2022년 3월에 발표된 차선 인식 model인 'CLRNet'에 대해서 작성해보겠다.
해당 논문을 거의 반년동안 보았다. 코드를 수정하고 개발하며 카롱이(erp-42)에 적합하게 만들었다. 결론적으로 말하면 대회때 사용하지는 못했다.
그래도 이번 논문 리뷰 이후에 카롱이에 어떻게 적합하게 만들었는지, 추가적인 기술은 어떤 것을 이용하였고 어떻게 제어했는지 작성할 예정이다.
Abstract
이 논문에서 가장 강조하는 것은 차선은 높은 수준(high-level)의 semantics과 낮은 수준(low-level)의 semantics을 동시에 사용해야 정확한 차선을 추출할 수 있다는 것이다. High-level feature를 이용하여 차선을 검출하고 low-level feature를 이용해서 차선의 위치 개선한다. 두 특성을 모두 사용하여 차선을 예측하는 새로운 model인 Cross Layer Refinement Network (CLRNet)을 발표했다.
또한 global context를 얻기 위해서 ROIGather를 제안했으며, 새로운 loss로 Line IOU loss를 제안하였다.
CLRNet은 state-of-the-art(SOTA)에 등록됐었으며 현재 CULane부분에서 CLRNet기반으로 만든 CLRerNet이 SOTA를 기록중이다.(https://paperswithcode.com/task/lane-detection)
1. Introduction

-
그림 (a)는 low-level 특성만 이용해서 차선을 인식한 사진이다.
Computer Vision에서 말하는 low-level은 corners, edges, angles, and colors등이 있다. 해당 사진에서는 low-level 특성으로만 예측하여 화살표를 차선으로 잘못 인식한 모습을 나타낸다. -
그림 (b)는 high-level로만 이용해서 차선을 인식한 사진이다.
High-level semantics은 items, scenes, and behaviors와 같은 전체적인 모습을 의미한다. 해당 그림은 차선은 인식하지만 location, 즉 차선의 위치가 정확하지 않은 것을 알 수 있다. -
보이지 않는 폐색 문제(occlusion problem)를 꼽았다. 그림 (c)는 차량에 의해서 차선이 안 보이는 경우, 그림 (d)는 햇빛에 의해서 안 보이는 사진이다.
기존의 몇몇 방식들은 pixel-wise 예측하며 차선을 전체 단위로 보지 않아 성능이 떨어진다고 한다.
CLRNet은 먼저 high-semantic features를 이용해서 line이 어디 있는지 대충(coarsely) 잡는다. 이후 low-level를 이용해서 차선이 어디에 있는지 보정해준다.
차선이 안 보이는 문제를 해결하기 위해서 ROI lane feature와 whole feature map 연관시킴으로써 global contextual information을 얻는 ROIGather를 도입하였다.
예측한 차선과 정답과의 loss를 새롭게 정의한 Line IOU (LIOU)를 도입하였다. LIOU는 차선을 하나의 단위로 차선을 예측하고 smooth- loss와 비교하여 성능을 개선한다.
Main contribution:
-
저수준 및 고수준 기능이 차선 감지를 위해 상호 보완적임을 입증하고, 차선 감지를 위해 저수준 및 고수준 기능을 충분히 활용하기 위한 새로운 네트워크 아키텍처(CLRNet)를 제안합니다.
(We demonstrate low-level and high-level features are complementary for lane detection, and we propose a novel network architecture (CLRNet) to fully utilize low-level and high-level features for lane detection) -
다른 네트워크에도 연결될 수 있는 global context를 수집하여 차선 특징의 표현을 더욱 향상시키기 위해 ROIGather를 제안합니다.
(We propose ROIGather to further enhance the representation of lane features by gathering global context, which can also be plugged into other networks.) -
차선 감지를 위해 조정된 LIOU(Line IoU) loss를 제안하고, 전체 단위로 차선을 회귀시키고 성능을 크게 향상시킵니다.
(We propose Line IoU (LIoU) loss tailored for lane detection, regressing the lane as the whole unit and considerably improving the performance.) -
다양한 감지기의 지역화 정확도를 더 잘 비교하기 위해 새로운 mF1 metrics 채택합니다. 우리는 제안된 방법이 세 개의 차선 감지 벤치마크에서 다른 최첨단 접근 방식을 크게 능가함을 입증합니다.
(To better compare the localization accuracy of different detectors, we also adopt the new mF1 metrics. We demonstrate the proposed method greatly outperforms other state-of-the-art approaches on three lane detection benchmarks.)
2. Related work
2-1. Segmentation-based methods
차선을 segmentation, 즉 픽셀을 이용하여 예측하는 방식이다.
SCNN은 좋은 성능을 보이고 있지만 속도가 느려서 real-time에 적합하지 않다.
이를 보완한 RESA는 real-time에 적합하다.
CurveLane-NAS는 curve lane을 정확하게 찾는 neural architecture이다. 하지만 GPU를 엄청 많이 소모한다.
따라서 이러한 segmentation-based 방식은 차선을 하나의 단위로 보는 것이 아니라 픽셀 단위로 예측을 하기 때문에 비효율적이고 시간 소모가 많다.
2-2. Anchor-based methods

Anchor-based 방식은 line anchor-based 방식과 row anchor-based 방식으로 나뉜다.
Line anchor-based 방식은 Line-CNN 논문을 통해서 시작되었으며 line anchor를 이용하여 line을 인식하는 방법이다. 이후 LaneATT, SGNet이 발표되었다.
Row anchor-based 방식은 미리 정의된 각 row에 대하여 가능한 cell을 예측하는 방식이다. UFLD가 처음으로 row 방식을 제안하였다. 빠른 추론 속도를 가지고 있지만 좋은 성능을 가지고 있지는 않다. 이후 발표된 CondLaneNet은 conditional lane detection을 도입하였다.
이들의 한계로는 복잡한 상황에서는 처음 start point를 특정하기 어렵다는 것이다.
2-3. Parameter-based methods
Parameter-based 방법은 차선 곡선을 parameter로 모델링하고 이러한 parameter들을 회귀한다.
PolyLaneNet이 polynomial regression problem을 얘기하고 좋은 결과를 냈다.
LSTR은 transformer를 이용하여 차선을 예측하는 방법이다.
Parameter-based 방식은 회귀할 parameter가 적다는 장점이 있지만 예측된 매개변수에 민감하다. 예를 들어 고차 계수에 대하여 잘못 인식하는 경우 아예 다른 차선 모양이 나오게 된다.
따라서 parameter-based 방식은 매우 빠른 inference 속도를 가지고 있지만 성능이 좋지 않다.
3. Approach
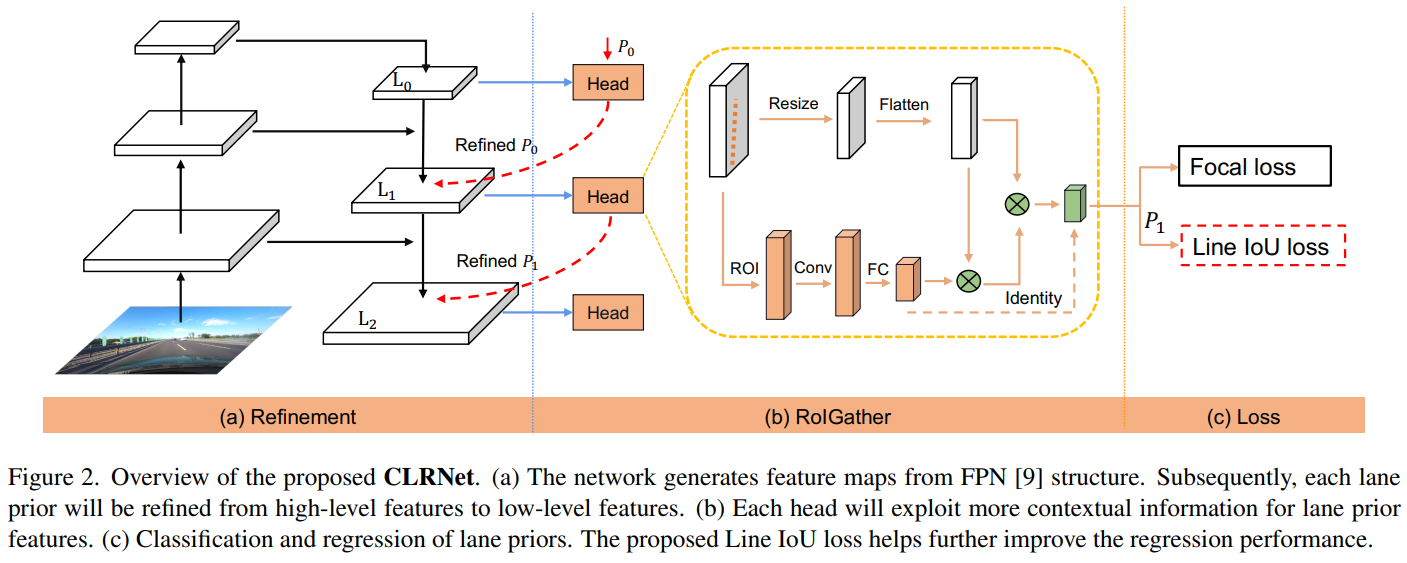
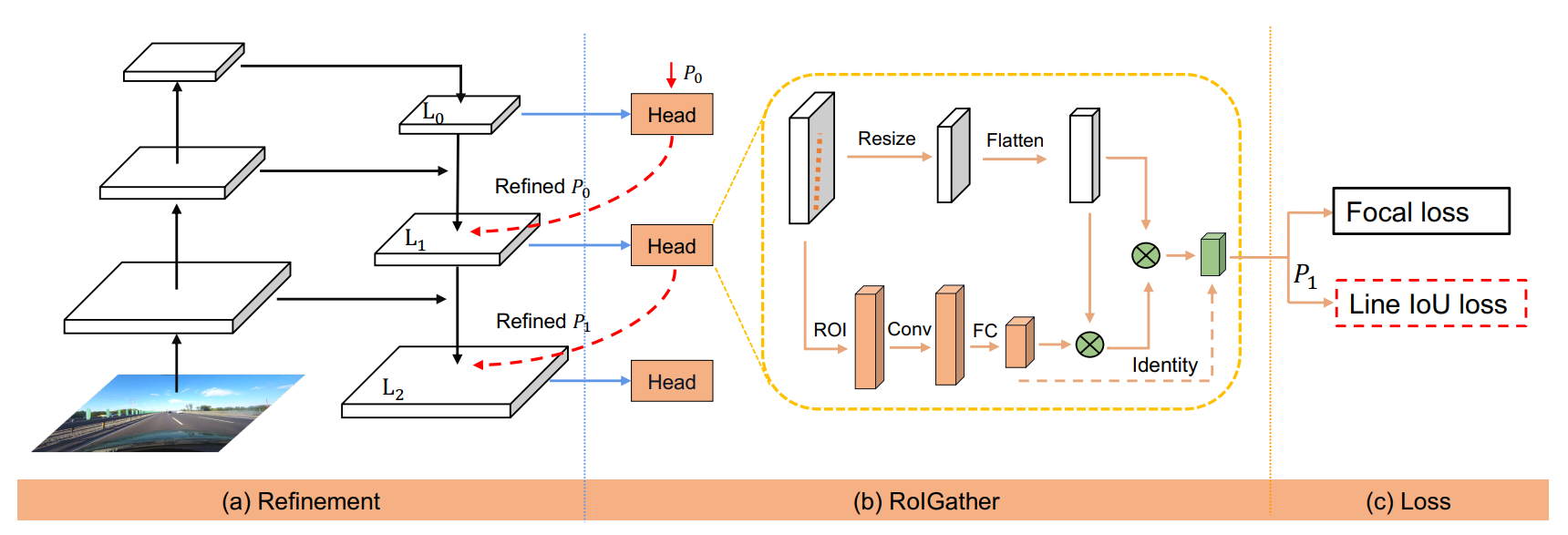
CLRNet의 전체적인 모습
3.1 The Lane Representation
일반적인 object detection에서 object들은 직사각형 box로 표현된다.
하지만 차선은 긴 선이기 때문에 직사각형 box로 표현되기 어렵다. 때문에 다른 논문(Line-cnn: End-to-end traffic line detection with line proposal unit와 Keep your Eyes on the Lane: Real-time Attention-guided Lane Detection)에서 제시된 2D-points를 사용하는데, 차선을 점으로 표시한다는 얘기이다.
으로 표현하며 좌표는 이미지의 높이를 점의 개수로 동등하게 나눈 것이다.
즉, 이며 는 이미지의 높이(height)이다.
이렇게 점으로 표현하는 것을 Lane Prior라고 정의했다.
각각의 lane prior는 아래의 4가지 요소로 구성된다.
1) foreground와 background의 확률
2) lane prior의 길이
3) 차선의 start point와 x축과의 lane prior 사이의 각도
4) prediction과 ground truth의 수직차이 (N offsets)
3.2 Cross Layer Refinement
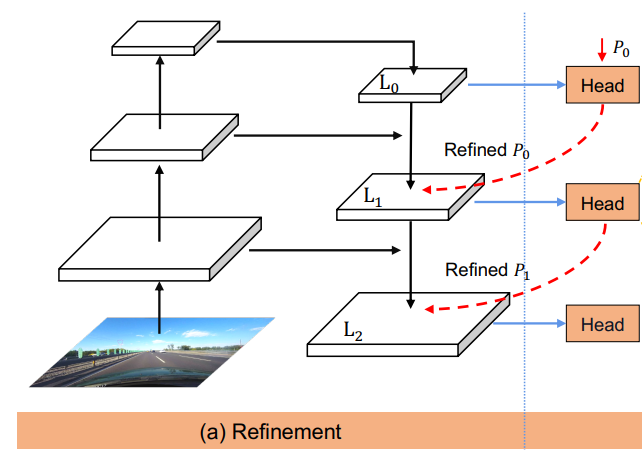
Motivation
High-level과 low-level을 사용하기 위해서 Feature pyramid networks for object detection(FPN)을 이용한다.
Refinement structure
Low-level에서 high-level로 가는 ConvNet's pyramidal feature hierarchy를 사용하며 전체적으로 high-level semantics를 구축한다.
Resnet을 backbone으로 사용하는 FPN에 의해 가 생성된다.
Cross layer refinement는 high-level인 에서부터 로 진행하며, 이를 라고 나타낸다.
(t는 개선(refinement)의 전체 개수이다.)
는 가 image plane에 균등하게 분배되어 있다. 는 를 input으로 받아 ROI lane feature를 얻고 개선된 parameter 를 얻기 위해 2개의 FC layer를 거친다.
FPN으로 얻은 layer와 이전 lane prior를 통해서 refinement를 얻고 이를 lane prior에 다시 넣어(합성함수) 현재의 lane prior를 만드는 방식이다.
3.3 ROIGather
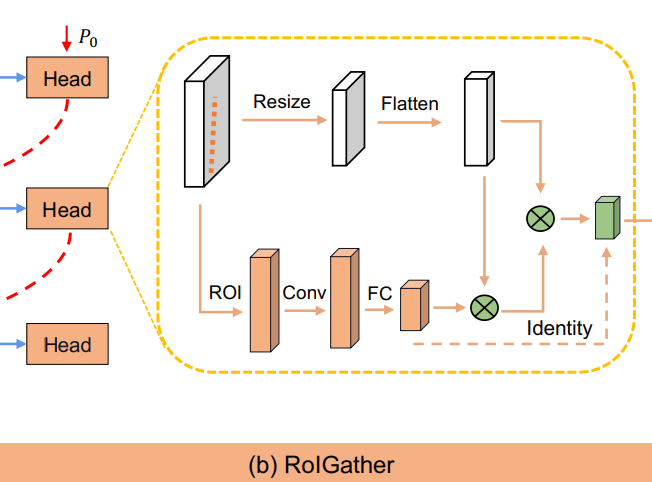
Motivation
차선의 no visual, 즉 안 보이는 경우를 해결하기 위해서 ROIGather를 사용했다. Global context를 계속 확인하여 차선을 인식한다.
ROIGather structure
ROIGather는 feature map과 lane prior를 input으로 입력받는다. 각각의 lane prior에 대해서 lane prior의 feature를 얻기 위해 ROIAlign을 진행한다.
일반 bounding box와 달리 bilinear interpolation을 사용하였으며, 가까운 lane pixel을 이용하기 위해서 convolution을 수행하였다. 마지막으로 메모리를 아끼기 위해서 FC를 사용했다. 이렇게 추출된 값을 lane prior feature이라고 한다.
처음 input으로 들어온 feature map을 resize하고 flatten한 것을 global feature map이라고 한다.
Global context를 얻기 위하여 아래와 같은 식을 진행한다:
, is
이렇게 구해진 는 attention matrix이다.
이렇게 구한 로 를 구한다. 를 다시 에 더하여 결과를 구한다.
3.4 Line IoU loss
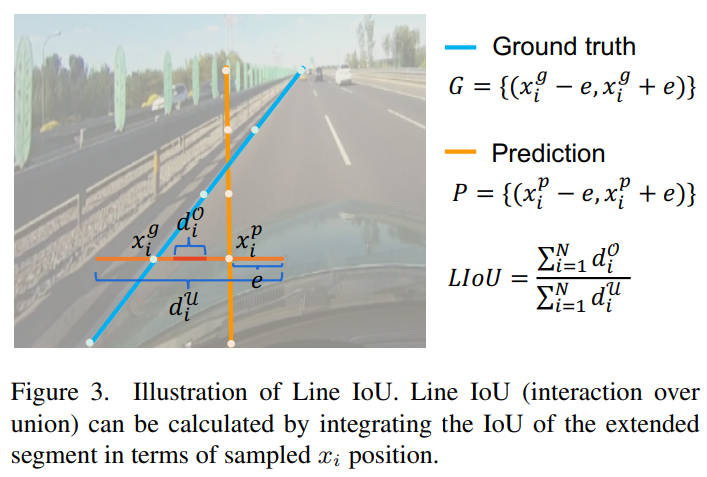
Motivation
차선의 회귀를 위해서 smooth-을 사용하는 대신에 Line Intersection over Union (LIoU) loss 를 도입하였다.
Formula
IoU에 대한 공식은 다음과 같다.
는 점의 ground truth, 는 점의 prediction, 는 prediction의 radius이다. 한 마디로 오차범위를 둔다고 생각하면 될 것 같다. IoU는 음수가 나올 수 있는데, 이는 겹치지 않는 경우를 최적화 할 수 있다고 한다.
LIoU는 IoU의 모든 점들의 합이며, LIoU loss는 1에서 LIoU를 뺀 값이다.
이때, 의 값은 -1과 1사이의 값을 갖는데 1이면 차선이 잘 예측된 것이고 -1이면 예측을 잘 못한 것 이다.
LIoU Loss에 대한 장점은 아래와 같다.
(1) 단순하고 미분 가능하여 병렬 연산 구현이 매우 용이하다.
(It is simple and differentiable, which is very easy to implement parallel computations.)
(2) 전체 단위로 차선을 예측하여 전체 성능을 향상시키는데 도움이 된다.
(It predicts the lane as a whole unit, which helps improve the overall performance.)
3.5 Training and Inference Details
-
Positive samples selection
: focal cost between predictions and labels
: similarity cost between predicted lanes and ground truth
: average pixel distance of all valid lane points
: distance of start point coordinates
: difference of the theta angel
: weight coefficients of each defined commponent -
Training Loss
: focal loss between prediction and labels
: smooth- loss for the start point coordinate, theta angle and lane length regression
: Line IoU loss between the predicted lane and ground trouth
4.Experiment
4.1. Datasets
차선에 있어서 3개의 benchmark dataset을 이용하였다:CULane, Tusimple, LLAMAS
-
CULane: 100,000개의 train, validation, test sets로 구성되어 있으며 다양한 환경과 날씨에 대한 데이터를 보유하고 있다. 1640 x 590 pixels
-
LLAMAS: 마찬가지로 100,000개의 이미지로 구성되어 있다. 1276 x 717 pixels
-
Tusimple: 3268개의 training images와 358개의 validation, 2782개의 testing data로 구성되어 있다. 1280 x 720 pixels
4.2. Implemeatation details
ResNet과 DLA를 backbone으로 사용하였다.
320 x 800의 resize를 진행하며 data augmentation으로 random affine transformation(translation, rotation, scaling)을 진행해준다. (코드에서는 800x320으로 resize되어있는데 논문 저자에게 메일을 보내봤지만 답이 없다.,..)
Optimizer로 AdamW를 사용하며 learning rate는 1e-3와 cosine decay learning rate를 power set to 0.9로 설정하여 사용하였다.
CULane은 15 epochs, Tusimple은 70 epochs, LLAMAS는 20 epochs를 각각 설정하였다.
이 밖에도 Lane prior , sampled number , ROIGather의 resized , LIOU에 사용되는 extended radius . .
4.3. Evaluation Metric
평가 지표로 F1-measure를 사용하였다.
F1 score는 precision과 recall의 조화평균으로 분류 class간의 data 불균형이 심각한 경우에 사용한다고 한다.
IoU(intersection-over-union)의 true posivies(TP) threshold는 0.5, 즉 50%의 확률이 넘으면 차선으로 인식한다는 것이다.
또한 새로운 지표인 mF1을 제시하였다.
이는 IoU threshold가 각각 0.5, 0.55, ... ,0.95 일 때의 값의 평균을 구한 것이다.
4.4 Comparision with the state-of-the-art results
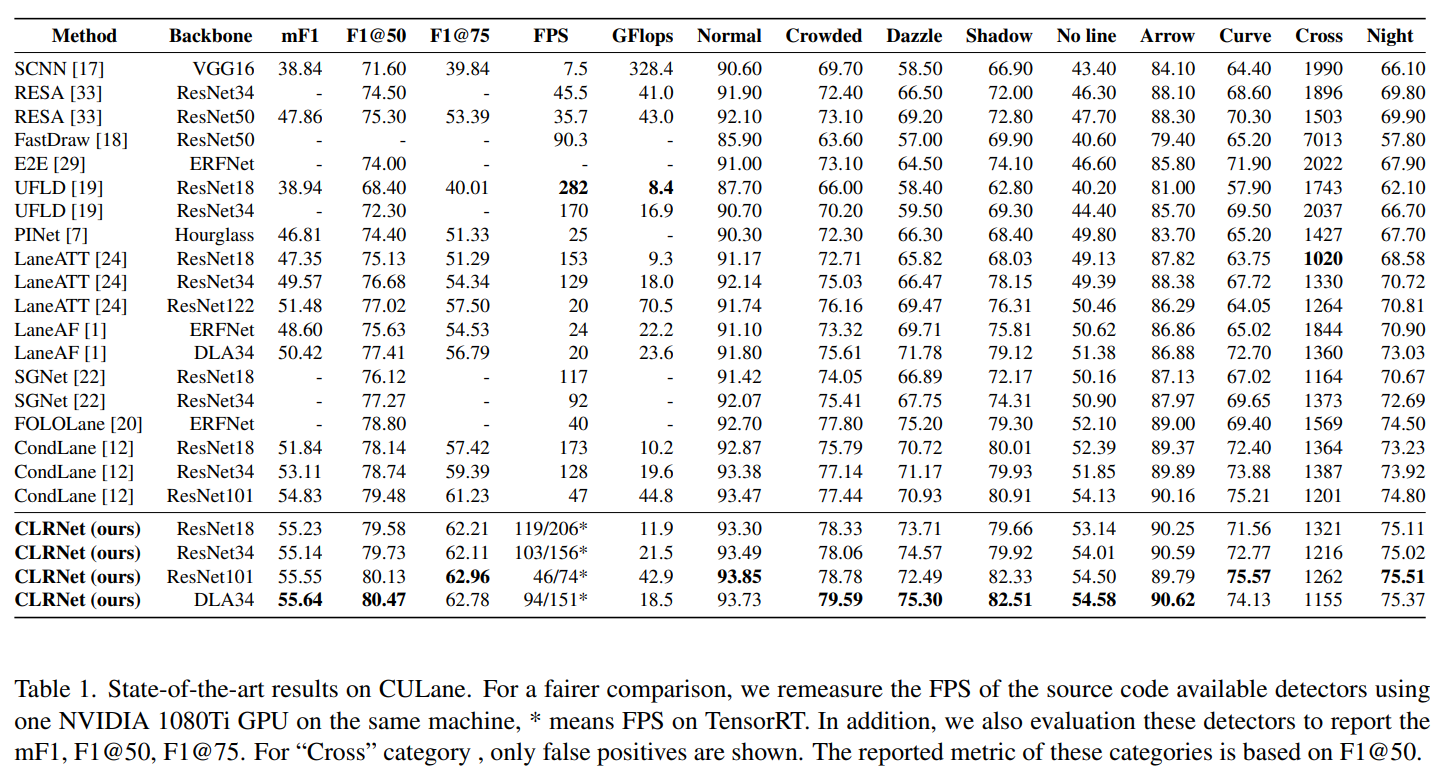
표를 보면 새로 제시한 mF1, threshold가 각각 0.5와 0.75인 F1 score가 모두 높은 것을 확인 할 수 있다. 위 결과는 CULane dataset으로 진행한 결과이다. TensorRT를 사용하면 ResNet18의 FPS가 206까지 나오는 것을 확인할 수 있다.
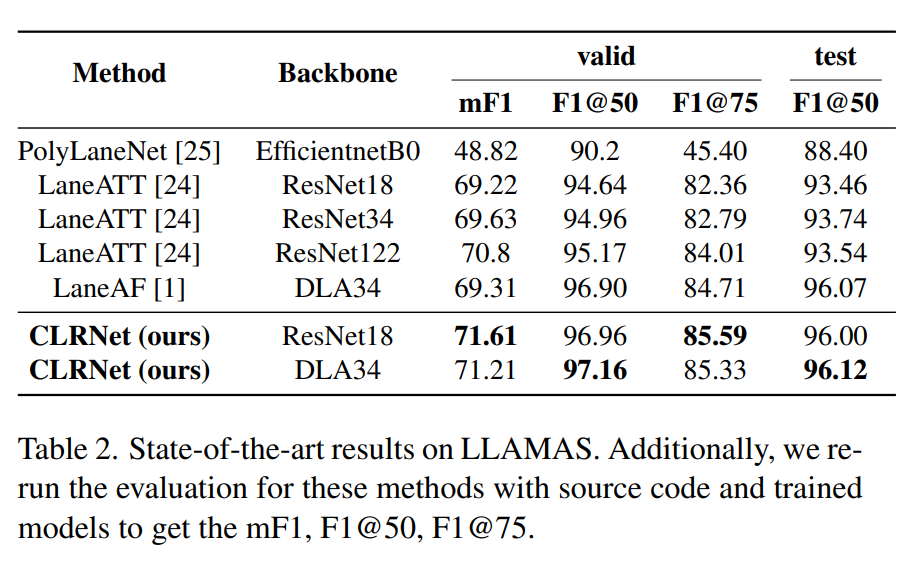
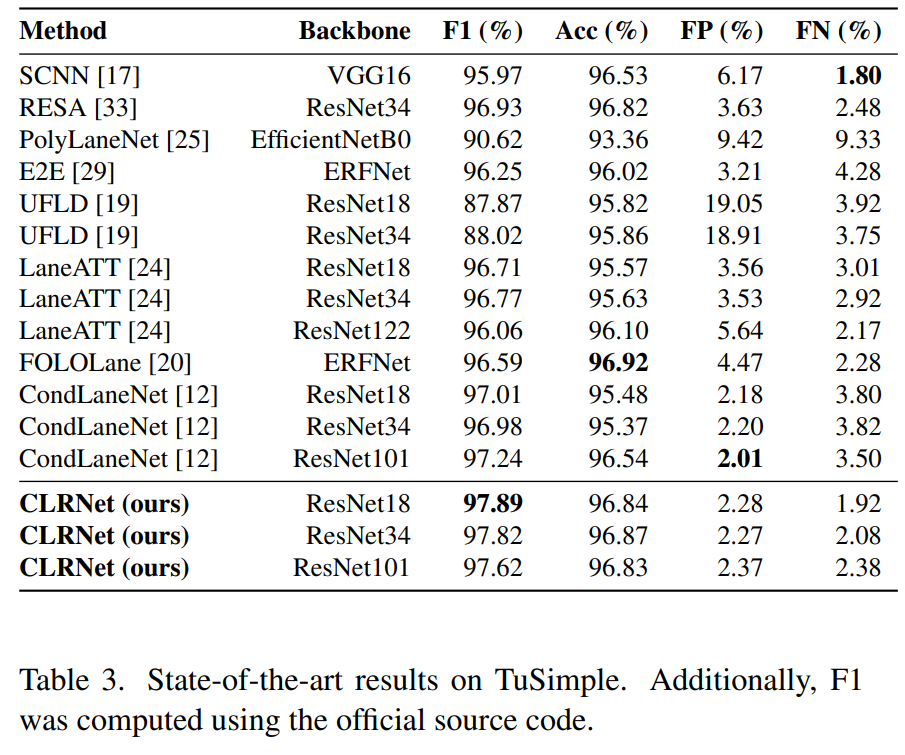
LLAMAS(Table 2)와 Tusimple(Table 3)로 진행한 결과도 높은 F1 score를 얻은 것을 볼 수 있다.

CULane과 Tusimple dataset을 이용하여 나온 결과이다. x축에는 Inference하는 시간을, y축에는 F1 score를 그렸다. 주황색인 CLRNet을 보면 꽤 빠른 편에 속한 것을 볼 수 있으며, 결과가 제일 높은 것을 확인할 수 있다.
4.5 Ablation study
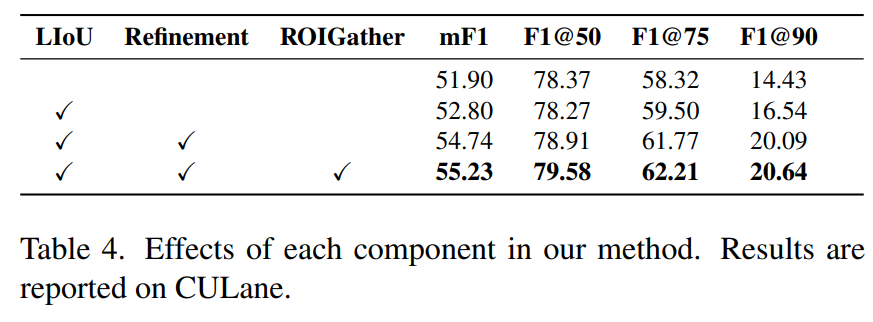
LIoU loss, Cross Layer Refinement, ROIGather에 대해서 ablation study를 진행했다. ResNet18 환경에서 진행하였으며, 추가함으로써 F1 score가 증가하는 것을 확인할 수 있다.
-
ROIGather
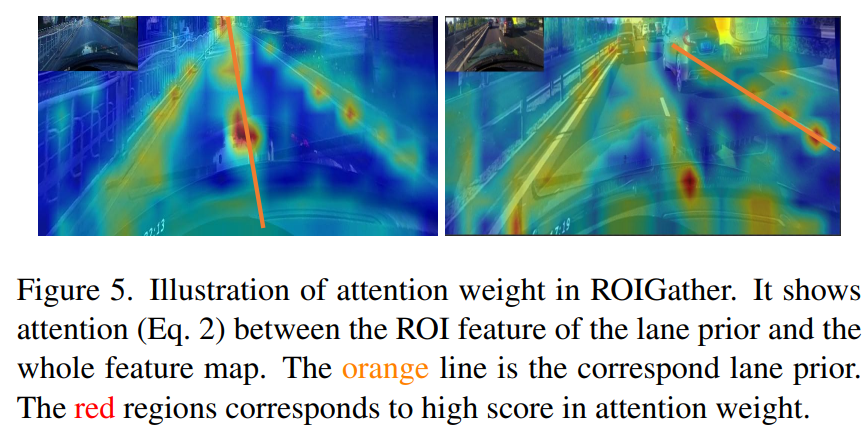
위 사진은 ROIGather의 성능을 확인하기 위해서 attention map을 시각화 한 사진이다. 주황색 선이 lane prior의 ROI feature이며, 이와 전체 feature map의 attention weight를 사진으로 나타낸 것이다.
왼쪽은 global context를 효과적으로 얻은 것이고 오른쪽은 occlusion에 대해서 차선을 예측하여 잘 표현한 것을 나타낸다. -
Cross Layer Refinement
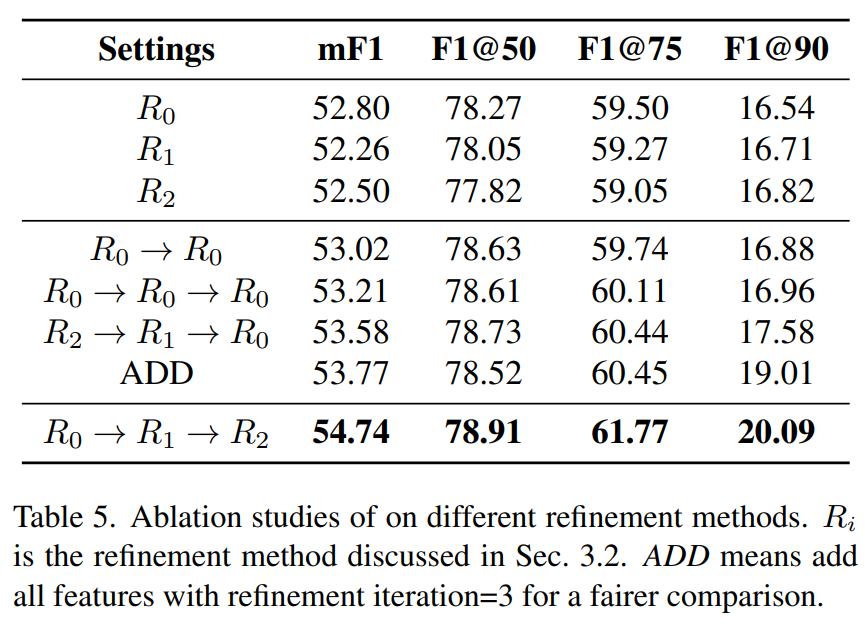
Layer 하나씩 진행한 결과부터 순서를 바꿔가며 진행한 결과와 최종적으로 진행한 결과까지 나타냈다.
각각의 결과에서 의 F1@90이 상대적으로 높다. 이는 low-level feature가 lane accuracy를 regress하는데 도움을 준다는 의미이다. 하지만 이는 high semantic information을 잃어버리기 때문에 다른 layer와 같이 결합하여 사용하면 더 좋은 성능을 얻을 수 있다. 가 상대적으로 좋은 성능을 내기 때문에 에서 더하는 방식을 택했다. -
Line-IoU Loss

Smooth- loss는 regress를 위해서 사용하는 loss이다. 기본적으로 L1 loss를 택하고 있지만 미분을 위해서 예측값과 실제값이 매우 작은 부분에서만 L2 loss를 택하는 loss function이다. Decreasing weight가 0.5까지 내려가야 좋은 성능을 확인 할 수 있는 반면에, 새로 제시한 LIoU는 안정적이고 더 좋은 성능을 내는 것을 확인할 수 있다.
6. Conclusion
CLRNet은 high-level feature를 통해서 차선을 예측하고 low-level feature를 통해서 차선의 위치를 개선해 나간다.
차선이 안 보이는 occlusion을 해결하기 위해서 ROIGather를 사용하였다.
차선을 한 단위, 개체로 보기 위해서 Line IoU loss를 제시하였다.
느낀점
블로그 글을 작성하는데 정말 오랜시간이 걸린 것 같다. 학교 다니느랴, 대회 준비하느랴, 영어 공부하느랴 이것 저것 한게 많아서 11월인 올해 초에 본 논문을 올해 말에 작성하게 되었다. 작성하면서 다시 한 번 공부할 수 있어서 좋았다. 이제 대회도 끝났으니 많은 논문을 읽으면서 공부 해야할 것 같다. 우선 과제부터 하러 가야겠다.
비록 대회에서 사용하지는 않았지만 차선 공부를 하고 적용시키면서 실력적으로 많은 성장을 하였다. 코드도 직접 뜯어보면서 고쳐보고, 이것 저것 찾아보고, 인공지능 공부도 처음부터 다시 해보고.
항상 많은 도움을 준 마카롱5.0 팀원들한테 너무 고맙다. 난 그들을 보면서 열심히 하고 노력해야겠다고 느낀다.
다음 글은 카롱이(erp-42)에 어떻게 적용했는지 소개하려고 한다.
