1부 - 기초 지식
01. 들어가며
1.1 정보 검색이란 무엇인가?
정보검색(Information Retrieval)이란 수많은 전자 문서나 사람의 언어로 만들어진 자료에서 정보를 찾고 다루는 기술을 말한다.
ex) 웹 검색엔진, 디지털 도서관, 지역 검색, 기업용 자체 검색 시스템, 데스크톱 검색
1.1.1 웹 검색
웹 검색의 원리 : “웹 페이지를 모으고 순위를 매긴다.”
- 질의에 담긴 단어를 포함한 페이지들을 추리고 각각 점수를 계산한 다음 겹치는 내용을 제거하고 문서 내용을 발췌해 요약본과 문서 링크를 웹 브라우저에 띄운다.
- 웹 검색엔진은 캐시 서버를 둬 자주 요청받는 질의는 곧바로 응답하며 복제 서버를 둬 질의를 병렬 처리한다.
- 검색엔진은 검색 결과를 정확하게 얻고자 웹 구조의 특정 순간 상태(스냅숏)을 저장한다.
정보를 검색했을 때 적당하지 않은 항목, 페이지가 나열된 순서를 개선하는 방법이 있을까?
적합도 순위화 알고리즘을 효율적으로 구현하고 평가하는 것이 정보 검색 분야에서 중요한 문제
적합도 순위화 알고리즘 : 순위를 매길 때 여러 문서 특성을 균형 있게 반영해 질의 의도에 부합하는 수준을 예측하는 방식.
검색 엔진의 순위화 알고리즘에서 최상위 문서를 고르는 기준은 문서의 내용과 구조, 다른 페이지와의 연관성, 웹 전체 구조가 있을 수 있고 특수한 유형의 질의는 사용자의 지리적 위치, 과거 검색 이력 등을 반영한다.
1.1.2 다른 검색 응용 프로그램
파일 검색 :
- 데스크톱 검색엔진으로 로컬 하드 디스크 또는 네트워크로 연결된 디스크에 저장된 파일을 검색하고 조회할 수 있다.
- 데스크톱 검색엔진은 웹 검색엔진과 달리 파일 형식과 생성 시간을 알아야 한다. 사용자가 이메일 파일에서만 검색하거나 파일의 생성 또는 다운로드 기간을 정해 검색할 수도 있기 때문이다.
- 파일의 저장한 내용은 자주 바뀌기 때문에 검색 시스템을 운영체제의 파일 시스템과 직접 연계하고 적절히 튜닝해야 수많은 갱신을 반영할 수 있다.
기업용 정보 검색 시스템 :
웹 검색엔진을 인트라넷에 적용해 직원만 조회할 수 있는 문서 수집
문서 갱신, 버전 관리, 접근 권한 제어 같은 기능을 갖춘 문서 관리 시스템도 있음
디지털 라이브러리, 전문 정보 검색 시스템 :
- 정보 가치가 높아 주로 소유권이 있는 자료에 접근
- 저작권 때문에 공개된 웹 사이트에 게재하지 않는 뉴스 기사, 의학 저널, 지도 , 서적
- 잘 편집되고 주제가 명확해 저자, 제목, 날짜, 출판 정보 같은 특성 활용 → 정확도 높은 검색 결과
- OCR(Optical Character Recognition)로 전자화해서 저장
1.1.3 다른 정보 검색 응용 분야
정보 검색 기술의 핵심은 검색 과정 그 자체지만 저장 공간, 자료 가공, 사람의 언어에 기반한 탐색 기술이 얽힌 다양한 문제도 관심 범위에 속함
- 문서 전달, 조건 검사, 선택적 배포 작업
- 전형적인 정보 검색 과정과 정반대
- 전형적인 검색이란? 임의의 질의를 받아 정해진 문서를 평가
- 질의 집합을 미리 고정하고 새로운 문서가 들어오면 정해 놓은 질의로 평가해 사용자의 관심을 끌 만한 것을 골라낸다.
- ex) 그날의 뉴스를 카테고리화, 이메일 시스템의 스팸 판별기
- 문서 클러스터링과 분류 시스템
- 분류 시스템: 여러 유형에 속한 자료를 미리 학습한다. 그 후 학습시키지 않은 자료를 입력해 분류한다.
- 클러스터링 시스템: 학습용 자료를 사전에 입력 받지 않는다. 스스로 어떤 패턴을 찾아 문서들을 적절한 묶음으로 나눈다.
- 요약 시스템
- 원본 문서를 핵심적인 문단이나 문장, 구절로 몇개로 줄인다. 웹 검색 결과에 표시하는 본문 발췌가 문서 요약의 한가지 보기이다.
- 정보 추출 시스템
- 자료에서 장소나 날짜 같이 정해진 항목을 찾아내고, 이 항목들을 결합해 항목 간의 관계를 표현하도록 구조화 한다. 예를 들면 웹 자료로부터 책과 저자 목록을 생성하는 것과 같은 일이다.
- 주제 추적 시스템
- 끊임없이 입력되는 뉴스 기사 등으로부터 특정 사건을 찾아내고 그 사건의 흐름을 추적한다.
- 전문가 검색 시스템
- 조직 내에서 어떤 분야의 전문가를 찾아준다.
- 질의 응답 시스템
- 질문이 주어지면 여러 출처에서 모은 정보를 결합해 간결하게 대답한다. 검색, 요약, 정보 추출을 비롯한 정보 검색 기술이 자주 쓰인다.
- 멀티미디어 검색 시스템
- 적합도 순위화 방식이나 기타 정보 검색 기술을 화상, 영상, 음악, 음성 자료로 확장 적용한다.
1.2 정보 검색 시스템
1.2.1 정보 검색 시스템의 기본 구조
- 사용자는 주제(topic)을 검색한다.
- 사용자는 원하는 정보를 찾고자 검색 시스템에 질의를 입력한다.
- 질의는 대체로 텀(term) 몇 개로 이뤄지며, 웹 검색에는 두 세텀 짜리 질의가 흔하다.
- ‘텀’이라고 쓴 이유는 질의가 단어만으로 이뤄지는 건 아니기 때문이다.
- 텀은 원하는 정보가 무엇이냐에 따라 날짜, 숫자, 악보 구절 같은 것이 되기도 한다.
- 와일드카드 연산자(*)와 부분 부합 연산자도 질의 텀이 될 수 있다.
- inform* (informs, informal, informant, informative) 등에 부합한다.
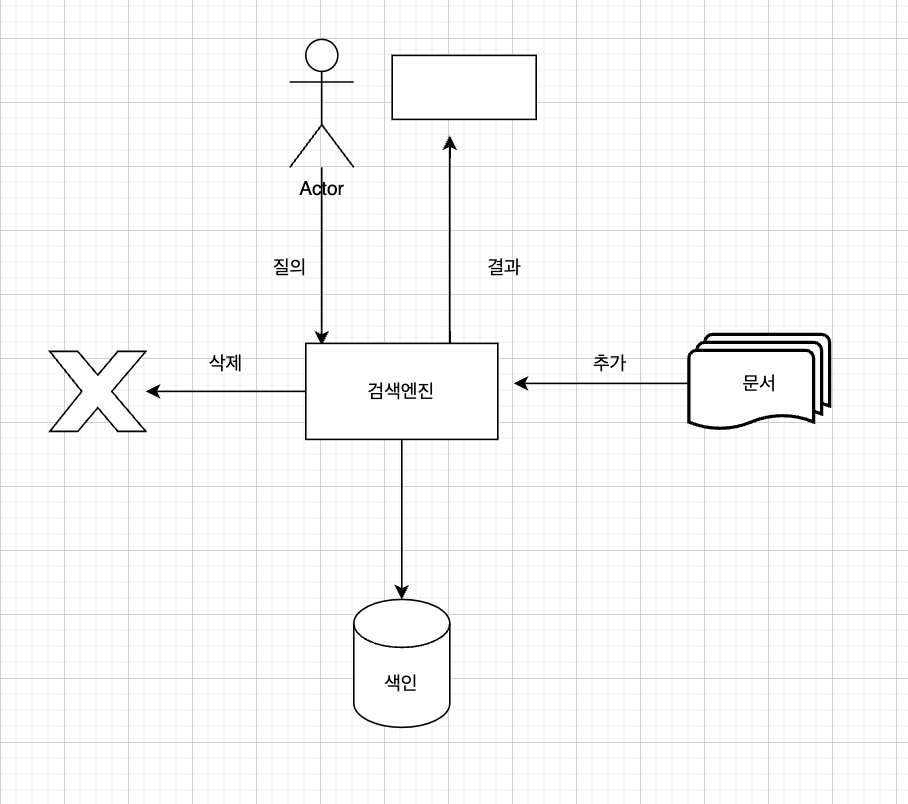
검색엔진은 사용자의 개인 컴퓨터에서 작동하거나 원격에 있는 대규모 클러스터에서 작동하거나 그 둘 사이 어디에선가 작동하면서 질의를 처리한다.
검색 엔진의 주요 작업은 문서 모음에 대한 역색인(inverted index)를 만들고 유지하는 일이다.
역색인은 문서 탐색과 적합도 순위화에 사용하는 가장 중요한 자료 구조로, 각 텀과 그 텀이 문서에서 등장한 위치를 이어준자.
색인의 크기는 원본 문서 규모에 필적하므로 색인에 접근하고 갱신하는 속도는 빨라야 한다.
1.2.2 문서 갱신
“문서” : 검색 결과로 돌려줄 수 있는 온전한 단위 / 이메일, 웹페이지, 뉴스 기사, 동영상 등.
- 책 한 권에서 특정 페이지나 문단을 찾아내는 것처럼 어떤 커다란 대상을 여러 부분으로 나누고 각 부분을 검색 결과로 돌려준다면 이 부분들을 요소(elements)라고 부름
- 대부분의 문서 갱신은 전체 집합에 일부를 더하거나 전체에서 일부를 없앤다. 문서를 일단 추가하면 이후 내용을 바꾸는 일은 없다
- 대부분 문서를 수정할 때 기존 페이지 내용이 바뀐 것을 탐지하더라도 기존 페이지를 없애고 바뀐 내용을 새 문서 인것 처럼 추가한다. 예외적으로 이메일은 새 메시지를 저장함 마지막에 덧붙인다. 이메일 저장함은 이미 크거나 금방 커질 수 있어서 전체를 덮어 쓰는 것보다 뒤에 덧붙이는 쪽이 효율적이다.
1.2.3 성능 평가
검색 시스템 성능을 평가 할때는 주로 능률과 효율성을 따진다.
시스템의 능률은 시간과 공간의 척도로 측정한다.
가장 정확한 능률 척도는 응답시간(응답 지연시간) : 질의를 보낸 순간부터 검색 결과를 돌려받은 순간까지 걸린 시간을 뜻한다.
초당 처리하는 질의 수로 나타내는 질의 처리량 역시 중요한 척도가 된다.
정보 검색 시스템이 각 질의마다 적합도 확률이 높은 순서대로 문서를 나열한다면 사용자가 느끼는 전반적인 검색 시스템의 성능이 가장 좋을 것이다.
“문서의 크기”와 “주제 범위”를 간과해서는 안된다.
- 문서의 특화도:
- 문서 내용이 얼마나 특정 정보에 집중하는지를 반영한다.
- 특화도가 높은 문서는 특정 주제에 관련된 내용이 대부분을 차지한다.
- 특화도가 낮은 문서는 상당 부분 주제와 관련 없는 내용이다.
- 문서의 완전도:
- 문서 내용이 해당 정보를 얼마나 폭넓게 다루는지 반영
- 완전도가 높으면 관련된 사실을 거의 모두 포함하고 , 낮으면 그중 일부만 다룬다.
“문서가 길면 어떤 주제에 대한 모든 사실을 포함해서 완전도가 높지만, 부수적인 내용도 많아 특화도는 높지 않을 것이다”
- 문서의 참신함 : 사용자가 알고 싶은 새로운 정보
