지난 포스트까지 Computer Vision과 관련된 내용을 끝내고 오늘은 Lidar Sensor를 어떻게 다룰 것인가와 관련하여 써보고자 한다.
1. Lidar
Lidar는 레이저를 쏘아서 거리를 측정하는 Sensor로써, 아래 그림에서 보이는 것과 같이 레이저를 쏘아 객체에 닿은 후 반사되어 돌아오는 것을 측정하여 객체와 센서 사이의 거리를 측정한다. 이때 단방향 Lidar Sesor와 Channel이 여러 개로 360도 회전하는 전방향 Lidar Sensor가 있다.
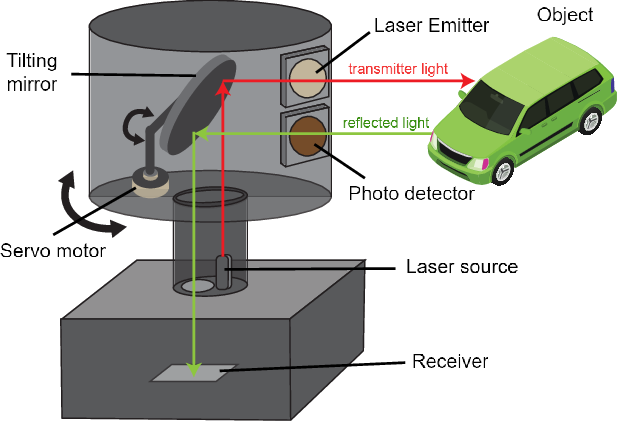
Lidar 선택 시 고려해야 할 사항은 단순히 단방향, 전방향 뿐만 아니라 최소 감지 거리, 최대 감지 거리를 고려해서 구매해야 한다.
로봇 혹은 자율주행 자동차의 경우, Lidar 센서는 여러 개의 레이저 센서가 부착되어 있거나, 회전 또는 이동하며 넓은 영역에 대한 거리 정보를 취득한다. 이러한 거리 정보는 등의 형식으로 저장되며, 이러한 데이터가 넓은 영역에 걸쳐 수없이 많이 존재한다.
Point Cloud
방금 설명한 것처럼 거리 정보는 가 넓은 영역에 걸쳐 수없이 많이 존재한다고 했는데, 마치 점들이 구름을 이루는 형상과 비슷하다고 하여 Point Cloud라고 지칭한다.

이러한 Point Cloud를 Ros에서 다루기 위해서는 일반적으로 PointCloud2.msg를 활용한다. Ros에서 활용하고 싶다면 다음 Document를 참고하길 바란다. https://docs.ros.org/en/noetic/api/sensor_msgs/html/msg/PointCloud2.html
Lidar의 경우 Camera Sensor와는 다르게 거리 정보에 대한 유용성이 높다. Camera의 경우 앞서 살펴봤던 것 처럼, Depth Estimation과정이 필요하지 않다. 그렇다면 이러한 Lidar로 들어오는 Point Cloud를 어떻게 처리하여 객체검출, 바닥면을 추출하는 유용한 정보를 얻을 수 있을지 지금부터 살펴보자.
2. Clustering Algorithm
Point Cloud(Raw data)가 주어졌을 경우 장애물을 검출하는 알고리즘은 Clustering으로 주어진 데이터를 비슷한 것끼리 묶는 방법이다. ML을 어느 정도 공부했다면 알 수도 있지만, Clustering은 Unsuperviesed-Learing 방식의 알고리즘으로써,주어지는 Lable 없이 비슷한 데이터끼리 묶는 방법이다.
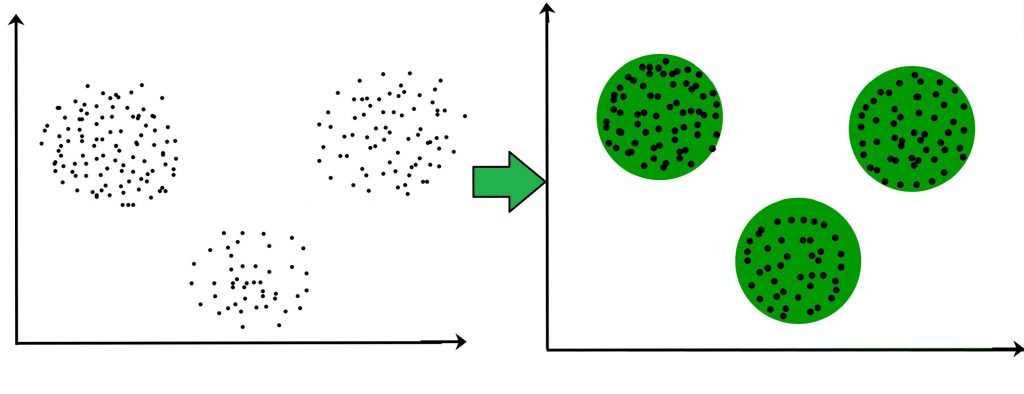
K -means 알고리즘
k-means알고리즘은 Clustering의 대표적인 알고리즘이다. 알고리즘의 순서를 적어보자면 다음과 같다.
1. K개의 Centroid를 초기화
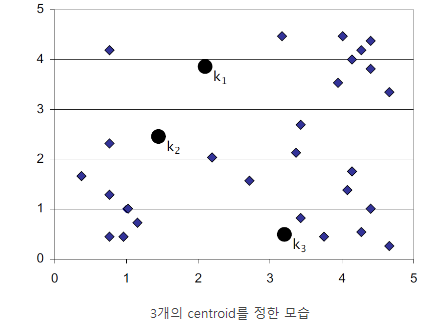
K-means 알고리즘은 몇 개의 Cluster를 구분해야 할 지 사전에 미리 정해둔다.
이것은 K-means 알고리즘의 단점이기도 하다.
2. 현재의 Centroid를 기반으로 가까이 있는 점들을 해당 Centroid의 Class로 분류
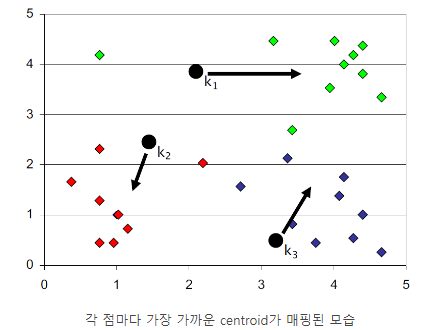
중심점과 모든 Data들의 거리를 측정하여 1차적으로 구분한다.
3. 분류된 데이터들 내에서 새로운 Centroid를 생성
1차적으로 분류된 Data를 기반으로 해서 새로운 중심점을 찾는다. 무게중심 혹은 평균을 기반으로 한다.
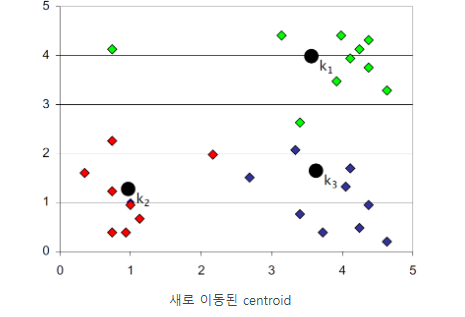
4. 2번에서 3번 과정을 mapping되지 않을 때까지 반복한다.
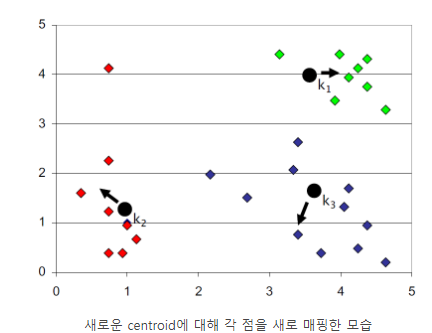
K-means알고리즘의 경우에는 방금 전에 설명하였듯이, 몇 개의 Cluster를 구분해야 하는지를 사전에 정해주어야 한다. 하지만, 실제로 Object가 몇 개인지 판단하기가 어렵기 때문에 실사용이 어려울 수 있다.
3. Agglomerative Clustering
Agglomerative Clustering(병합군집화)는 각각의 Point가 하나의 Cluster로 생각하고 병합해나가면서 Clustering을 생성하는 알고리즘이다.
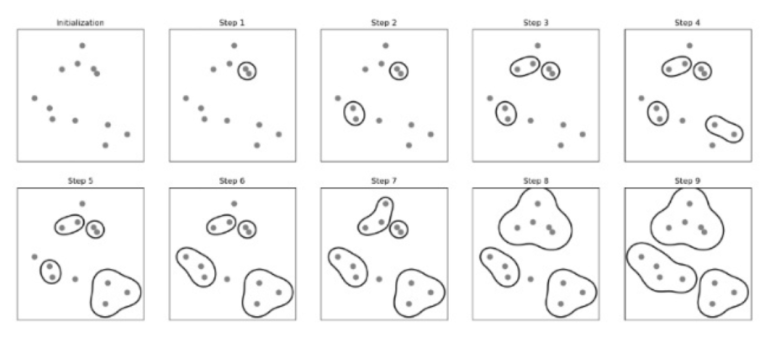
1. 각각의 점을 하나의 Cluster로 생각
2. 가장 가까운 데이터들끼리 Cluster로 병합
3. 하나의 Cluster만 남을 때까지 혹은 원하는 개수의 Cluster만 남을 때까지 반복
즉, Data 각각이 Cluster이며, 각각의 data들끼리 거리를 측정한 후, 가장 가까이 붙어있는 Data끼리 병합하는 방식이다. 이때 어떻게 합병을 할지에 따라 방식이 달라지게 되는데, 군집을 합병하는 과정에서 군집 간의 거리를 재는 방식은 아래와 같이 여러가지가 있다. 해당 내용을 수업에서는 다루지 않았지만, 나중에 Machine Learning을 공부하다보면, 해당 내용이 등장하기 때문에 참고로 알아두면 좋을 것이다.
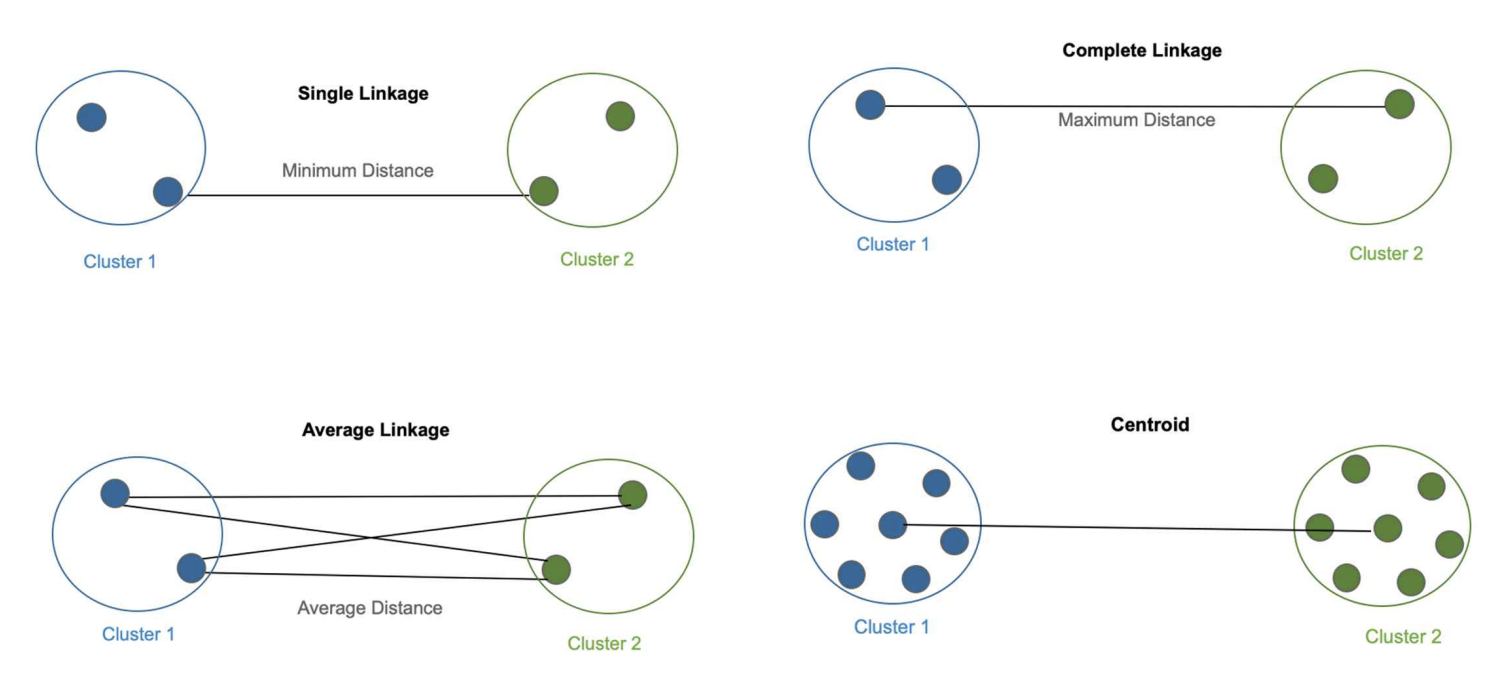
- Single Linkage : 1번째 그림에서 보는 것처럼, 2개의 Cluster 간의 Point 중에서 가장 가까운 것을 거리로 간주하는 방식이다.
- Complete Linkage : 2개의 Cluster 간의 Point 중에서 가장 먼 것을 거리로 간주하는 방식이다.
- average linkage : 2개의 Cluster 간의 모든 거리를 측정하여 이를 평균 낸 것을 거리로 간주하는 방식이다.
- Centroid : 각 cluster의 Centroid를 구하여, 각 Cluster의 Centoid 간의 거리를 Cluster 간의 거리로 간주하는 방식이다.
Agglomerative Clustering을 hierarchical clustering라고도 하는데,
해당 시리즈에서 Machine Learning까지 다루기는 버거울 거 같아서, 따로 시간을 빼서 Machine Learning과 Deep Learing의 기초 내용을 작성해보도록 하겠다.
4. Euclidean clustering
Euclidean clustering은 거리를 기반으로 하는 Clustering이다. 즉, 데이터간 거리가 일정거리 이하이면 하나의 군집으로 묶는 알고리즘이다. 하지만 이를 아무런 전처리 없이 구현하면 모든 데이터간 거리를 계산해야 한다. 하지만 데이터를 필요에 맞게 구조화 시키면 모든 데이터간 거리를 계산하지 않아도 Euclidean clustering이 가능해진다. 여기서는 KD Tree를 기반으로 해서 설명하고자 하며, 추가적으로 DB-Scan에 대해서도 간략하게 다루어보겠다.
고영민 교수님 수업에서는 따로 다루지는 않는 내용이니 참고하길 바란다.
KD Tree란?
KD Tree는 BST(Binary Search Tree)를 K차원으로 확장한 Data Structure를 가지고 있으며, insert 기능을 수행하는 경우에는 각 차원을 번갈아 비교하여 Tree 구조에 저장하게 된다.
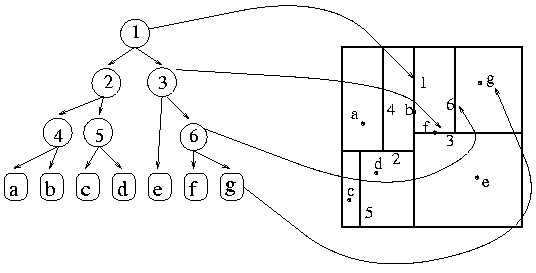
Tree를 구성하기 위한 방법에는 여러 가지가 있는데, 여기서는 균형잡힌 KD Tree를 구성하기 위하여 median값을 사용하는 방법을 통해서 설명하겠다. 2D의 구성단계를 짧게 요약하자면 다음과 같다.
KD Tree의 구축 절차
KD Tree를 만들 때 핵심은 depth에 따라 분할 축을 바꾸고, 그 축에서 중앙값(median)을 기준으로 좌/우 Subtree를 나누는 것이다.
- 처음 삽입된 point가 Tree의 Root가 된다.
- Depth에 따라 Axis를 선택하여 모든 유효한 값을 순환하도록 한다.
- Axis를 기준으로 point list를 정렬하고, median값을 Pivot로써 선택한다. 만약 median 값보다 작다면 왼쪽 Branch로 넘기고, median값보다 크다면 오른쪽 Branch로 넘긴다.
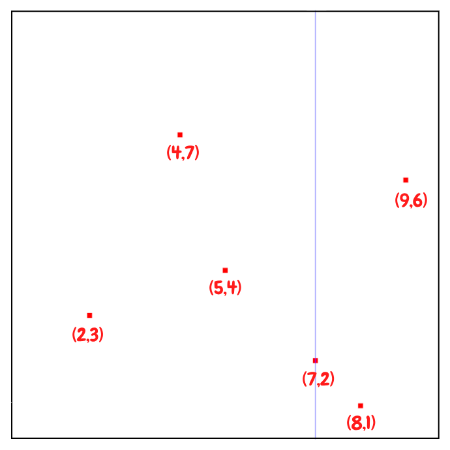
- Node가 비어있을 때까지 Tree를 순회한 후에 해당 Node에 Point를 할당한다.
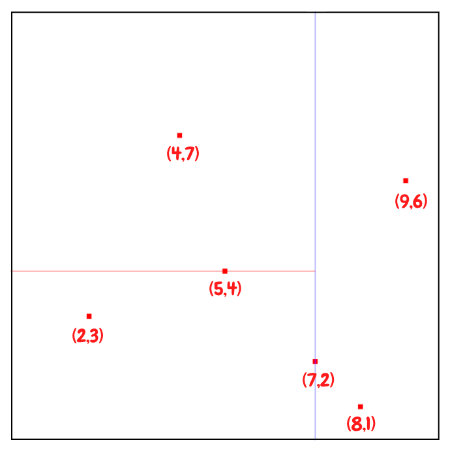
- 2번에서 4번과정을 Reculsive하게 반복한다.
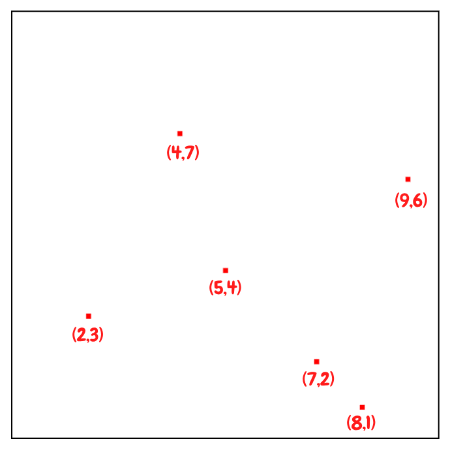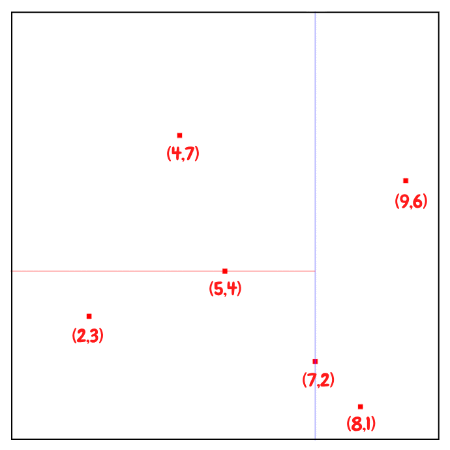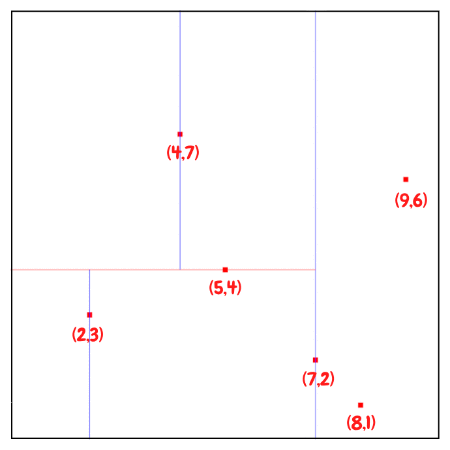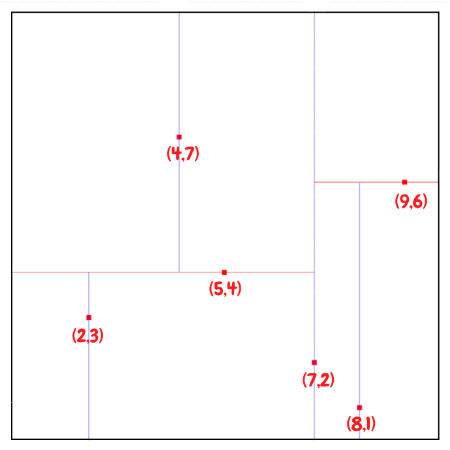
median값을 기준으로 분할하면 대체로 트리가 balanced에 가까워지고, 이 경우 탐색 시간이 좋아진다. 중앙값을 쓰지 않으면 트리가 한쪽으로 치우쳐 성능 보장이 어려워진다.
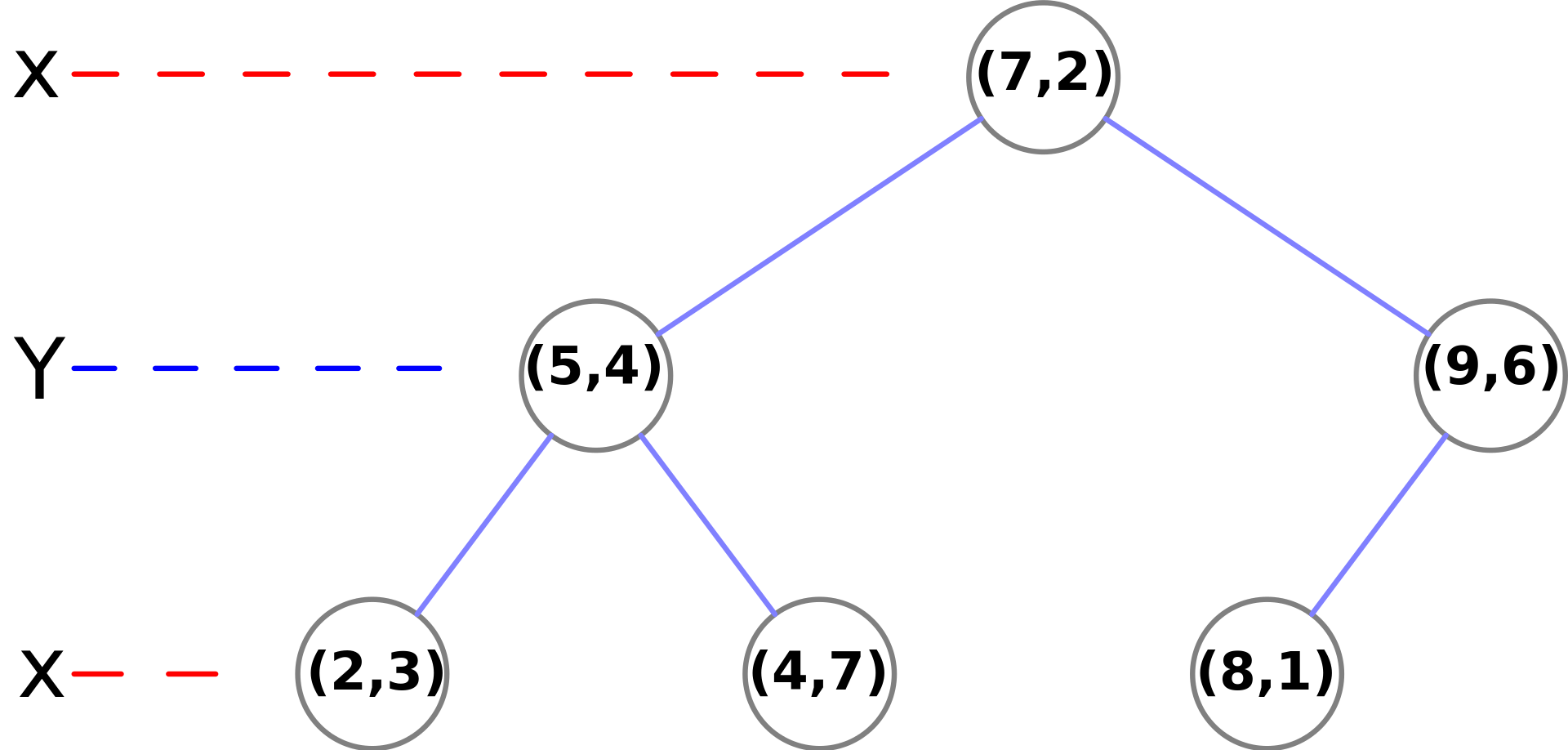
KD-Tree에서 Nearest Neighbor Search과정
KD-Tree로 Nearest Neighbor Search를 찾는 기본적인 아이디어는 "삽입하듯이 내려갔다가, 돌아오면서(backtracking) 다른 가지도 볼 필요가 있는지 검사”하는 것이다. 절차는 다음과 같다.
-
Root Node부터 시작하여 분할 축에서의 비교로 좌/우 가지 중 하나를 선택하며 Leaf Node까지 내려간다.
-
Leaf Node에서 만난 점을 현재 최적으로 둔다.
-
재귀를 되돌아오면서(위로 올라가면서) 현재 노드가 더 가깝다면 current best를 갱신한다.
-
other branch에 더 가까운 점이 존재할 가능성이 있는지 검사한다.
현재 최적 거리 로 중심이 Query 점인 hypersphere를 생각했을 때, 그 구가 분할 평면과 교차하면 반대쪽에도 후보가 있을 수 있으므로 반대쪽도 탐색한다. 교차하지 않으면 반대쪽 Branch 전체를 배제한다.
-
Root까지 되돌아오면 Search가 종료된다.
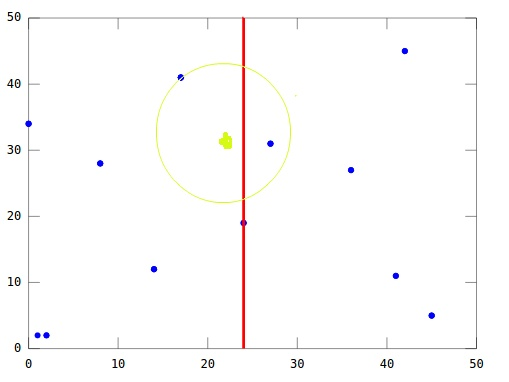
Euclidean Clustering에서 KD-Tree가 실제로 쓰이는 방식
Euclidean Clustering은 보통 거리 임계값 이내의 점들을 연결해서 connected component를 만든다에 가깝고, 이때 반복적으로 필요한 연산은 어떤 점 에 대해 반경 안에 있는 이웃 점들을 찾는 radius search 하는 것이다. KD-Tree는 6번의 Nearest Neighbor Search(1-NN)과 동일한 pruning 원리를 이용해 radius search도 빠르게 수행할 수 있고, 그래서 Euclidean Clustering 전체 속도를 크게 올린다.
Euclidean Clustering 전체 순서 (KD-Tree) 정리
- 포인트클라우드로 KD-Tree를 구축한다.
processed/visited배열을 만든다.- 모든 점을 순회하며, 아직 처리되지 않은 점을 만나면 새 클러스터를 시작한다.
- 큐(BFS)를 돌면서, 현재 점에서
radiusSearch(d_th)로 이웃 점들을 가져오고
아직 미방문이면 visited 처리 후 큐에 넣는다. - 큐가 빌 때까지 반복하면 하나의 클러스터가 완성된다.
- 클러스터 크기가
min_cluster_size/max_cluster_size범위에 맞는지 검사하고 저장/폐기한다. - 전체 점에 대해 위 과정을 반복한다.
DB-Scan
DB-Scan은 Density-Based Spatial Clustering Of Applications With Noise의 약자로, Noise를 포함한 데이터에 대해 밀도 기반으로 클러스터링 하는 알고리즘이다. 데이터가 밀집되어 있는 집합을 클러스터로 간주하고 이를 Clustering한다.
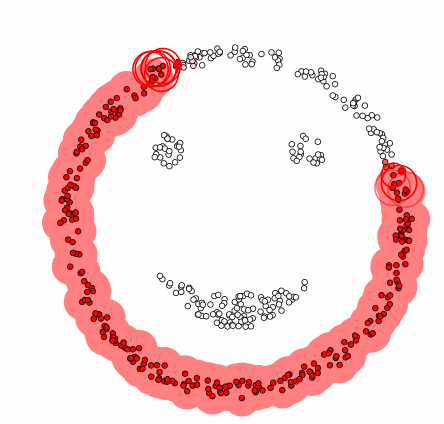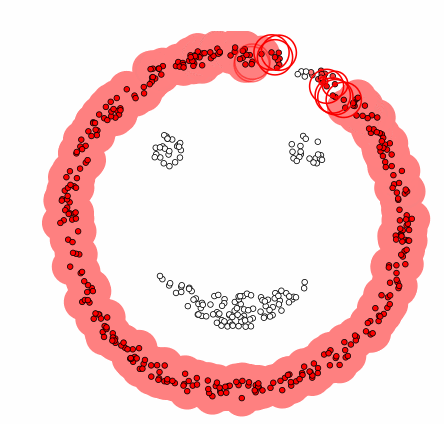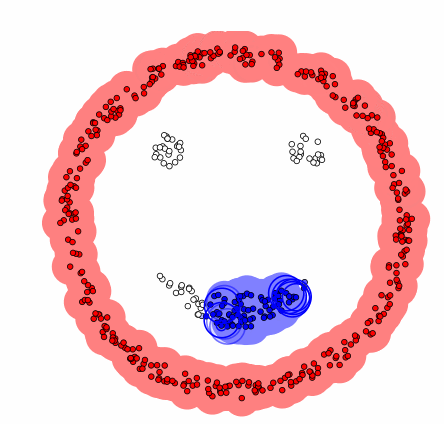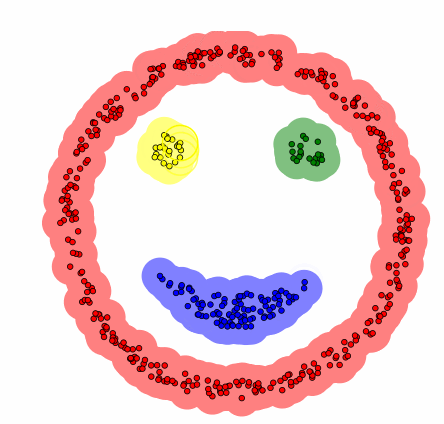
Density Estimation은 class 별 Data를 만들어냈을 것으로 추정되는 확률분포를 찾는 것으로 각 class별로 해당 class의 데이터를 잘 생성할 수 있는 확률분포를 만들고, 각 확률 분포에 대한 Test Data의 확률 계산하여, 가장 큰 확률을 주는 확률 분포의 class를 선택하는 것이다. 이를 기반으로 하는 Clustering 알고리즘이 DB-Scan이다.
DB - Scan의 장점이라고 한다면, 기하학적으로 Pattern이 있는 Clustering에 유리하고, K-means 알고리즘과 비교하여 Clustering의 개수를 따로 정해줄 필요가 없다.

다만, 다양한 density를 가지고 있는 데이터 형태는 군집화 성능이 떨어지며, 하이퍼 파라미터 값에 따라 클러스터링 결과가 크게 달라지며, 적정 하라미터 값 지정이 어렵다.
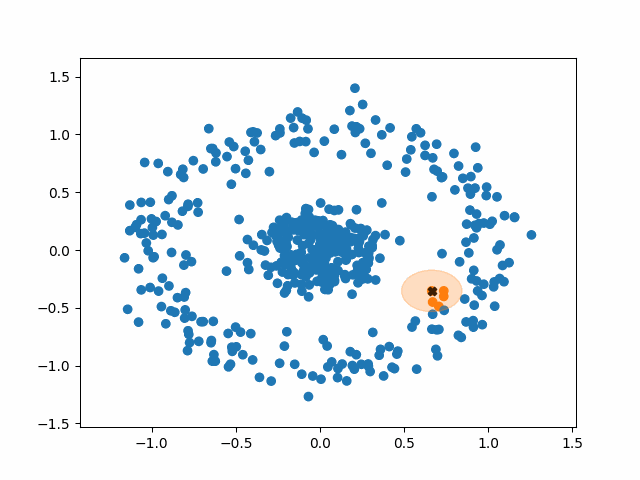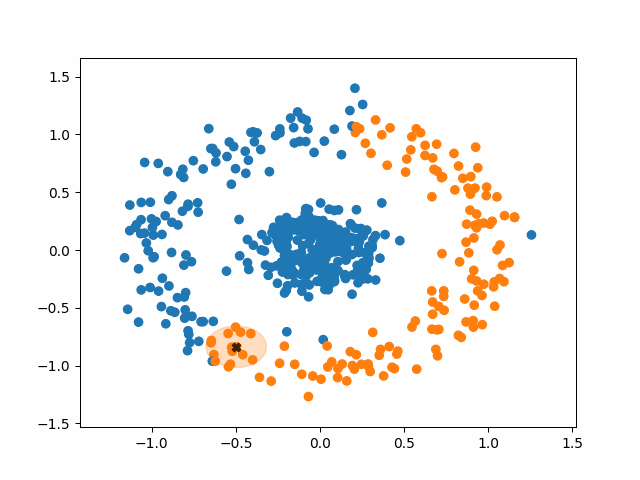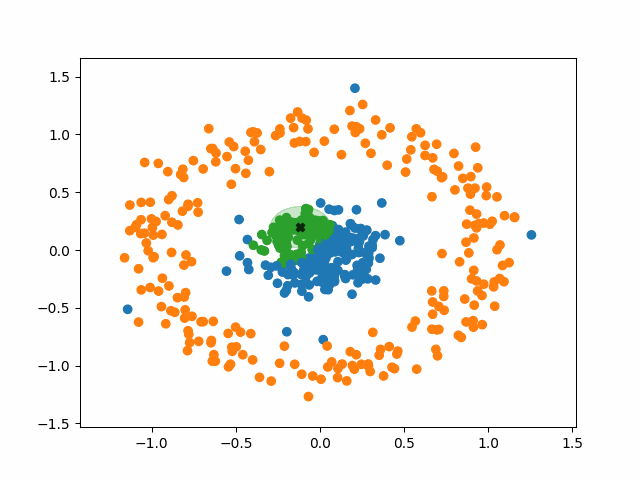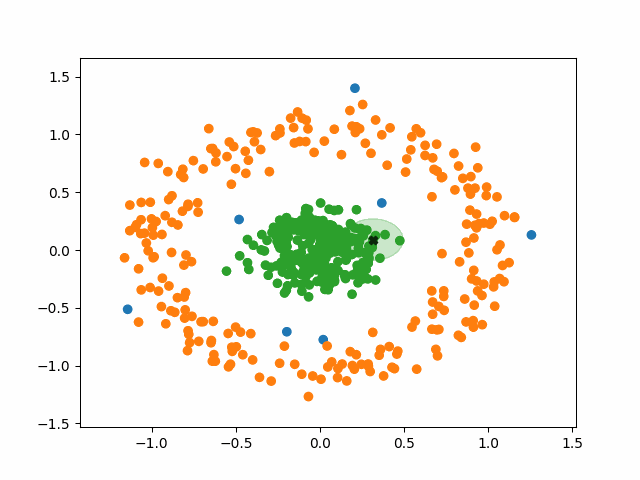
간단하게 용어를 한 번만 정리하도록 하겠다.
- (거리) : 하나의 점으로부터의 반경
- (Minimum Points) : Cluster를 이루기 위한 최소한의 Data수.
DB-Scan의 동작 과정
- 임의의 데이터 포인트 선택
- 선택한 데이터 포인트와 거리 내에 있는 모든 포인트 탐색
거리 내 데이터 포인트가 MinPts 이상: 초기 포인트를 Core Point로 지정
데이터 포인트가 MinPts 미만: 코어 포인트 포함 시 Border Point, 미포함 시 Noise Point - Cluster 내의 다른 Cluster의 Core Point가 있다면, 해당 Point를 Core Point로 하는 Cluster도 동일한 군집으로 간주
- 2번과 3번 과정을 반복하고, 모든 point가 Core Point / Border Point / Noise Point 중 하나로 구분되면 종료
수업에서는 Cluster Algorithm에 대해서 자세하게 다루지는 않았지만, Machine Learning 관련 내용을 공부하면서 정리했던 내용을 올렸다. 관심이 있다면 Unsuperviesed -Learning과 관련된 자료들을 찾아보면 좋을 것 같다. 다음 Chapter에서는 Localization과 관련된 내용을 다룰 것인데, 크게 Bayes Filter, Kalman Filter, Extended Kalman Filter에 대해서 설명하고, 추가적으로 Particle Filter의 특징 정도만을 정리해보고자 한다.
