분이다.
주소 공간은 크게 아래와 같은 세그먼트들로 나뉘어 질 수 있다.
- code segment
- data segment
- stack segment
- heap segment
그리고 앞서 말하였듯, 각 세그먼트는 연속적인 부분이기에 세그먼트 마다의 base/limit 값이 필요하고, 이러한 값들을 HW적으로 저장하는 것이 세그멘테이션 관련 레지스터이다(MMU에 존재).
Code segment, Base: 32K, Size: 2K (size는 가변적)
Heap segment, Base: 32K, Size: 2K
StaCK segment, Base: 28K, Size: 2K
Segmentation 기법에서의 주소 변환

case 1)
가상 주소 100(ex, PC)
=> 물리 주소: 32K(base) + 100(offset)
case 2)
가상 주소: 4200 = 4k(4096) + 104
=> 물리 주소: 34k(base) + 104(offset)
case 3)
가상 주소: 7000(heap 영역)
=> offset = 7000 - 4k
=> offset > heap size(2k)
=> segmentation fault
세그먼트 인코딩 (in virtual address)
- 세그먼트 번호 부분 + 오프셋 부분
예시를 들기 전 아래와 같은 가정이 있다.
1) 주소 공간의 크기: 16KB = 2^14B
-> 14bit로 표현한다.
2) 세그먼트의 갯수는 3개로 가정(code/heap/stack)
-> 2bit로 표현한다.
3) 남은 12bit가 세그먼트 내 오프셋이 될 수 있다.
-> 결국 한 세그먼트의 최대 크기는 4KB이다.
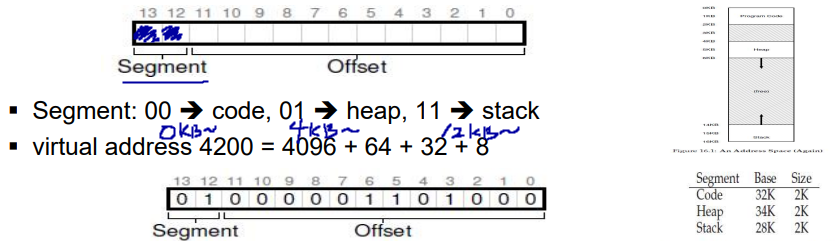
세그먼트 번호는 해당 세그먼트의 base 레지스터를 찾기 위해 사용된다.
오프셋은 base 레지스터의 값에 더해 물리 주소를 산출하는 데 사용되며, 만약 더한 결과가 limit 레지스터이 값보다 크면(또는 offset이 세그먼트 크기보다 크면) 세그멘테이션 폴트가 발생하게 된다.

세그먼트 크기 이슈
Coarse-grained(big)
예들 들어 code/data/heap/stack과 같이 네 가지의 세그먼트들로만 주소 공간을 구성한다면 관리하는 세그먼트 숫자가 적어지게 되고, 이는 레지스터들로만 관리가 가능하다는 것이다.
하지만 큰 단위의 세그먼트기에 유연성이 떨어진다는게 단점이다.
Fine-grained(small)
세그먼트 갯수가 많아짐에 따라 '테이블'로써 보통 관리된다.
좀더 유연하다는게 장점이다.
예를 들어 code 세그먼트를 1/2로 나누고, heap을 1/2, data를 1/2/3, stack을 1로 둔다면 8개의 세그먼트로 주소 공간을 구성하는 셈이다.
OS responsibilities
-
문맥교환: save/restore 세그먼트 관련 레지스터
-
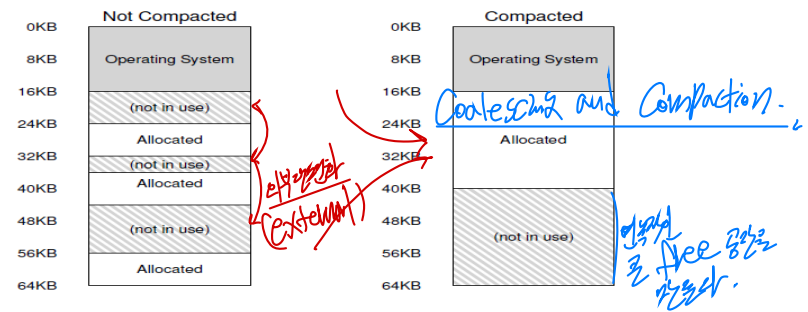
free space 관리
외부 단편화(external fragmentation)를 줄이기 위한 기법 추가
-> 'coalescing and compaction'
세그멘테이션 기법의 장점
1) 다양한 프로세스들 간의 공유가 가능하다
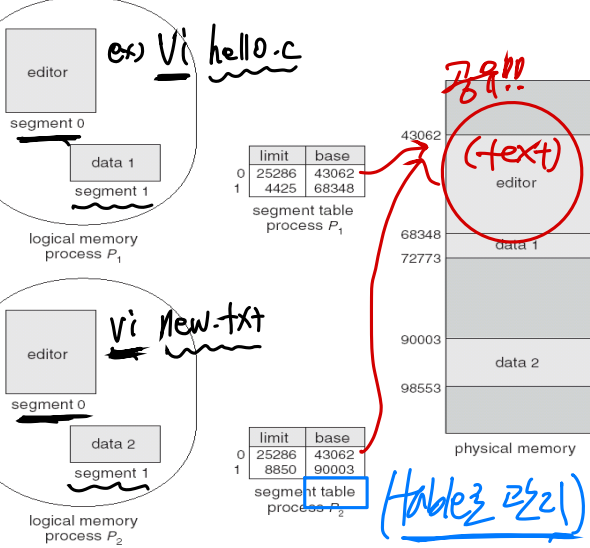
2) 세그먼트 단위의 보호 지원

세그멘테이션 기법의 단점
1) 가변 크기
가변 크기를 하드웨어에서 구현하는 것은 고정 크기보다 상대적으로 어렵고, 외부 단편화를 유발하기 쉽다. 이는 free space 관리를 복잡하게 한다.
반대로 연속 할당 기법은 내부 단편화를 쉽게 유발한다.
2) 큰 사이즈의 세그먼트
큰 사이즈의 세그먼트는 여전히 물리 메모리 상에서 낭비되는 공간을 만든다. 이를 위해 프로세스가 실제로 사용하는 주소 공간에 세그먼트로 나눈다.
세그멘테이션 기법의 단점을 보완하는 Paging 기법이 있다.
