(복습)
Linear Regression
: 연속된 숫자를 결과로 반환하는 형태
독립변수가 1개 일 때 y = xw+b식을 이용
독립변수가 여러개가 되면 y = xw+b의 wx가 여러개가 됨
(keras를 이용하면 내부적으로 쉽게 계산 가능)
Logistic Regression
ex)
시간 연수 합격여부
1 1 fail
3 1 fail
2 3 success
10 1 success
5 2 success
나는 4시간 공부하고 연수를 2년 했을 때 합격할까 불합격할까?
fail과 success는 숫자 0과 1로 표현이러한 문제를 처음에는 우리가 공부했었던 linear regression으로 해결하려고 해봤어요!
-> 안돼요!❓그럼 어떻게 하면 될까요?
Sigmoid라는 식을 이용해요
sigmoid공식이란?

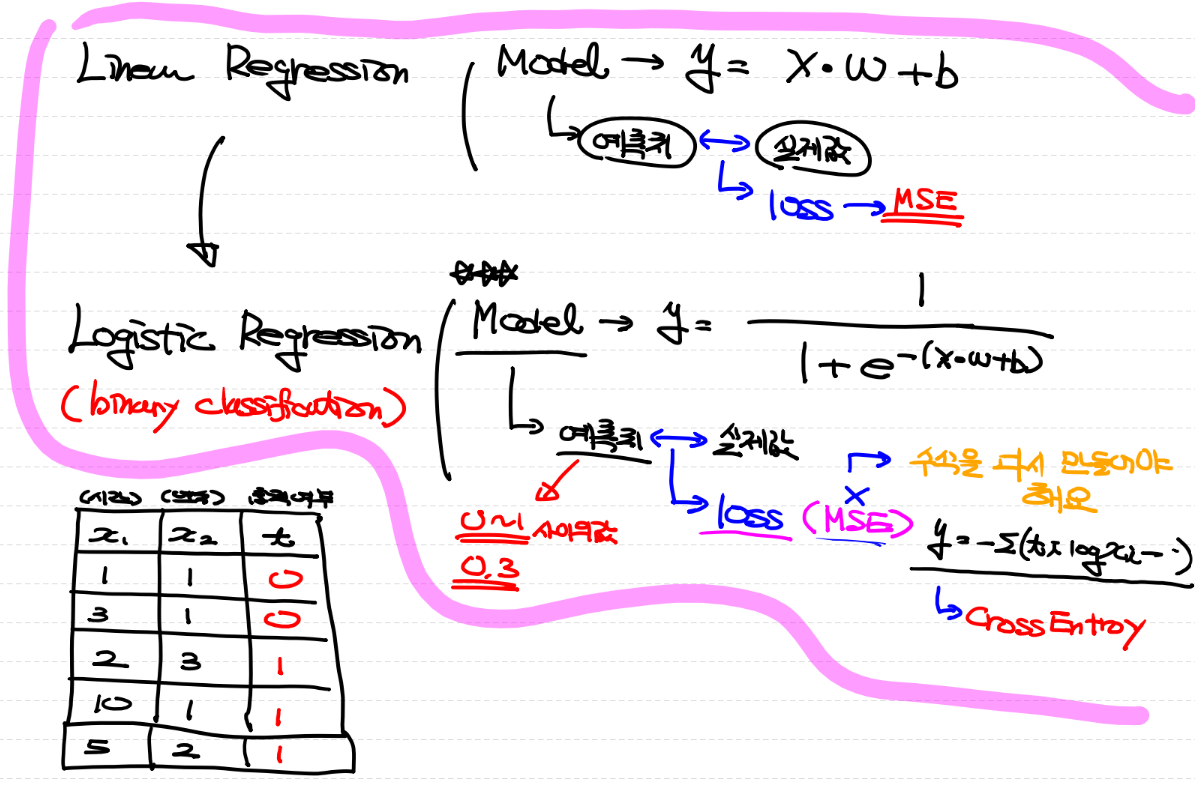
*기본적으로 library가 해결해줌 그러나 방식에 대해 알고 있어야 한다
Multiple Linear Regression
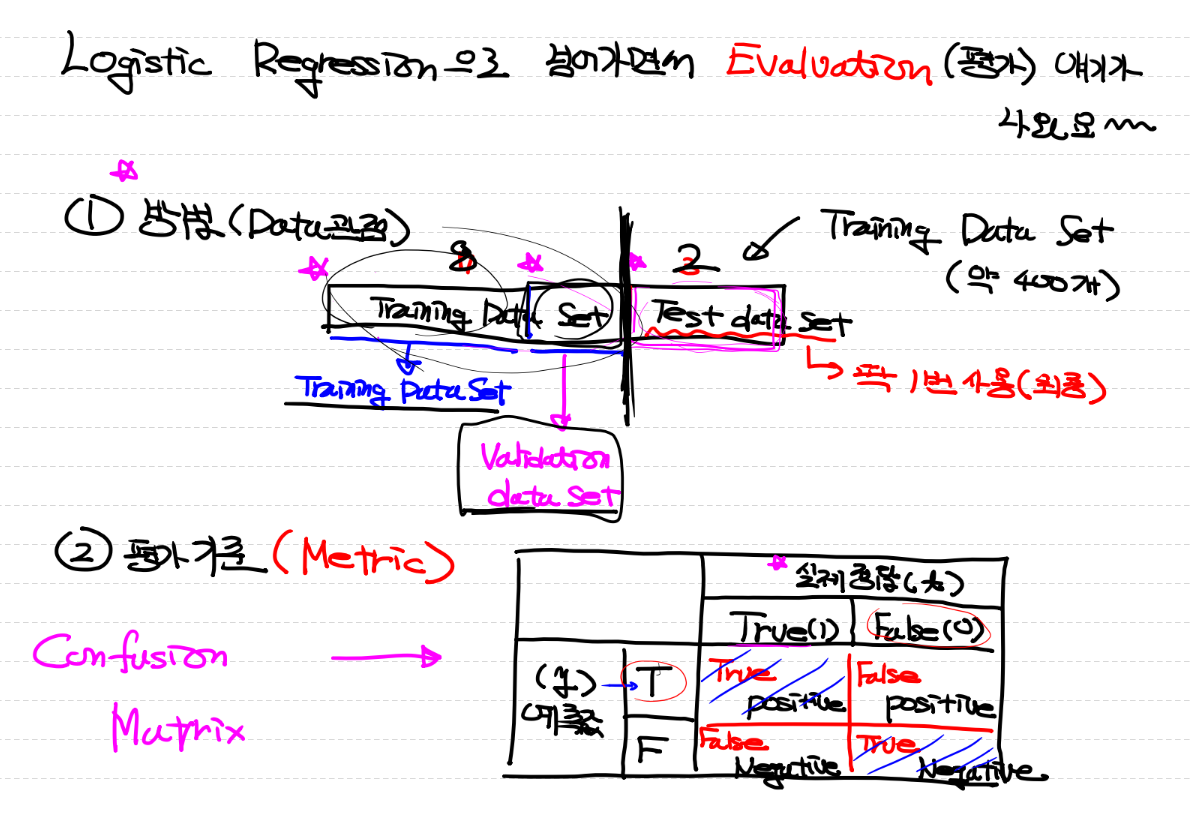
회귀모델을 만들기 전에 모델의 성능을 평가하기 위해
훈련(train)과 테스트(test) 데이터로 나눈다
훈련데이터를 사용해서 학습을 하여 모델을 만들고 학습에 사용하지 않은 테스트데이터를 얼마나 잘 맞추는지가 중요
(나누는 이유 : 나눠야 모델의 예측 성능을 제대로 평가할 수 있다)
Training and testing
Training set으로 모델을 학습시키고, Test set으로 모델의 accuracy를 평가
# 다중선형회귀를 구현해 보아요
# 오존 데이터를 가지고 모델을 만들어볼거에요
# 1. 필요한 모듈을 불러들여요
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Flatten, Dense
from tensorflow.keras.optimizers import Adam
# 2. Raw Data Loading
raw_data = pd.read_csv('./data/ozone.csv')
display(raw_data.head(), raw_data.shape)
# 결측치 처리
raw_data = raw_data.dropna(how='any')
display(raw_data.head(), raw_data.shape)
# 이상치는 처리하지 않을게요
# 정규화는 진행해야해요
# 정규화는 MinMaxScaling을 통해 진행할거에요
scaler_x = MinMaxScaler()
scaler_t = MinMaxScaler()
# scaler한테 최대값과 최소값을 알려줘야 이놈이 그 정보를 가지고 정규활르
# 진행할 수 있어요(scaler에게 정보를 줄 때는 2차원 matrix로 줘야해요)
scaler_x.fit(raw_data[['Solar.R','Wind','Temp']].values)
scaler_t.fit(raw_data['Ozone'].values.reshape(-1,1))
# 3. Training Data Set
x_data = scaler_x.transform(raw_data[['Solar.R','Wind','Temp']].values)
print(x_data)
t_data = scaler_t.transform(raw_data['Ozone'].values.reshape(-1,1))
print(t_data)
# Model
model = Sequential()
# Layer추가
model.add(Flatten(input_shape=(3,)))
model.add(Dense(1,activation='linear'))
# Model 설정
model.compile(optimizer=Adam(learning_rate=1e-4),
loss='mse')
# Model학습
model.fit(x_data,
t_data,
epochs=2000,
verbose=0)
# 모델이 완성이 됐다고 생각하면
# 예측 작업에 들어가요
# 예측하고 싶은건... 태양광 세기가 150, 바람이 10, 온도가 80일 경우 오존량 예측
predict_data = np.array([[150.0, 10.0, 80.0]])
scaler_predict_data = scaler_x.transform(predict_data)
# print(scaler_predict_data)
result = model.predict(scaler_predict_data)
# print(result)
final_result = scaler_t.inverse_transform(result)
print(final_result)# logistic Regression을 구현해보아요
# binary Classification(이항분류)
# 처음은 당연히 필요한 모듈 불러들이는것부터 시작
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler # 정규화
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Flatten, Dense
from tensorflow.keras.optimizers import Adam
# Raw Data Loading + 데이터 전처리
# 데이터 전처리는 크게 3가지만 진행
# 1. 결측치
# 2. 이상치
# 3. 정규화
df = pd.read_csv('./data/admission.csv')
# display(df.head(), df.shape) # (400, 4)
print(df.info()) # 확인했더니 결측치가 없어요 - 처리할 필요x
# 이상치 처리인데.. 사실 이 데이터는 이상치가 존재해요
# 이상치를 처리하는 방법은 여러가지 방법이 있어요
# 가장 대표적인 방법은 크게 2가지에요
# 1. Tuky Fence(4분위를 이용하는 방법)
# 2. Z-score 방식(정규분포를 이용하는 방법)
# 여기서는 2번 Z-score방식으로 이상치를 걸러내서 사용할거에요
from scipy import stats
zscore_threshold = 2.0 # zscore outliers 임계값 (2.0이하가 optimal)
for col in df.columns:
outliers = df[col][(np.abs(stats.zscore(df[col])) > zscore_threshold)]
df = df.loc[~df[col].isin(outliers)]
# print(df.shape) # (382, 4)
# 3. 정규화를 진행해야해요
scaler = MinMaxScaler()
scaler.fit(df[['gre','gpa']].values)
from sklearn.model_selection import train_test_split
# Training Data Set
x_data = scaler.transform(df[['gre','gpa']].values)
# print(x_data)
t_data = df['admit'].values.reshape(-1,1)
x_data_train, x_data_test, t_data_train, t_data_test = \
train_test_split(x_data,
t_data,
test_size=0.2)
# Model
model = Sequential()
# Model에 Layer추가
model.add(Flatten(input_shape=(2,)))
model.add(Dense(1, activation='sigmoid'))
# Model설정
model.compile(optimizer=Adam(learning_rate=1e-3),
loss='binary_crossentropy',
metrics=['accuracy'])
# Model학습
model.fit(x_data_train,
t_data_train,
epochs=500,
validation_split=0.2,
verbose=1)
지니야 코딩 해줘