학습한 내용
CNN의 네트워크 구조
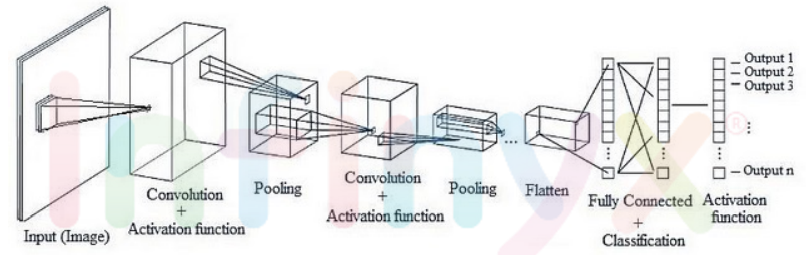
- CNN의 구조는 기존의 완전연결계층(Fully-Connected Layer)과는 다르게 구성되어 있다.
- 완전연결계층(또는 Dense Layer이라고도 합니다)에서는 이전 계층의 모든 뉴런과 결합 되어있는 Affine계층으로 구현했지만, CNN은 Convolutional Layer과 Pooling Layer들을 활성화 함수 앞뒤에 배치하여 만들어진다.
1. 첫번째 Convolutional Layer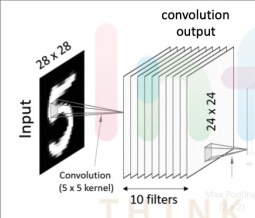
- 입력값은 28x28크기를 가진 이미지이고, 이 이미지를 대상으로 여러 개의 필터(커널)을 사용하여 결과값(feature mapping)을 얻는다.
- 한개의 28x28 이미지 입력값에 10개의 5x5필터를 사용하여 10의 24x24 matrics, 즉 convolution 결과값을 만들어 낸다.
- 그 후 이렇게 도출해낸 결과값에 Activation function(예를 들면 ReLU function)을 적용하면 첫번째 Convolutional Layer이 완성된다.
- 한 Convolutional Layer는 Convolution처리와 Activation
function으로 구성되어 있다는 것을 알 수 있다. - A Convolutional Layer = convolution + activation
활성함수 쓰는 이유
- 선형함수(linear function)인 convolution에 비선형성(nonlinearity)를 추가하기 위해 사용
- 따라서 MLP(Multiple layer perceptron)는 단지 linear layer를 여러개 쌓는 개념이 아닌 활성화 함수를 이용한 non-linear 시스템을 여러 layer로 쌓는 개념이다
활성화 함수(Activation Functions)
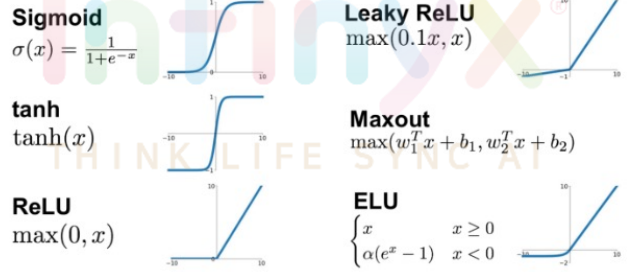
1. 시그모이드(Sigmoid)
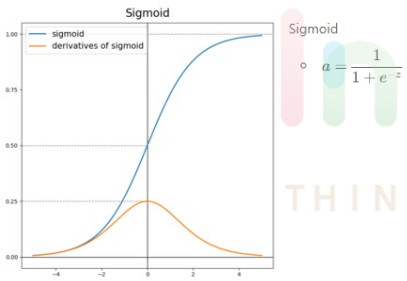
- output값을 0에서 1사이로 만들어준다. 데이터의 평균은 0.5를
갖게된다. - 그림에서 시그모이드 함수의 기울기를 보면 알 수 있듯이 input
값이 어느정도 크거나 작으면 기울기가 아주 작아진다. - 이로인해 생기는 문제점은 vanishing gradient현상이 있다.
[Vanishing gradient]
이렇게 시그모이드로 여러 layer를 쌓았다고 가정하자. 그러면 출력층에서 멀어질수록 기울기가 거의 0인 몇몇 노드에 의해서 점점 역전파해갈수록, 즉 입력층 쪽으로갈수록 대부분의 노드에서 기울기가 0이되어 결국 gradient가 거의 완전히 사라지고만다. 결국 입력층쪽 노드들은 기울기가 사라지므로 학습이 되지 않게 된다. - 시그모이드를 사용하는 경우: 대부분의 경우에서 시그모이드함수는 좋지 않기때문에 사용하지 않는다. 그러나 유일한 예외가 있는데
binary classification경우 출력층 노드가 1개이므로 이 노드에서 0~1사이의 값을 가져야 마지막에 cast를 통해(ex. 0.5이상이면 1, 미만이면 0) 1혹은 0값을 output으로 받을 수 있다. - 장점: binary classification의 출력층 노드에서 0~1사이의 값을 만들고 싶을때 사용한다.
- 단점: Vanishing gradient - input값이 너무 크거나 작아지면 기울기가 거의 0이된다.
2. Thah(Hyperbolic Tangent)-하이퍼볼릭 탄젠트
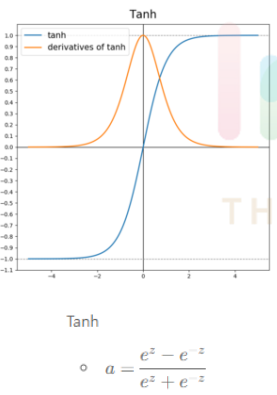
- 그림에서 보면 알 수 있듯이 시그모이드 함수와 거의 유사하다. 차이는 -
1~1값을 가지고 데이터의 평균이 0이라는 점이다. - 데이터의 평균이 0.5가 아닌 0이라는 유일한 차이밖에 없지만 대부분의 경우에서 시그모이드보다 Tanh가 성능이 더 좋다.
- 장점: output데이터의 평균이 0으로써 시그모이드보다 대부분의 경우에서
학습이 더 잘 된다. - 단점: 시그모이드와 마찬가지로 Vanishing gradient현상이 일어난다.
3.ReLU
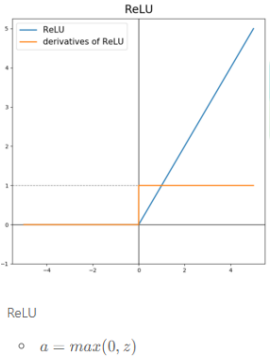
- 대부분의 경우 일반적으로 ReLU의 성능이 가장 좋기때문에 ReLU를 사용한
다. - "Hidden layer에서 어떤 활성화 함수를 사용할지 모르겠으면 ReLU를 사용하면 된다" - Andrew ng 앤드류 응
- 대부분의 input값에 대해 기울기가 0이 아니기 때문에 학습이 빨리 된다. 학습을 느리게하는 원인이 gradient가 0이 되는 것인데 이를 대부분의 경우에서 막아주기 때문에 시그모이드, Tanh같은 함수보다 학습이 빠르다.
- 그림을 보면 input이 0보다 작을 경우 기울기가 0이기 때문에 대부분의 경우에서 기울기가 0이 되는것을 막아주는게 납득이 안 될수 있지만 실제로 hidden layer에서 대부분 노드의 z값은 0보다 크기 때문에 기울기가 0이 되는 경우가 많지 않다.
- 단점으로는 위에서 언급했듯이 z가 음수일때 기울기가 0이라는 것이지만 실제로는 거의 무시할 수 있는 수준으로 학습이 잘 되기 때문에 단점이라 할 수도 없다.
- 장점: 대부분의 경우에서 기울기가 0이 되는 것을 막아주기 때문에 학습이 아주 빠르게 잘 된다.
4. leaky ReLU
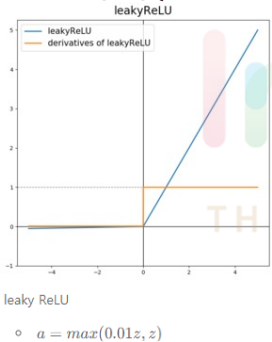
- ReLU와 유일한 차이점으로는 max(0, z)가 아닌 max(0.01z, z)라는 점이다.
- input값인 z가 음수일 경우 기울기가 0이 아닌 0.01값을 갖게 된다.
leaky ReLU를 일반적으로 많이 쓰진 않지만 ReLU보다 학습이 더 잘 되긴
한다. - 장점: z가 음수일때 기울기가 0이 아닌 0.01을 갖게 하므로
ReLU보다 학습이 더 잘 된다
Optimizer 종류 및 정리
- 옵티마이저는 학습 데이터(Train data)셋을 이용하여 모델을 학습 할 때 데이터의 실제 결과와 모델이 예측한 결과를 기반으로 잘 줄일 수 있게 만들어주는 역할을 한다.
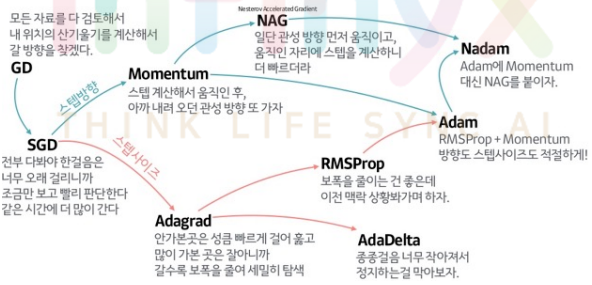
1. Gradient descent(GD)
- 가장 기본이 되는 optimizer 알고리즘으로 경사를 따라 내려가면서 W를 update시킨다.
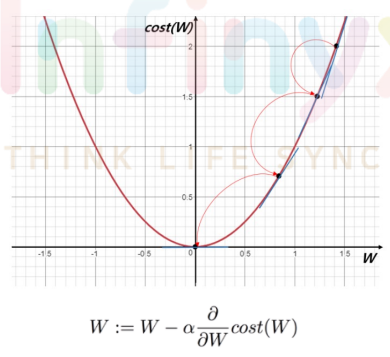
- 대부분의 non-linear regression문제는 closed form solution이 존재하지 않는다. closed form solution이 존재해도 수많은 parameter가 있을때는 GD로 해결하는 것이 계산적으로도 더 효율적이다.
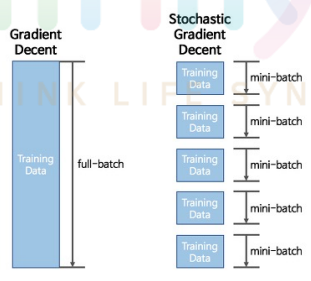
2. Stochastic gradient decent(SGD)
- full-batch가 아닌 mini batch로 학습을 진행하는 것
- batch로 학습하는 이유 : full-batch로 epoch마다 weight를 수정하지 않고 빠르게 mini-batch로 weight를 수정하면서 학습하기 위해
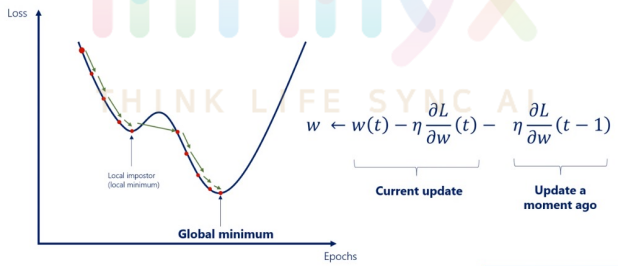
- Momentum 개념: 현재 batch로만 학습하는 것이 아니라 이전의 batch 학습결과도 반영한다.
3.Adam
- Momentum과 RMSProp를 융합한 방법이다.




Pooling Layer
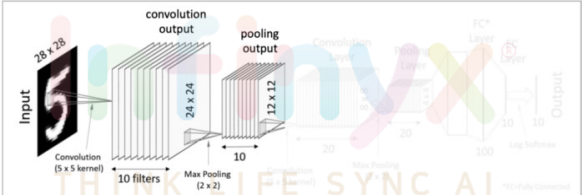
- Pooling은 각 결과 값(feature map)의 dimentionality를 축소해 주는 것을 목적으로 둡니다.
- 즉 correlation이 낮은 부분을 삭제(?)하여 각 결과값을 크기(dimension)을 줄이는 과정입니다
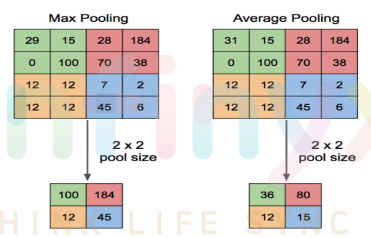
첫번째 Pooling Layer
- Pooling Layer의 결과값이 열개의 12x12 matrics가 된 것을 확인
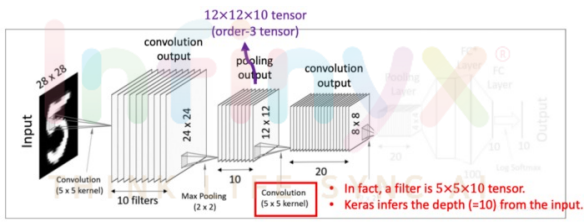
두 번째 Convolutional Layer
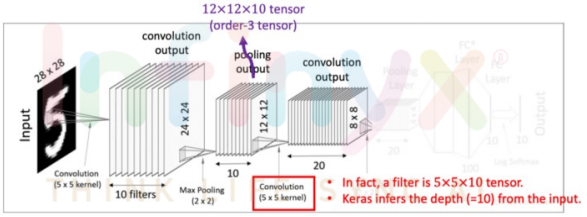
- 이번 Convolutional layer에서는 텐서 convolution을 적용
- 이전의 pooling layer에서 얻어낸 12x12x10 텐서(order-3 tensor)를 대상으로 5x5x10크기의 텐서필터 20개를 사용해 준다. 그렇게 되면 각각 8x8크기를 가진 결과값 20개를 얻어낼 수 있다.
두 번째 Pooling Layer
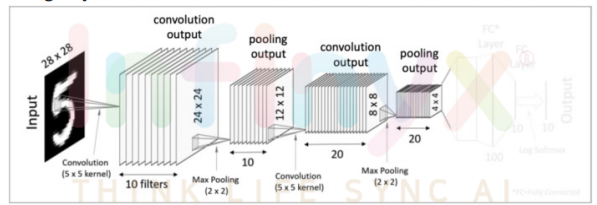
- 전과 똑같은 방식으로 Pooling과정을 처리해주면 더 크기가 작아진 20개의 4x4 결과값을 얻는다.
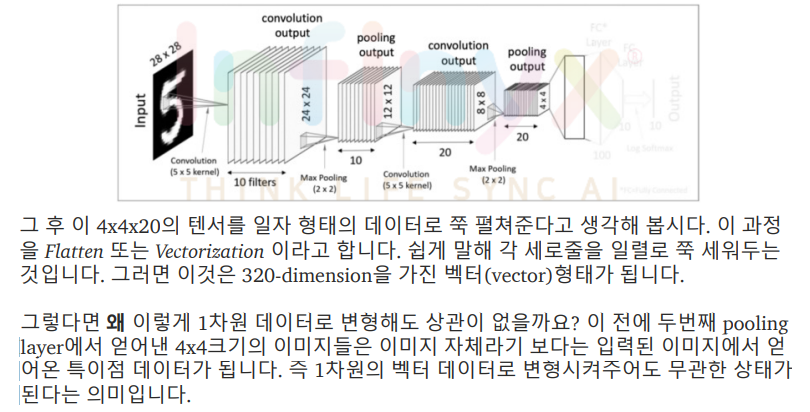
Flatten(Vectorization)
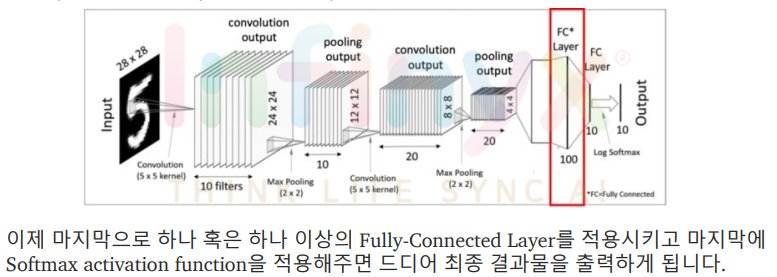
Fully Connected Layers(Dense Layers)
학습한 내용 중 어려웠던 점 또는 해결못한 것들
딱히 없다.
해결방법 작성
학습 소감
이론적인 부분이고 기초적인 내용이라 어려운 것은 없었다.
