
1. Computer Vison Introduction
Computer Vision이란 컴퓨터가 이미지, 비디오 등의 입력데이터로부터 유용한 정보를 추론하도록 하는 인공지능 기술의 일종이다.
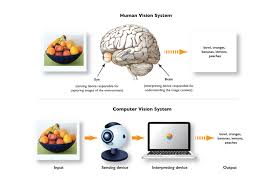
사람의 경우 과일 사진을 보면 해당 이미지는 과일이라는 것을 바로 인식이 가능하다. 하지만 컴퓨터의 경우 해당 이미는 단지 Pixel로 이루어진 숫자들의 조합이다. 즉, Computer vision은 "이러한 Pixel값들을 어떻게 활용하여 사람처럼 유용한 정보를 추출해낼 것인가?"와 관련된 기술들을 다룬다.

Computer Vision 분야는 이전부터 존재하였다. Vision 분야에서 유명한 Obeject Classification 대회인 ImageNet Challenge는 이미지 속에서 주어진 객체를 찾아내는 대회로 유명하다. 2012년 이전에는 전통적인 Vision 알고리즘을 활용하여 객체를 분류해왔다. 하지만, 2012년 해당 대회에서 이후의 포스트에서 다루어볼 AlexNet이 등장하면서, Vision 분야에서 Deeplearning이 주목받기 시작하였다. AlexNet은 Deeplearning을 활용하였다는 것도 주목받았지만, GPU를 활용하여 Deeplearning을 사용했다는 점이 중요한 Contribution이기도 하다.
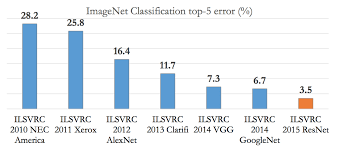
Deep learning을 활용하면서부터 Error율이 급감하였고, 이후에는 인간보다 객체를 더 잘 구별해내는 수준에까지 이르게 되었다.
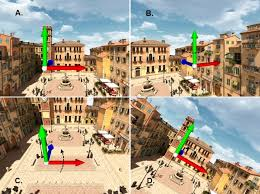
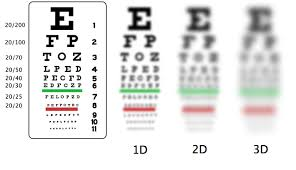
하지만, 여전히 Computer Vision 분야에서 아직도 정복되지 않은 문제가 존재한다. 크게 4가지만 꼽자면, 3D viewpoint change, illumination change, Scale change, Motion blur 등과 같은 문제이다.
-
3d Viewpoint change
-
illumination change

-
Motion blur
-
Scale change
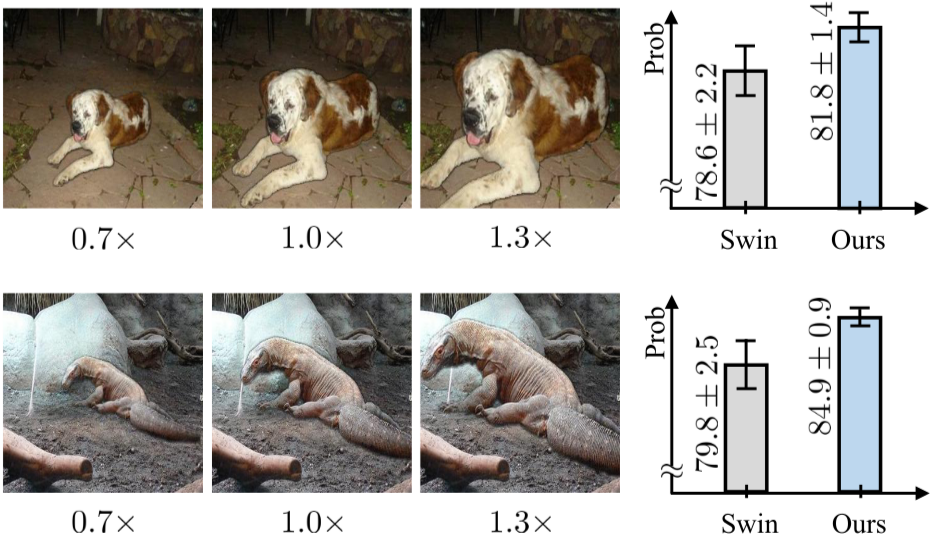
인간의 경우 위와 같은 문제가 발생하여도 문제없이 사물을 인지하지만, Computer Vision 분야에서는 Pixel을 활용하여 Object를 인지하기 때문에 살짝의 변화만으로도 Pixel값이 크게 바뀌어 제대로 작동하지 않을 가능성이 크다.
2. Image Coordinate
Image는 각각의 Pixel들이 위치한 좌표계라고 생각할 수 있다. 이때 이미지는 Pixel들의 좌표만 나타내는 2D Coordinate가 아닌 각각의 Pixel이 위치한 곳마다 Color값도 가지고 있는 3D Coordinate이다.
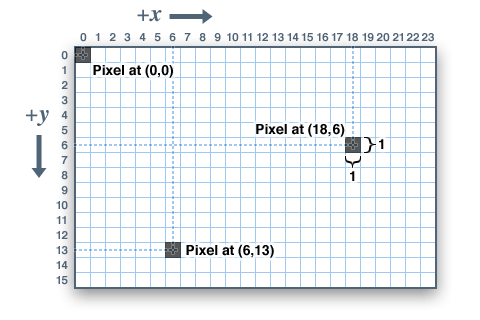
Image 좌표계의 원점은 좌측 상단을 원점으로 하면 각각의 위치마다 RGB Color값을 가진다. 즉, 기본적으로 Image 좌표계는 (W, H, C(color))값을 가진다.

OpenCV에서는 BGR 순서로 되어있으므로, cv2.cvtColor를 활용하여 BGR2RGB로 변환해주어야 한다.
이러한 Image는 Computer 입장에서는 Pixel들을 모아둔 Matrix라고 생각할 수 있다. 따라서 Original RGB image가 있다면, 동일한 크기의 임의의 값을 채운 Matrix를 생성하여 연산을 수행하면 색상이 변조된 이미지나 패턴 변화된 이미지가 될 수 있다. 예를 들어 만약 Image Crop을 수행하고 싶은 경우 좌표를 알아낸 후에 잘라서 오면 되고, 원본이미지를 늘리고 싶은 경우에는 Mapping function을 만들어서 resize를 수행할 수 있다.
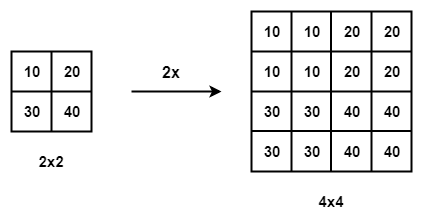
Resize의 경우 비어 있는 Pixel이 존재한다면 interpolation을 수행하면 된다.
오늘은 Computer Vision이 무엇인지에 대한 개념과 Image 좌표계를 위주로 다루었다. 다음 포스트에서는 이러한 Image 좌표계. 즉, matrix를 활용하여 어떻게 이미지를 변조시킬 수 있는지에 관하여 다루어볼 예정이다.
