
🎬 유튜브 쇼츠 자동 생성 & 업로드 시스템 구축기
짧은 영상의 시대, 쇼츠 콘텐츠는 이제 유튜브 성장의 핵심입니다.
하지만 영상 제작 → 편집 → 업로드까지 매번 수작업으로 처리하기엔 너무 번거롭죠.
그래서 저는 이 모든 과정을 완전히 자동화한 파이프라인을 직접 구축했습니다.
이 글은 그 프로젝트의 전체 개요를 소개하는 글입니다.
⸻
🎯 프로젝트 목표
• 🔍 영상에 사용될 소스 자동 크롤링
• 🧠 ChatGPT API를 이용한 스크립트 & 이미지 자동 생성
• 🔊 ElevenLabs / Google AI를 활용한 오디오(TTS) 생성
• 🧩 Revideo를 이용한 영상 생성
• ⬆️ YouTube Data API v3로 쇼츠 자동 업로드
• 🧠 중복 방지를 위한 영상/스크립트/메타데이터 DB 관리
⸻
🛠 사용한 기술 스택
• TypeScript / Node.js – 자동화 로직 전반
• Revideo – 영상 클립 생성 및 편집
• OpenAI API (ChatGPT) – 콘텐츠 스크립트 및 이미지 프롬프트 생성
• ElevenLabs / Google TTS – 음성 합성
• YouTube API – 영상 자동 업로드
• SQLite / Supabase 등 DB – 콘텐츠 기록 및 중복 방지
• pnpm – 패키지 관리
⸻
오늘은 첫번째 스텝으로, 프로젝트 생성 및 Revideo 설치, 설정 과정에 대해 설명해보겠습니다.
🎬 Revideo란?
Revideo는 React 기반으로 영상을 생성할 수 있는 오픈소스 라이브러리입니다.
HTML/CSS처럼 구성요소를 조립하듯이 영상을 만들 수 있기 때문에, 기존의 FFmpeg처럼 복잡한 명령어를 다룰 필요 없이 개발자가 친숙한 방식으로 영상 콘텐츠를 구성할 수 있다는 게 큰 장점이에요.
✅ 주요 특징
• React 컴포넌트로 영상 만들기
<Video>, <Sequence>, <Audio>, <Img> 등 실제 DOM처럼 영상 요소를 조립 가능
• 타입스크립트 기반
TS로 정적 타입 지원을 받으며 안정적으로 구성 가능
• 동적 콘텐츠에 강함
API에서 불러온 데이터나 랜덤 요소 등도 쉽게 반영 가능
• 웹 기반으로 미리보기/렌더링 가능
개발 환경에서도 실시간으로 영상 구조 확인 가능
1. 프로젝트 생성
1. 깃허브에 새로운 레퍼지토리 생성
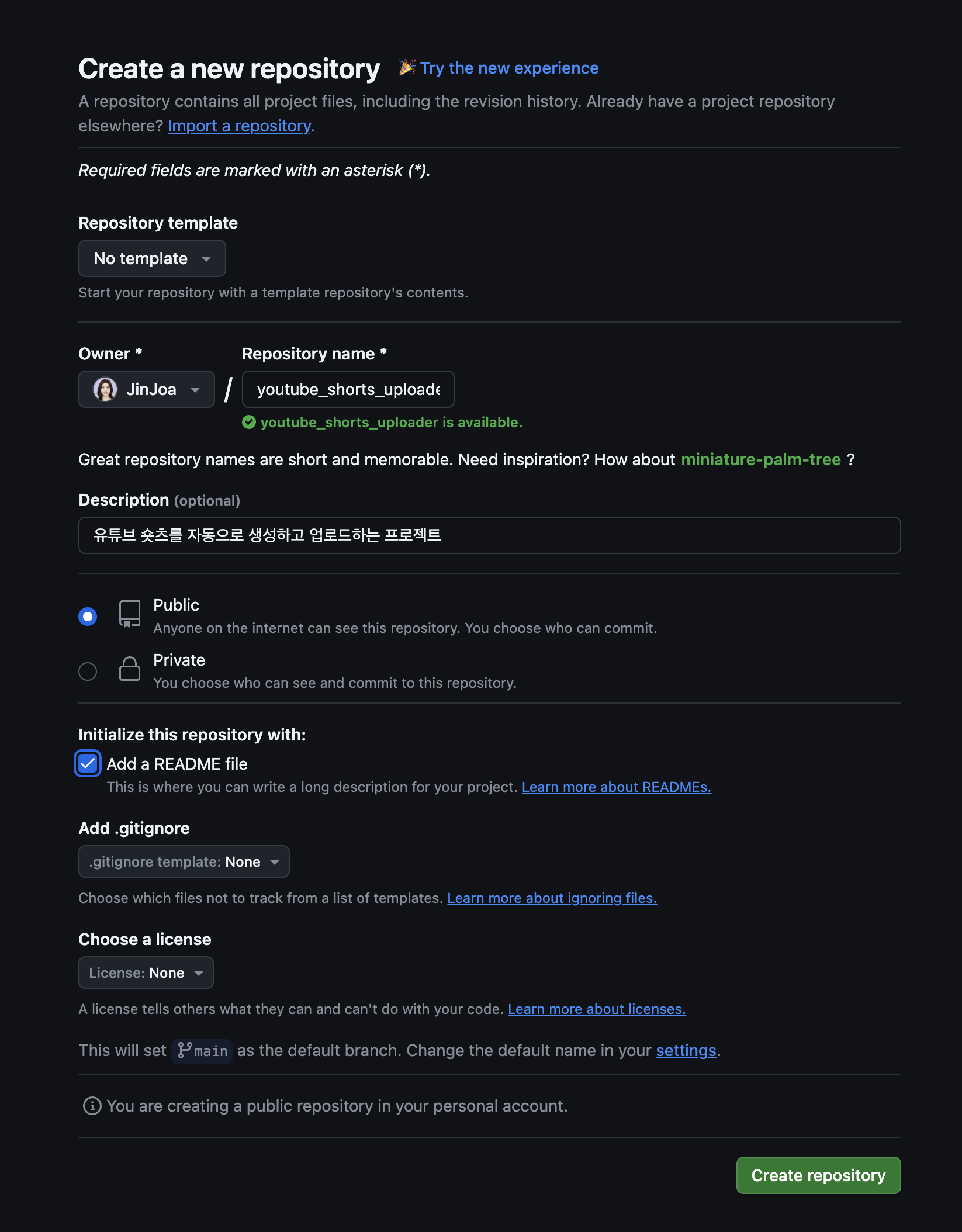
2. 생성된 레퍼지토리 open GitHub desktop
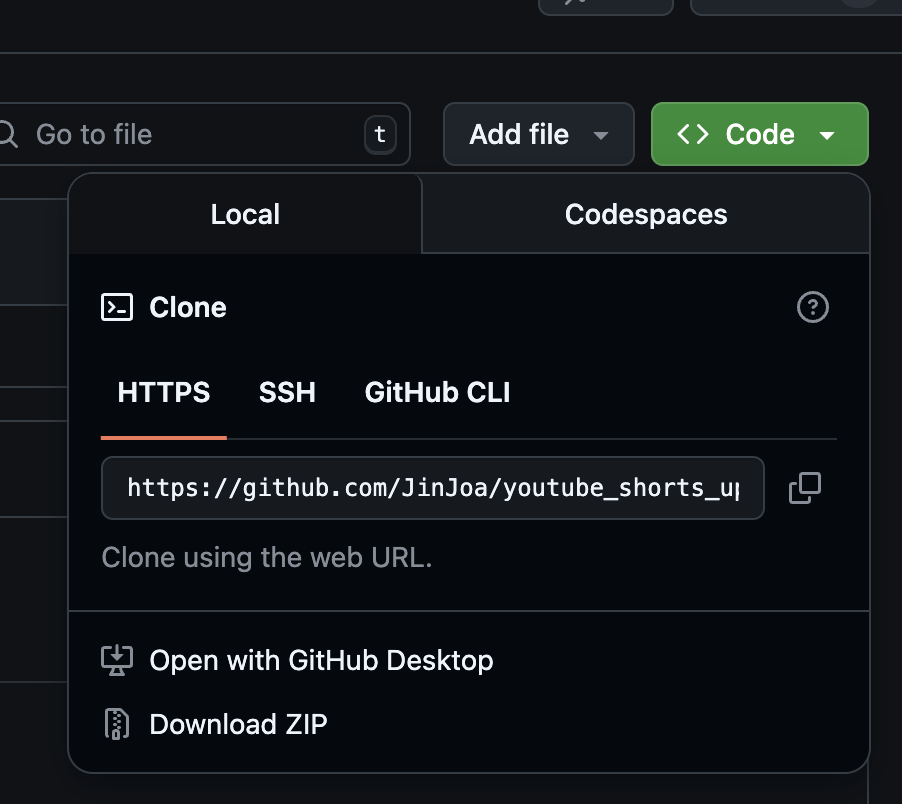
3. Cursor에서 해당 프로젝트 열기
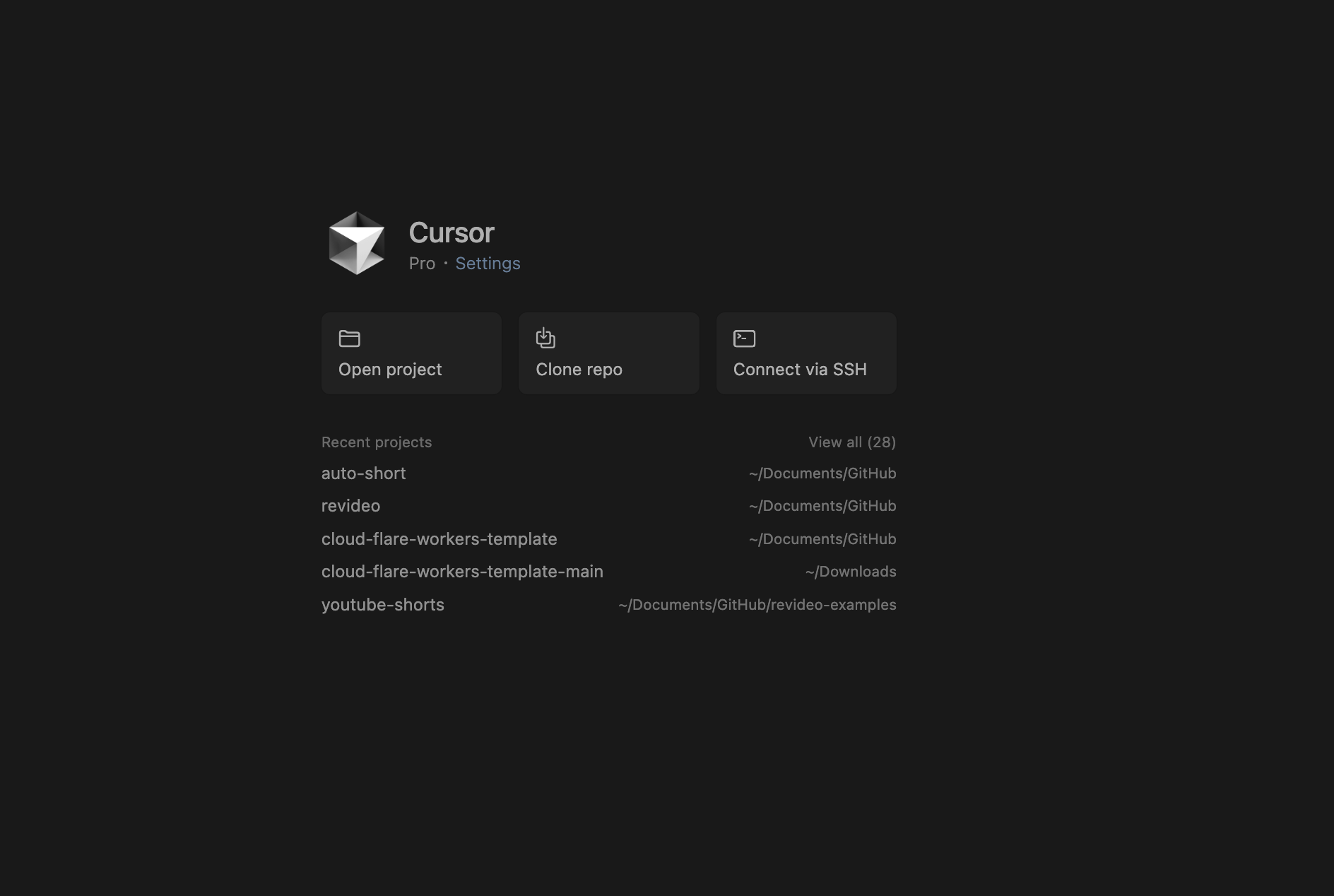
🧠 Cursor란?
Cursor는 최근 개발자들 사이에서 화제가 되고 있는 AI 기반 코드 에디터입니다.
기본적으로는 VS Code를 기반으로 만들어졌지만, 거기에 ChatGPT 수준의 AI 코딩 도우미가 깊이 통합된 버전이라고 보면 이해가 쉬워요.
⸻
✅ 주요 특징
• 코드 리팩토링/생성/설명/테스트 작성 등을 자연어로 요청 가능
예: "이 함수 테스트 코드 만들어줘", "여기서 성능 병목이 어딘지 찾아줘"
• 파일 단위가 아니라 ‘맥락 단위’로 이해
특정 함수나 클래스뿐 아니라, 전체 프로젝트 흐름까지 고려해서 코멘트하거나 수정 제안 가능
• VS Code와 거의 동일한 인터페이스
기존 VS Code 사용자라면 별다른 러닝커브 없이 바로 사용 가능
• Git 연동 + PR 리뷰도 지원
커밋 메시지 자동 작성, PR 리뷰, 코드 변경 의도 설명 등도 AI가 도와줌
코드를 직접 수정해달라고 해도 되고, 설명만 요청할 수도 있어요.
무엇보다 맥락을 잘 파악하고, 수정 이유까지 설명해주는 게 정말 편합니다.
⸻
📦 설치 방법
Cursor 공식 홈페이지에서 직접 설치 가능합니다:
👉 https://www.cursor.sh
4. Node 버전 확인
% node -v #버전이 20 이상인지 확인해주세요.5. revideo 설치
% pnpm create @revideo@latest
✔ Project name … youtube_shorts_uploader
✔ Project path … youtube_shorts_uploader
✔ Choose a starter template › YouTube Shorts #유튜브 숏츠 템블릿을 선택해주세요.
Scaffolding, this can take a few seconds...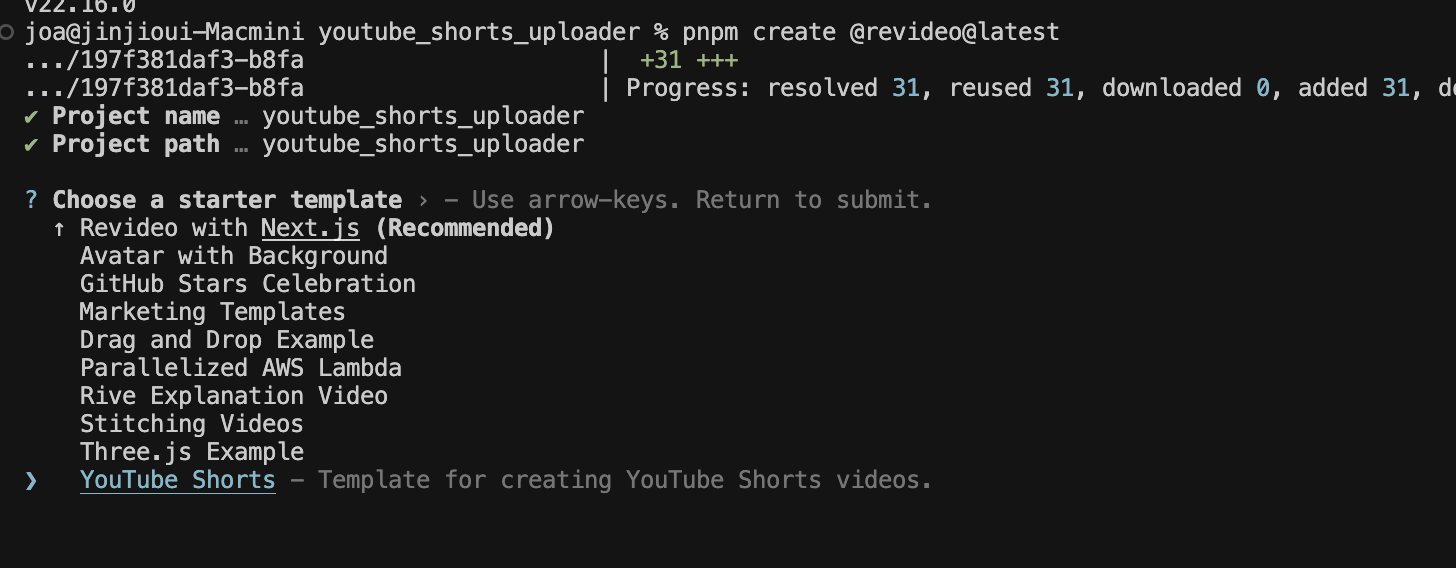
6. revideo 시작
# 프로젝트 폴더로 이동
% cd youtube_shorts_uploader
# 의존성 패키지 설치
% pnpm install
# preact 패키지 설치
% pnpm add preact
# @preact/signals 패키지 설치
% pnpm add @preact/signals
# (필요시) 다시 한 번 전체 의존성 설치
% pnpm install
# 프로젝트 실행 (start 스크립트 실행)
% pnpm starthttp://localhost:9000/#/에 접속해, 리비디오 창이 올바르게 뜨는지 확인하세요.
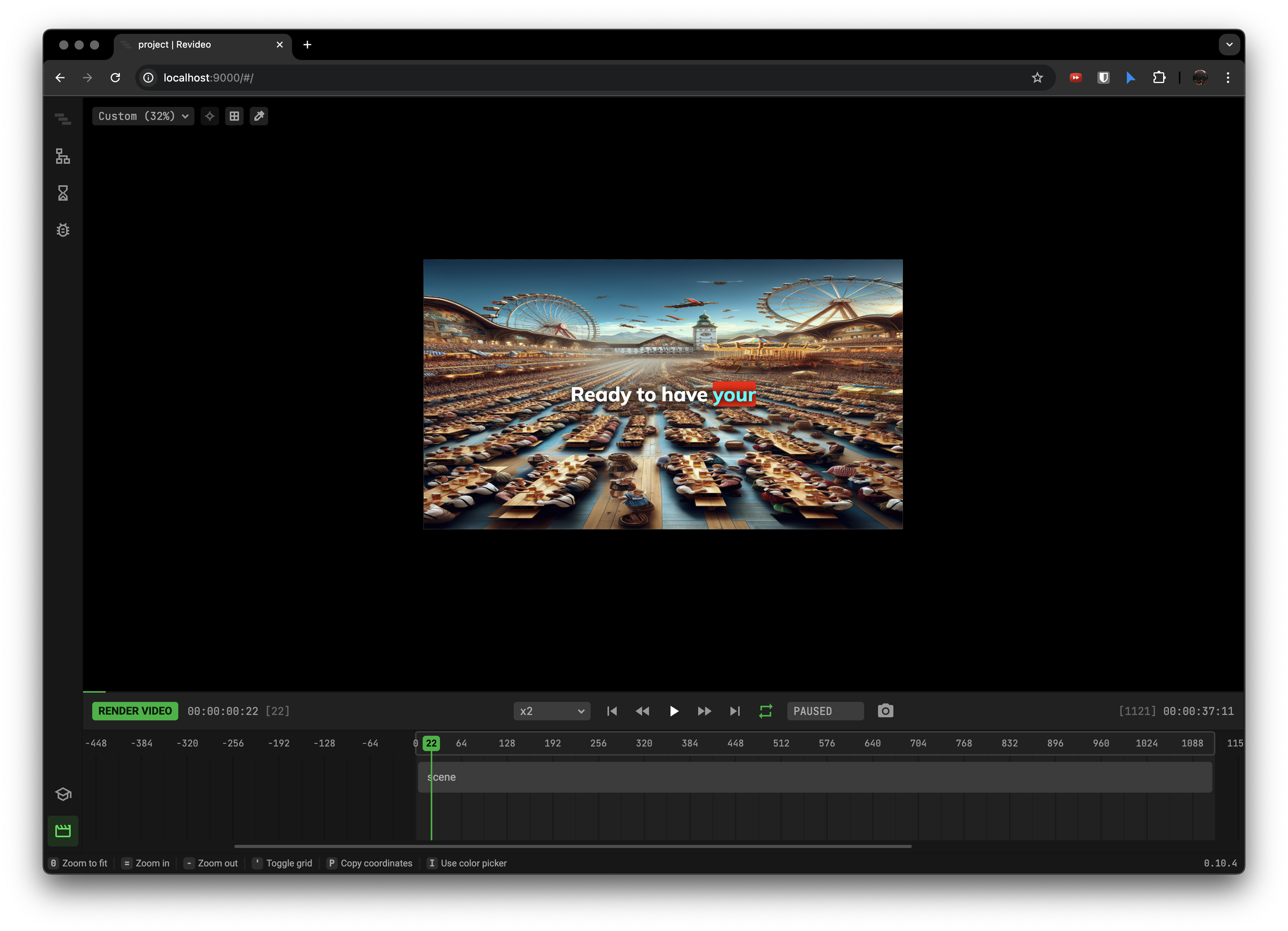
7. 루트 파일에 .gitignore 추가
/dist
node_modules
.env
.DS_Store
node_modules/.vite/deps/_metadata.json
node_modules
8.루트 파일에 .env 파일 추가
필수 환경 변수 설정
# OpenAI API (스크립트 생성용)
OPENAI_API_KEY=your_openai_api_key
# ElevenLabs API (음성 생성용)
ELEVENLABS_API_KEY=your_elevenlabs_api_key
# YouTube API (업로드용)
YOUTUBE_CLIENT_ID=your_youtube_client_id
YOUTUBE_CLIENT_SECRET=your_youtube_client_secret
### 추후 필요한 API 추가 작성 예정OpenAI API 발급 방법
OpenAI 사이트에 들어가 회원가입 > 오른쪽 상단 프로필 사진 > Your profile > Organization > API keys > + Create new secret > 새로운 키 발급 후 꼭 복사해서 잘 저장해두기(이후 재 열람 불가능) > Bliing에서 필요한 금액만큼 선결제
- OpenAI API와 ChatGPT 유료버전은 별개입니다
- 미결제 시, OpenAI API 사용안됨.
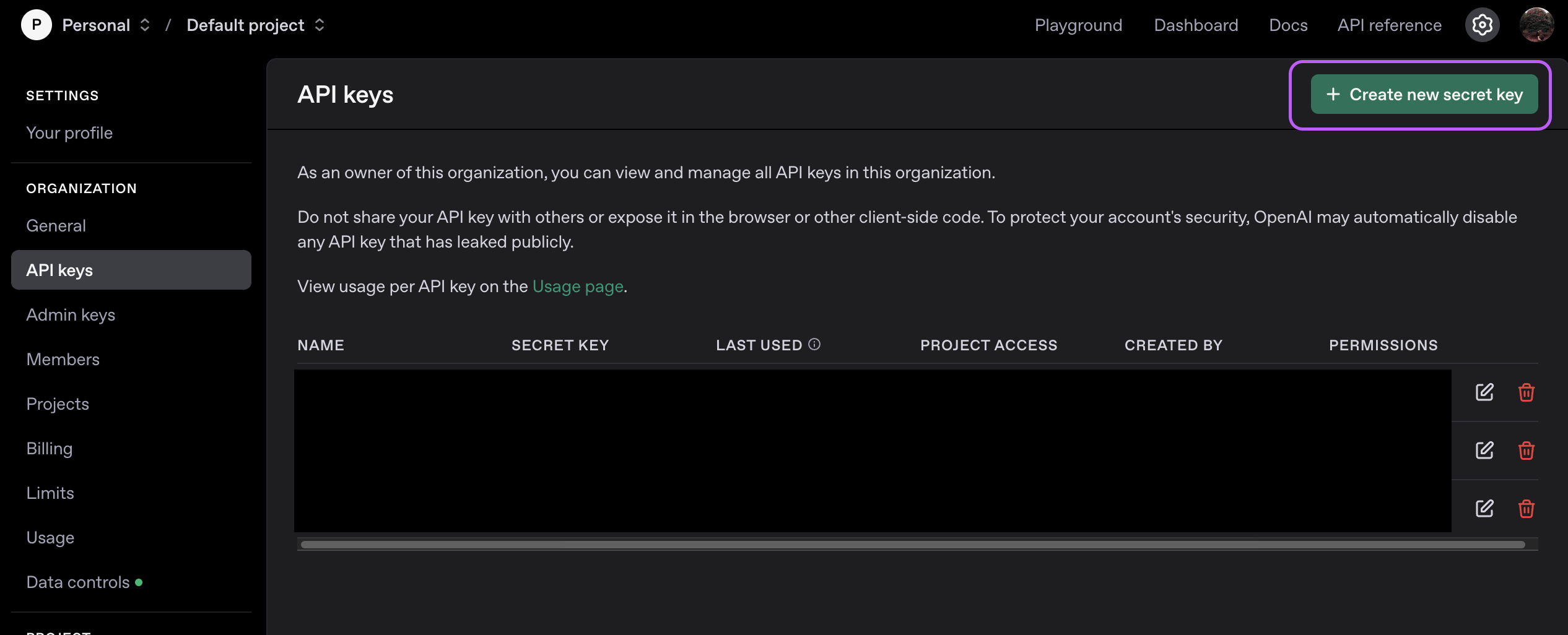
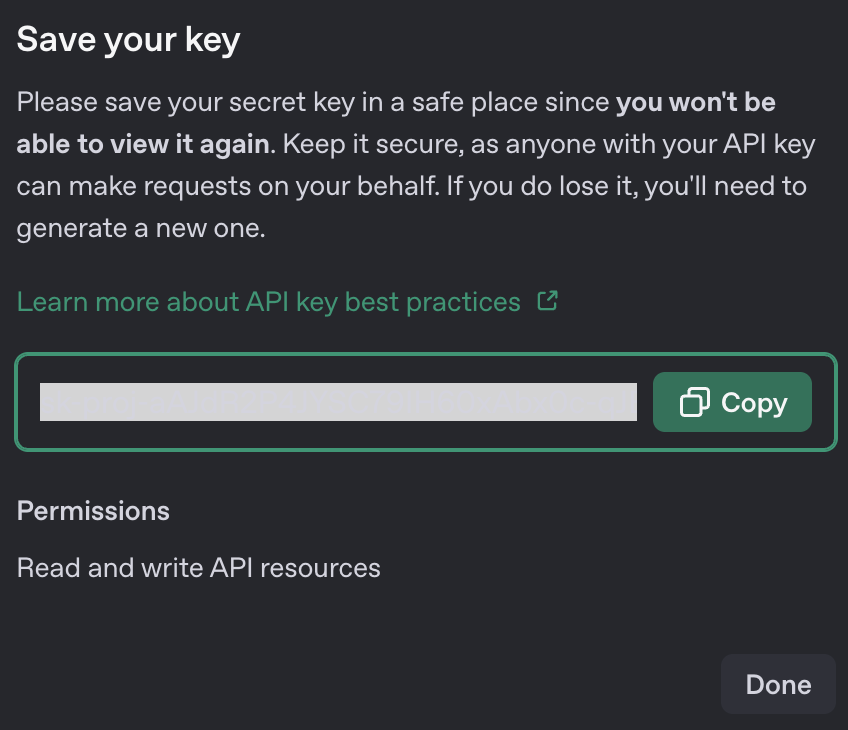
ElevenLabs API 발급방법
ElevenLabs 접속 > 하단 오른쪽 프로필사진 클릭 > API Keys > Create API Key
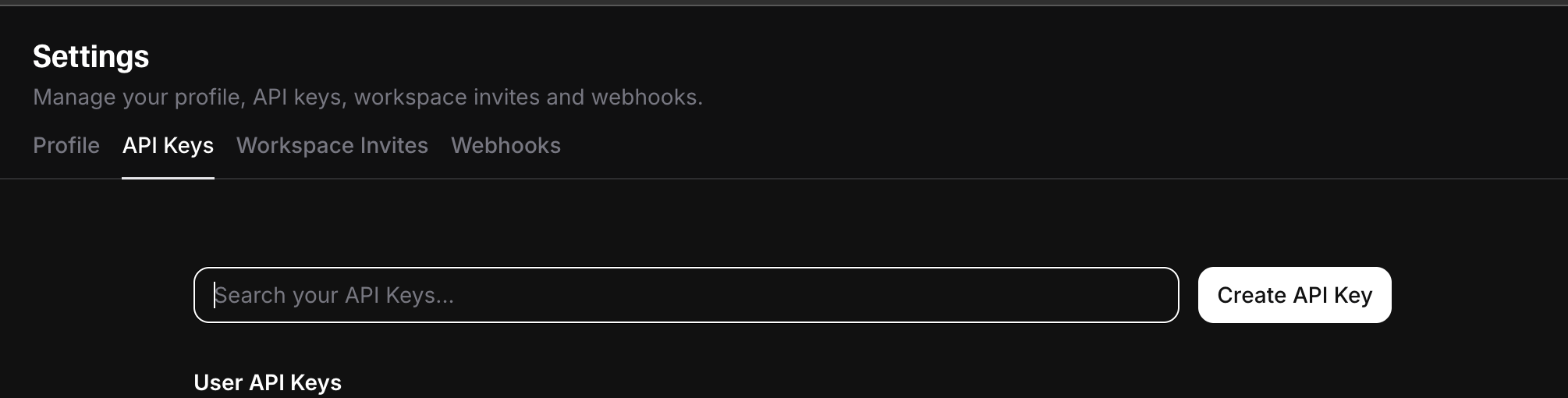
- 일정량 무료 사용가능
- 다양한 목소리가 사용하고 싶다면, 업그레이드 필요
9. /public 폴더 생성
public 폴더는 동영상 생성에 필요한 에셋(이미지, 오디오 등)을 저장하는 부분입니다.
src 폴더
와 같은 레벨로 생성해주세요
2. 프로젝트 구조 이해
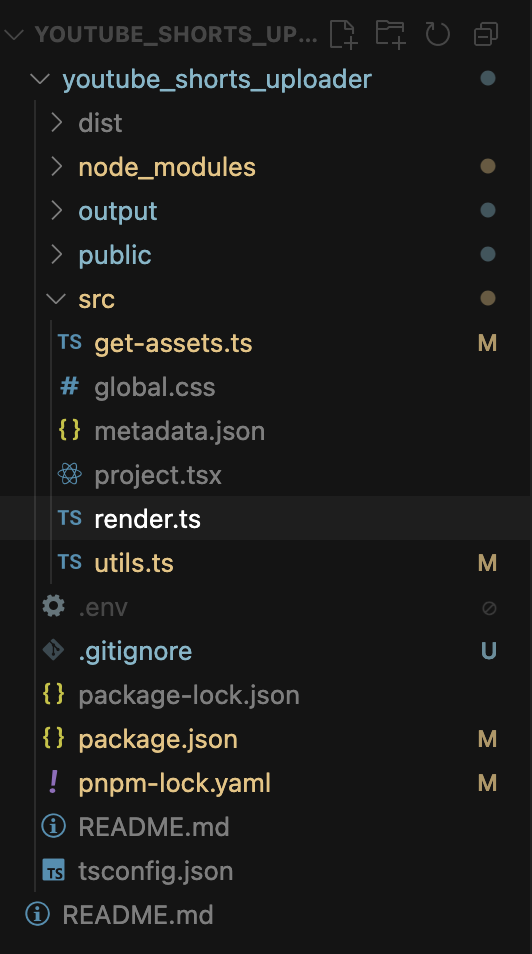
youtube_shorts_uploader/
├── src/
│ ├── get-assets.ts # 이미지/스크립트/오디오 생성 관련 유틸함수 파일
│ ├── global.css # 전체 프로젝트에 적용되는 전역 스타일 파일
│ ├── metadata.json # 에셋 정보 저장 파일
│ ├── project.tsx # 동영상 생성 부분
│ ├── render.ts # 렌더링 관련 함수 & 진입점파일
│ ├── utils.ts # 유틸리티 함수들
│ └── metadata/ # 영상 스크립트 데이터
├── public/ # 정적 파일들
├── output/ # 생성된 영상 출력
├── package.json # 실행 scripts명령어 및 프로젝트 패키지 관리
├── .env # 환경변수 파일
└── .gitignore #3. utils 함수 톺아보기
utils.ts 파일을 들어가보면, import axios from "axios";부분와 아래와 같이 오류가 뜰것입니다.
터미널 창에 아래 명령어를 입력해주세요,
% pnpm add axios
% pnpm install1. 코드 보기
import OpenAI from 'openai/index.mjs';
import axios from "axios";
import * as fs from "fs";
import { createClient } from "@deepgram/sdk";
const deepgram = createClient(process.env["DEEPGRAM_API_KEY"] || "");
const openai = new OpenAI({
apiKey: process.env['OPENAI_API_KEY'],
});
export async function getWordTimestamps(audioFilePath: string){
const {result} = await deepgram.listen.prerecorded.transcribeFile(fs.readFileSync(audioFilePath), {
model: "nova-2",
smart_format: true,
});
if (result) {
return result.results.channels[0].alternatives[0].words;
} else {
throw Error("transcription result is null");
}
}
export async function generateAudio(text: string, voiceName: string, savePath: string) {
const data = {
model_id: "eleven_multilingual_v2",
text: text,
};
const voiceId = await getVoiceByName(voiceName);
const response = await axios.post(`https://api.elevenlabs.io/v1/text-to-speech/${voiceId}`, data, {
headers: {
"Content-Type": "application/json",
"xi-api-key": process.env.ELEVEN_API_KEY || "",
},
responseType: "arraybuffer",
});
fs.writeFileSync(savePath, response.data);
}
async function getVoiceByName(name: string) {
const response = await fetch("https://api.elevenlabs.io/v1/voices", {
method: "GET",
headers: {
"xi-api-key": process.env.ELEVEN_API_KEY || "",
},
});
if (!response.ok) {
throw new Error(`HTTP error! status: ${response.status}`);
}
const data: any = await response.json();
const voice = data.voices.find((voice: {name: string; voice_id: string}) => voice.name === name);
return voice ? voice.voice_id : null;
}
export async function getVideoScript(videoTopic: string) {
const prompt = `Create a script for a youtube short. The script should be around 60 to 80 words long and be an interesting text about the provided topic, and it should start with a catchy headline, something like "Did you know that?" or "This will blow your mind". Remember that this is for a voiceover that should be read, so things like hashtags should not be included. Now write the script for the following topic: "${videoTopic}". Now return the script and nothing else, also no meta-information - ONLY THE VOICEOVER.`;
const chatCompletion = await openai.chat.completions.create({
messages: [{ role: 'user', content: prompt }],
model: 'gpt-4-turbo-preview',
});
const result = chatCompletion.choices[0].message.content;
if (result) {
return result;
} else {
throw Error("returned text is null");
}
}
export async function getImagePromptFromScript(script: string) {
const prompt = `My goal is to create a Youtube Short based on the following script. To create a background image for the video, I am using a text-to-video AI model. Please write a short (not longer than a single sentence), suitable prompt for such a model based on this script: ${script}.\n\nNow return the prompt and nothing else.`;
const chatCompletion = await openai.chat.completions.create({
messages: [{ role: 'user', content: prompt }],
model: 'gpt-4-turbo-preview',
temperature: 1.0 // high temperature for "creativeness"
});
const result = chatCompletion.choices[0].message.content;
if (result) {
return result;
} else {
throw Error("returned text is null");
}
}
export async function dalleGenerate(prompt: string, savePath: string) {
const response = await openai.images.generate({
model: "dall-e-3",
prompt: prompt,
size: "1024x1792",
quality: "standard",
n: 1,
});
if (!response.data || !response.data[0]) {
throw new Error("No image generated");
}
const url = response.data[0].url;
const responseImage = await axios.get(url || "", {
responseType: "arraybuffer",
});
const buffer = Buffer.from(responseImage.data, "binary");
try {
await fs.promises.writeFile(savePath, buffer);
} catch (error) {
console.error("Error saving the file:", error);
throw error; // Rethrow the error so it can be handled by the caller
}
}아래는 utils.ts의 주요 함수별 설명입니다.
getWordTimestamps(audioFilePath: string)
- 오디오 파일을 받아서, Deepgram API로 음성 인식(자막) 결과의 단어별 타임스탬프를 반환합니다.
- 반환값: 각 단어의 시작/끝 시간 정보 배열
오디오 파일에서 단어별 시간 정보를 추출합니다.
generateAudio(text: string, voiceName: string, savePath: string)
- 텍스트와 목소리 이름을 받아, ElevenLabs API로 음성 파일을 생성하고 지정한 경로에 저장합니다.
- 내부적으로 getVoiceByName을 호출해 voiceName에 맞는 voiceId를 찾습니다.
텍스트를 AI 목소리로 변환해 오디오 파일로 저장합니다.
getVoiceByName(name: string)
- ElevenLabs API에서 등록된 목소리 목록을 받아와, 이름이 일치하는 voiceId를 반환합니다.
- 일치하는 목소리가 없으면 null 반환
원하는 목소리 이름에 맞는 voiceId를 찾아줍니다.
getVideoScript(videoTopic: string)
- 주제를 받아, OpenAI GPT-4 API로 유튜브 쇼츠용 흥미로운 스크립트를 생성합니다.
- 60~80단어, 캐치프레이즈로 시작, 해시태그/메타정보 없이 순수 대본만 반환
주제에 맞는 유튜브 쇼츠 대본을 AI로 생성합니다.
getImagePromptFromScript(script: string)
- 스크립트를 받아, 해당 내용에 어울리는 AI 이미지 생성 프롬프트(한 문장)를 OpenAI GPT-4로 생성합니다.
- 반환값: 텍스트-투-이미지 모델에 적합한 짧은 프롬프트
대본에 어울리는 AI 이미지 프롬프트를 만들어줍니다.
dalleGenerate(prompt: string, savePath: string)
- 프롬프트를 받아, OpenAI DALL·E 3로 이미지를 생성하고 지정한 경로에 저장합니다.
- 이미지 생성 실패 시 에러 발생
프롬프트로 AI 이미지를 만들고 파일로 저장합니다.
2. 코드 수정
utils.ts 파일 첫줄에 아래 코드를 추가주세요.
.env 파일의 환경변수 값들을 불러오는 코드입니다.
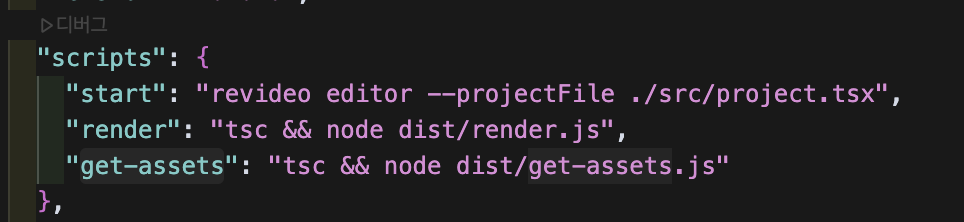
require('dotenv').config();package.json파일의 "scripts"에 아래 명령어를 추가하세요.
"get-assets": "tsc && node dist/get-assets.js"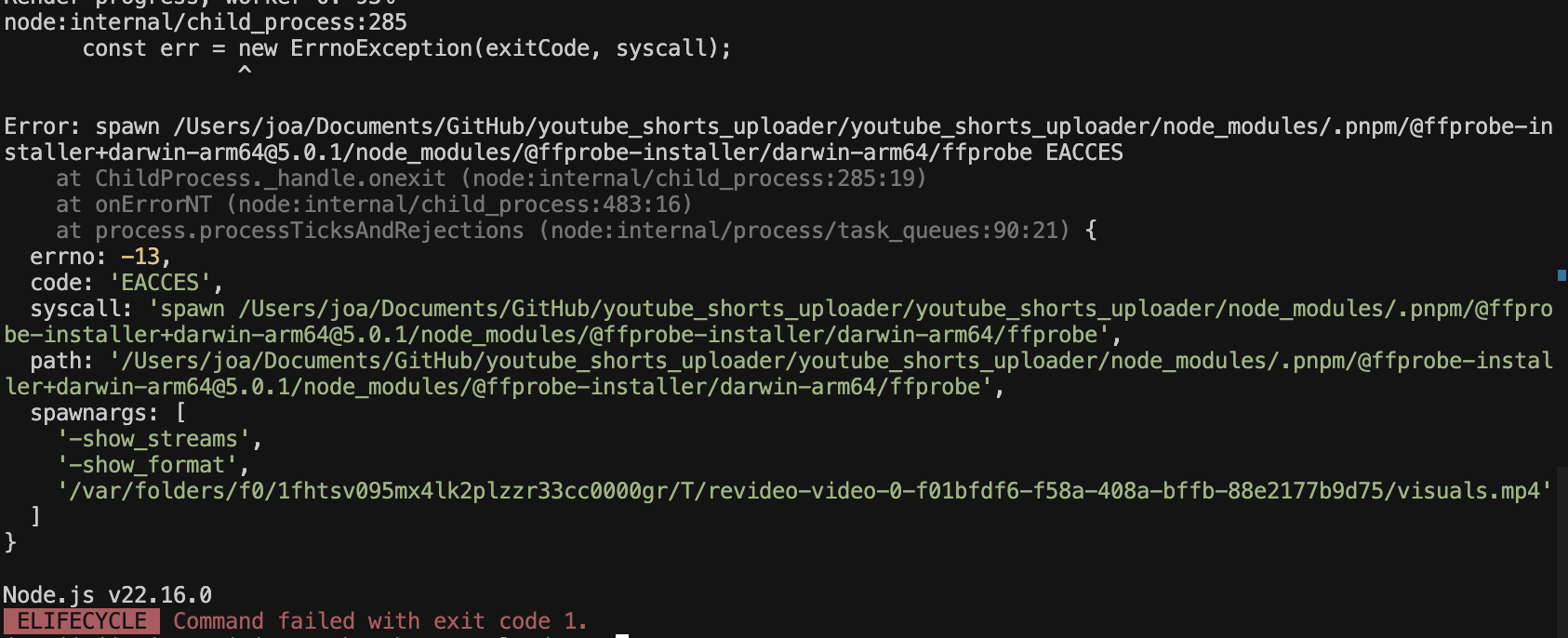
get-assets.ts 파일에서, 최하단 줄 createAssets함수에 원하는 토픽 / 목소리 넣기
createAssets("월식 일식", "Sarah") // topic, voice_name실행 명령어
% pnpm run get-assets #어셋 생성. public 폴더에서 확인가능생성된 오디오/이미지/메타데이터
생성된 메타데이터 파일의 내용을 복사해서, src/metadata.json 파일에 붙여 넣습니다.
이후 영상 생성 명령어를 쳐줍니다.
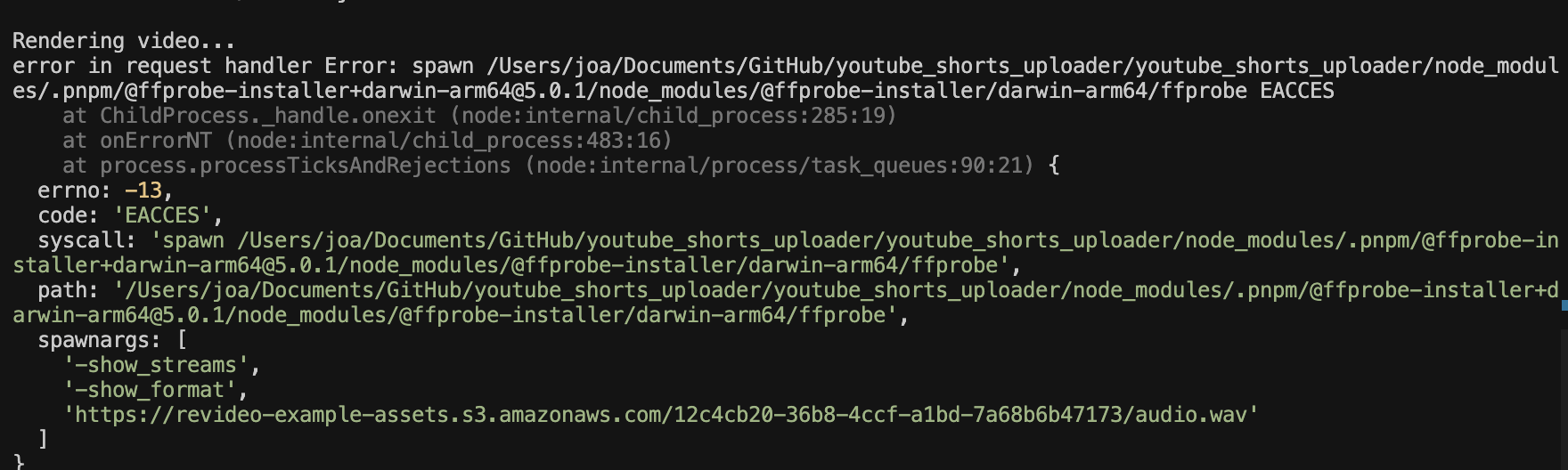
% pnpm run render #영상 생성. output 폴더에서 확인가능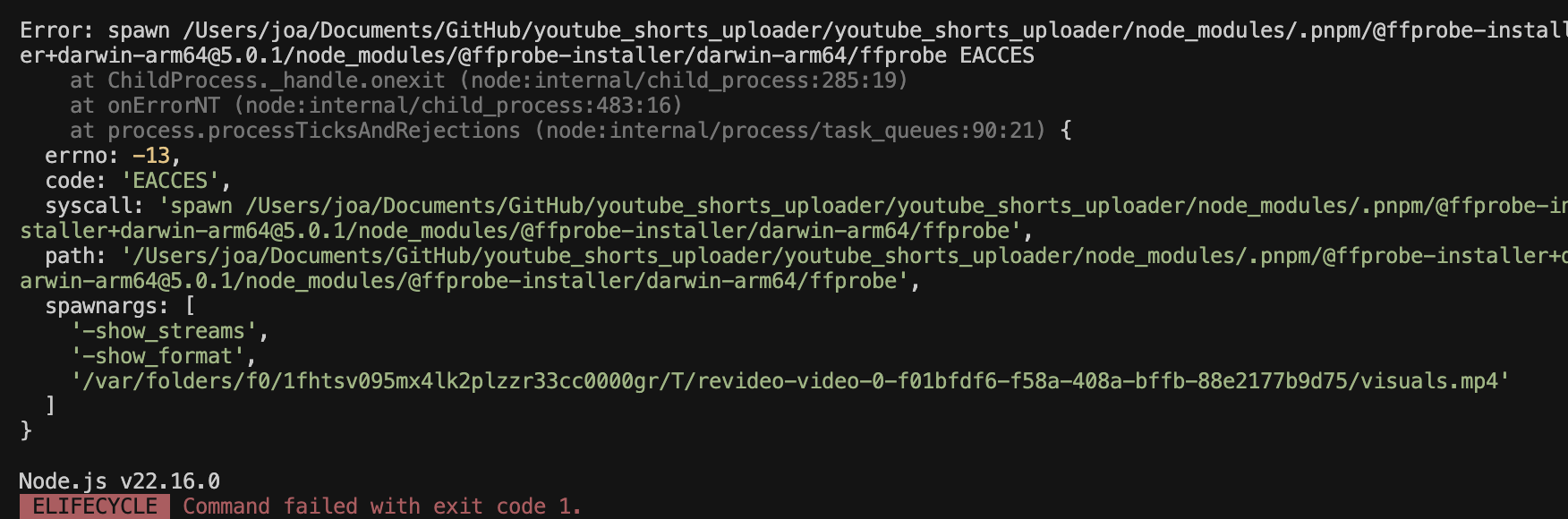
run render 실행중 위와 같은 오류가 뜬다면, ffprobe 실행 파일에 실행 권한이 없어서 발생하는 것이므로, 터미널에 아래 명령어를 입력해 실행 권한을 부여해주세요.
% chmod +x [프로젝트 경로]/node_modules/.pnpm/@ffprobe-installer+darwin-arm64@5.0.1/node_modules/@ffprobe-installer/darwin-arm64/ffprobe프로젝트 경로 모르겠으면, 최상단 폴더(youtube_shorts_uploader)에 가서 우클릭 > 경로복사
이후 다시, pnpm run render 사용시, output 폴더에 새로 생성된 video.mp4 파일을 확인할 수 있습니다.
오늘은 기존 리비디오 유튜브 숏츠 템블릿을 활용해, 새로운 영상을 제작해봤는데요,
다음 시간에는 영상을 숏츠 비율로 바꾸는 방법, 자막의 색 바꾸기, 스크립트 한국어로 바꾸기 등을 통해 우리가 원하는 숏츠 형태의 영상이 생성되도록 코드를 수정해보겠습니다.
