0609 - CNN 기반 이미지 처리 인공지능 소개
0
학습한 내용
CNN 기반 이미지 처리 인공지능
1. Hyper-parameters(CNN모델에서 튜닝 가능한 하이퍼 파라미터 종류)
- Convolutional layers: 필터의 갯수, 필터의 크기, stride값, zero-padding의 유무
- Pooling layers: Pooling방식 선택(MaxPool or AvgPool), Pool의 크기, Pool stride 값(overlapping)
- Fully-connected layers: 넓이(width)
- 활성함수(Activation function): ReLU(가장 주로 사용되는 함수), SoftMax(multi class classification), Sigmoid(binary classification)
- Loss function: Cross-entropy for classification, L1 or L2 for regression
- 최적화(Optimization) 알고리즘과 이것에 대한 hyperparameter(보통 learning rate): SGD(Stochastic gradient descent), SGD with momentum, AdaGrad, RMSprop
- Random initialization: Gaussian or uniform, Scaling
2. 학습률 learning rate
- 최소값으로 크게 진동하지 않고 최소값에 도달하거나 무한대로 분기하지 않고 손실 함수가 완만하게 내려갈 수 있을 정도로 작아야하며, 최적화가 적당한 시간 내에 이루어 지도록 충분히 커야 함.
- 학습 속도 설정 방법:
1.미리 결정된 부분 단위 학습 속도를 설정
- 학습 속도는 0.1임. 처음 5 개의 에포크의 경우 0.01, 다음 5의 경우 0.01, 끝까지의 0.001. 이로 인해 손실 함수가 최소로 훨씬 빠르게 수렴되어 정확한 결과를 얻을 수 있음.
2. 지수 일정
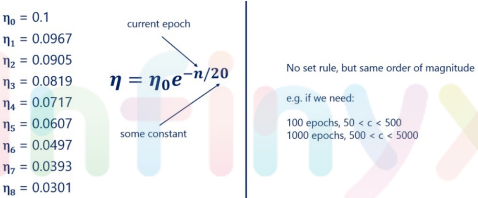
- 학습 속도를 부드럽게 줄이는 것보다 훨씬 나은 대안
- 일반적으로 eata와 같은 높은 값에서 시작함. 이 식에서 규칙을 사용하는 방법은 현재 에포크(C)는 상수이면서, 위 그림에서는 C는 20에 해당하는 학습률로 제공함. 상수 C에 대한 규칙은 없지만 일반적으로 크기 순서는 같아야 함.
- 100에서 100까지의 에포크 값이 필요한 경우 50에서 500 사이의 c 값이 모두 괜찮음.
- 500에서 5000까지의 1000 값이 필요한 경우 일반적으로 훨씬 적을 것임.
- c의 정확한 값은 그다지 중요하지 않음. 큰 차이를 만드는 것은 학습률 자체가 있다는 것. C는 하이퍼 매개 변수이고 모든 하이퍼 매개 변수는 특정 문제에 차이를 줄 수 있음.
- 좋은 학습 속도인지 분별하는 방법: 학습률이 너무 높을수록 손실을 최소화할 수 없으며 비용은 그래프에서 볼 수 있듯이 상향으로 폭발함. 지수 적으로 스케쥴에 따라 정의된 학습률과 같이 잘 선택된 학습률은 낮은 학습률보다 훨씬 빨리 손실을 최소화함. 또한 높은 학습 속도보다 더 정확하게 수행 가능함.
3. 딥러닝(Deep learning)
실제 데이터를 균형 잡히게 만들어야 하는 이유:
- 비즈니스 사례에서는 목표를 신속하게 검토해야함.
- 대부분의 실제 데이터는 균형잡히지 않았다라는 것을 알아야함.
- 계속 진행하려면 데이터 세트의 균형을 반드시 맞춰야함.
- 이 작업은 대상의 총 개수를 세고 0과 동일한 개수를 일치시키는 방식으로 수행됨.
Mini batch를 사용하는 이유
- 딥러닝에서 한번의 iteration을 위해 들어가는 input data는 보통 batch라고 하여 수십수백개의 데이터를 한그룹으로 사용하게 됨
- mini-batch는 두가지 방법의 장점을 모두 얻기 위한(서로의 단점을 보완) 타협점임
- iteration: forward + backpropagation + 업데이트를 거치는 한번의 과정
1) 데이터를 한 개 사용하는 경우
- 장점: iteration 한번 수행하는데 소요되는 시간이 매우 짧습니다. cost function의 최적의 값을 찾아가는 과정을 한걸음 한걸음 minimum을 향해 걸어가는 것으로 생각한다면 매우 빠르게 걸을 수 있음.
- 단점:
1) 데이터 전체의 경향을 반영하기가 힘들어서 업데이트를 꼭 좋은 방향으로만 하지않음. 현재 학습을 진행하는 데이터 한개에 대해서는 cost function의 값이 줄어들더라도 이로 인해 다른 데이터에 대해서는 cost가 증가 할 수 있기 때문에 많이 헤매게됨.
2) 하드웨어입장에서 비효율적임 현재 딥러닝에 GPU를 많이 쓰는 이유는 그 강력한 병렬 연산능력 때문인데 한번에 데이터 한개만 학습에 사용한다면 그 병렬연산을 안쓰는 것이나 마찬가지라 학습을 위해서 갈 길이 먼데 매우 아까운 낭비임.
2) 전체 데이터를 사용하는 경우
- 장점: 전체 데이터를 반영하여 한걸음 한걸음을 내딛음. 즉 정말로 cost function의 값을 줄이는 양질의 이동을 하게됨.
- 단점:
1) 데이터셋의 크기가 커질 경우 iteration을 한번 수행하는데 소요되는 시간이 매우 김. 최적의 위치를 찾아가기 위해서는 최소한으로 수행해야 하는 iteration이 존재하기에 학습시간이 매우 길어짐. 이를 보완하기 위해서 learning rate를 높이려고 해봐도 쉽지 않고, 보통 학습을 진행 할 때 learning rate를 너무 크게 잡으면 local minimum만 왔다갔다하거나 minimum에 들어가지 못하는 shooting 현상이 생김.
2) 하드웨어입장에서 부담스러움. 데이터셋이 커질 경우 그 데이터를 메모리에 올려야 될 뿐만 아니라, 그 데이터의 전처리한 결과나 레이어를 거친 아웃풋 등도 수시로 메모리를 드나들어서 매우 큰 메모리용량이 필요하게 됨.
3) mini-batch 사용하는 경우
- 적당히 빠르고 적당히 정확한 길을 찾기 위해 mini-batch를 사용함
- 적게는 수십개부터 많게는 수백개의 데이터를 한 그룹으로하여 처리함으로써 iteration 한번 수행하는데 소요되는 시간을 최대한 줄이면서 전체 데이터를 최대한 반영함
- 동시에 보통은 가능한 한도 내에서 batch 크기를 최대한 크게 잡아 하드웨어에 부담을 주지 않는 선에서 하드웨어를 최대한 활용함
4. 딥러닝 학습을 위한 국내외 데이터셋 현황 - 이미지편
범용 대규모 이미지 데이터셋
- 2009년 공개된 이후로 ImageNet 데이터셋 [J. Deng et al. 2009] 은 최근까지 이미지 분류뿐 아니라 객체인식(object detection), 의미 분할(semantic segmentation), 자세 추정(pose estimation) 등의 다양한
컴퓨터 비전 문제에 활용될 수 있는 공통 convolutional neural network (CNN) 백본 모델 학습에 널리 활용됨. - 최근에도 ImageNet-1k (1000 클래스 Image 데이터)는 이미지 분류 모델의 성능 평가를 위한 표준 평가데이터로 활용됨.
1. OpenImage [R. Benenson et al. 2019]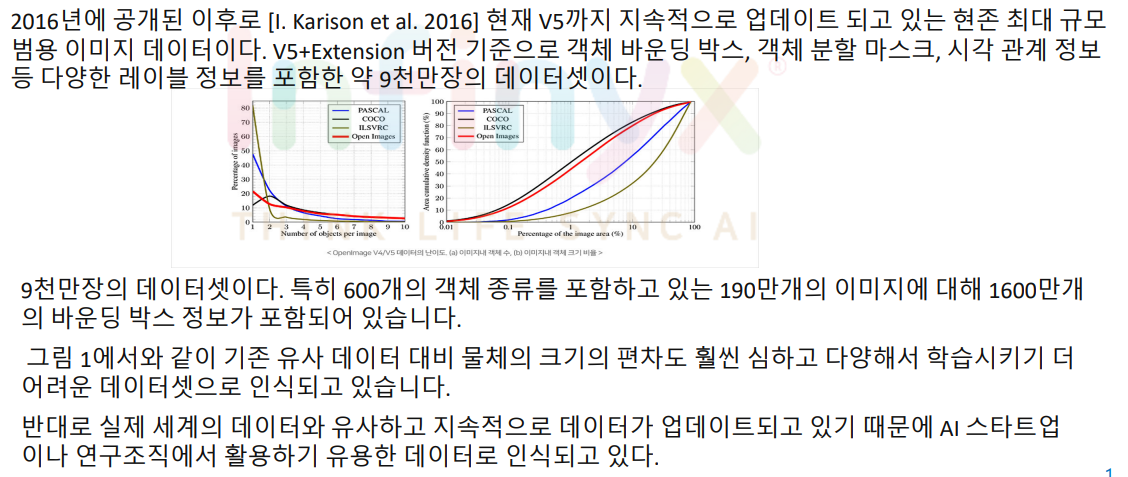
2. Microsoft COCO
3. LVIS 
얼굴 데이터셋
- 얼굴 인식은 컴퓨터 비전 분야에서 가장 다양한 실제 서비스와 직결된 기술 중의 하나이다. 특히 중국을 중심으로 얼굴감지와 인식을 위해 다양한 데이터들이 공개되었다.
- 또한 최근 Generative adversarial network (GAN) [I. Goodfellow et al. 2014]의 발전에 따라 얼굴 생성 모델 학습을 위한 다양한 데이터들이 공개되었습니다.
- 얼굴 데이터는 대부분 초상권 이슈와 연관되어 있어 상업용 활용이 특히 다른 데이터 대비 극히 제한됩니다.
- 이에 최근에는 StyleGAN [T. Karras et al. 2019] 을 이용하여 가상으로 생성된 얼굴 이미지를 공개함으로써 초상권 문제를 회피하고 있습니다.
1. Widerface

2. B.CelebA

AI-Hub 데이터셋
- 과학기술정보통신부와 한국정보화진흥원(NIA) 에서는 지난 수년간 이미지, 텍스트, 법률, 농업, 영상, 음성 등 다양한 분야의 딥러닝 학습에 필요한 데이터를 수집 구축하고 이를 AI-Hub 를 통해 공개하고 있다.
- 이미지 데이터로는 한국인 안면 이미지, 질병 진단이미지, 한국형 사물 이미지. 손글씨 이미지 등을 공개하고 있다. 또한 내년에도 추가로 다양한 종류의 데이터를 추가 구축 공개 예정이다.
5. 컴퓨터 비젼 (Computer Vision)
1. 이미지 분류(Image Classification)
- 인간이 이미지를 분류하는 성능은 약 95%정도이다.
- 이미지 분류를 하더라도 수많은 데이터 없이 적은 데이터만을 가지고 어떻게 하면 높은 성능을 기록을 할 수 있을 지, 어떻게 하면 더욱 더 강건한 (Robust) 모델을 만들 수 있을지, 어떻게 하면 학습 데이터에 내에 있는 노이즈 데이터를 걸러 낼 수 있을지 등 다양한 형태와 분야로 발전해 오고 있다.
2. 객체 탐지(Object Detection)
- 객체 탐지란 어떠한 이미지 및 비디오 속에 포함 되어있는 물체들에 대해서 어떤 물체인지 분류해내는 이미지 분류를 하는 것과 동시에 해당 물체가 이미지 및 비디오 속에 어디에 위치하였는지 찾아내는 일이다.

3. Segmentation
- Segmentation이란 앞서 Object Detection보다 정교한 탐지를 요구하는 연구분야이다.
- Segmentation은 특정 위치에 Boundary로 물체 존재 유무를 표현하는 것의 한계를 극복하기 위해, 이미지 빛 비디오 내 존재하는 모든 픽셀에 대해 특정 클래스로 예측하는 방식으로 진행한다.

6. 최근 인공지능 적용 사례
1. Generative Adversarial Networks(GAN)

2. Style Transfer

3. Deep Photo Style Transfer

4. Style Transfer for Anime Sketches

5. StarGAN

6. Globally and Locally Consistent Image Completion

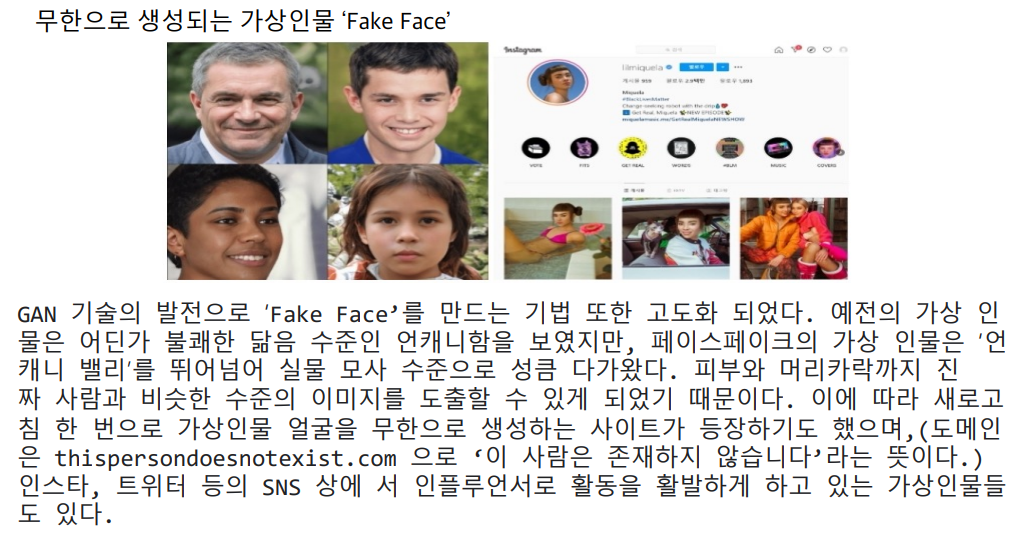
7. Fake Face
학습한 내용 중 어려웠던 점 또는 해결못한 것들
없다.
해결방법 작성
학습 소감
이론적인 부분이라 쉬웠다.
