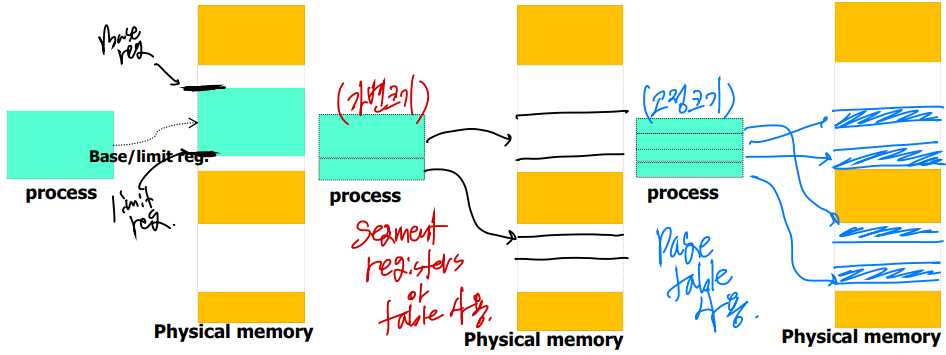
연속 할당(base/limit) vs 불연속 할당의 세그멘테이션 기법 vs 불연속 할당의 페이징 기법
세그멘테이션 기법과 페이징 기법은 둘 다 불연속 할당 방식인데, 세그멘트는 가변 크기를 가지고, 페이징은 고정 크기를 가진다.
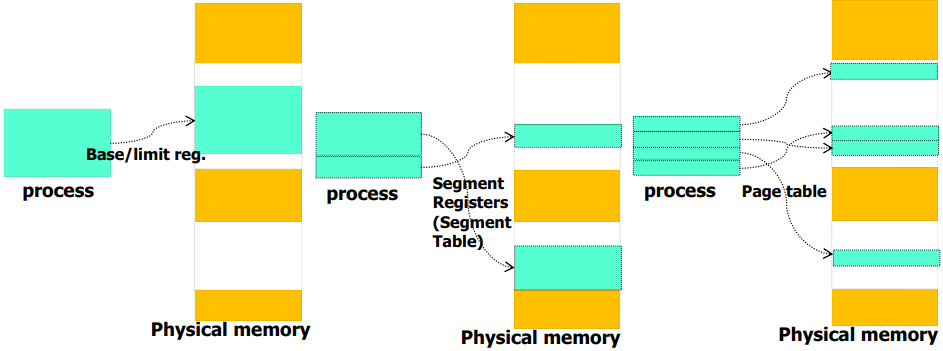
페이징 기법의 도입 이유
메모리 공간이 가변 크기의 세그멘트로 할당과 반환이 이루어지면 외부 단편화가 심해져 할당 작업에 있어 어려움이 점점 더 커진다. 이에 spliting, coalesing, compation과 같은 추가적인 작업이 필요하다.
하지만 고정된 크기의 불연속 할당이 이루어지면 이러한 외부 단편화 문제가 해결되며, TLB와 같은 HW 지원을 쉽게 받을 수 있다.
용어
- 주소 공간(virtual memory)를 나누는 고정된 크기를 페이지(page)라 한다.
- 물리 메모리를 나누는 고정된 크기는 페이지 프레임(page frame, 또는 그냥 frame)이라 한다.
- 주소변환은 페이지 테이블을 통해 이루어진다.
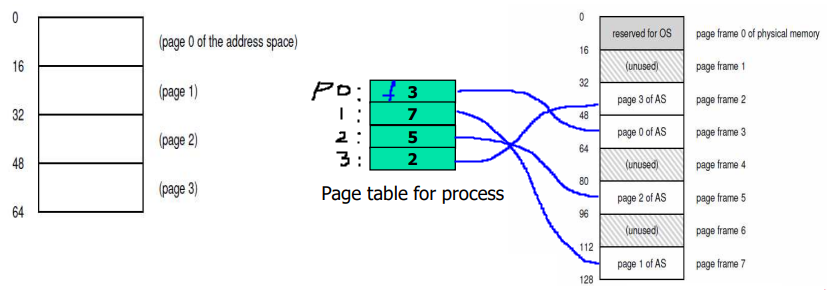
페이징 예시
다음과 같이 가정한다. 각 프로세스에게 할당되는 주소 공간의 크기는 64(2^6)B이고, 페이지의 크기는 16(2^4)B이다. 즉 주소 공간은 4개의 페이지로 나뉜다.
물리 메모리의 크기는 128(2^7)B이고, 페이지 프레임의 크기는 16(2^4)B이다. 즉 물리 메모리 공간은 8개의 페이지 프레임으로 나뉜다.

현재 0번째 프레임(프레임0)은 OS의 커널에 할당되었고, 2,3,5 그리고 7번째 프레임이 프로세스에 할당되었다. 나머지 프레임은 OS가 관리하는 free-list(bit map or list)에 의해 관리된다.
페이지 테이블
페이지 테이블은 물리 메모리의 프레임과 가상 메모리의 페이지의 맵핑 관계를 기록한 자료구조이다. 이 페이지 테이블은 프로세스 각각이 개별적으로 참조한다(task의 문맥).
예를 들어 하나의 프로세스가 페이지 테이블을 참조할 때 주소 변환이 아래와 같이 이루어진다.
주소 공간의 크기는 64B이므로 6bit로 표현될 수 있다. 물리 메모리의 크기는 128B이므로 7bit로 표현될 수 있다.
6bit로 표현되는 가상 주소는 VPN(Virtual Page Number, 2bit)와 offset(4bit)로 이루어져 있다. 여기서 VPN은 페이지 테이블을 탐색하는데 사용하고, 이를 바탕으로 PFN(Physical Frame Number)을 찾을 수 있다.
페이지 테이블 검색을 바탕으로 아래와 같은 주소 변환을 할 수 있다.
"VPN / offset => PFN x pageSize + offset"
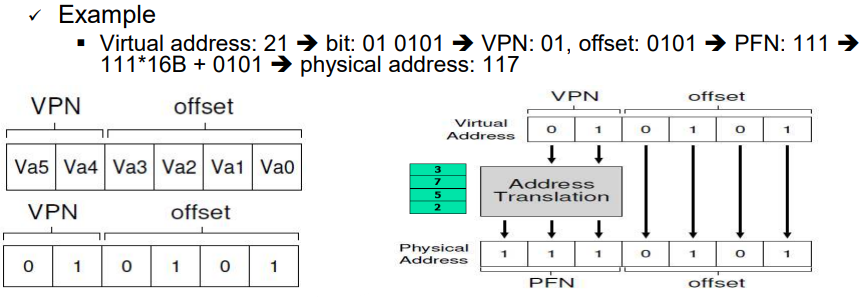
정리하자면, 가상 주소는 두 파트로 나눌 수 있고, VPN과 offset이다. VPN은 페이지 테이블의 인덱스 역할을 하고, offset은 해당 페이지 내의 상세 위치이다.
각각의 페이지 테이블 엔트리는 맵핑되는 프레임의 번호 또는 해당 프레임의 시작 주소(물리적)을 가지고 있다. 이를 offset과 결합하여 물리 메모리 상 주소를 산출할 수 있다.
페이지 테이블은 어떻게 관리되는가?
페이지 테이블은 앞서 말했듯 각 프로세스마다 독립적으로 관리된다.
커널 공간 속 개별 프로세스 관리를 위한 자료구조인 PCB(or task_struct)에서 관리되는 자료구조이다.
PTE(Page Table Entries)
페이지 테이블에서 인덱싱 될 수 있는 엔트리를 PTE, 페이지 테이블 엔트리라 한다. 이 PTE는 맵핑되는 프레임 정보외에도 추가적인 정보를 비트 단위로 담고 있다.

- P (Present bit): whether this page is in physical memory or on disk (swap out)
- R/W (Read/Write bit): Whether writes are allowed to this page
- U/S (User/Supervisor bit): if user-mode processes can access the page
- A (Access bit, a.k.a. reference bit): for replacement
- D (Dirty bit): whether the page has been modified
- Others
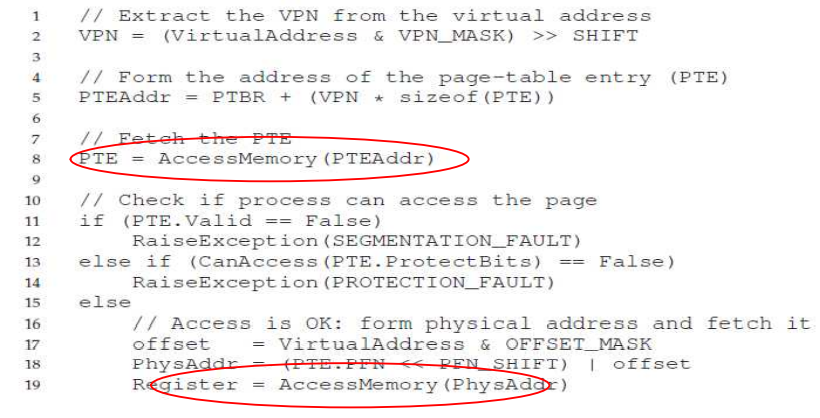
추가 비트를 포함한 주소 변환 Pseudo code
페이징 기법에서의 2가지 이슈
-
메모리 접근을 어떻게 하면 줄일 수 있을까? => TLB 활용
각 메모리 접근 요청은 주소 변환을 수반한다. 주소 변환은 페이지 테이블의 참조가 필요하며, 결국 메모리 상에 존재하는 페이지 테이블에 접근해야 한다. 이는 필요로 하는 메모리 접근 외 추가적인 메모리 접근을 수반한다는 것이다.
이러한 메모지 접근 오버헤드를 TLB라는 HW적 지원을 통해 줄일 수 있다.
-
고정 크기 할당 기법은 더 큰 맵핑 정보(페이지 테이블)를 요구하게 된다. 이 맵핑 정보를 더 작게 하여 메모리를 절약할 수 있을까? => multi-level page table or inverted page table
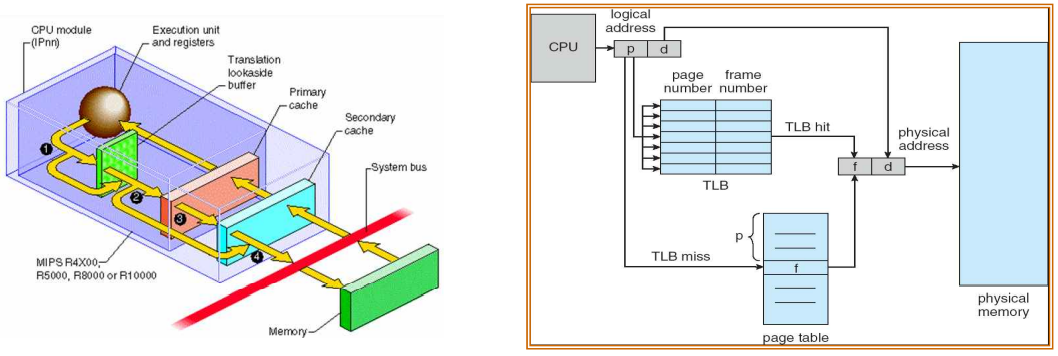
TLB(Translation Lookaside Buffer): for faster translations
TLB는 MMU의 파트들 중 하나이다. 페이지 테이블 참조를 위한 추가적인 메모리 접근 오버헤드를 낮추기 위해 활용된다.
이 TLB는 최근에 사용한(recent used) PTE에 대한 캐시라 할 수 있다. => '주소 변환 캐시(an address-translation cache)'
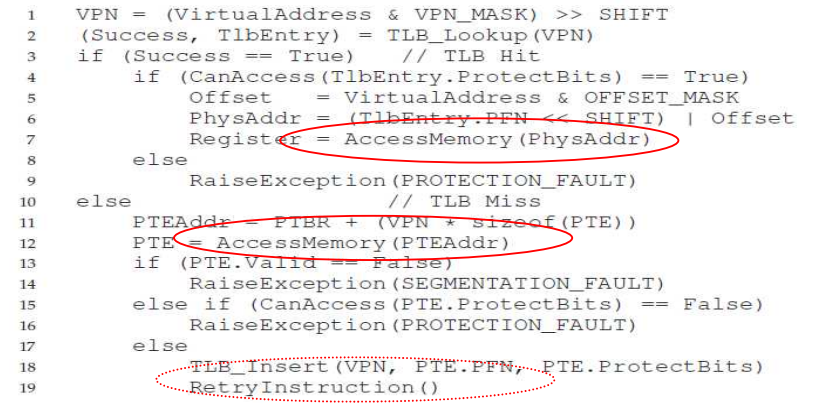
TLB가 포함된 주소 변환 프로세스는 다음과 같다.
1) HW first check TLB
2-1) 만약 TLB hit라면, 페이지 테이블 참조 없이 빠르게 주소 변환을 수행한다.
=> 한 번의 메모리 접근이 이루어짐(요청 데이터 공간 접근)
2-2) 만약 TLB miss라면, 페이지 테이블을 참조하고, 사용된 PTE 정보를 TLB에 갱신한다.
=> 두 번의 메모리 접근이 이루어짐(페이지 테이블 접근 + 요청 데이터 공간 접근)
TLB 포함 주소 변환 process pseudo code
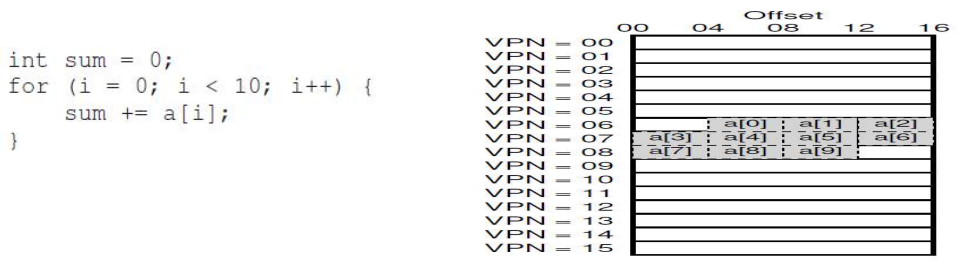
지역성(Locality) 특성을 고려하면, 대부분의 메모리 접근에 있어 TLB hit 비율이 높다.
공간적 지역성(spatial locality)
- Access
a[0]-> TLB miss -> 두 번의 메모리 접근 + TLB 갱신- Acess
a[1] ~ a[2]-> TLB hit -> 한 번의 메모리 접근- Acess
a[3] or a[7](서로 다른 페이지)-> TLB miss -> 두 번의 메모리 접근 + TLB 갱신
Advanced Page Tables: Multi-level Page Table
페이지 테이블 참조와 관리에 관련한 문제는 크게 추가되는 메모리 접근 오버헤드와 테이블 그 자체에서 비롯되는 메모리 차지 문제가 있다. 메모리 접근 오버헤드는 앞선 설명처럼 TLB라는 HW 장치의 도움을 받아 줄일 수 있다.
메모리 차지 문제, 즉 공간적 오버헤드는 어떻게 해결할까?
먼저 32-bit 시스템에서 주소 공간의 크기는 최대 4G(2^32)B가 될 수 있다. 페이지 크기가 4K(2^12)B라면 페이지 테이블 안 PTE의 갯수는 2^20개나 된다. 만약 PTE의 크기가 4B라면 각 프로세스별로 관리해야할 페이지 테이블의 크기는 4MB가 될 것이며, 프로세스 100개가 생성된다면 전체 페이지 테이블의 크기는 400MB나 될 것이다. 이는 메모리 부족(memory shortage)를 유발할 것이다.
그렇다면 어떻게 페이지 테이블을 작게 만들 수 있을 까? 1) semenatation + paging 기법을 혼합한 하이브리드 접근 방법과 2) Multi-level 페이지 테이블 방법 등이 있다.
두 방법 모두 핵심은 계층화하여 메모리에 로드되는 정보를 줄인다는 것이다. 따라서 1) 하이브드식 접근 방법에서는 '세그먼트 식별 테이블'이라는 자료주고를 상위에 두는 방식으로 계층화 하였고, 2) 멀티-레벨 페이지 테이블 방법에서는 '페이지 디렉토리'라는 자료구조를 상위에 두어 계층화 하였다.
