AI(인공지능, artificial intelligence)
- 사람의 사고능력을 구현한 SW
1) Strong AI : 사람과 구별이 불가능🔥
2) Weak AI : 특정 분야에 국한된 AI(바둑, 자율주행, 챗봇 등)
우리는 결국 weak AI를 만들거예요
그러면 어떻게 만들까❓
CS쪽에서 데이터를 기반으로 학습 > 예측 하는 형태로 진행돼요
=> machine learning
지금까지 우리가 하고 있는 일반적인 program은 Rule Based program, Explicit program(규칙 기반 프로그램)이에요
Machine Learning
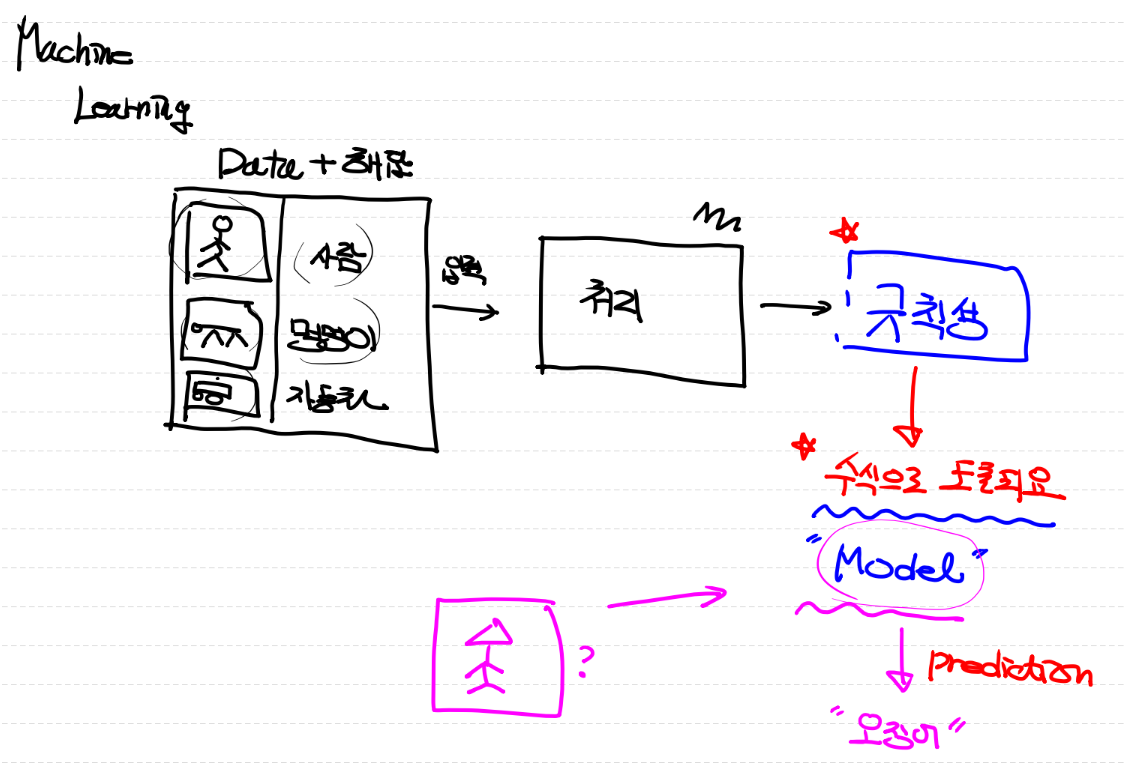
데이터가 들어가면 학습해서 규칙성을 찾아냄
규칙성이 수식(Model)으로 도출
✔️Machine Learning 기법
- ⭐Regression
- svm(support vector machine)
- decision tree, random forest
- KNN
- Naive Bayes
- ⭐Artificial newral network(ANN) -> 발전시킨게 딥러닝
- k-means, DBSCAN
- Reinforcement learning(강화학습)
➡️ 정형화된 Data는 일반 머신러닝 기법을 이용해요
➡️ 비정형 Data(이미지, 자연어, 소리 등)는 딥러닝
✔️Machine Learning Type
1) data/label -> program-> 규칙성model => 지도학습
2) data -> program -> clusting -> 비지도학습
3) data -> program -> clusting -> 준지도학습
4) 강화학습 (알파고같은~)
우리가 배울것은 지도학습
- Regression 기법

: 어떤 데이터에 대해 그 데이터의 영향을 주는 조건들의 영향력을 이용해서 데이터에 대한 조건부 평균을 구하는 기법
ex)
아파트 가격
우리나라의 아파트 가격은 얼마인가요?
(가격에 직접적으로 영향을 주는 요소? 지역, 평수, 학군 등)
💢즉, 조건들의 영향을 받아서 데이터가 생성됨
전체를 통으로 잡기보단 조건들을 고려하여 설정
y(가격) = 평수 8000 + 역세권 3000 + 학군 * 5000
=> 조건에 따른 가중치가 있음. 이러한 조건을 가지고 평균을 내는것
한마디로 평균 구하는거에요
=> 평균은 우리가 대표값을 가장 많이 이용하는 값
(최소값/최대값/평균값/최빈값(빈도높은) 으로 대표값을 설정할건지~~~)
평균은 데이터를 가장 잘 표현하는 값
⭐어떤 데이터에 대해 그 데이터에 영향을 주는 조건들의 영향력을 이용해서 데이터에 대해 가장 잘 표현하는 함수
- 독립변수 feature
: 독립적인 변수 - 종속변수 target
: 다른것에 의해 결정되는 변수
ex) 키, 몸무게 => 독립변수, BMI =>종속변수
연수기간, 공부시간 => 독립변수, 성적 => 종속변수
− 독립변수가 하나라면 우리의 모델은 어떻게 될까?
종속변수(예측치) = 가중치 독립변수 + 상수
⭐y = ax + b
(그래프 그림첨부)
- Regression model
독립변수가 1개일때 y = ax + b 로 만들어져요
classical linear regression model
독립변수가 2개일때 -> y = ax1 + bx2 + c 실제 그림을 그리면 평면으로 나옴
우리가 구해야하는 값 => a, b, c 회귀계수
즉, regression은 평균 구하는 기법!
평균으로 데이터를 잘 표현할 수 있는 데이터여야 의미가 있음.
평균을 사용하기 힘든 데이터라면 회귀모델 사용을 고려해봐야함
예를들어 이재용의 월급과 우리의 월급 같은,,,🥲평균으로 사용하기 적합한 데이터는?
ex) 평균 키(중간이 젤 많은, 편향되지 x)
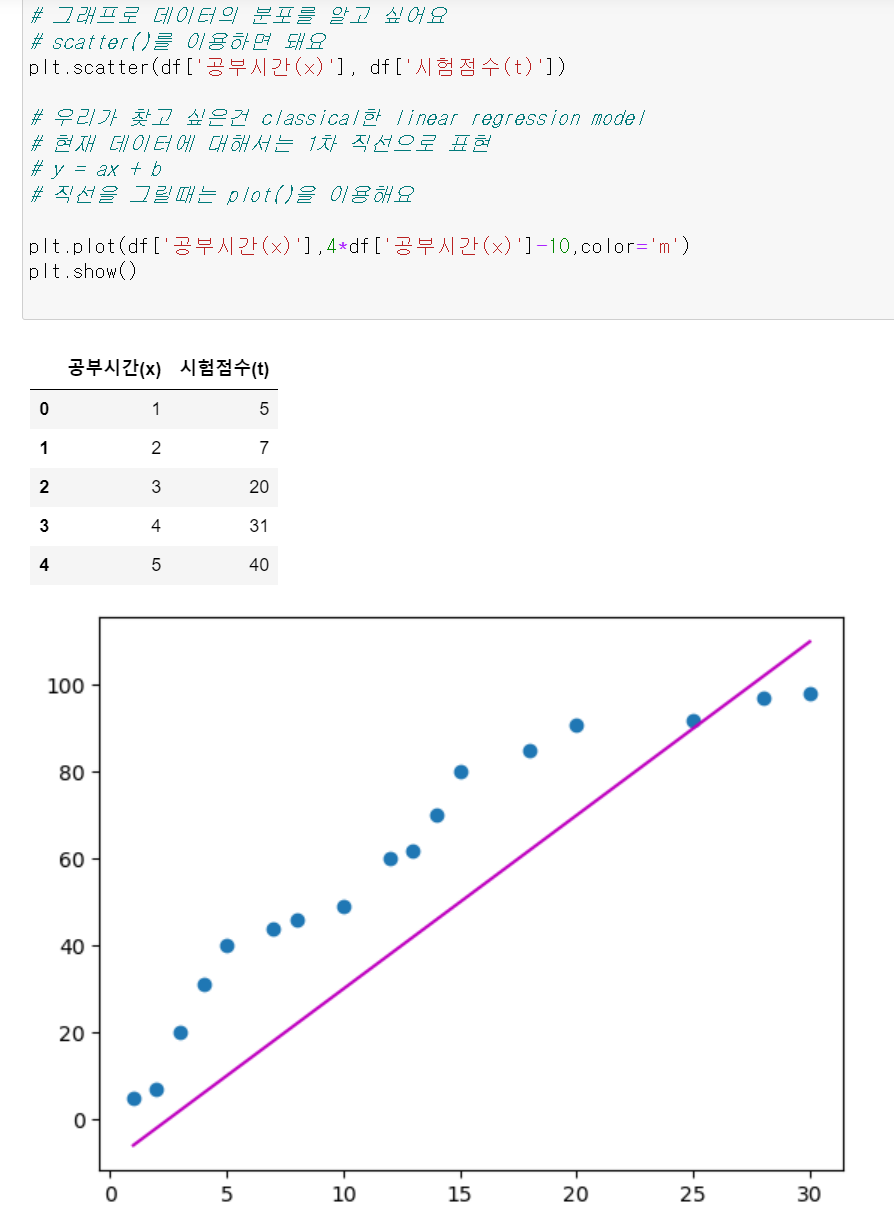
y = wx + b
이 그래프가 점들을 잘 표현하고 있는지 확인
어떻게 판단할것인지? Error(오차)가 적을수록 good
=> 평균 제곱 오차를 구한다(Mean Squared Error) y = wx + b
모델이 좋은지 나쁜지 판단하는 식을 통칭해서 loss fuction 비용함수 라고 함
위 경우 MSE가 적합
loss function은 '평균 제곱 오차MSE'로 판단
우리 loss는 결국 w b의 2차 함수
그래프로 그려보면 그래프가 U모양으로 그려짐
✔️loss가 낮아야 좋음
식을 어떻게 바꾸느냐?
y = x(입력으로 들어오는 2차원 matrix) * w(내가 구할 2차원 매트릭스) + b(상수)
model -> y = xw + b
loss -> mse(평균제곱오차) 이용
training dataset
- 대표적인 머신러닝 딥러닝 라이브러리
tensorflow(google)+keras
pytouch(meta)
