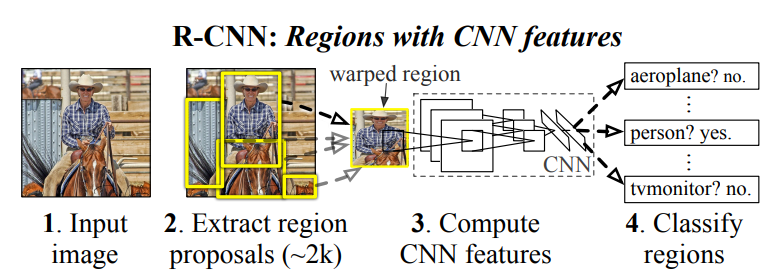
2013년에 발표된 R-CNN이라고 불리는 논문에 대해서 공부했다.
Abstract
본 논문은 object detection에 CNN 기법을 도입한 논문이다. 기존에 object detection은 ensemble systems을 이용했다. 또한 R-CNN과 비교하는 Overfeat은 CNN을 이용한 sliding windows 기법을 이용하였다.
R-CNN은 2가지의 insights가 있다:
-
고용량의 CNN을 localization과 segmetation을 위한 bottom-up(가장 작은 문제들부터 답을 구해가며 전체 문제의 답을 찾는 방식) region proposal 방식에 대해 적용하는 것
(one can apply high-capacity convolutional neural networks (CNNs) to bottom-up region proposals in order to localize and segment objects) -
labeled training data가 부족할 때, supervised pre-training을 하고 이후에 fine-tuning을 하는 것.
(when labeled training data is scarce, supervised pre-training for an auxiliary task, followed by domain-specific fine-tuning, yields a significant performance boost)
-> 지금은 그렇지 않지만 AI가 인기가 없던 2013년에는 아마 data가 부족해서 그런 것 같다.
- Pre-trained model: 내가 풀고자하는 문제와 비슷하면서 사이즈가 큰 데이터로 미리 학습된 model
- Fine-tunning: pre-trained model을 활용하여 새로운 model을 학습하는 과정
Region with CNN features라는 뜻으로 R-CNN이라고 부른다고 한다.
1. Introduction
SIFT, HOG, Neocognitron등 이러한 예전 기술들이 object detection에 쓰였다는 것에 대해서 소개하고 있다.
이후 CNN이 Krizhevsky(AlexNet)이 도입되면서 많이 사용되었고 image classification에서 높은 accuracy를 달성했다고 한다. 이후 'Classification에서 좋은 성능을 달성한 CNN을 object detection에도 도입할 수 있지않을까?'이 논의되었다.
이러한 결과를 달성하기 위해서 2가지 문제를 해결해야한다.
1. localizing objects with a deep network
2. training a high-capacity model with only a small quantity of annotated detection data -> 적은 양의 data로 대용량 model 학습시키기
*annotated data: dataset에 metadata(다른 데이터를 설명해주는 데이터)를 추가한 data
-> labeled data, Bounding box, semantic segmentation 등
1번을 문제를 해결하는 하나의 방법은 localization을 regression problem으로 보는 것이다. 그러나 이러한 방법은 실제로는 잘 작동하지 않는다고 한다. 또 다른 방법으로는 sliding-window detector를 사용하는 것이다. CNN은 얼굴과 같은 한정된 category에서 이러한 방식을 사용하였다. 이러한 CNN은 높은 해상도를 유지하기 위해서 2개의 conv layer와 pooling layer를 사용한다. 저자들도 이러한 방식을 사용했었는데, 5개의 conv layer를 사용하다보니 input image에 대한 수용 범위도 크고 stride도 커서 정확한 결과를 얻을 수 없다고 한다.
따라서 "recognition using region"으로 1번 문제를 해결했다. 이는 input image에 대해서 카테고리에 상관없이 약 2000개의 영역을 만들고, CNN을 활용하여 고정된 feature vector를 추출한 이후 category-specific linear SVMs을 이용하여 분류한다. 아래의 그림이 이것에 대한 설명이다. (2000개의 영역을 만드는데 class가 하나라도 나올 것이다!)
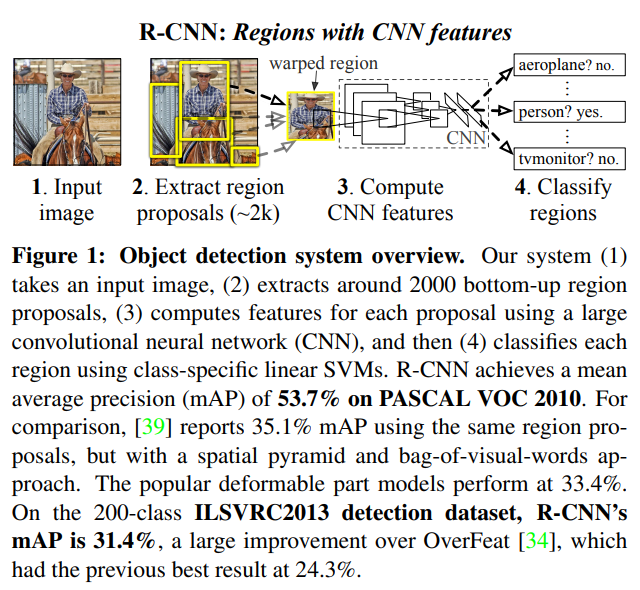
이러한 방식과 sliding window기법을 활용한 OverFeat과 비교 결과도 주어졌다. R-CNN이 31.4%로 24.3%인 OverFeat을 'significally outperform'하다고 쓰여있다.
Data가 부족한 2번 문제는 supervised pre-training을 한 후 fine-tuning을 진행하는 방식으로 해결했다.
- Data가 부족하고 model의 parameter가 많으면 overfitting이 발생할 수 있다. 이를 해결하기 위해서 data를 많이 늘려주는 방법도 있다. 하지만 object detection에서는 그 수 많은 data를 Bounding box치는 것은 시간이 정말 정말 많이 오래걸린다. 따라서 위 방법처럼 다른 dataset(여기서는 ILSVRC)으로 pre-training을 진행하고 이후 fine-tuning을 진행한다. (자세한 내용은 추후에 다룰 예정!)
2. Object detecetion with R-CNN
3가지 모듈로 구성했다고 한다.
2-1. Module design
-
Region proposals
다양한 category-independent region proposal들이 있는데 이중에서 selective search 알고리즘을 이용했다. -
Feature extraction
각각의 region proposal에 대해서 AlexNet으로 구성된 CNN을 이용하여 4096-dimensional feature vector를 추출하였다. Forward propagation으로 계산되어진 feature들을 5개의 conv layers와 2개의 FC layers를 통해(=AlexNet) 227*227의 image를 mean-subject한다. (mean-subject는 각각의 특성에서 mean을 빼는 작업으로 data들을 원점으로 이동하는 작업을 말한다.)
Region proposal에 대한 feature(4096-vector)를 계산하기 위해서 image data를 AlexNet이 요구하는 227*227 pixel size로 전환해주어야한다. 따라서 이미지의 비율이나 크기에 대해 상관없이 selective search로 찾은 candidate region에 대해서 required size인 227*227로 만들어준다.(여기서는 warp, 찌그러뜨린다는 의미로 사용) Warping하기 전에 bounding box를 pixel, 즉 16pixels만큼 주변 영역을 확장해준다음에 warping을 진행한다.
-> 이것에 대한 이유는 Appendix A에 서술되어있으며, 단순히 경험적으로 일 때, 좋은 결과가 나와서 이렇게 정했다고 한다.

-
Warping한 data의 모습
2-2. Test-time detection
Selective search를 이용해서 약 2000개의 region들을 추출한다. AlexNet을 이용해 4096-dimensional feature vector를 추출하기 위해서 image를 warp한다. 그런 다음 SVM을 이용해서 각각의 class에 대해서 예측한다. 각각의 class에 대한 점수가 매겨진 region에 대해서 non-maximum suppression(NMS) 알고리즘을 적용한다.
- Run-time analysis: 2가지 효율적인 발견
-
모든 CNN parameter들은 모든 category에 대해서 공유된다.
(First, all CNN parameters are shared across all categories.)
-> 이 부분에 대해서 무슨 말이지 고민을 많이 했었는데 그냥 CNN에 대한 특징을 말하는 것 같다. 이 논문이 쓰여질 당시는 2013년으로 CNN이 그렇게 활성화되지 않은 시점이다. 따라서 CNN이 무엇인지 모르는 사람들을 위해서 사용한 문장인 것 같은데, 모든 CNN parameter들이 공유된다는 말은 각각의 filter가 input image를 거치는 것을 얘기하는 것 같다. Filter의 값은 고정되어 있으므로 이 부분이 'parameter are shared'가 아닌가 싶다. -
CNN에 계산되어진 Feature vector는 다른 방식들과 비교하였을 때 low-dimension이다.
(Second, the feature vectors computed by the CNN are low-dimensional when compared to other common approaches, such as spatial pyramids with bag-of-visual-word encodings.)
UVA detection system은 36만-dimension인데 4096-dimension과 비교하면 훨씬 크다.
Feature matrix는 2000 X 4096 (4096-dimension vector가 region 개수만큼)이고 SVM weight matrix는 4096 X N (4096-dimension feature vector를 이용해서 class 개수인 N만큼 학습하므로)이다. 따라서 dot product 계산을 하기 때문에 시간이 적게 걸린다고 하고 있다. (그래봤자 10만개 클래스가 10초..? -> 2013년에는 대단한 발견!, DPM은 1만개가 5분이래요~)
2-3. Training
-
Supervised pre-training
Open source인 Caffe CNN library를 ILSVRC2012 dataset을 이용하여 pre-train해준다. -
Domain-specific fine-tuning
새로운 domain에 적용하기 위해서, warped region proposal을 이용해서 SGD를 수행한다. Pre-train한 CNN은 1000개의 class를 가지고 있는 ImageNet dataset(ILSVRC2012)이다. 이것을 CNN 구조를 바꾸지 않고 N+1개의 class로 바꾸어준다. 이때 N개가 class의 개수이고, 1은 background인 배경을 포함시켰다. (VOC의 N=20, ILSVRC2013의 N=200)
Ground-truth box와 region proposal에 대해서 IOU가 0.5이상이면 positive, 이하는 negative로 취급한다. 32개의 positive sample과 96개의 negative sample을 이용해서 총 128개의 mini-batch를 이용해서 SGD를 진행한다. 아무래도 background인 negative가 positive에 비해서 더 많을 수 밖에 없어서 개수가 3배가량 차이가 난다. -
Object category classifiers
Fine-tuning을 마치고 object를 detection하는 과정이다. Fine-tuning과 다른 과정으로 학습을 진행한다.
먼저 각각의 class에 대해서 ground-truth bounding box들만 positive로 정의한다. 이는 부분적으로 object와 background가 겹쳐있다면 정확한 답을 찾기 어렵기 때문에 이렇게 설정하였다. IOU가 0.3이하인 것에 대해서는 negative로 취급하였다. (다시 말해 0.3이상은 버리고 ground-truth만 positive!)
-> 0.3이 threshold인 이유는 Appendix B에서 언급하였는데, 이것도 경험적으로 0.3이 제일 좋은 결과를 얻어서 그렇다고 한다. 심지어 threshold가 0인 경우가 0.5인 경우보다 성능이 더 좋게 나왔다.
SVM은 하나의 class에 대해서만 분류하기 때문에 class의 개수만큼 SVM이 있다. 또한 memory를 절약하기 위해서 hard negative mining method를 이용했다. -
Hard negative mining method란?
Hard negative는 Type one error인 오답인데 정답으로 분류하는 False positive으로 예측하기 쉬운 데이터를 뜻한다. Hard negative mining method는 이러한 hard negative를 confidence가 높은 순으로 training data로 mining, 즉 학습 data로 모으는 것을 의미한다. 이렇게 하면 좋은 negative sample들을 가져오게 되고 False positive error에 대해서 강해진다. 또한 전체 negative sample을 사용할 필요가 없기 때문에 memory 절약에 효과적이다.
2-4. Results on PASCAL VOC 2010-12
2-5. Results on ILSVRC2013 detection
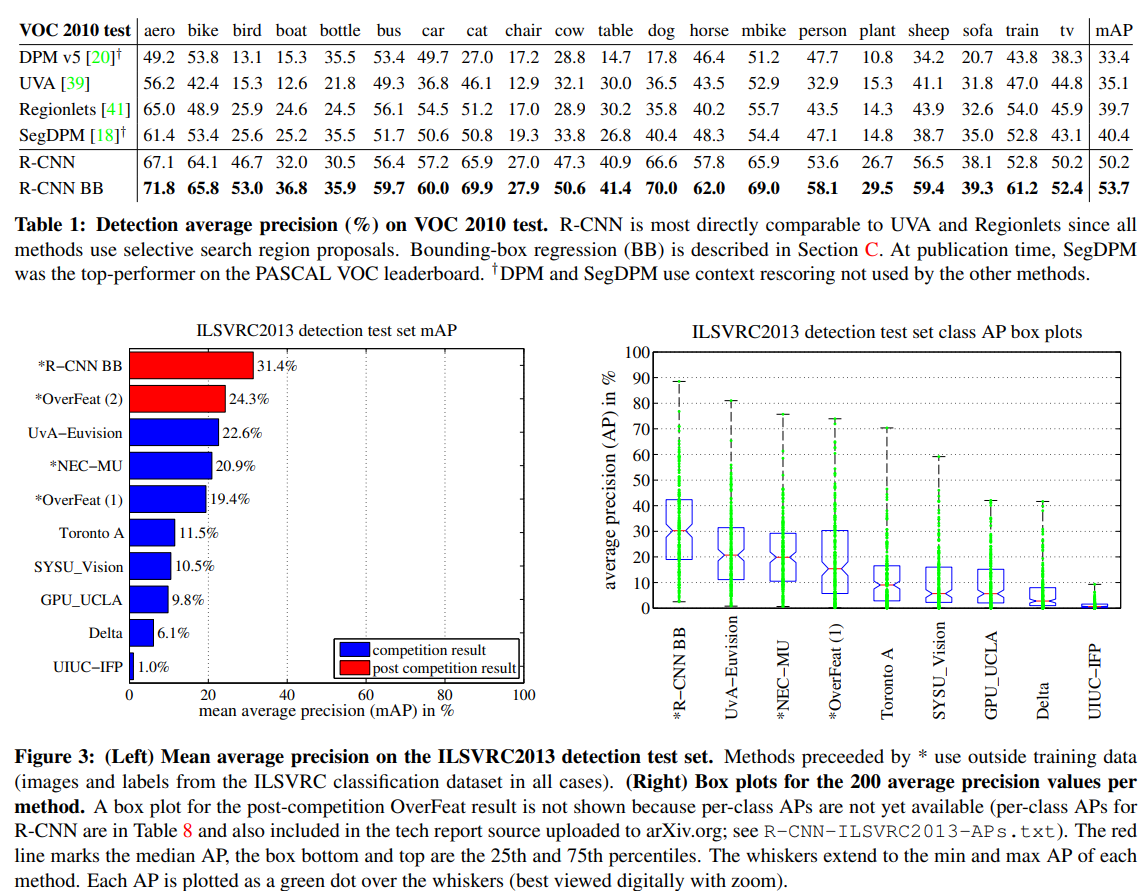
R-CNN 성능에 대한 결과이다.
위에는 2-4이고 four strong baselines과의 비교이며, R-CNN의 mAP가 훨씬 더 좋은 성능을 갖는 것을 알 수 있다.
아래는 2-5에 대한 결과이며, 마찬가지로 R-CNN이 좋은 성능을 보여줬다.
3. Visualization, ablation, and modes of error
3-1. Visualizing learned features
1000만개나 되는 엄청나게 큰 region proposal에서 unit들의 activation을 계산한 후에 내림차순으로 정렬시키고, NMS알고리즘을 실행하고 높은 점수를 받은 region들을 보여준다.
(That is, we compute the unit’s activations on a large set of held-out region proposals (about 10 million), sort the proposals from highest to lowest activation, perform nonmaximum suppression, and then display the top-scoring regions)

위 사진은 어떤 class에 대해서 layer pool의 top16을 시각화 한 것이다.
Pool란 마지막 conv layer와 max-pooling을 거쳐서 나온 값이다. Pool의 feature map은 6 X 6 X 256 = 9216-dimensional을 갖는다.
3-2. Ablation studies
- Ablation: 요소를 하나씩 없애면서 해당 요소가 전체 시스템에 어떤 역할을 하는지 확인
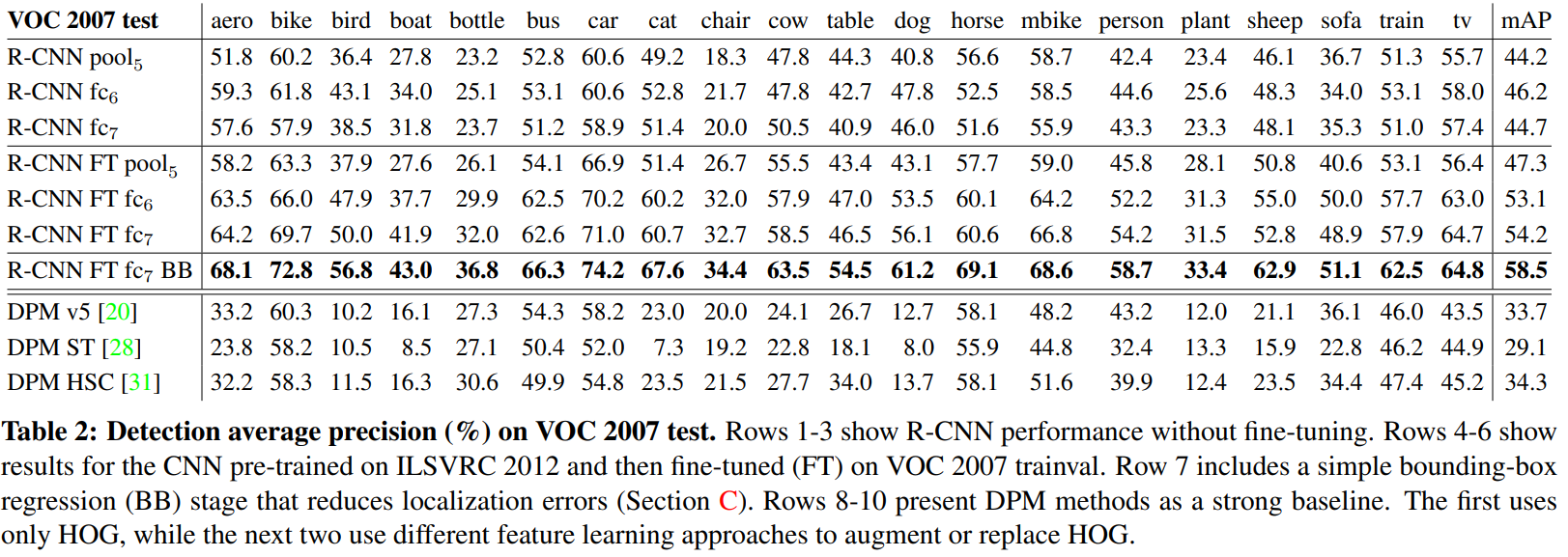
-
Performance layer-by-layer, without fine-tuning
Fine-tuning없이 마지막 3개의 layer들(pool, fc, fc)을 확인한다.
Fc은 pool의 fc layer로써 해당 feature map은 4096 X 9216 weight matrix에 pool feature map vector를 곱하고 bias vector를 더한다.
Fc은 마지막 layer로써 4096 X 4096 weight matrix에 fc을 곱해서 feature map을 얻는다.
이렇게 계산을 통해 얻은 결과는 위 표에서 3개 열에 해당한다. 3개의 결과는 모두 비슷비슷한 mAP가 나왔다. 심지어 끝까지 실행한 fc보다 마지막에서 멈춘 fc의 결과가 더 좋게 나왔다. Pool는 fc이 사용한 parameter의 오직 6%밖에 사용하지 않았는데 비슷한 mAP를 기록했다. 이는 계산이 훨씬 많아 봤자 비슷하다는 얘기다. -
Performance layer-by-layer, with fine-tuning.
VOC 2007 dataset을 이용하여 fine-tuning을 하고 나서 3개의 layer를 비교해봤더니 결과가 확연히 차이가 났다. (4, 5, 6열에 해당) Layer가 깊어질수록 더 좋은 성능을 냈다. -
Comparison to recent feature learning methods.
DPM과의 비교를 통해 R-CNN이 좋은 결과를 내는 것을 알 수 있다.
3-3. Network architectures
Krizhevsky = AlexNet = T-Net
16-layer deep network recently proposed by Simonyan and Zisserman = VGG-16 = O-Net
으로 취급하면 된다. 이 논문에선 network model명으로 부르는 것이 아니라 구현한 저자의 이름으로 부른다.

위 Table 3는 R-CNN을 어떤 Network로 구성했느냐에 대한 결과이다. R-CNN을 VGG로 구현하는 것이 AlexNet으로 구현하는 것 보다 더 좋은 결과를 갖는다. 다만 VGG로 구현한 R-CNN은 AlexNet으로 구현한 R-CNN보다 7배 더 긴 시간이 걸렸다고 한다.
-> 좋은 결과를 갖는다고 좋은게 아닌듯
3-4. Detection error analysis
어떠한 error가 나왔는지 분석해보았다.
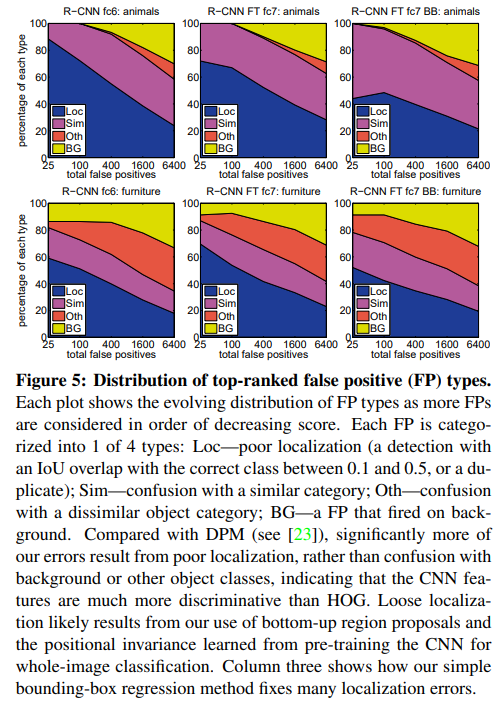
LOC - localization 문제
Sim - 비슷한 catogory에 대한 confusion
Oth - 비슷하지 않은 category에 대한 confusion
BG - Background에 대한 False Positive (배경인데 positive라고 말한 error)
LOC에 대한 error비율이 굉장히 컸는데 R-CNN fine-tuning Bound box는 좋은 해당 비율이 낮아진 것을 알 수 있다. 즉 bounding box를 놓음으로써 localization문제를 어느정도 해결할 수 있다.
3-5. Bounding-box regression
위에서 언급했던 것처럼 localization error를 줄이기 위해서 bounding box를 도입했다. Selective search 알고리즘으로 탐색한 region들을 ground truth에 맞게 training하는 것을 의미한다. 자세한 내용은 Appendix C에 나와있다.
4. The ILSVRC2013 detection dataset
ILSVRC2013 dataset을 가지고 detection을 수행한 내용이며 3장과 비슷한 구성을 띄고있다. CVPR 논문에서는 아예 없어진 내용이므로 넘어가겠다.
5. Semantic segmentation
R-CNN을 object detection만이 아니라 segmentation분야에서도 사용하였다. Segmentation 분야에서도 좋은 성능을 냈다는 얘기인 것 같다.
6. Conclusion
2개의 insight를 통해서 문제를 해결했다.
1. Object를 localize와 segment하기 위해서 bottom-up 방식의 region proposal을 deep한 CNN으로 해결하기
2. Labeled data가 부족할 때 CNN 학습시키기
Computer vision과 deep learning에서의 전형적인 방식으로 문제를 해결했다고 한다.
느낀점
설날도 끼어있었고 논문도 어렵기도 해서 오래걸린 것 같다. R-CNN이 고비라고 생각했는데 하나의 큰 산을 넘은 것 같아서 좋다. 이제 마카롱도 해야하고 할 것들이 점점 많아진다... 뭔가 일은 벌리는데 하기는 싫은 느낌? 아 귀찮아~~ 쉬고싶다
오늘도 화이팅

화이팅이에요