reference: "프로그래머가 몰랐던 멀티코어 CPU 이야기" / 김민장, "Computer System A Programmers'Perspective" / 랜달 E.브라이언트
비순차 실행의 구현: 토마슐로 알고리즘
비순차 슈퍼스칼라 프로세서는 주어진 명령어에서 ILP를 찾아 실행 가능한 명령어부터 처리한다.
어떤 명령이 실행 가능하다는 이야기는 이 명령이 취하는 피연산자가 모두 연산을 마쳤을 때라는 의미다. 따라서 어떤 명령의 피연산자가 완료되는 것을 탐지한다면 비순차 실행이 가능할 것이다.
1: x = data[10];
2: y = x + 10;
3: a = b / c;
4: d = e + f;편의상 x, y, a, b, c, d, e 변수 값을 모두 레지스터로 가정하고, data[10] 은 어떤 데이터가 담겨있는 주소로 생각한다.
일단 (1) 명령어를 모두 읽어 큐(queue)(구체적으로 Reservation Station 혹은 Re-Order Buffer(ROB))에 넣는다(ID 이후).
그리고 (2) 큐에서 기다리면서 반복적으로 명령어의 피연산자가 준비되는지 검사한다.
(3) 준비가 다 되었다면 실제 계산을 수행한다.
(4) 완료되면 혹 자신의 결과를 필요로 하는 명령어에 완료가 되었음을 알려준다. 그러면 이제 명령어는 큐에서 떠나고 프로그래머에게 완료가 된 것으로 보일 것이다.
이것을 대략의 비순차 프로세서 파이프라인의 주요 4단계가 된다.
(1) 명령어 인출 및 해독: 명령어를 읽고 해독한 뒤 RS 혹은 ROB 큐에 넣는다.
(2) 스케줄링 단계: 자신의 피연산자가 완료가 되는지 계속 검사한다.
(3) 실행: 완료되면 실행 장치를 하나 얻어 실제 계산을 수행한다.
(4) 결과 쓰기: 연산 결과를 쓰고 혹시 모를 뒤 따르는 명령어에 내가 완료되었음을 알린다.
비순차 실행의 큰 그림은 위와 같이 생각보다 단순하다. 이 뼈대 알고리즘에 살을 붙여보면,
- 명령 1은 큐를 하나 할당받고 자리를 잡는다. 명령 1은 레지스터 x에 값을 쓸 것이므로 뒤에 따라오는 명령어 중 x를 쓰는 명령어들은 반드시 자신을 기다리라고 체크해둔다. 예를 들어 레지스터 파일에서 x 값을 바로 읽지 못하게 한다. 명령 1은 메모리 로드이므로 캐시에 이 데이터를 가져달라고 요청한다. 캐시 미스가 발생해서 이제 긴 시간이 걸린다고 가정한다.
- 프로세서는 다음 명령 2를 읽어 큐에 넣는다. 명령 2는 레지스터 x의 값이 필요하다. 따라서 명령 1이 완료될 때까지 게속 기다린다.
- 명령 3이 큐에 들어온다. 레지스터 b와 c를 읽어야 하는데 그냥 읽을 수 있다. 명령 1, 2에 아무 상관 없이 실행가능하다. 프로세서는 ALU 하나를 할당하고 계산을 수행한다. 큐에서 이제 이 명령을 빼고 완료되었음을 알린다.
- 명령 4도 마찬가지로 명령 3과 같이 처리된다.
- 긴시간이 지나고 명령 1의 데이터가 레지스터에 도달했다. 명령 1이 완료되면 이 사실을 큐에서 기다리고 있는 명령에 알린다. 그러면 명령 2는 비로소 레지스터 x의 값을 읽을 수 있다.
위 과정에서 데이터 의존성에 따라 명령어가 스케줄링됨을 볼 수 있다. 이 알고리즘이 비순차 실행의 기원인 토마슐로 알고리즘이다.
명령어 윈도우(Instruction Window)
실제 프로그램의 크기는 매우 크다. 코드 전체를 분석해 이상적인 ILP를 찾는 것은 현실적으로 제약적인 하드웨어로서 불가능하다. 따라서 비순차 프로세서에서 찾는 ILP는 상대적으로 매우 제한적인 범위 내에서 찾는다. 명령어 윈도우는 이 범위를 가리킨다.
예를들어 128개의 명령어 윈도우를 갖는 다는 것은 128개의 명령어 속에서 ILP를 찾을 수 있다는 뜻이다. 다르게 말하면 128개 명령어를 잠시 들고 있으면서 비순차 실행을 수행한다는 말이기도 하다. 명령어 윈도우는 보통 연속적으로 움직이며, 윈도우 안에서 가장 오래된 명령어가 완료되면 한 칸씩 이동한다. 명령어 윈도우 안에 있는 명령어를 인-플라이트(in-flight) 명령어라 표현하기도 한다.
최신 프로세서에서 명령어 윈도우 크기는 보통 100여개 정도다. 윈도우 크기가 크면 클수록 당연히 좋지만 하드웨어 구현의 여러 제약으로 인해 쉽게 늘리지 못한다. 인텔 코어 2 프로세서는 96개의 명령어를 비순차적으로 처리할 수 있었다. 이것이 네할렘 구조에서 128개로 확장되었다.
이후 언급할 수도 있겠지만(story17 VLIW 참고) 하드웨어인 프로세서가 아닌 소프트웨어 컴파일러가 ILP를 찾는 방법이 있다. 컴파일러는 하드웨어 제약이 없으므로 이보다 더 큰 범위에서 ILP를 찾을 수 있다. 보통 수천 개의 명령어 사이에서 최적의 ILP를 찾는다.
레지스터 리네이밍(Register Renaming)으로 가짜 의존성 제거
순차 프로세서에서는 '가짜 의존성'에 대해 거의 고려할 필요가 없다. 가짜 의존성은 비순차 프로세서에서는 반드시 주의 깊게 다루어야 한다.
기계어상에서 데이터 의존성은 레지스터 이름이 겹치는 것으로 찾아낼 수 있다. 피연산자와 목적지에 있는 레지스터 이름만 비교하면 쉽게 데이터 의존성을 찾을 수 있다. 그 종류는 RAW/WAW/WAR 세 가지가 있고, WAW, WAR는 변수 이름 교환으로 제거될 수 있는 가짜 의존성이다. 반면 RAW 의존성은 제거할 수 없는 진짜 의존성이었다.
순차 프로세서에서는 RAW 의존성은 파이프라인 해저드를 만들었지만, WAW/WAR 의존성으로 파이프라인 해저드는 일어나지 않았다.
위 그림에서 명령 1과 2는 레지스터 r1에 대해 WAR 의존성을 가진다. 그러나 이것은 파이프라인 해저드를 만들지 않는다.
명령 2가 r1에 값을 쓰는 시점은 t7 시간의 WB 단계이다. 명령 1은 r1 값을 이보다 빠른 t3 시간에 RR 단계에서 읽었다. 따라서 WAR 의존성은 아무런 문제를 읽으키지 않는다. 명령 2와 3의 WAW도 같은 이유로 문제없다.
이렇게 WAR/WAW 의존성은 순차적으로 명령어를 처리할 때는 특별한 파이프라인 구현상의 제약이 아닌 이상 데이터 흐름 자체로는 아무런 문제를 만들지 않는다. 그러나 RAW는 WB 시간보다 앞서 데이터가 필요했기에 "바이패스"로 미리 데이터를 전달해야만 했다.
그런데 비순차 실행이 되면 WAW/WAR 의존성(거짓 의존성)은 문제를 일으킨다. 명령 1과 2를 뒤바꾸어 실행하고자 하여도 WAR 의존성 떄문에 그렇게 할 수 없다. WAW 의존성도 마찬가지이다. 이전에 보았던 이름 바꾸기 기법으로 WAR/WAW 의존성을 없앴다면 휠씬 높은 비순차 실행 기회를 얻을 수 있다. 비순차 프로세서는 높은 ILP을 얻고자 레지스터 이름을 바꿔서 가짜 의존성을 제거하는 작업을 필수적으로 한다. 이 과정을 레지스터 리네이밍(register renaming)이라 부르고, 명령어 해독 단계 ID에서 이루어진다.
예를 들어 아래의 코드는 레지스터 리네이밍을 통해 가짜 의존성을 없앨 수 있다.
1: r2 = r1 + 5; => F0 = r1 + 5;
2: r0 = r2 + 4; => F1 = F0 + 4;
3: r1 = r0 + 1; => F2 = F1 + 1; // r1에 대해 명령 1과 WAR 의존성, r1 리네이밍
4: r1 = r0 + 2; => F3 = F1 + 2; // r1에 대해 명령 3과 WAW 의존성, r1 리네이밍
5: r3 = r1 + 3; => F4 = F3 + 3;
// 가짜 의존성 제거
// r0 ~ r3는 논리 레지스터이며, F0~F4는 물리 레지스터레지스터 리네이미을 항상 할 필요는 없지만, 필요할 때만 하는 것은 복잡하기에 명령어를 해독(ID)할 때 모든 목적지 레지스터의 이름을 바꾼다. 그리고 뒤따르는 명령어는 바뀐 내용을 따른다.
명령어상에 있는 레지스터 이름은 ISA가 정의하는 것으로 프로그래머가 보는 것이다. 그런데 ISA가 정의하는 레지스터 외에 추가 레지스터가 있어야 레지스터 리네이밍이 효과적이다. 레지스터 수를 확장하지 않으면 이름을 바꾸는데 제약이 매우 심하다. 따라서 레지스터 파일을 ISA가 정의하는 구조 레지스터(Architecture Register, ARF, 혹은 논리 레지스터)과 물리 레지스터 파일(Physical Register File, PRF)로 나눈다. 논리 레지스터는 함부로 바꾸면 하위 호환성이 어긋나기 때문에 쉽게 바꿀 수 없다. 반면, 물리 레지스터 파일은 프로그래머가 볼 수 없으므로 자유롭게 설계할 수 있다.
논리 레지스터 파일과 물리 레지스터 파일의 매핑 내역을 기억하는 자료구조가 필요한데, 이 변경 내역을 기억하는 장소를 레지스터 변경 테이블(Register Alias Table, RAT)이라 한다.
논리 레지스터는 위 코드에서 보이는 r0~3만 있다고 하고, 물리 레지스터는 F0~9까지 있다고 가정하자. 변경 규칙은 다음과 같다.
(1) 명령어의 목적지 레지스터 이름을 현재 가능한 물리 레지스터 중 하나로 바꾼다. 변경 내역을 RAT에 기록한다. (만약 물리 레지스터에 여유가 없다면 stall 시켜야 한다.)
(2) 다음 명령어가 레지스터(논리 레지스터)를 읽을 때 RAT를 살펴보고 현재 어떤 물리 레지스터에 매핑되어 있는지 확인하고 읽는다.
비순차 프로세서는 WAR/WAW 의존성 역시 파이프라인 해저드를 만들 수 있으므로 하드웨어 수준의 레지스터 리네이밍 장치로 가짜 의존성을 효과적으로 제거한다. 레지스터 리네이밍은 슈퍼스칼라 구조에서는 더욱 복잡한 구현 문제를 안고 있다는 사실도 기억해야 한다.
동적 명령어 스케줄링: Reservation Statation
비순차 실행의 핵심은 동적 명령어 스케줄링에 있다. 피연산자가 완료되는 순서대로 처리하여 비순차적으로 명령어들을 실행시키려면 스케줄링 장치가 필요하다.
IF, ID 단계 이후 큐에 있는 명령어가 자신의 피연산자가 완료되는가를 감시하고 있다. 이 장치(큐)를 Resevation Station(RS)이라 부른다. 비순차 실행에서는 명령어를 해독한 후 RS 장치로부터 하나의 슬롯을 할당받도록 한다. 명령어가 RS에 자리 잡으면 크게 두 가지 작업이 이루어진다.
(1) wake-up(깨우기) 작업: 어떤 명령어의 모든 피연산자가 완료되었는지 감시하는 장치. 모두 완료되면 명령어를 잠에서 '깨운다'. 실행할 준비가 되었다는 뜻.
(2) select(선택) 작업: 명령어를 깨운 이후 필요한 계산 장치를 할당해주는 작업. 예를 들어 RS에 있는 명령 중 3개가 동시에 실행 가능해졌고, 사용 가능한 ALU가 하나만 있다면 어떤식으로든 스케줄링해야 함. 가장 오래된 명령어에 미리 할당해주는 정책을 떠올릴 수 있음.
위 두 작업이 비순차 실행에서 가장 중요한 부분인 동적 명령어 스케줄링의 큰 줄기이다.
인텔 네할렘 구조의 Reservation Station과 실행장치들
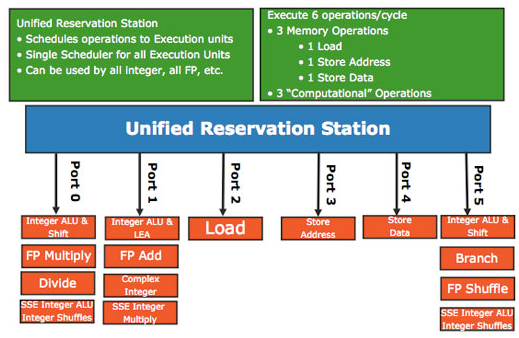
인텔 네할렘 구조의 RS 그림이다. 네할렘 구조에서 RS 개수는 총 36개다(RS는 36개의 명령어를 담을 수 있다는 뜻). 'Unified'의 의미는 명령어 종류에 상관없이 통합했다는 것이다. 하나의 스케줄러가 있다는 이야기인데, 어떤 프로세서는 RS를 정수/부동소수점/로드/스토어에 따라 독립적으로 관리하기도 한다.
위 그림에서 Port는 RS와 여러 실행 정차 사이를 연결하고 있다. RS는 36개의 명령어를 담을 수 있고, 15개의 실행 장치가 있다. 따라서 최악에는 36개의 명령어가 동시에 실행 장치를 요구할 수 있으므로 36 대 15의 스케줄링 회로를 구현해야 한다. 이는 지나치게 복잡하고 시간도 오래 걸린다. 그래서 15개의 실행 장치를 단위, 즉 포트로 묶는다. 이 그림에서는 6개의 포트가 있는데, 이는 36 대 6의 스케줄링만 구현하면 되므로 부담이 준다.
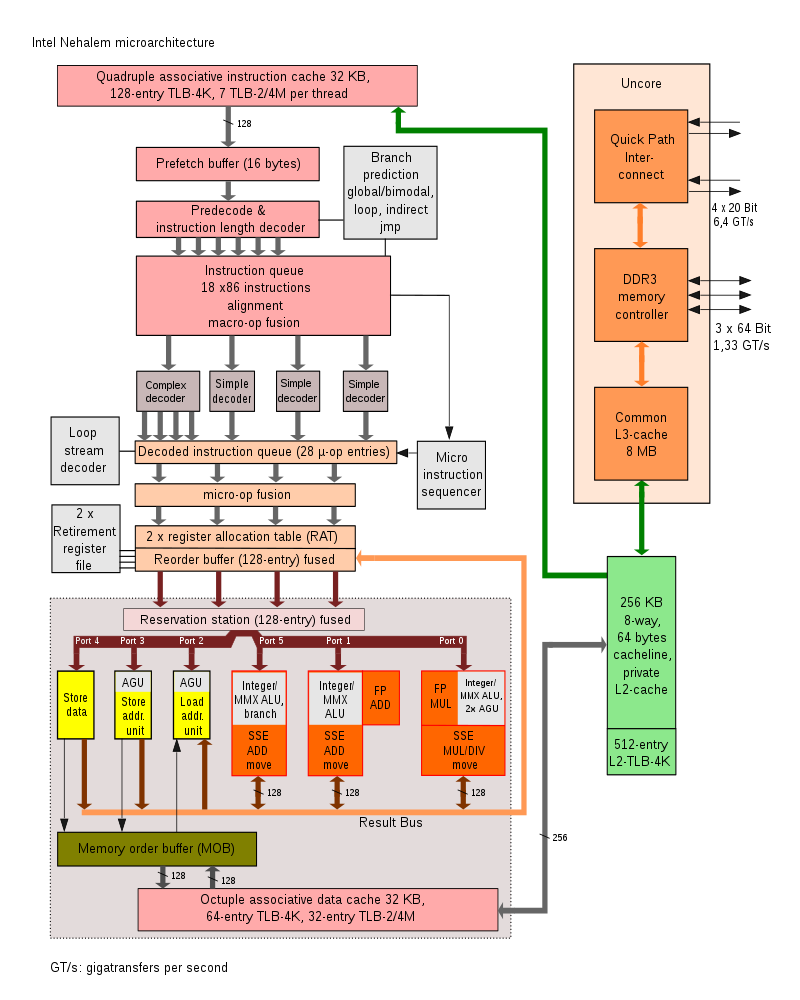
참고, 네할렘 구조 전체 개괄
순서대로 완료되게 하는 리오더 버퍼
비순차 프로세서라고 했지만 모든 것이 뒤죽박죽 실행되는 것은 아니다. 명령어 인출과 해독을 비순차적으로 한다는 것은 말이 안된다. 명령어를 가져오는 것은 여전히 프로그램 순서대로만 가져온다. 비순차는 오직 실행 단계에서 피연산자가 먼저 완료되는 순서로 실행하는 것.
지금까지 한 가지 간과한 것이 있는데 명령어 완료의 순차성 여부이다. 명령어 인출(IF)와 해독(ID)은 순차지만 실행(EXE)은 비순차적이다. 따라서 명령어가 완료되는 것 역시 비순차적이다. 하지만 프로그래머 입장에서는 프로그램이 순차적으로 실행되고 있다고 믿는다. 따라서 명령어가 완료되는 것 역시 순차적으로 이루어지게 해야 한다. 리오더 버퍼(Re-Order buffer, ROB)가 이것을 하게 한다.
명령어가 해독되면 스케줄링을 위해 RS의 한 공간을 할당받는데 이때 ROB도 할당받게 한다. 한 명령어는 실행이 완전히 완료될 때까지 늘 ROB에 머물러야 한다. 따라서 ROB의 크기가 사실상 비순차 프로세서의 명령어 윈도우를 결정한다. 대신 명령어는 자신의 피연산자가 모두 충족되면 RS는 실행할 수 있는 시점에서 떠날 수 있다. 보통 RS의 개수가 30여 개임에 비해 ROB 개수는 100여 개로 훨씬 많다. 인텔의 네할렘 구조는 128개, Core 2는 96개이다.
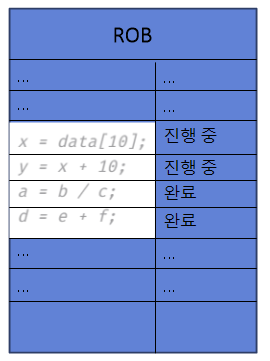
위 그림은 ROB의 모습을 간단히 보여준다. ROB는 일종의 환형(circular) 큐와 같다. 명령어가 해독되면 ROB에 자리를 잡는다. 그리고 실행을 마치면 완료되었다고 기록한다. 이것이 바로 밖으로 노출되는 것이 아니고 자신이 ROB에서 가장 오래된 명령어일 때 정말로 완료할 수 있다. 그렇다면 프로그래머는 명령어가 순차대로 완료되었다고 볼 것이다. 이 과정을 커밋(commit), 퇴장(retirement), 마침(graduation)으로 표현한다. 또 중요한 사실은 명령어가 논리(구조) 레지스터 파일에 값을 최종적으로 갱신하는 것이나 메모리에 값을 쓰는 것도 커밋이 되어야 가능하다. 그 전까지는 레지스터 및 메모리 변경 값을 보류해야 한다.
완전히 완료되었다면, 차지했던 자원을 반환하고 자신의 결과를 최종적으로 반영한다. 구조 레지스터 파일이나 메모리를 갱신한다.
위 그림에서 명령 3, 4는 1, 2dhk 무관해 이미 실행을 마쳤다. 그러나 ROB에서 가장 오래된 명령어는 아니다. 바로 커밋해버리면 프로그래머는 프로그램이 비순차적으로 실행되었다는 것을 보기에 혼동하고 말 것이다. 따라서 일단 ROB에서 자신보다 앞서 있는 명령어가 커밋할 때까지 기다리고, ROB로 명령어 완료를 순차적으로 다시 정렬할 수 있다.
ROB가 순차적으로 명령어를 커밋해야 하는 또 다른 중요한 이유는 폴트(fault)와 예외 처리에 있다.
1: r3 = r1 + r4;
2: r4 = r7 / r1; // 0으로 나눔 예외
3: r6 = Load[r7]; // 페이지 폴트이 짧은 코드에서 모든 명령은 의존성이 없기에 동시에 실행될 수 있다. 하지만 만약 명령 3이 명령 2가 되기 전에 수행하고, 페이지 폴트를 만났다면 운영체제 개입이 들어간다. 그런데 명령 2가 완료되지도 않았는데 페이지 폴트를 띄우고 운영체제로 제어가 넘어가면 역시 프로그래머는 혼란을 겪는다. 따라서 비순차 프로세서에서는 예외나 폴트 역시 하나의 결과로 간주해 발생하는 시점에 즉시 어떤 일을 하는 것이 아니다. ROB에서 기다리고 있다가 자신의 커밋 차례가 올 때 비로소 외부 세계에 알린다.
비순차 프로세서 파이프라인
비순차 프로세서에서의 주요 부분: 기본 개념, 레지스터 리네이밍, 명령어 스케줄링, 리오더 버퍼(ROB), Reservation Station을 설명.
그런데 현대 프로세서는 모두 파이프라인화 되어 있으므로 비순차 실행이 어떻게 최종적으로 파이프라인화 되었는지가 중요하다.

위 그림은 비순차 프로세서의 주요 파이프라인 단계이다. 스케줄/실행/쓰기는 비순차, 나머지는 순차적으로 이루어진다.
아주 크게 분류하면 (1) 명령어 인출 및 해독, (2) 자원 할당(ROB, RS 할당), (3) 비순차 실행, (4) 커밋으로 나눌 수 있고, 세분화하면 위 그림과 같다.
프론트 엔드, 즉 명령어 인출, 해독, 리네이밍, 이슈 과정과 백 엔드인 커밋 과정은 순차적으로 이루어진다.
- 명령어 인출(IF): 순차 프로세서와 큰 차이는 없으나 보통 슈퍼스칼라 구조이므로 더욱 복잡해진다.
- 명령어 해독(ID): x86프로세서라면 RISC 형식의 마이크로 명령어로 바꾼다.
- 레지스터 리네이밍: 가짜 의존성을 제거를 위한 레지스터 이름 바꾸는 작업을 한다.
- 이슈 혹은 할당(allocation): 준비된 마이크로 명령어를 각종 장치(RS, ROB)에 할당한다.
- 스케줄링: 비순차적 실행이 가능하도록 피연산자 완료를 매 사이클마다 검사하고 준비되면 실행 장치를 스케줄링한다.
- 실행(EXE): 진짜 계산이 이루어진다.
- 쓰기(WB): 연산 결과를 ROB나 물리 레지스터 같은 곳에 쓴다. 아직 커밋 전이기에 결과는 외부 세계에 노출되어선 안된다.
- 커밋: 완전히 완료할 수 있다. 차지했던 자원을 반환하고 자신의 결과를 최종적으로 반영한다. 구조 레지스터 파일이나 메모리를 갱신한다.
결론
본 글을 통해 비순차 슈퍼스칼라 파이프라인의 개념에 대해 알아보았다. 분기 예측(branch prediction)이나 투기적 실행(speculative execution)에 대해선 아직 안다루었다.(to be continued.. 이 기술은 컨트롤/메모리 의존성을 푼다.)
명령어 처리율(IPC)을 높이는 방법은 근본적으로 동시에 많은 명령어를 처리할 수 있어야 한다. 파이프라인으로 큰 도약을 이루었다면 슈퍼스칼라 구조와 비순차 실행으로 명령어 처리율을 비약적으로 증가시켰다. 슈퍼스칼라 프로세서는 동시에 여러 명령어를 파이프라인에 투입하고 완료할 수 있어 1보다 큰 IPC를 얻게 해주었다. 비록 싱글쓰레드 프로그램이라 하더라도 데이터 흐름, 즉 명령어 사이의 데이터 의존성에 따라 동시에 실행시킬 수 있는 병렬성, 명령어 수준 병렬성이 있었다. 비순차 실행은 하드웨어에서 명령어 수준 병렬성을 찾는 알고리즘이었다. 프로그램 코드에 적혀있는 순서대로 실행하는 것이 아니라, 피연산자가 준비되는 순서대로 명령어를 수행시킨다. 그리고 이 비순차 프로세서의 알고리즘으로 토마슐로 알고리즘이 사용된다.
가짜 의존성을 제거하기 위해 레지스터 리네이밍이 필요하고, 비순차 프로세서의 핵심인 명령어 스케줄링이 필요하다.
아무리 실행 단계가 비순차적이라도 명령어 완료는 순차로 보여야 프로그래머가 혼동하지 않기에 RS, ROB, RAT과 같은 장치들이 필요하다.
마지막으로 비순차 프로세서의 파이프라인은 순서대로 처리하는 프론트 엔드와 백 엔드 사이에 비순차로 처리되는 실행 단계를 갖고 있다.
