Elastic Search
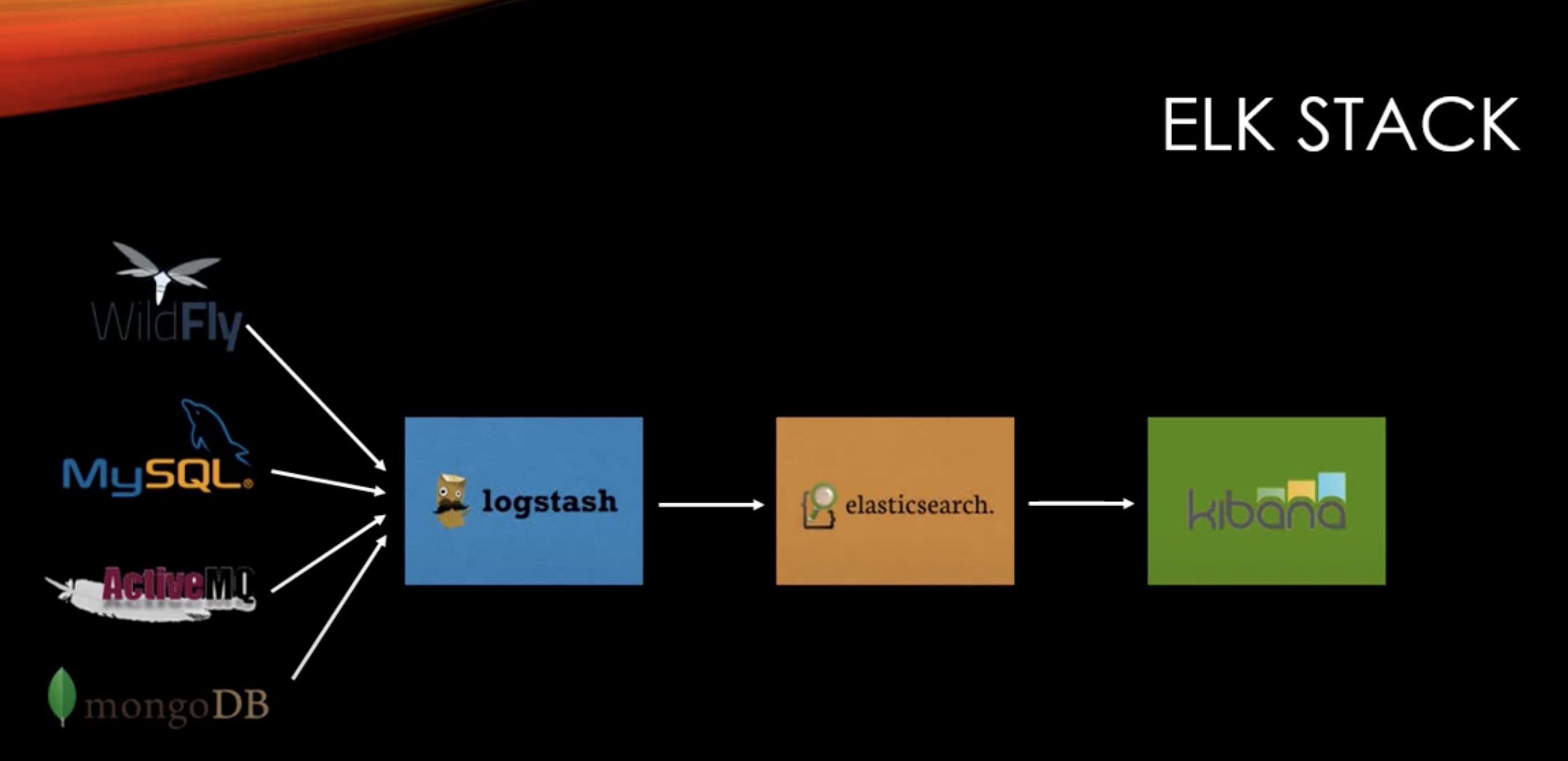
ELK : elastic search + logstash + kibana
- logstash
- 어떤 데이터, csv에 상관없이 elastic search에 데이터 수집
- kibana
- 데이터를 보기 좋게 시각화 하는 툴
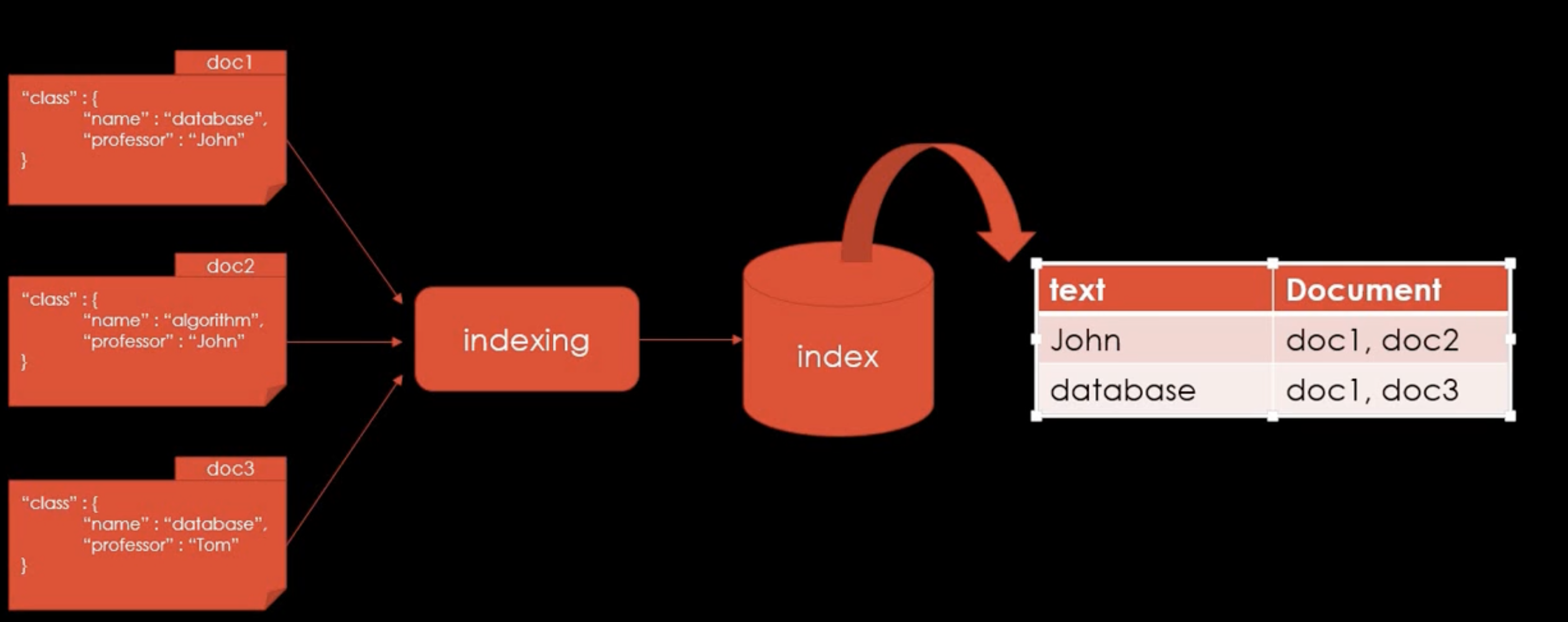
Data Flow

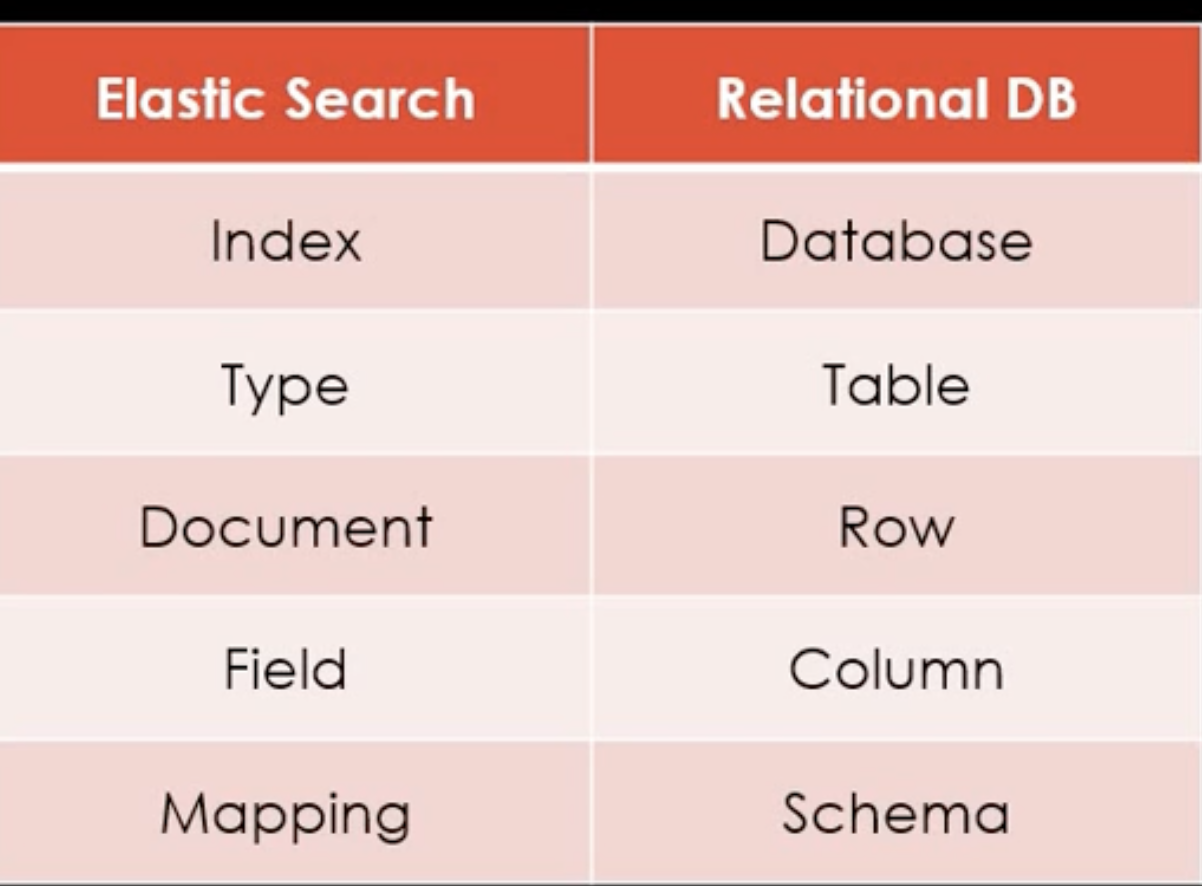
ES VS RDB
| 저장 방식 | 검색 | |
|---|---|---|
| Elastic Search | 키워드가 document에 있다고 저장 | O(1)로 저장 / 해시테이블 |
| RDB | document 정보를 모두 저장 | O(n) / Full Scan |
인덱스 안에 타입을 가지고 있다.
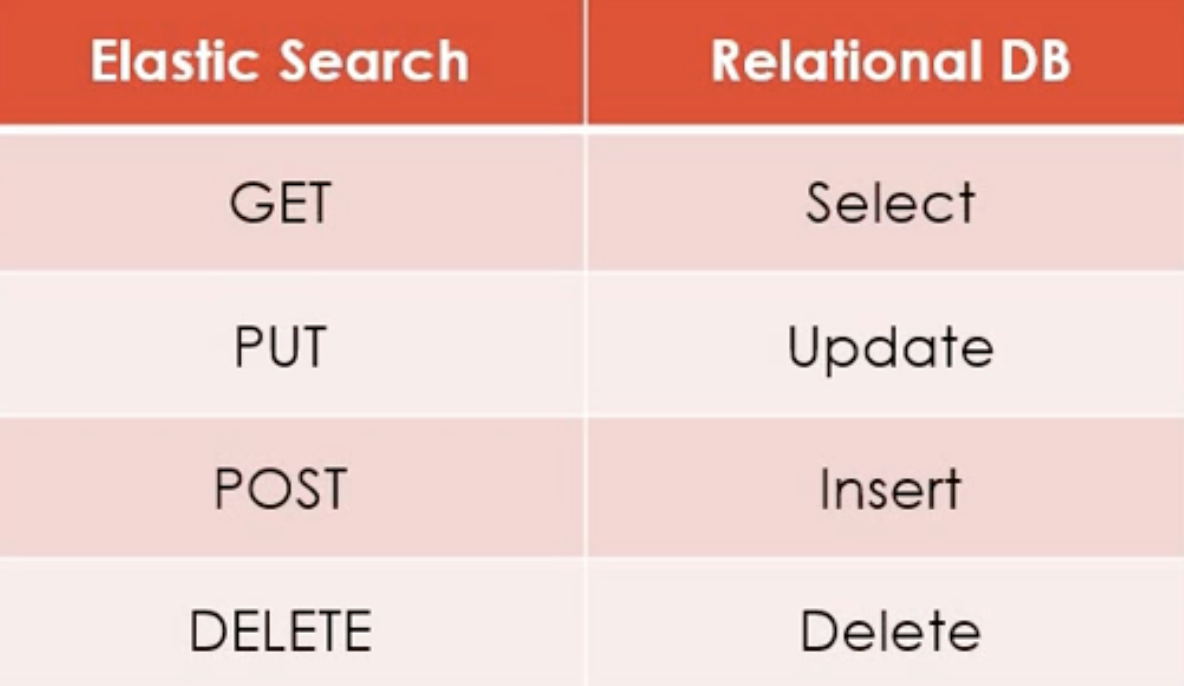

Elastic Search CRUD 실습
주의) put, patch 가 용도에 맞게 쓰이지 않아서 데이터 변경시에는
header에 _update 붙이고 post로 쏴야 함
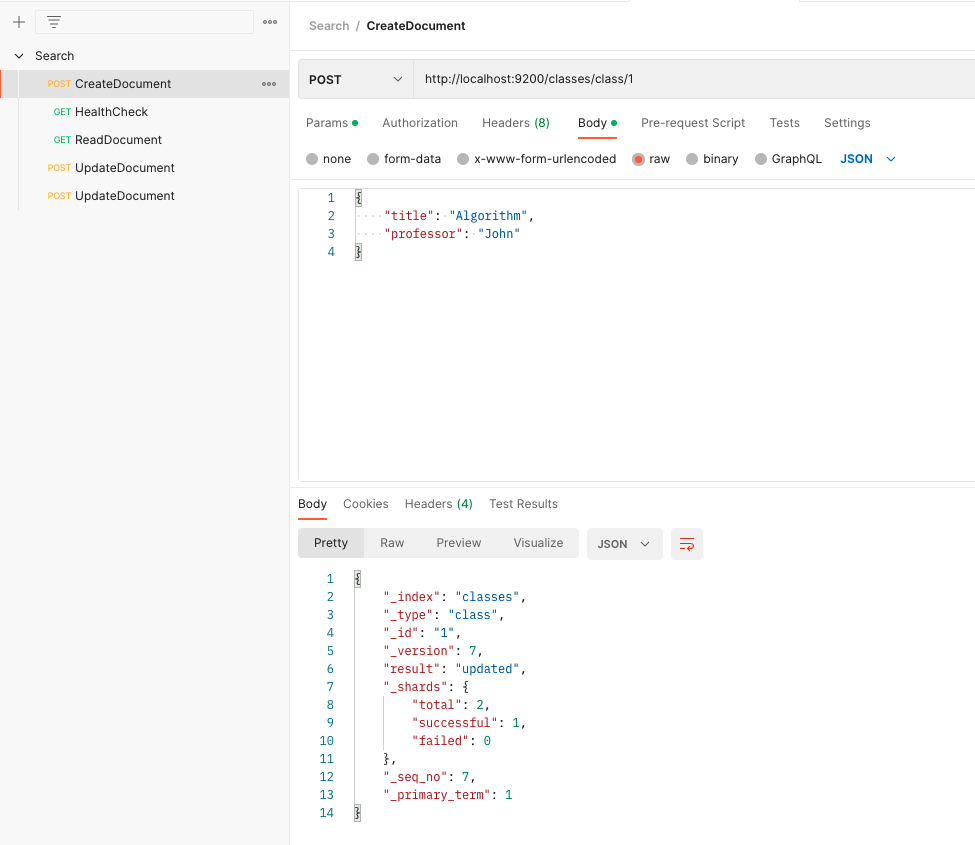
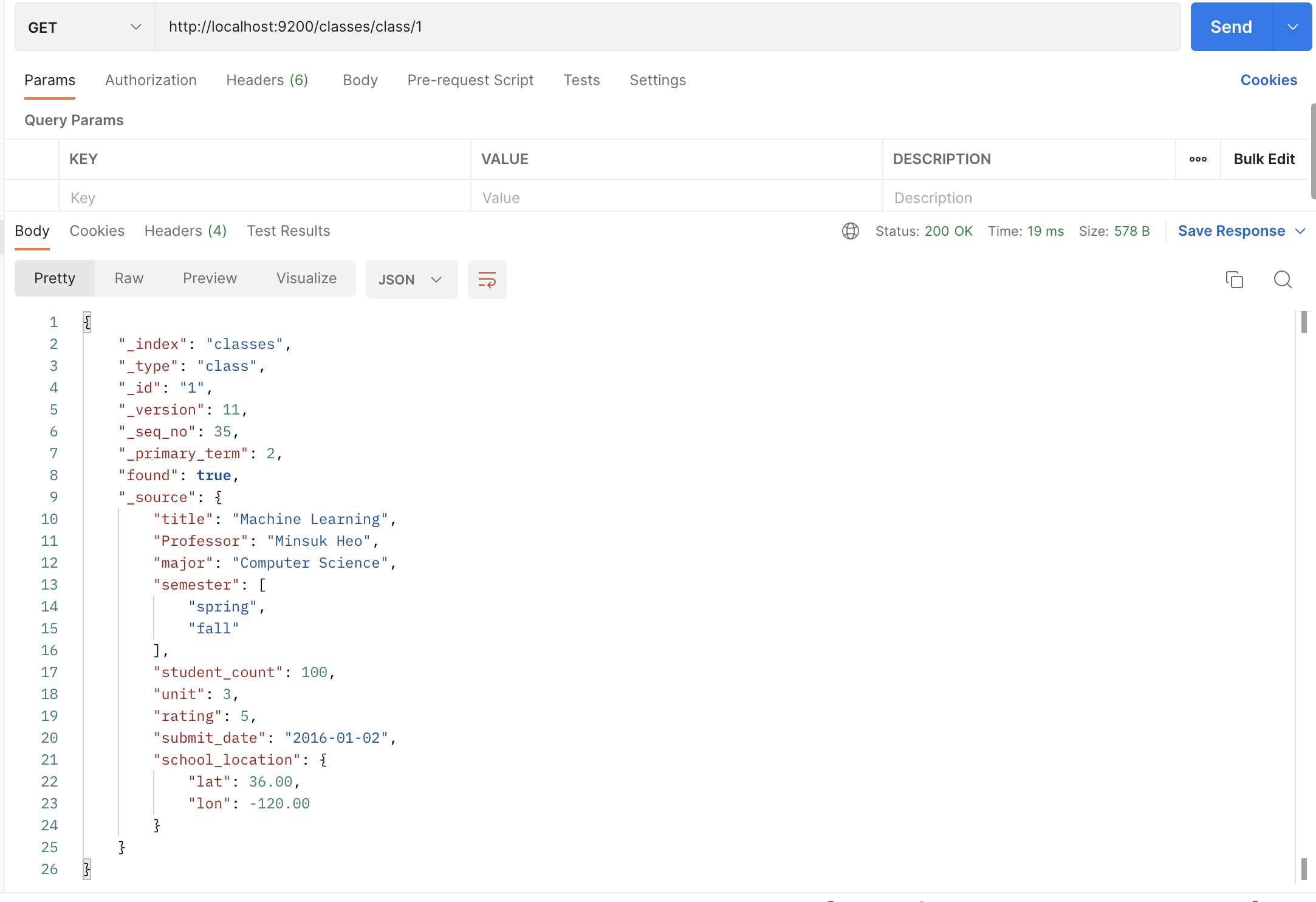
BULK POST
post method로 bulk 생성 할 때 mapper_parsing_exception 발생
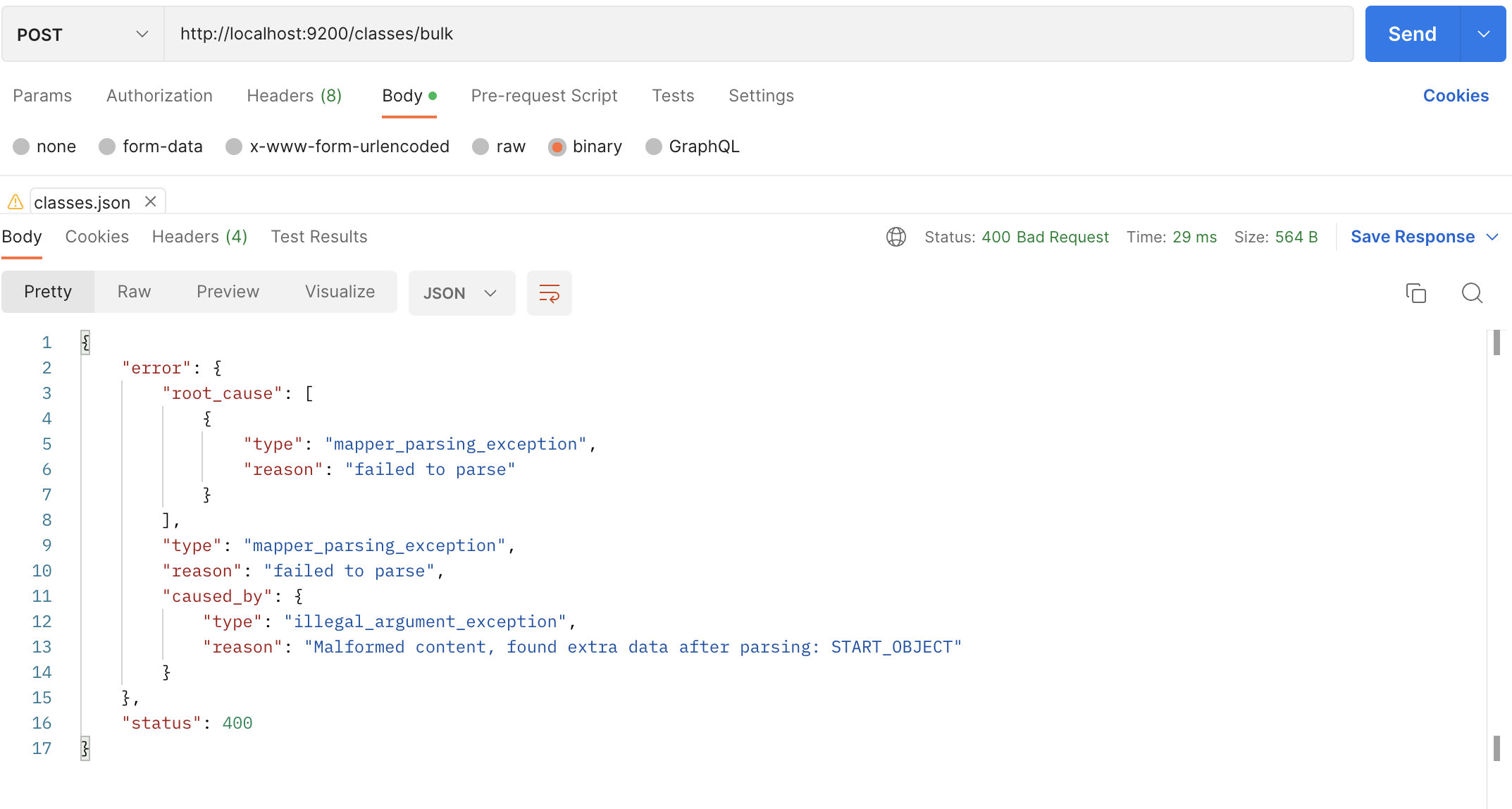
_bulk로 쏴야됨 → Nginx단에서 underscore 확인 안되는 경우가 있어서 nginx.conf 에서 설정값(underscores_in_headers on;) 수정해야 함
POST Method : http://localhost:9200/classes/_bulk
https://stackoverflow.com/questions/33340153/elasticsearch-bulk-index-json-data/33340234#33340234
https://web-front-end.tistory.com/43
MAPPING(SCHEMA)
-
인덱스 생성
- Put Method
- http://localhost:9200/classes/
-
조회하면 mapping이 비어있음
{ "classes": { "aliases": {}, "mappings": {}, "settings": { "index": { "creation_date": "1694398754356", "number_of_shards": "1", "number_of_replicas": "1", "uuid": "NDmKCQbqQlepC3kJK8nbig", "version": { "created": "7090199" }, "provided_name": "classes" } } } } -
데이터 매핑 → 타입 에러 발생 (**illegal_argument_exception)**
원인: elastic version
mapping 생성할 때 elasticsearch 7.x 버전 이후부터는 curl 리퀘스트에서 헤더를 명확히 설정해주어야 하고 include_type_name을 true로 설정해주어야 한다.
http://localhost:9200/classes/class/_mapping?include_type_name=true
그리고 string 으로 되어 있는 것은 text로 변경 해야 한다.
—> mapping에 데이터가 잘 들어감
{ "classes": { "aliases": {}, "mappings": { "properties": { "major": { "type": "text" }, "professor": { "type": "text" }, "rating": { "type": "integer" }, "school_location": { "type": "geo_point" }, "semester": { "type": "text" }, "student_count": { "type": "integer" }, "submit_date": { "type": "date", "format": "yyyy-MM-dd" }, "title": { "type": "text" }, "unit": { "type": "integer" } } }, "settings": { "index": { "creation_date": "1694398754356", "number_of_shards": "1", "number_of_replicas": "1", "uuid": "NDmKCQbqQlepC3kJK8nbig", "version": { "created": "7090199" }, "provided_name": "classes" } } } }ref. https://www.inflearn.com/questions/12385/elasticsearch-에러-관련입니다
https://velog.io/@mingtorr/elasticsearch-illegalargumentexception-에러
SEARCH
Get Method http://localhost:9200/basketball/record/_search
{
"took": 10,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "basketball",
"_type": "record",
"_id": "1",
"_score": 1.0,
"_source": {
"team": "Chicago Bulls",
"name": "Michael Jordan",
"points": 30,
"rebounds": 3,
"assists": 4,
"submit_date": "1996-10-11"
}
},
{
"_index": "basketball",
"_type": "record",
"_id": "2",
"_score": 1.0,
"_source": {
"team": "Chicago Bulls",
"name": "Michael Jordan",
"points": 20,
"rebounds": 5,
"assists": 8,
"submit_date": "1996-10-11"
}
}
]
}
}특정 필드 값으로 검색하기 → 하나만 나오는 것을 알 수 있다.
http://localhost:9200/basketball/record/_search?q=points:30
{
"took": 22,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "basketball",
"_type": "record",
"_id": "1",
"_score": 1.0,
"_source": {
"team": "Chicago Bulls",
"name": "Michael Jordan",
"points": 30,
"rebounds": 3,
"assists": 4,
"submit_date": "1996-10-11"
}
}
]
}
}Aggregation(Metric)
도큐먼트 조합을 통해 값을 도출하는 방법
평균, 최대, 최솟값
Metric Aggregation (산술 - 평균, 최소, 최댓값 )
{
"size" : 0,
"aggs" : {
"stats_score" : {
"stats" : {
"field" : "points"
}
}
}
}
results
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 35,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"stats_score": {
"count": 2,
"min": 20.0,
"max": 30.0,
"avg": 25.0,
"sum": 50.0
}
}
}Aggregation(Bucket)
group by
쿼리
{
"size" : 0,
"aggs" : {
"players" : {
"terms" : {
"field" : "team.keyword"
}
}
}
}
데이터
{ "index" : { "_index" : "basketball", "_type" : "record", "_id" : "1" } }
{"team" : "Chicago","name" : "Michael Jordan", "points" : 30,"rebounds" : 3,"assists" : 4, "blocks" : 3, "submit_date" : "1996-10-11"}
{ "index" : { "_index" : "basketball", "_type" : "record", "_id" : "2" } }
{"team" : "Chicago","name" : "Michael Jordan","points" : 20,"rebounds" : 5,"assists" : 8, "blocks" : 4, "submit_date" : "1996-10-13"}
{ "index" : { "_index" : "basketball", "_type" : "record", "_id" : "3" } }
{"team" : "LA","name" : "Kobe Bryant","points" : 30,"rebounds" : 2,"assists" : 8, "blocks" : 5, "submit_date" : "2014-10-13"}
{ "index" : { "_index" : "basketball", "_type" : "record", "_id" : "4" } }
{"team" : "LA","name" : "Kobe Bryant","points" : 40,"rebounds" : 4,"assists" : 8, "blocks" : 6, "submit_date" : "2014-11-13"}결과
{
"took": 30,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 37,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"players": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "Chicago",
"doc_count": 2
},
{
"key": "LA",
"doc_count": 2
}
]
}
}
}팀별로 묶어서 점수 내기
{
"size" : 0,
"aggs" : {
"team_stats" : {
"terms" : {
"field" : "team.keyword"
},
"aggs" : {
"stats_score" : {
"stats" : {
"field" : "points"
}
}
}
}
}
}키바나 매니지먼트
- 데이터 생성
- 키바나 인덱스 매핑
- management → Index Patterns → Create Index Pattern → Index pattern → basketball → next step → filter field name → submit_date
키바나 디스커버
- 디스커버 → 날짜 선택
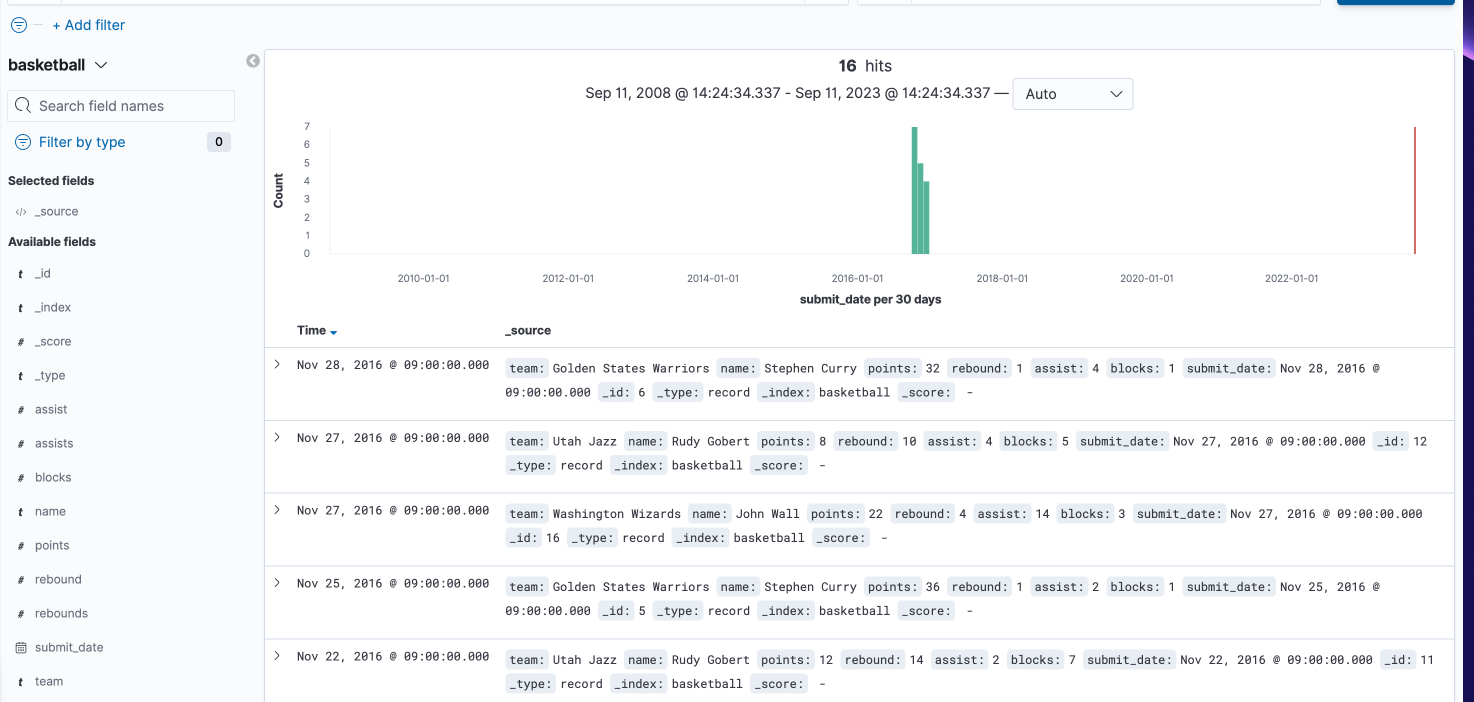
키바나 타일 맵
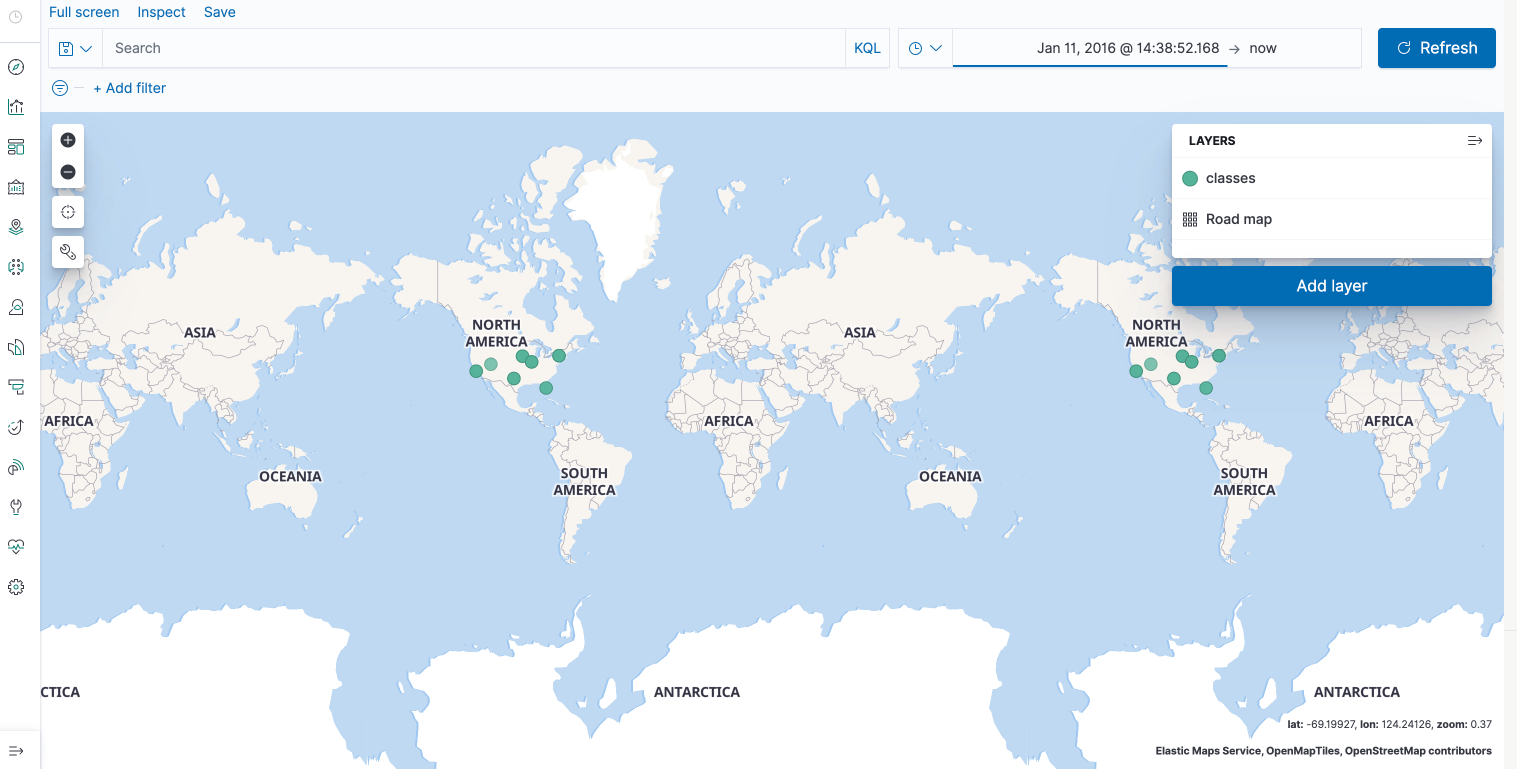
로그 스태시
!!인풋 담당!! → elastic search → kibana
input (stdin)/ filter / output(stdout)
csv(text) → 수치로 변환할 수 있다.
ref. 인프런 - ELK 스택 (ElasticSearch, Logstash, Kibana) 으로 데이터 분석
