- 정규성검정
- T검정과 분산분석
- 모수검정과 비모수검정 비교
- 상관분석과 회귀분석
- 다중회귀분석
- 범주형자료분석
귀무가설과 대립가설
귀무가설(null hypothesis)은 우리가 증명하고자 하는 가설의 반대되는 가설, 효과와 차이가 없는 가설을 의미하며 우리가 증명 또는 입증하고자 하는 가설, 효과와 차이가 있는 가설을 대립가설이라고 한다.
귀무가설 H0 : 현재의 가설
대립가설 H1 : 새로운 가설
p값이 0.05보다 작으면 대립가설을 채택! (귀무가설 기각)
기본 세팅
setwd('C:\\Users\\Public\\Downloads\\MyFolder')
getwd()결측치 제거
dat_F<-na.omit(dat)
nrow(dat_F)
a[complete.cases(a),]파일불러오기
txt 파일 불러오기
data<- read.table('test1.txt')header=T 컬럼이름 있음.
sep 구분자
data<- read.table('test1.txt',header=T,sep=',')2,3열만
data<- tmp[, c(2,3)]csv 파일 불러오기
ex_data <-read.csv(“C:/Rstudy/data_ex.csv”)xlsx 파일 불러오기
install.packages(‘readxl’)
library(readlxl)
excel_data<- read_excel('test2.xlsx', sheet=2)범주형으로 나누기
data2_1=data2[(data2$A_steps>0 & o2$A_steps<10000), ] summary(뫄)
hist(뫄)3450 넘으면 1, 아니면 0
o2_3<-ifelse(o2_1$A_steps>=3450, 1, 0)1300이하는 1, 1300<=x<5000는 2, 아니면 3
o2_1$A_steps_gr2<-with(o2_1, ifelse(A_steps<1300, 1, ifelse((A_steps>=1300 & A_steps<5000), 2, 3)))freq(o2_1$A_steps_gr)merge(x, y, key=??)r4<- aggregate(r2$A_steps, list(r2$pid), mean)
r4[1:20, ]
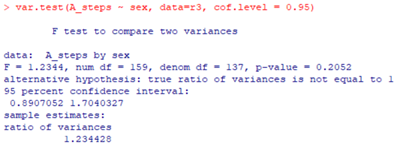
dim(r4)var.test(A_steps ~ sex, data=r3, cof.level = 0.95)
: F-검정. p-value가 0.2052는 0.05보다 크기 때문에 귀무가설 기각 불가. -> 남자와 여자의 퍼진 정도(분산)가 같다.
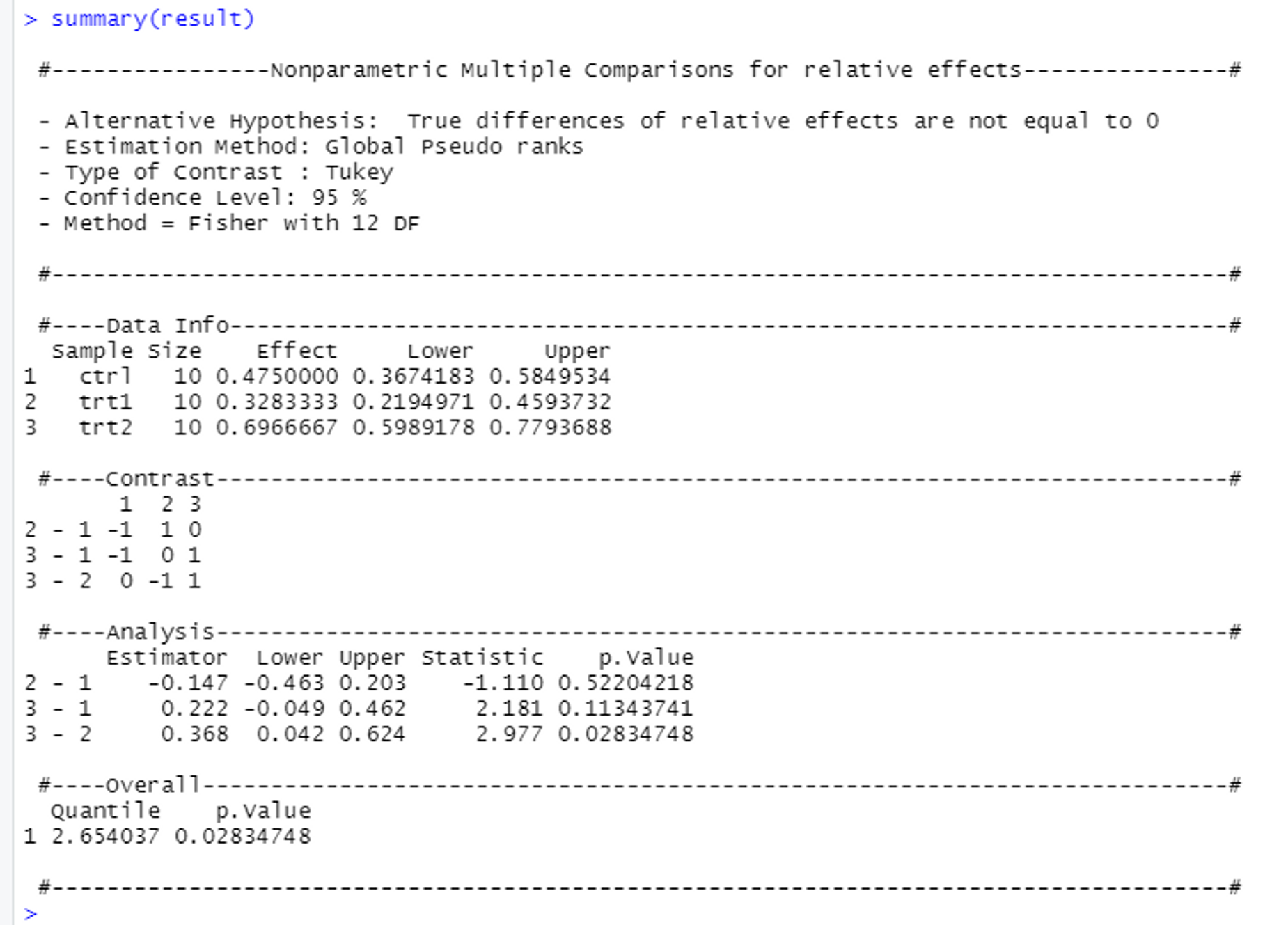
- 변수가 2개일 때는 t-test, 3개 이상이면 ANOVA 사용
t.test(A_steps ~ sex, data=r3, var.equal=TRUE, conf.level=0.95)
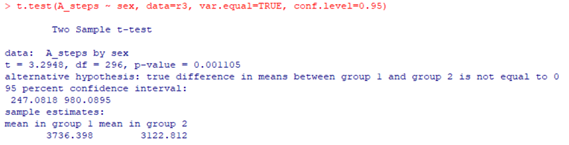
남자의 평균 걸음수 : 3736.398, 여자의 평균 걸음수 : 3122.812
p-value는 0.001105로 0.05보다 작기 때문에 귀무가설을 기각한다. -> 당뇨 환자인 남자와 여자의 평균 걸음 걸이는 같지 않다. (다르다) -> 남자인 경우가 더 많이 걷는다.(생활 습관을 변하기 위해 더 노력한다)
9. 정규분포와 중심극한정리
정규성 확인 및 검정
1. 히스토그램
2. qq plot
qqnorm(dat_subj$HE_glu, col='grey')
qqline(dat_subj$HE_glu, col='#377EB8', lwd=2)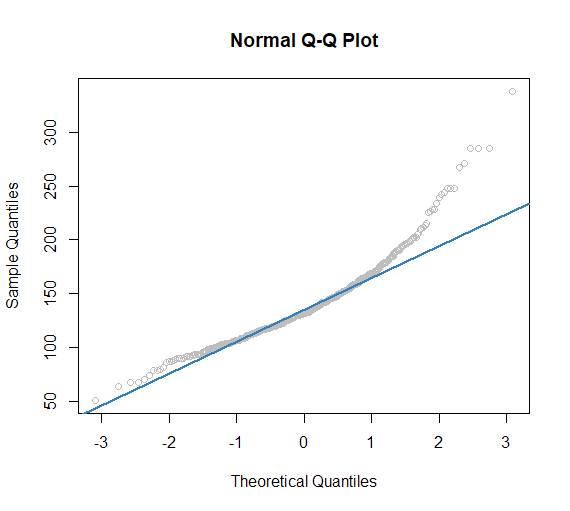
공복혈당(HE_glu)에 대한 Q-Q plot이에요.
도트로 표현된 분포는 empirical distribution, 즉 우리가 가진 공복혈당의 분포이고
파란색 선으로 표현된 분포는 theoretical distribution으로, 정규분포입니다.
이 두 분포가 근접하게 분포하면 정규성을 띈다고 할 수 있으며, 근접하지 않으면 정규성을 띄지 않는다고 할 수 있어요.
3. Shapiro-Wilk test 정규분포 검사
정규성을 검정하는 방법
H0 귀무가설은 데이터가 정규분포를 따른다.
H1 대립가설은 데이터가 정규분포를 따르지 않는다이다.
p값이 0.05보다 작을 경우, 귀무가설을 기각하고 대립가설을 채택!
즉, 0.05보다 클 경우, 정규분포를 따른다.
shapiro.test(r3$A_steps)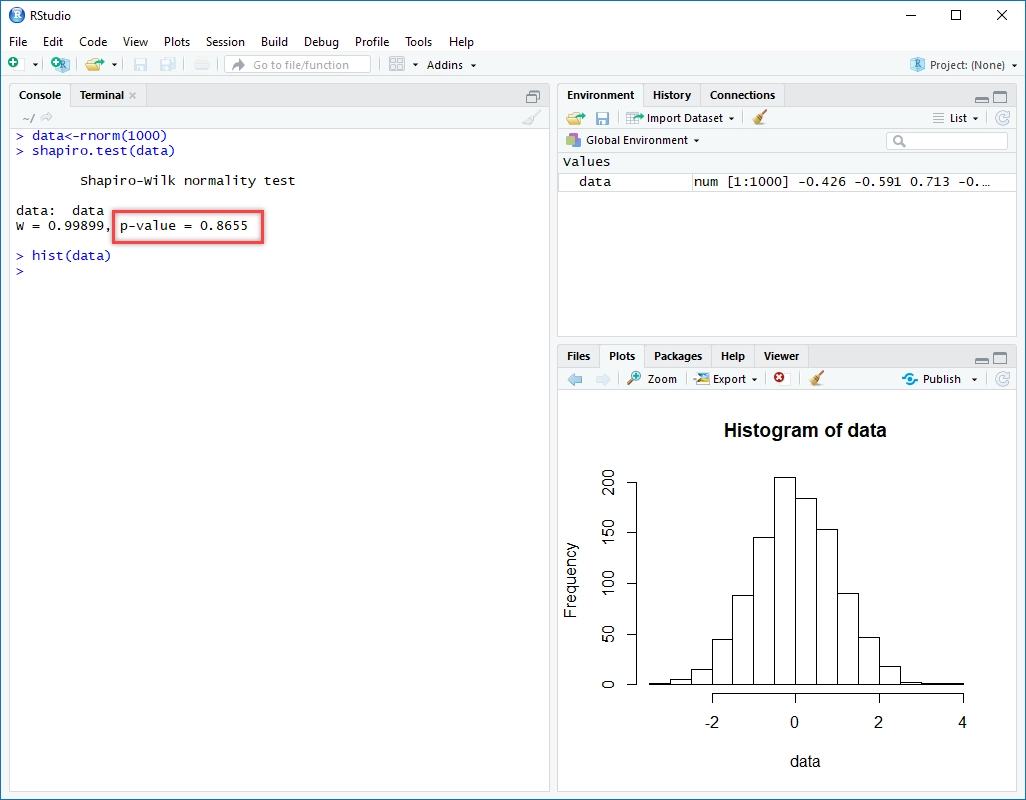
but, 표본 크기가 5000을 넘으면 에러가 발생
Chi-square test
비연속적 범주형 자료를 분석함에 있어 연속성 분포인 카이제곱 분포에
적용함으로써 발생하는 확률값의 차이를 보정하는 방법임
등분산성 검정
H0 (귀무가설): 두 그룹의 분산의 차이가 없다. vs. H1(대립가설): 두 그룹의 분산의 차이가 있다.
var.test(dat_subj$HE_glu ~ dat_subj$DE1_31)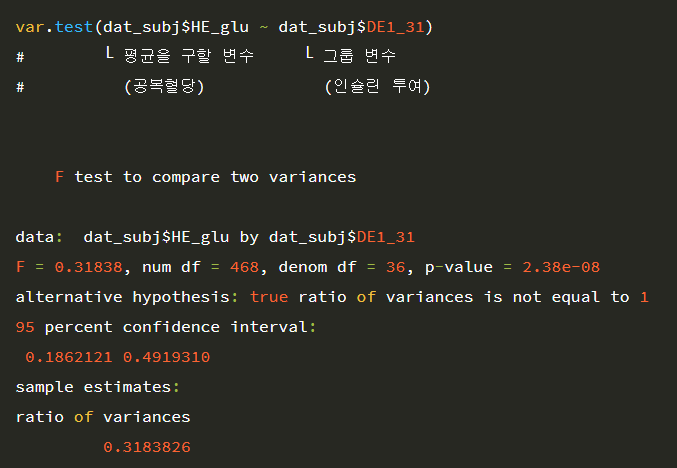
p값이 매우 작다. = 귀무가설을 기각하여 등분산성이 없다, 즉 두 그룹의 분산이 같지 않다고 할 수 있습니다.
중심극한 정리 central limit theorem
정규분포 검사
shapiro.test(r3$A_steps)
11. 모수검정과 비모수검정
변수
- 이산형 변수(범주형 변수)
- 연속형 변수 continuous
연속형 자료 분석
- 정규성검정
모수 parametric
-> 정규성을 만족할 때
t.test : 범주형 2군 vs 연속형 평균 비교
two-sample t-test 독립된 두 집단의 모평균 비교
paired t.test : 범주형 vs 연속형 평균
paired t-test 쌍을 이룬 집단에서 모평균의 차이에 대한 검정
1) 단일 표본 t-test (one sample t-test)
- 특정 그룹의 평균이 특정 값과 같은지 비교
- 예: 인슐린 투여 후 공복혈당 수치는 90mg/dL 일 것이다.
2) 독립 표본 t-test (two sample t-test)
- 서로 다른 두 그룹 간의 평균을 비교
- 예: 당뇨환자에서 인슐린 투여군과 비투여군은 혈당의 차이가 있을 것이다.
3) 대응 표본 t-test (paired t-test)
- 한 그룹 내에서 동일한 대상을 반복 측정하여 전과 후 평균을 비교
- 예: 당뇨환자에서 인슐린 투여 전과 후의 혈당 변화는 차이가 있을 것이다.
t.test는 정규성을 만족해야한다! 등분산성 여부를 알아야한다.
- 정규분포를 따르지 않음! 따른다고 가정!
- 인슐린 투여 그룹 간 분산이 다름!
# two sample t-test
t.test(dat_subj$HE_glu ~ dat_subj$DE1_31, paired=F, var.equal=F, conf.level=0.95)여기서 실행시키기 전에!! 몇 가지 command를 추가해 줄게요.
먼저, 독립 표본 t-test이므로 paired=F를 추가해 줍니다.
대응 표본(paired t-test)인 경우엔 paired=T라는 설정만 바꿔주시면 됩니다.
두 번째로 위에서 등분산성 여부를 파악했었죠?
등분산성을 만족하지 못했기 때문에 var.eqaul=F를 추가해 주시구요.
마지막으로 신뢰구간은 일반적으로 95% 설정하므로 conf.level=0.95까지! 추가해 줍니다.
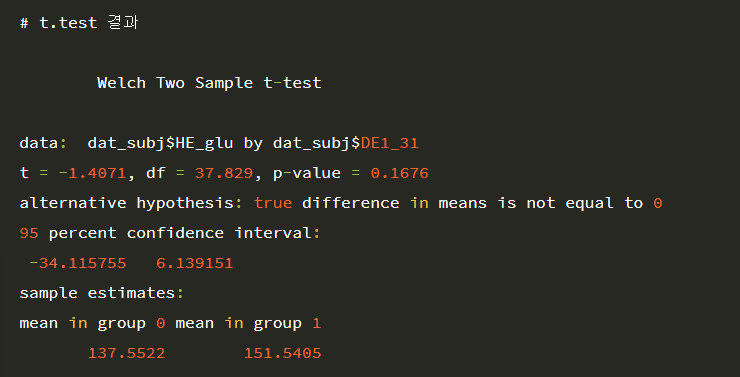
p-value는 0.1676으로 인슐린 투여 여부에 따라 공복혈당이 다르지 않다고 할 수 있습니다.
anova : 범주형 3군 vs 연속형 평균
one-way ANOVA 세 집단 이상의 모평균 비교
- pearson correlatoin
- 다중 비교 multiple comparison
- 집단 간의 비교
- Bonferroni procedure- Tukey procedure
- Scheffé procedure
- Dunnett procedure
- 집단 간의 비교
비모수 nonparametric
-> 정규성을 만족하지 못할때
Wilcoxon Rank-sum text (윌콕슨 순위-합 검정)
t.test의 비모수 버전
wilcox.test(Price ~ Origin, data=dat)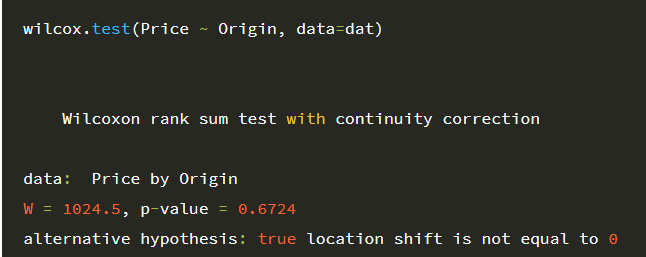
검정 결과 p-value=0.6724입니다. 친절하게 결과 마지막 줄에 대립가설도 나오네요.
대립가설은 중위수 차이는 0이 아니다. 즉, 중심 차이가 있다.인데
p-value가 0.05보다 크기 때문에 생산국(USA/non-USA)에 따른 자동차 가격의 차이는 없다고 할 수 있습니다.
Wilcoxon Signed Rank text (윌콕슨 부호-순위 검정)
대응표본 paired t.test에 대한 비모수 버전
대응표본 paired=T
wilcox.test(weight ~ group, data=dat2, paired=T)
중위수를 구할 변수 ~ 그룹 변수와 대응표본임을 알려주는 paried=T 옵션을 추가합니다.
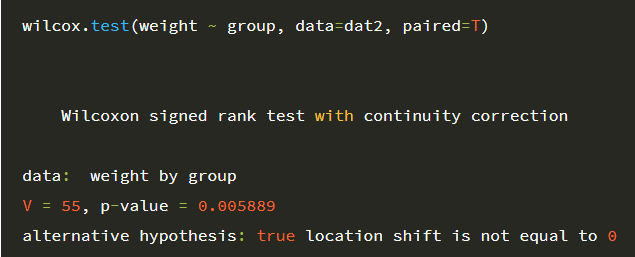{kind=link}
P-value=0.006으로 0.05보다 작으므로, 전(before group)과 후(after group)의 체중(weight)에는 차이가 있다고 할 수 있습니다.
kruskal-wallis test
ANOVA의 비모수버전
shapiro.test()-> p값이 0.05보다 작다 = 정규성을 띄지 않는다. => 비모수 사용
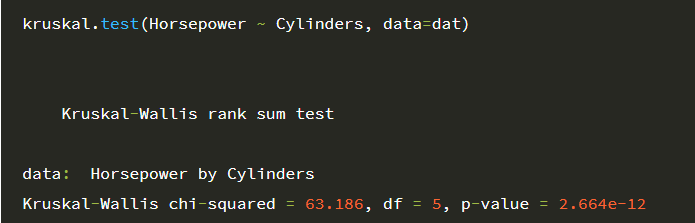
p-value가 매우 작으므로 실린더 수에 따른 마력의 차이가 있다고 할 수 있습니다.
사례2) H0 (귀무가설) : 모든 집단의 중위수(median)가 같다 vs. HA (대립가설) : 한 집단이라도 중위수(median)가 같지 않다
p-value가 0.05보다 작기 때문에 귀무가설을 기각하고, 대립가설을 채택하게 됩니다. 즉, 한 집단이라도 중위수가 같지 않다는 결과가 나왔고, 이는 선수들 간 경기별 출전 시간 분포(양상)이 한 명이라도 다른 것이 있다는 것을 의미합니다.
- spearman corrlation
선형 회귀분석
범주형 자료 분석
- chi-square test 차이 제곱분석
- logistic regreesion 로지스틱회귀분석
12. 상관분석과 회귀분석
상관분석 correlation
cor.test
cor.test(dat$cyl, dat$hp)실린더의 수(cyl)와 마력(hp) 간 상관관계가 있는가
- pearson 상관계수 (피어슨)
- spearman 순위상관계수 (스피어만)
선형회귀분석
: 회귀분석은 한마디로 독립변수와 종속변수 간의 관계를 알아내는 분석
독립변수(영향을 줌)->종속변수(영향을 받음)
독립변수의 상태에 따라, 혹은 독립변수가 증가/감소할수록 종속변수가 증가/감소한다고 해석한다.
(선형회귀분석의 종속변수는 연속형 변수)
lm(종속변수~독립변수(+들), data=데이터셋)- 단순선형 회귀분석
독립변수가 하나, 종속변수도 하나
lm_fit <- lm(hp ~ cyl, data=dat)linear model
R-squared : 적합도 판단
13. 다중회귀분석
- 다중선형 회귀분석
독립변수가 여러개, 종속변수는 하나
multi_fit <- lm(hp ~ cyl + wt, data=dat)
summary(multi_fit)plot(x~y, data=데이터)
abline(reg=result1,col="red",lwd=2)step(res)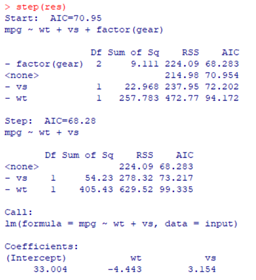
AIC가 작을수록 좋음!
(3가지의 설명력은 70.95지만 wt와 vs의 AIC 값은 68, 결국 factor(gear)일 때만 AIC가 낮아졌음을 알 수 있다. 결국 factor(gear)를 뺐을 때가 AIC값이 낮아졌기에 더 좋음을 알 수 있다. 마지막에 factor(gear)를 뺀 회귀계수를 보여줌.
mpg=33-4.4wt+3.2vs
- 다중공선성
다중공산성을 평가하는 지표인 VIF
(다중공선성은 다중회귀분석을 진행하기 전에 반드시 확인해야하는 사항이다.
보편적인 기준은 10
install.packages("car")
library(car)
vif(m)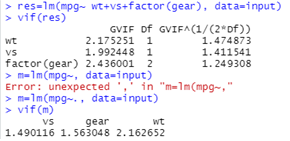
14. 범주형 자료분석
- 독립성검정
빈도를 가지고 변수들 사이의 관련성을 분석
두 범주형 변수가 서로 관계가 있는지, 관련없이 독립적인지 판단
독립변수와 종속변수가 모두 범주형이면 독립성 검정을 한다!
CrossTable
rowPercents(a3)
colPercents(a3)
install.packages("gmodels")
library(gomodels)
CrossTable(b$obstruct, b$status)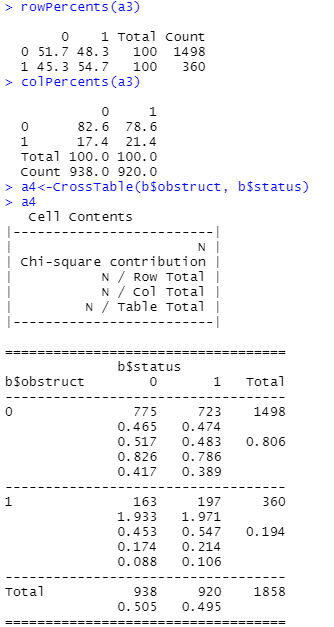
일반횟수
카이 제곱 ( 기대치 비율 )
행을 기준으로 비율 값 ( 가로로 읽는다. )
컬럼을 기준으로 비율 값 ( 세로로 읽는다. )
전체를 기준으로 비율 값
Chi-square test 카이제곱 검정
chisq.test(b$obstruct, b$status)
p값이 매우 작은 값이면 x와 y가 관계가 있다고 결론을 내릴 수 있다.
카이제곱은 분산에 대한 추정.
유의하지 않음->귀무가설기각->분산이 같지 않음
로지스틱 회귀분석 logistic regression model
로지스틱 회귀분석
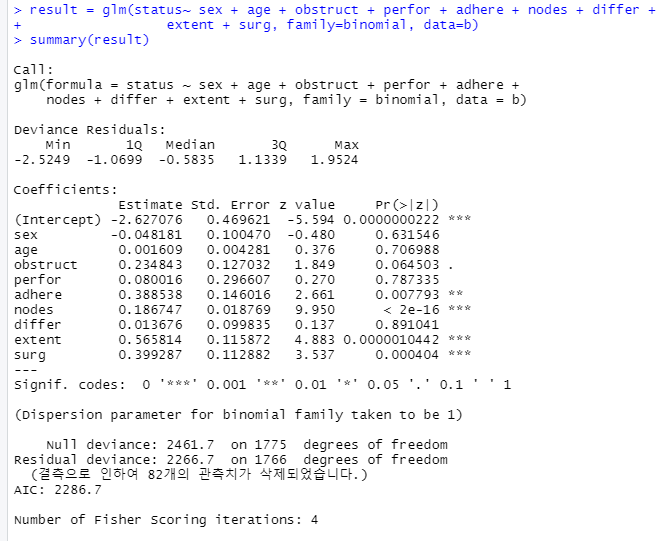
로지스틱 회귀분석은 선형 회귀분석과 달리 종속변수(반응변수)가 범주형 변수인 경우에 독립변수와 종속변수 간 관계를 알아내는 데 사용되는 분석방법이다.
logit_fit <- glm(survived ~ ., data=dat_F, family='binomial')generalized linear model
- AIC 값이 작을 수록 좋은 모형이다 (상대적인 기준이기에 여러 모델을 만들어놓고 좋은 모델을 선택하기)
- Coefficients : Estimate를 보기
A가 1 증가하면 B배가 된다. 와 같이 해석함
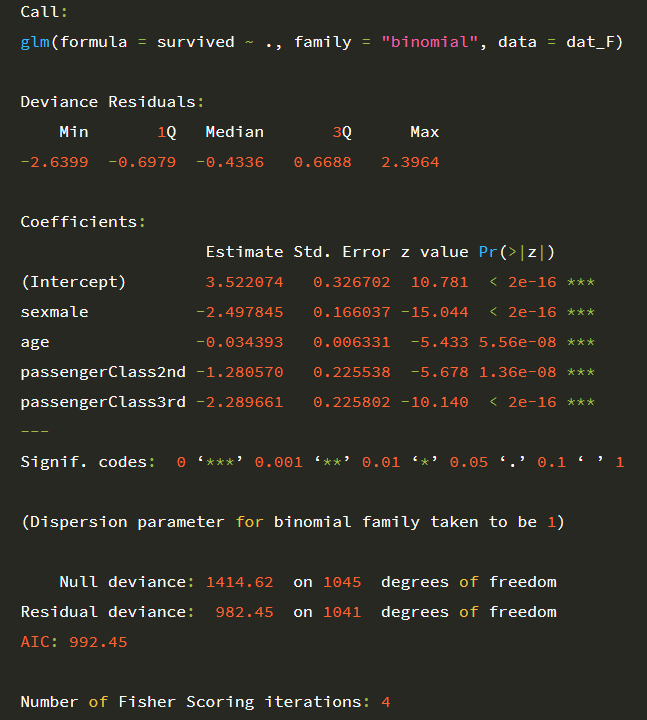
간단한 해석을 하자면,
남자의 생존확률이 여자의 생존 확률 보다 더 낮고,
연령이 높아질수록 생존 확률이 낮아지며,
2nd class와 3rd class의 생존 확률이 1st class보다 낮다고 할 수 있습니다.
좀 더 자세한 해석을 하자면
남자의 생존확률은 여자의 생존확률의 e-2.497845배이고,
나이가 1살 많아지면 생존확률은 e-0.034393배가 되고,
2nd class는 1st class 생존확률의 e-1.280570배이고,
3rd class는 1st class 생존확률의 e-2.289661배입니다.
################################## categorical data analysis ##################################
# dependent var : status ( recur or death of colorectal cancer =1 )
# independent var :
obstruct : obastruction ��?翡 ???? ???? ????
install.packages("survival")
library(survival)
str(colon)
View(colon)
library(descr)
b<-colon
#1. categorical variable : frequency
a1<-freq(b$status)
a1
View(a1)
a2<-freq(b$obstruct)
a2
View(a2)
a3<-table(b$obstruct, b$status)
a3
View(a3)
install.packages("Rcmdr")
library(Rcmdr)
rowPercents(a3)
colPercents(a3)
a4<-CrossTable(b$obstruct, b$status)
a4
#2. chi-sqaure test
chisq.test(b$obstruct, b$status)
# dependent var : status ( recur or death of colorectal cancer =1 )
# independent var :
obstruct : obastruction ��?翡 ???? ???? ????
perfor : perforation ???? õ??
adhere : adherence ??��???????? ��??
nodes : number of lymphatic gland ?ϼ????? Ȯ?ε? ?????? ??
differ : ?ϼ????? ��?????? ??ȭ��??(1=well, 2=moderate, 3=poor)
extent : ?ϼ????? ħ???? ???? (1=submucosa, 2=muscle, 3=serosa, 4=adjacent organ)
surg : time until registration after surgery (0=short, 1=long)
freq(b$obstruct)
freq(b$perfor)
freq(b$adhere)
freq(b$nodes) # NA's 36
hist(b$nodes)
summary(b$nodes)
hist(b$nodes, breaks=seq(0,35, by=1))
freq(b$differ) # NA's 46
freq(b$extent)
freq(b$surg)
#2. chi-sqaure test
CrossTable(b$obstruct, b$status)
chisq.test(b$obstruct, b$status)
CrossTable(b$perfor, b$status)
chisq.test(b$perfor, b$status)
CrossTable(b$adhere, b$status)
chisq.test(b$adhere, b$status)
CrossTable(b$differ, b$status)
chisq.test(b$differ, b$status)
CrossTable(b$extent, b$status)
chisq.test(b$extent, b$status)
CrossTable(b$surg, b$status)
chisq.test(b$surg, b$status)
# continuous var -> categorical var
b$nodes_gr=ifelse(b$nodes>2,1,0)
CrossTable(b$nodes_gr, b$status)
chisq.test(b$nodes_gr, b$status)
###### logistic regression model #########################################
# GLM (Genelized Linear Model)
result = glm(status~ sex + age + obstruct + perfor + adhere + nodes + differ +
extent + surg, family=binomial, data=b)
summary(result)
dim(b)
data1<-na.omit(colon)
dim(data1)
# sample = data1
result = glm(status~ sex + age + obstruct + perfor + adhere + nodes + differ +
extent + surg, family=binomial, data=data1)
summary(result)
# differ, extent => gr
result = glm(status~ sex + age + obstruct + perfor + adhere + nodes +
factor(differ) +
factor(extent) + surg, family=binomial, data=data1)
summary(result)
step(result)
step(result, direction="backward")
step(result, direction="forward")
m=step(result, direction="backward")
summary(m)
m=step(result, direction="forward")
m=step(result, direction="both")
# Odds Ratio
ORtable = function(x, digits=2){
suppressMessages(a<-confint(x))
result=data.frame(exp(coef(x)),exp(a))
result=round(result,digits)
result=cbind(result, round(summary(x)$coefficient[,4],3))
colnames(result)=c("OR", "2.5%", "97.5%", "p")
result
}
ORtable(m)
# sex + age + obstruct + perfor + adhere + nodes + differ + extent + surg
result = glm(status ~ obstruct , family=binomial, data=b)
summary(result)
ORtable(result)
result = glm(status ~ adhere , family=binomial, data=b)
summary(result)
ORtable(result)
result = glm(status ~ nodes , family=binomial, data=b)
summary(result)
ORtable(result)
result = glm(status ~ factor(extent) , family=binomial, data=b)
summary(result)
ORtable(result)
result = glm(status ~ surg , family=binomial, data=b)
summary(result)
ORtable(result)
# visualization of Odds Ratio
install.packages("moonBook")
library(moonBook)
odds_ratio = ORtable(m)
odds_ratio = odds_ratio[2:nrow(odds_ratio),]
HRplot(odds_ratio, type=2, show.CI=TRUE, cex=2)mctp