안녕하세요, 저번 시간에 revideo 기본 세팅에 이어, 오늘은 생성되는 동영상을 보다 숏츠 동영상처럼 만들기 위해 project.tsx 파일을 수정해보겠습니다.
src/project.tsx 파일은 생성될 영상의 구조, 내용, 스타일을 정의합니다.
이 파일은 최종 영상에 어떤 이미지, 오디오, 텍스트, 효과가 등장하는지, 그리고 이들이 시간에 따라 어떻게 애니메이션되거나 표시되는지를 제어합니다.
함수 설명
- scene: 영상의 주요 장면을 설정하는 함수입니다. 이미지, 오디오, 자막을 배치하고, 이들의 타이밍과 레이아웃을 제어.
- displayImages: 영상에 여러 이미지를 순서대로 보여주며, 각 이미지를 일정 시간 동안 표시.
- displayWords: 자막 단어의 표시와 애니메이션을 담당, 현재 단어 강조, 스트리밍 텍스트 등 다양한 효과를 처리.
- highlightCurrentWord: 자막에서 현재 말하고 있는 단어를 강조, 해당 시간 동안 색상과 배경을 변경.
이 파일을 수정하면 레이아웃, 자막, 전환 효과, 영상의 전반적인 스타일을 바꿀 수 있습니다.
요약하면, src/project.tsx는 생성되는 영상의 모든 시각적·음향적 요소를 결정하는 메인 스크립트입니다.
1. 영상 비율 변경(가로 영상 -> 세로 영상)
project.tsx 기존코드
//생략
//가장 아랫부분
/**
* The final revideo project
*/
export default makeProject({
scenes: [scene],
variables: metadata,
settings: {
shared: {
size: {x: 1920, y: 1080},
},
},
});
project.tsx 수정코드
//생략
//가장 아랫부분
/**
* The final revideo project
*/
export default makeProject({
scenes: [scene],
variables: metadata,
settings: {
shared: {
size: {x: 1080, y: 1920}, //숏폼 비율로 변경
},
},
});
2. 자막 위치 및 현재 단어 색상 변경
youtube-shrots 예시 코드에서는 자막이 중앙에 뜨고, 현재 단어(오디오 재생중인 단어)의 강조색이 민트색 글씨에 빨간바탕입니다. 그치만 이건 너무 눈아프고, 보통 우리가 보는 숏츠는 자막이 하단에 뜨므로, 수정해보겠습니다.
project.tsx 코드
import {Audio, Img, makeScene2D, Txt, Rect, Layout} from '@revideo/2d';
import {all, createRef, waitFor, useScene, Reference, createSignal, makeProject} from '@revideo/core';
import metadata from './metadata.json';
import './global.css';
interface Word {
punctuated_word: string;
start: number;
end: number;
}
interface captionSettings {
fontSize: number;
textColor: string;
fontWeight: number;
fontFamily: string;
numSimultaneousWords: number;
stream: boolean;
textAlign: "center" | "left";
textBoxWidthInPercent: number;
borderColor?: string;
borderWidth?: number;
currentWordColor?: string;
currentWordBackgroundColor?: string;
shadowColor?: string;
shadowBlur?: number;
fadeInAnimation?: boolean;
}
const textSettings: captionSettings = {
fontSize: 80, // 자막 글자 크기
numSimultaneousWords: 3, // 동시에 표시할 최대 단어 수
textColor: "white", // 자막 기본 글자 색상
fontWeight: 800, // 자막 글자 두께
fontFamily: "Mulish", // 자막 글꼴
stream: false, // true면 단어가 하나씩 순차적으로 나타남
textAlign: "center", // 자막 정렬(가운데 정렬)
textBoxWidthInPercent: 70, // 자막 박스의 너비(비율)
fadeInAnimation: true, // 자막이 서서히 나타나는 애니메이션 사용 여부
//📌 수정된 코드
currentWordColor: "orange", // 현재 단어 강조 색상
currentWordBackgroundColor: "", // 현재 단어 배경 강조 색상
shadowColor: "black", // 자막 그림자 색상
shadowBlur: 30 // 자막 그림자 번짐 정도
}
/**
* The Revideo scene
*/
const scene = makeScene2D('scene', function* (view) {
const images = useScene().variables.get('images', [])();
const audioUrl = useScene().variables.get('audioUrl', 'none')();
const words = useScene().variables.get('words', [])();
const duration = words[words.length-1].end + 0.5;
const headerRef = createRef<Layout>();
const imageContainer = createRef<Layout>();
const textContainer = createRef<Layout>();
yield view.add(
<>
{/* 📌 수정된 코드 */}
{/* 메인 레이아웃 */}
<Layout
layout
size={["100%", "100%"]}
direction={"column"}
gap={0}
padding={0}
justifyContent={"start"}
alignItems={"stretch"}
>
{/* 헤더 영역 - 25% */}
<Layout
layout
ref={headerRef}
size={["100%", "25%"]}
padding={0}
justifyContent={"center"}
alignItems={"center"}
>
</Layout>
{/* 본문 영역 - 55% */}
<Layout
layout
ref={imageContainer}
size={["100%", "55%"]}
padding={0}
justifyContent={"center"}
alignItems={"center"}
>
</Layout>
{/* 푸터 영역 - 20% */}
<Layout
layout
ref={textContainer}
size={["100%", "20%"]}
padding={0}
justifyContent={"center"}
alignItems={"center"}
>
</Layout>
{/* 하단 여백 - 10% */}
<Layout
layout
size={["100%", "10%"]}
padding={0}
>
</Layout>
</Layout>
<Audio
src={audioUrl}
play={true}
/>
<Audio
src={"https://revideo-example-assets.s3.amazonaws.com/chill-beat-2.mp3"}
play={true}
volume={0.1}
/>
</>
);
// 📌 수정된 코드
// 헤더에 텍스트 추가 (예시)
headerRef().add(
<Txt
fontSize={60} // 헤더 글자 크기
fontWeight={700} // 헤더 글자 두께
fill="white" // 헤더 글자 색상
textAlign="center" // 가운데 정렬
>
숏츠 제목 //📌이 곳에 원하는 숏츠 제목 입력
</Txt>
);
yield* all(
displayImages(imageContainer, images, duration),
displayWords(
textContainer,
words,
textSettings
)
)
});
function* displayImages(container: Reference<Layout>, images: string[], totalDuration: number){
for(const img of images){
const ref = createRef<Img>();
container().add(<Img
src={img}
size={["100%", "100%"]}
ref={ref}
zIndex={0}
/>
)
yield* waitFor(totalDuration/images.length);
}
}
function* displayWords(container: Reference<Layout>, words: Word[], settings: captionSettings){
let waitBefore = words[0].start;
for (let i = 0; i < words.length; i += settings.numSimultaneousWords) {
const currentBatch = words.slice(i, i + settings.numSimultaneousWords);
const nextClipStart =
i < words.length - 1 ? words[i + settings.numSimultaneousWords]?.start || null : null;
const isLastClip = i + settings.numSimultaneousWords >= words.length;
const waitAfter = isLastClip ? 1 : 0;
const textRef = createRef<Txt>();
yield* waitFor(waitBefore);
if(settings.stream){
let nextWordStart = 0;
yield container().add(<Txt width={`${settings.textBoxWidthInPercent}%`} textWrap={true} zIndex={2} textAlign={settings.textAlign} ref={textRef}/>);
for(let j = 0; j < currentBatch.length; j++){
const word = currentBatch[j];
yield* waitFor(nextWordStart);
const optionalSpace = j === currentBatch.length-1? "" : " ";
const backgroundRef = createRef<Rect>();
const wordRef = createRef<Txt>();
const opacitySignal = createSignal(settings.fadeInAnimation ? 0.5 : 1);
textRef().add(
<Txt
fontSize={settings.fontSize}
fontWeight={settings.fontWeight}
fontFamily={settings.fontFamily}
textWrap={true}
textAlign={settings.textAlign}
fill={settings.currentWordColor}
ref={wordRef}
lineWidth={settings.borderWidth}
shadowBlur={settings.shadowBlur}
shadowColor={settings.shadowColor}
zIndex={2}
stroke={settings.borderColor}
opacity={opacitySignal}
>
{word.punctuated_word}
</Txt>
);
textRef().add(<Txt fontSize={settings.fontSize}>{optionalSpace}</Txt>);
// 텍스트가 완전히 렌더링된 후 배경 추가
yield;
container().add(<Rect fill={settings.currentWordBackgroundColor} zIndex={1} size={wordRef().size} position={wordRef().position} radius={10} padding={10} ref={backgroundRef} />);
yield* all(waitFor(word.end-word.start), opacitySignal(1, Math.min((word.end-word.start)*0.5, 0.1)));
wordRef().fill(settings.textColor);
backgroundRef().remove();
nextWordStart = currentBatch[j+1]?.start - word.end || 0;
}
textRef().remove();
} else {
yield container().add(<Txt width={`${settings.textBoxWidthInPercent}%`} textAlign={settings.textAlign} ref={textRef} textWrap={true} zIndex={2}/>);
const wordRefs = [];
const opacitySignal = createSignal(settings.fadeInAnimation ? 0.5 : 1);
for(let j = 0; j < currentBatch.length; j++){
const word = currentBatch[j];
const optionalSpace = j === currentBatch.length-1? "" : " ";
const wordRef = createRef<Txt>();
textRef().add(
<Txt
fontSize={settings.fontSize}
fontWeight={settings.fontWeight}
ref={wordRef}
fontFamily={settings.fontFamily}
textWrap={true}
textAlign={settings.textAlign}
fill={settings.textColor}
zIndex={2}
stroke={settings.borderColor}
lineWidth={settings.borderWidth}
shadowBlur={settings.shadowBlur}
shadowColor={settings.shadowColor}
opacity={opacitySignal}
>
{word.punctuated_word}
</Txt>
);
textRef().add(<Txt fontSize={settings.fontSize}>{optionalSpace}</Txt>);
// we have to yield once to await the first word being aligned correctly
if(j===0 && i === 0){
yield;
}
wordRefs.push(wordRef);
}
yield* all(
opacitySignal(1, Math.min(0.1, (currentBatch[0].end-currentBatch[0].start)*0.5)),
highlightCurrentWordSequentially(container, currentBatch, wordRefs, settings.currentWordColor, settings.currentWordBackgroundColor),
waitFor(currentBatch[currentBatch.length-1].end - currentBatch[0].start + waitAfter),
);
textRef().remove();
}
waitBefore = nextClipStart !== null ? nextClipStart - currentBatch[currentBatch.length-1].end : 0;
}
}
function* highlightCurrentWordSequentially(container: Reference<Layout>, currentBatch: Word[], wordRefs: Reference<Txt>[], wordColor: string, backgroundColor: string){
let nextWordStart = 0;
for(let i = 0; i < currentBatch.length; i++){
yield* waitFor(nextWordStart);
const word = currentBatch[i];
const originalColor = wordRefs[i]().fill();
nextWordStart = currentBatch[i+1]?.start - word.end || 0;
wordRefs[i]().text(wordRefs[i]().text());
wordRefs[i]().fill(wordColor);
const backgroundRef = createRef<Rect>();
if(backgroundColor){
// 텍스트가 완전히 렌더링된 후 배경 추가
yield;
container().add(<Rect fill={backgroundColor} zIndex={1} size={wordRefs[i]().size} position={wordRefs[i]().position} radius={10} padding={10} ref={backgroundRef} />);
}
yield* waitFor(word.end-word.start);
wordRefs[i]().text(wordRefs[i]().text());
wordRefs[i]().fill(originalColor);
if(backgroundColor){
backgroundRef().remove();
}
}
}
/**
* The final revideo project
*/
export default makeProject({
scenes: [scene],
variables: metadata,
settings: {
shared: {
size: {x: 1080, y: 1920},
},
},
});
3. 스크립트 한국어로 바꾸기
3-1. 스크립트 프롬프트 수정하기
스크립트를 한국어로 바꿀려면 utils.ts 파일에서 gpt에게 스크립트를 만들어 달라고 하는 코드를 수정해야합니다.
기존코드
export async function getVideoScript(videoTopic: string) {
const prompt = `Create a script for a youtube short. The script should be around 60 to 80 words long and be an interesting text about the provided topic, and it should start with a catchy headline, something like "Did you know that?" or "This will blow your mind". Remember that this is for a voiceover that should be read, so things like hashtags should not be included. Now write the script for the following topic: "${videoTopic}". Now return the script and nothing else, also no meta-information - ONLY THE VOICEOVER.`;
const chatCompletion = await openai.chat.completions.create({
messages: [{ role: 'user', content: prompt }],
model: 'gpt-4-turbo-preview',
});
const result = chatCompletion.choices[0].message.content;
if (result) {
return result;
} else {
throw Error("returned text is null");
}
}여기에서 prompt를 다음과 같이 바꿔주세요.
당신은 유튜브 숏츠 대본 작가입니다. 유튜브 쇼츠용 스크립트를 한국어로 작성해주세요.
말하는 형식의 보이스오버에 맞춰 자연스럽고 흥미롭게 작성하고, 스크립트의 길이는 반드시 60~80단어 사이로 작성해주세요.
제공된 주제에 대한 흥미로운 내용이어야 합니다. 매력적인 헤드라인으로 시작해주세요. 이것은 음성으로 읽힐 것이므로 해시태그 같은 것은 포함하지 마세요. 다음 주제로 스크립트를 작성해주세요: "${videoTopic}". 스크립트만 반환하고 다른 설명은 하지 마세요 - 오직 음성용 대본만 작성해주세요.
3-2. 한국어 보이스로 바꾸기
elevenlabs에서 한국어를 지원하는 보이스를 선택하여야 합니다.
먼저, 사용가능한 모든 보이스를 보는 명령어입니다. 터미널 창에 입력하세요.
curl -H "xi-api-key: $ELEVEN_API_KEY" https://api.elevenlabs.io/v1/voices | jq '.voices[].name'또는 jq가 없다면:
curl -H "xi-api-key: $ELEVEN_API_KEY" https://api.elevenlabs.io/v1/voices이렇게 하면 사용 가능한 모든 보이스 이름이 출력됩니다.
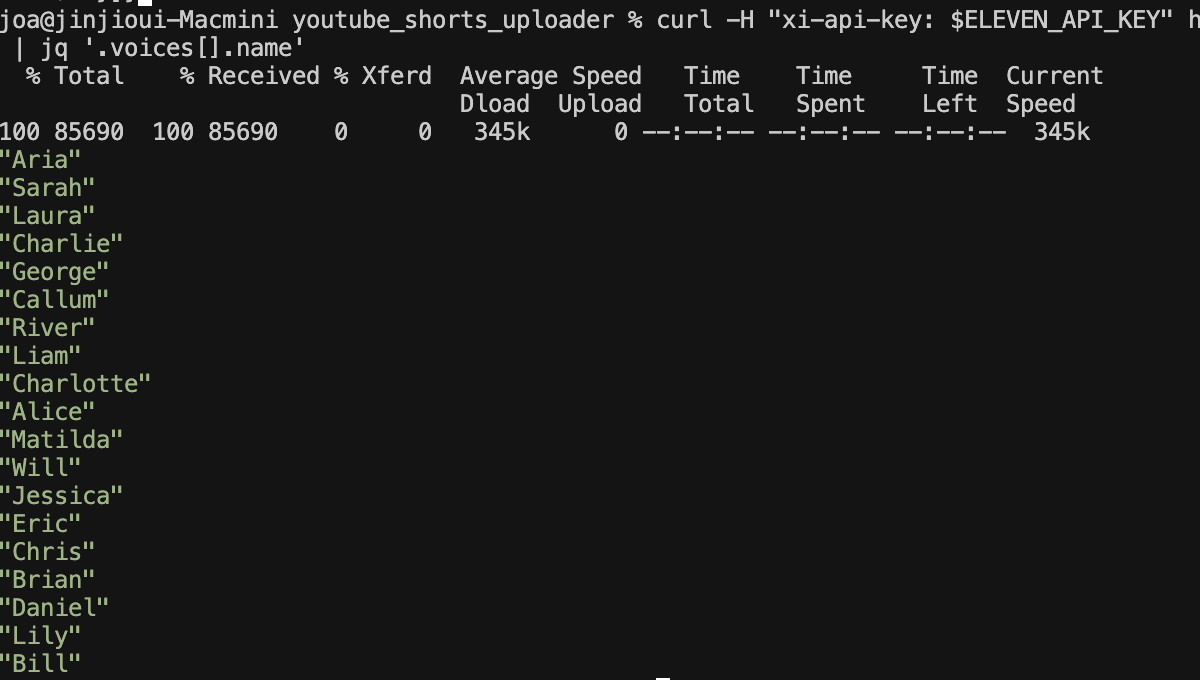
사용 가능한 한국어 전용 보이스를 찾는 명령어
curl -H "xi-api-key: $ELEVEN_API_KEY" https://api.elevenlabs.io/v1/voices | jq '.voices[] | select(.labels.language == "ko" or .labels.language == "korean" or .labels.language == "ko-KR" or .labels.language == "multilingual") | {name: .name, language: .labels.language}'사용가능한 한국어 보이스 목록 출력

한국어 보이스 목록을 확인했다면, get-assets.ts파일로 이동하세요.
import { getVideoScript, generateAudio, getWordTimestamps, dalleGenerate, getImagePromptFromScript } from './utils';
import { v4 as uuidv4 } from 'uuid';
import * as fs from 'fs';
async function createAssets(topic: string, voiceName: string){
const jobId = uuidv4();
console.log("Generating assets...")
const script = await getVideoScript(topic);
console.log("script", script);
await generateAudio(script, voiceName, `./public/${jobId}-audio.wav`);
const words = await getWordTimestamps(`./public/${jobId}-audio.wav`);
console.log("Generating images...")
const imagePromises = Array.from({ length: 5 }).map(async (_, index) => {
const imagePrompt = await getImagePromptFromScript(script);
await dalleGenerate(imagePrompt, `./public/${jobId}-image-${index}.png`);
return `/${jobId}-image-${index}.png`;
});
const imageFileNames = await Promise.all(imagePromises);
const metadata = {
audioUrl: `${jobId}-audio.wav`,
images: imageFileNames,
words: words
};
await fs.promises.writeFile(`./public/${jobId}-metadata.json`, JSON.stringify(metadata, null, 2));
// 📌 해당 코드 추가. metadata를 업데이트함.
await fs.promises.writeFile(`./src/metadata.json`, JSON.stringify(metadata, null, 2));
}
createAssets("월식과 일식에 대한 과학적인 설명", "Bin") // 📌 해당 부분에 사용가능한 한국어 보이스 입력⚠️ 만약, 아래와 같이 나오면 현재 사용가능한 한국어 보이스가 없는것입니다.

이 경우, 일레븐 랩스 홈페이지에 접속해 보이스를 추가해줍니다.
3-3. 일레븐 랩스 보이스 추가하기
- 일레븐 랩스 홈페이지에 접속하기
- 왼쪽 탭에서
Voices메뉴 선택 > 검색창 우측에 필터 버튼 클릭
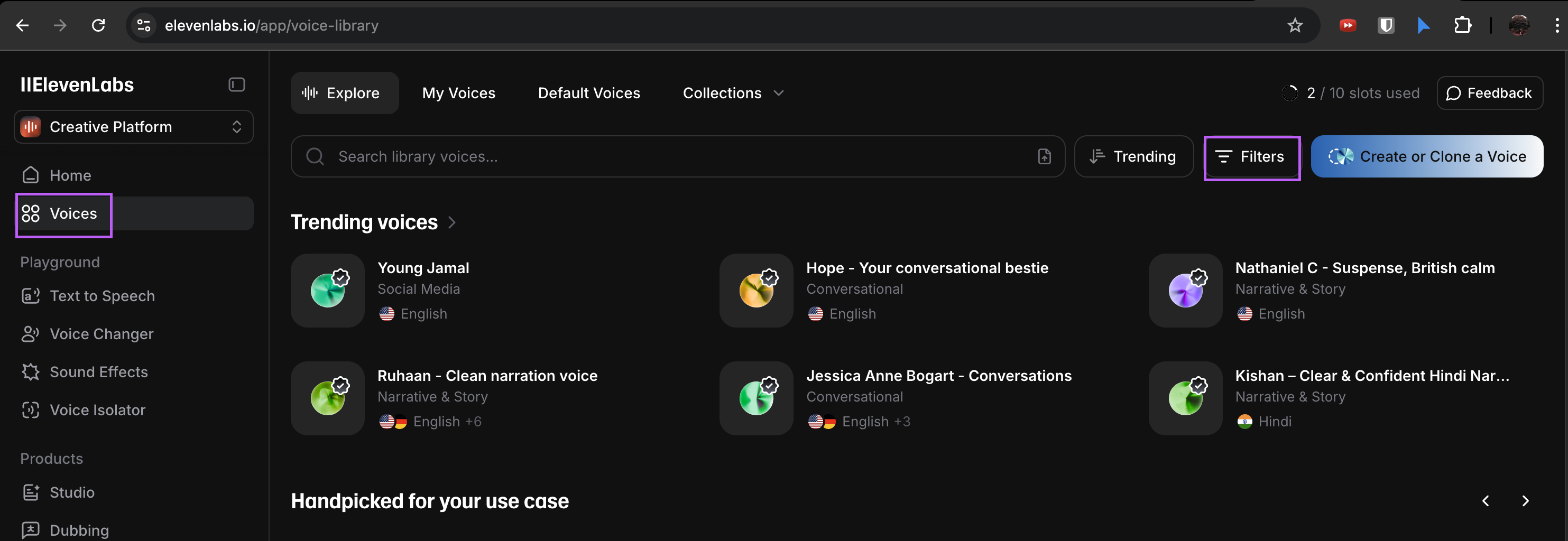
- 언어 - 한국어, 악센트 - Any 또는 Standard 선택 후 필터 적용
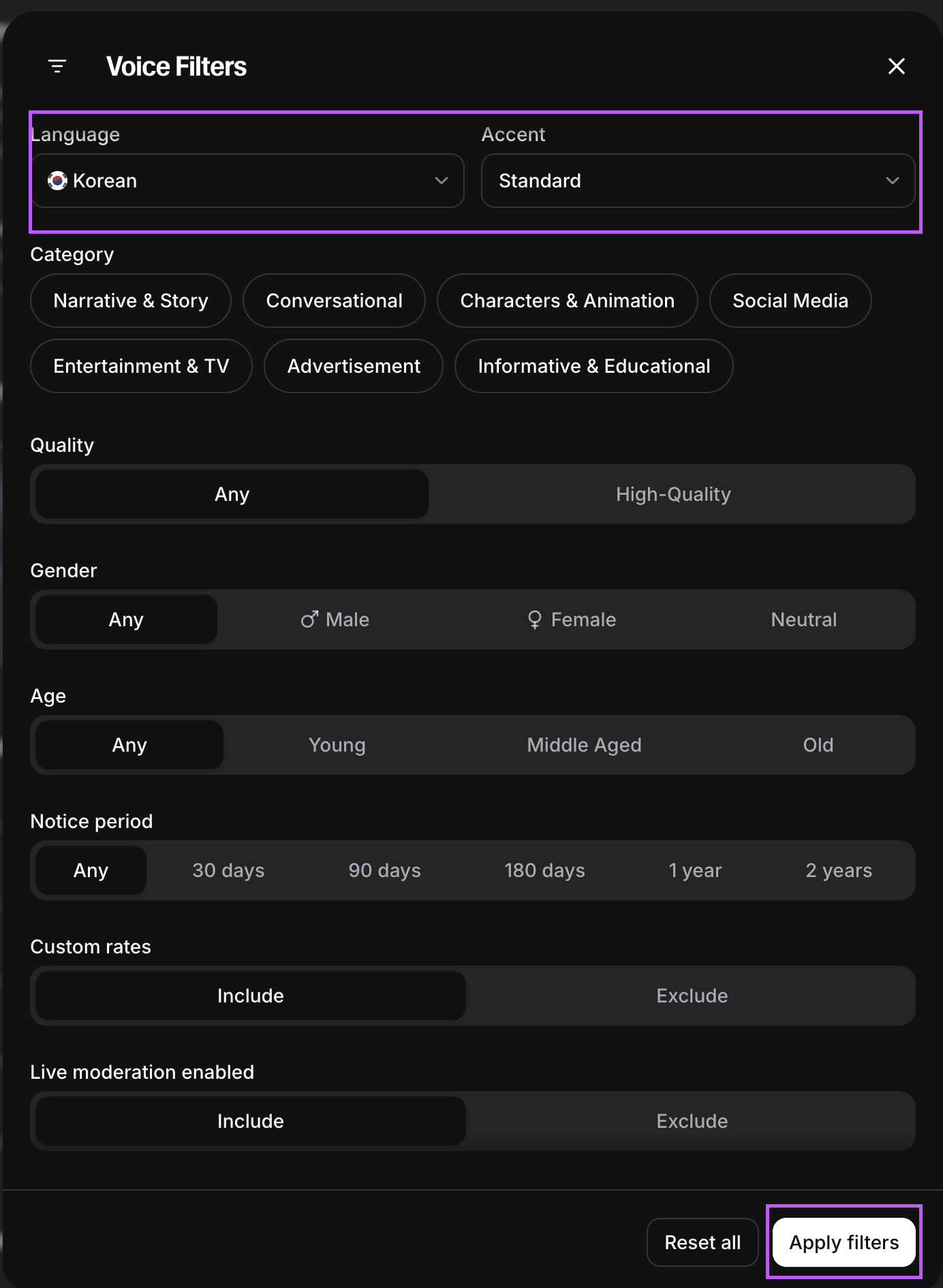
- 검색된 보이스 중, 원하는 목소리를 add해 주세요.
- 추가된 보이스는 상단탭
My Voices에서 확인할 수 있습니다.
이제 다시 3-2 과정으로 돌아가 수행해 주세요.
🍯 팁)
3-3 과정 수행 후에도, 여전히 사용가능한 한국어 보이스가 뜨지않는다면, 환경변수가 로드되지 않았을 가능성이 있습니다.
아래 명령어로 API 키를 확인하고, 확인되지않는 경우, .env 파일을 다시 로드해주세요.
% echo $ELEVEN_API_KEY #API 키 확인
#결과가 비었다면 환경변수가 적용되지 않은것 입니다.
#아래 명령어 또는 직접 .env 파일을 확인해 ELEVEN_API_KEY가 있는지 확인하세요. 없다면 입력하세요.
% cat .env
% source .env #환경변수 로드
% echo $ELEVEN_API_KEY #이번엔 제대로 된 키값이 나올 것 입니다.3-4. 타임스탬프 추출 함수 수정
이제 다시 utils.ts파일로 이동해, 타임스탬프 추출 함수를 수정해야합니다.
getWordTimestamps함수 : 오디오 파일을 받아서, Deepgram API로 음성 인식(자막) 결과의 단어별 타임스탬프를 반환함.
export async function getWordTimestamps(audioFilePath: string){
const {result} = await deepgram.listen.prerecorded.transcribeFile(fs.readFileSync(audioFilePath), {
model: "nova-2",
language: "ko", // 📌 추가된 줄. 한국어 오디오 파일을 읽습니다.
smart_format: true,
});
if (result) {
return result.results.channels[0].alternatives[0].words;
} else {
throw Error("transcription result is null");
}
}3-5. 재실행
youtube_shorts_uploader % pnpm run get-assets #오디오,메타데이터, 이미지 재생성
> youtube_shorts_uploader@0.0.0 get-assets /Users/Documents/GitHub/youtube_shorts_uploader/youtube_shorts_uploader
> tsc && node dist/get-assets.js
Generating assets...
script "하늘의 신비, 월식과 일식! 여러분이 꼭 알아야 할 놀라운 사실들을 준비했어요. 월식은 달이 지구의 그림자에 가려지는 현상입니다. 가끔 달이 붉게 변하는 걸 보셨나요? 그건 바로 ‘혈월’이랍니다. 반면, 일식은 달이 태양과 지구 사이에 위치해 태양의 빛을 막아 일부 혹은 전부를 가리는 현상이에요. 완벽한 일식을 보면 주변이 잠시 어두워져, 마치 짧은 밤이 찾아온 것 같죠. 두 현상 모두 우주의 경이로움을 느낄 수 있는 멋진 기회랍니다. 다음 번 월식이나 일식이 언제인지 확인하고, 이 우주의 신비를 직접 경험해 보세요!"
Generating images...
youtube_shorts_uploader % pnpm run render
> youtube_shorts_uploader@0.0.0 render /Users/Documents/GitHub/youtube_shorts_uploader/youtube_shorts_uploader
> tsc && node dist/render.js
Rendering video...
Worker 0: JSHandle:finished downloading
Worker 0: JSHandle@object
Render progress, worker 0: 8%
Render progress, worker 0: 18%
Render progress, worker 0: 27%
Render progress, worker 0: 36%
Render progress, worker 0: 46%
Render progress, worker 0: 56%
Render progress, worker 0: 66%
Render progress, worker 0: 75%
Render progress, worker 0: 83%
Render progress, worker 0: 93%
Render progress, worker 0: 100%
Rendered video to output/video.mp4결과물


안녕하세요, 글 잘 보았습니다! 한번 따라해보려고 하는데, npm run render 실행 시에
"Render attempt 1 failed: Navigating frame was detached" 에러가 발생합니다.ㅠ
이 에러가 혹시 사용하는 라이브러리나 Puppeteer 버전 문제에서 발생하는 것 같은데 위 소스 버전정보나.. 참고할만한 Git Repo가 있을까요?