
(무거운 + 크론 작업 = 시시포스)
0. 배경
사내 프로젝트에서는 뉴스를 주로 공급하고 있습니다.
그리고 반복적으로 등장하는 인기 뉴스를 효율적으로 제공하기 위해 Cloudfront를 사용하고 있습니다.
그런데!!
기획 변경이 생겨 뉴스 읽음 표시 작업이 추가되었습니다.
기존에 API 응답은 {인기 뉴스 1, 인기 뉴스 2, ... }와 같은 형태였다면,
이제는 {인기 뉴스 1(읽음), 인기 뉴스 2(읽지 않음), ...}로 수정해야 합니다.

그러니까 이제는 Cloudfront로 처리할 수 없다.
Cloudfront는 서버와 클라이언트 사이에 서서 캐싱된 요청을 반환해버리기 때문에.
이름하야 동적 캐싱!
(제가 만든 단어입니다.
면접 혹은 이력서에 남용할 경우 책임지지 않을 거에요 ~.~)
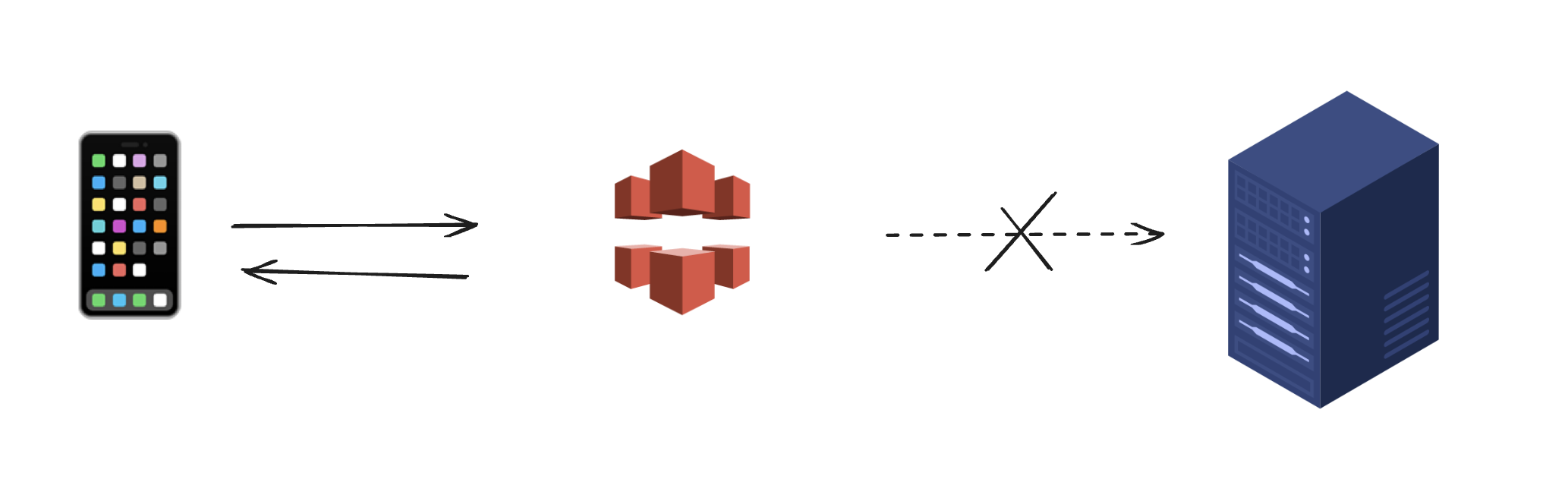
요랬는데~
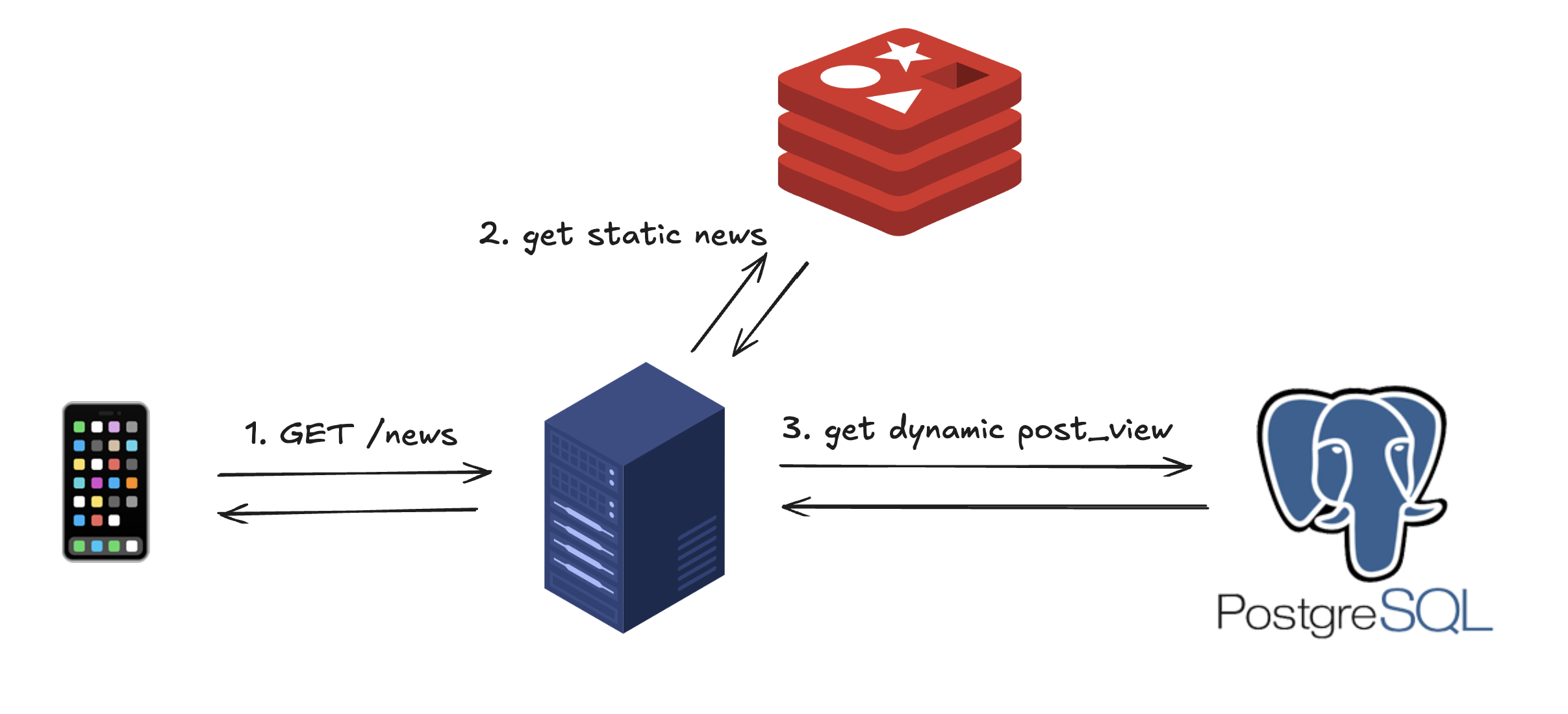
요래됐슴당~
나는 Redis로부터 캐시된 뉴스를 빠르게 읽고,
PostgreSQL DB에서 뉴스 조회 데이터를 가져와 합쳐 반환할 것이다.
1. 캐싱
이제 누가 캐싱해주냐
사용자 요청이 왔을 때 캐시를 살펴보고, 없을 경우 반환과 동시에 캐싱한다.
좋은 방법이다.
어떻게 보면 캐싱을 가장 정석적으로 사용하는 방법같아 보인다.
그런데 상부의 명령이 떨어졌다.
단 한 명의 사용자도 UX를 해치지 않기 위해 미리 캐싱해두고 시간 단위로 옮겨서 조회하자.
그래서 사용자가 요청하기 이전에 한발 앞서 뉴스가 캐싱되어 있어야 했다.
그러기 위해서는 API 요청과 별개로 캐싱 작업이 이뤄져야 했다.
2. cron ver.1
처음에는 NestJS에서 공식적으로 지원하는 @Cron을 사용했다.
@Cron("* * * * *")
async cache() {
cosnt now = addMinutes(new Date, 1)
const daily: News[] = await this.findDaily()
const weekly: News[] = await this.findWeekly()
...
await this.cache('daily' + now, daily)
await this.cache('weekly' + now, weekly)
...
}대략 이런 느낌으로 작성했다.
DB에서 매일, 매주 등의 간격 속에서 인기 뉴스를 조회하고 캐싱한다.
항목별로 키 값을 다르게 주고 있다.
그리고 미리 캐싱해야 하기 때문에 현재 시각보다 1분 뒤의 타임스탬프를 찍어 넣는다는 점에 주의하자.
그런데!!
서버가 여러대라면?
서버는 각자의 @Cron 메서드를 가지고 있다.
그러면 여러 번의 캐싱이 발생하고,
이러한 중복을 방지하는 것이 새로운 과제가 되었다.

3. cron ver.2
현재 우리 웹 서버는 Elastic Beanstalk을 활용하고 있다.
Beanstalk은 EC2를 오토 스케일링하는 데도 유리하고,
롤링 배포와 같은 배포 과정을 아주 간단하게 선언적으로 구현할 수도 있다.
아무튼, Elastic Beanstalk에서는 worker environment를 지원한다.
워커 환경이란, 웹 서버와 같이 클라이언트로부터 HTTP 요청을 받아 처리하는 서버가 아닌
이미지 프로세싱, 이메일 전송과 같이 시간이 오래 걸리는 작업을 따로 진행해주는 서버를 뜻한다.
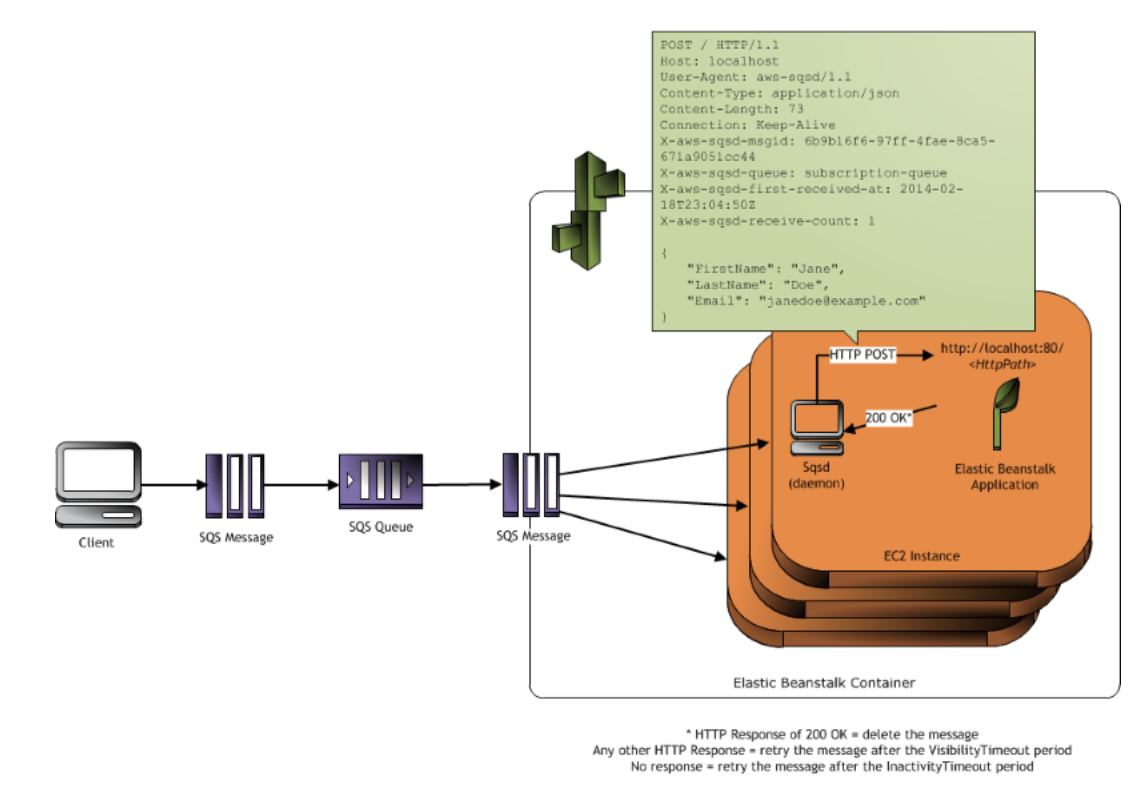
그리고 작업 요청은 SQS를 통해 전달받는다.
워커 환경의 서버에 AWS가 SQS 데몬(SQSD)을 깔아주기 때문에 우리는 어떤 URI를 통해 요청을 받을지만 약속해주면 된다.
게다가 200 응답을 주기만 하면
SQSD가 자동으로 큐의 메시지를 제거해준다는 점도 특징이다.
자, 그러면 하나씩 톺아보자.
Elastic Beanstalk 워커 환경 생성
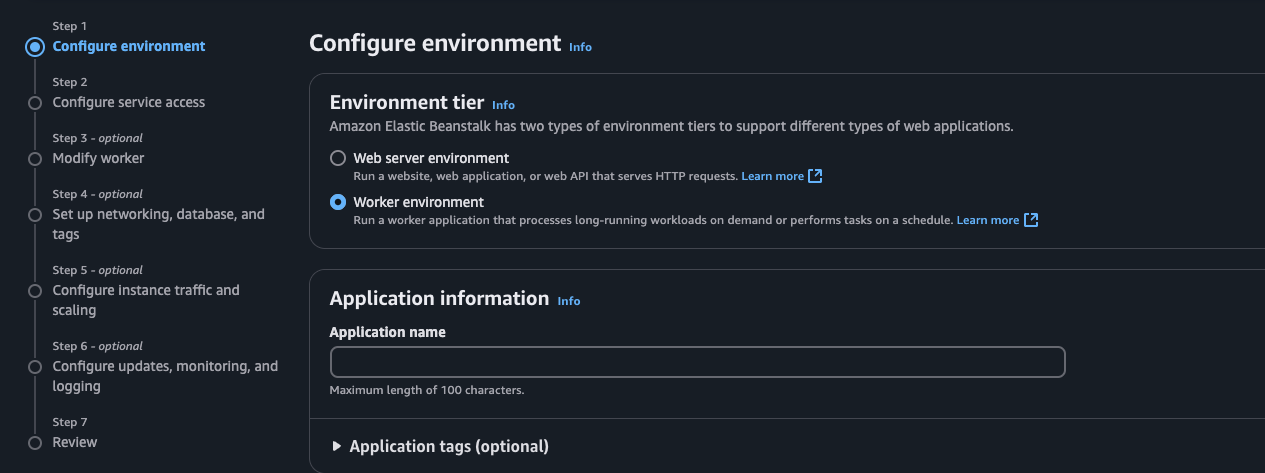
일단 워커 환경을 꼭 설정해야 한다.
웹 서버 환경에서는 SQSD가 제대로 작동하지 못한다.
애플리케이션 이름과 환경 이름은 막 지어도 된다.
플랫폼은 실행할 애플리케이션마다 다르겠지만, 나는 Node.js 18 / Amazon Linux 2를 선택했다.
애플리케이션 코드는 Sample Application,
프리셋은 기본값을 활용했다.

서비스 접근 설정은 프로젝트의 경우에는 큰 문제가 되지 않겠으나,
회사에서 활용할 경우 만들어둔 IAM role을 선택하면 된다.
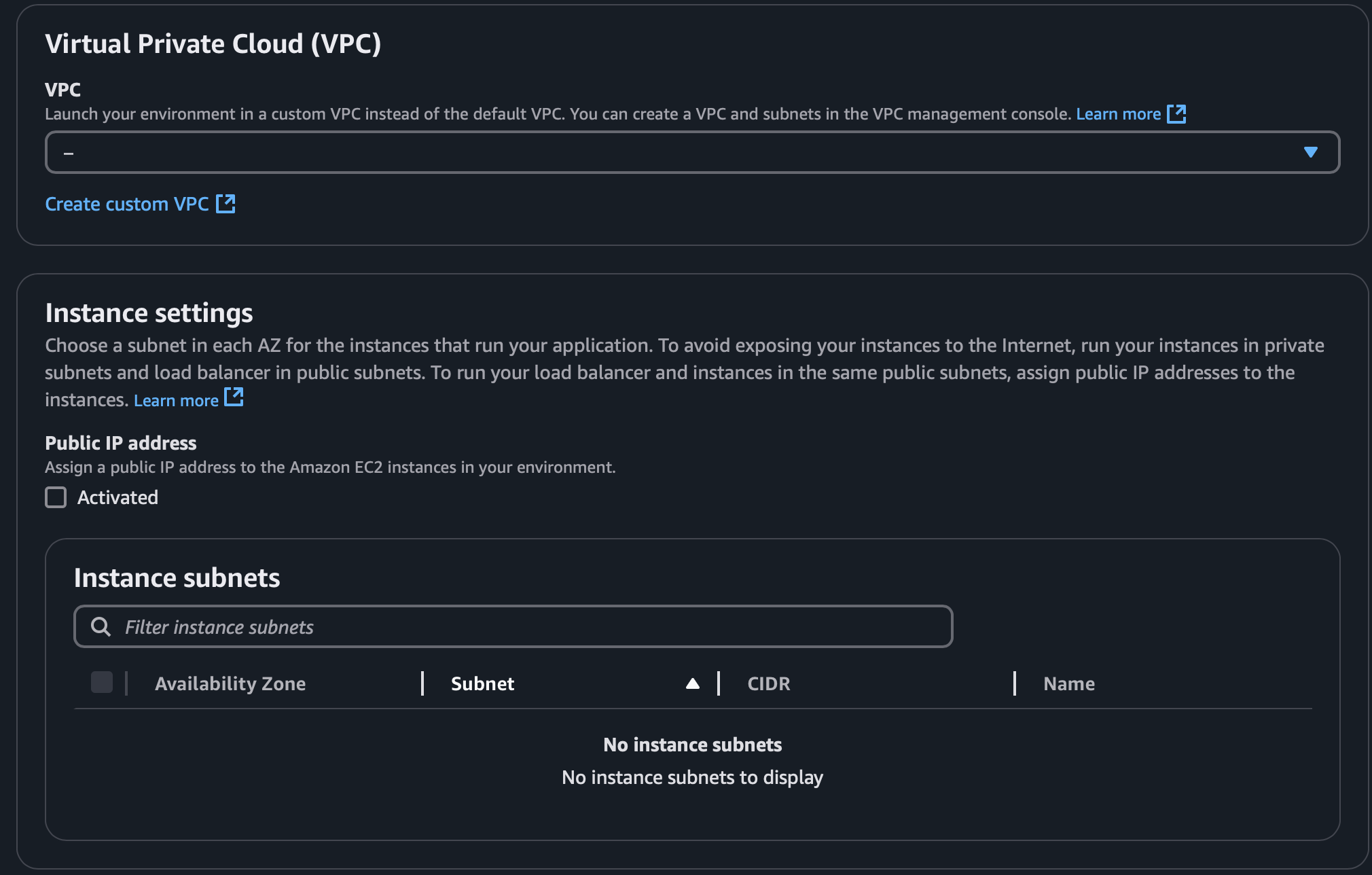
Step 3인 네트워크, 데이터베이스, 태그를 고르는 곳이다.
VPC를 사용하고 있다면 기존의 VPC를 선택하면 되고,
서브넷의 경우엔 private을 선택하는 것을 추천한다.
(어차피 우린 스스로 이벤트를 발생시켜서 처리하는 워커 환경을 생성하고 있으므로)
데이터베이스나 태그는 따로 설정하지 않았다.
어쨌거나 Step 2 ~ 5는 optional한 항목이므로
개인 프로젝트를 수행하는 수준이면 건너뛰거나 기본값으로 두는 경우가 많을 것이다.
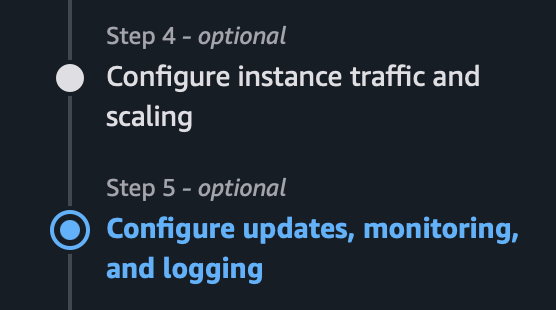
Step 4, 5도 마찬가지로 필요한 것만 골라서 활용하면 된다.
4번은 ec2 인스턴스의 스펙, 보안 그룹 등을 정하고
5번은 배포 방식, 로깅 등을 다룬다.
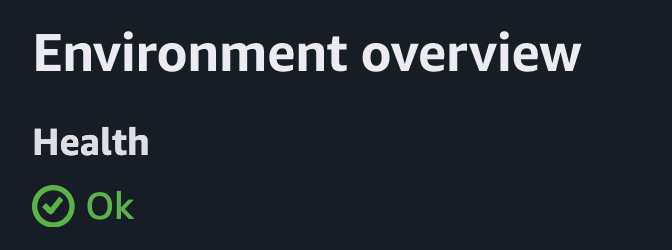
배포가 완료되면 위와 같이 Health: Ok 사인을 얻게 된다.
4. CodeBuild
이제 CodeBuild를 통해 소스코드를 빌드해야 한다.
CodeBuild에 관한 배포 사항은 이글을 참고하길 바란다.
여기서 중요한 건 npm run dev와 같이 웹서버 전체를 실행하는 명령어를 사용하지 않고,
캐싱을 진행하는 워커 모듈만 실행하도록 해야 한다는 것이다.
{
"scripts": {
"start:worker": "node dist/worker.js",
}
}그래서 위와 같이 package.json 파일에 특정 파일을 실행하도록 설정했다.
import { NestFactory } from '@nestjs/core'
import { NestExpressApplication } from '@nestjs/platform-express'
import { WorkerModule } from 'model/worker/worker.module'
async function bootstrap() {
const app = await NestFactory.create<NestExpressApplication>(
WorkerModule,
)
app.enableShutdownHooks()
await app.listen(process.env.PORT)
console.log(`⚙Worker server ready at http://localhost:${process.env.PORT}`)
}
bootstrap()그리고 이와 같이 bootstrap() 함수를 하나 정의해둬서
실행하도록 해야 한다.
phases:
build:
commands:
...
- 'echo "web: npm run start:worker" > Procfile'참고로, Procfile은 애플리케이션 실행 명령어를 저장하는 파일이다.
그래서 echo 명령어를 통해 실행하고자 하는 커맨드를 지정하는 것이다.
그리고 buildspec 파일에서 이와 같이
package.json에서 지정한 명령어를 실행하도록 한다.
5. CodePipeline
CodeBuild와 마찬가지로 CodePipeline은 현재 프로젝트의 상황에 따라 사용할 수밖에 없는 인프라다.
따라서, 현재 본인이 가지고 있는 환경에 맞춰 다른 방식을 사용해도 좋을 것 같다.
나는 CodePipeline을 통해 빌드 단계에서 소스코드를 빌드해서 아티팩트를 생성하고,
그 아티팩트를 배포 단계에서 활용하는 방식을 택했다.
6. issues
이번 작업은 Elastic Beanstalk, SQS, CodeBuild, CodePipeline 등 여러 인프라가 맞물려 가는 데다가
레퍼런스가 많지 않아 적지 않은 이슈를 겪었다...
이글을 읽는 이에게 도움이 될 수 있기를 바라며 하나씩 풀겠다.
1) 환경변수
사실 위에서 적었어야 했는데,
Elastic Beanstalk에서 환경을 생성하면서 애플리케이션을 실행하는 데 필요한 환경변수를 주입해야 한다.

만약 이미 적지 않은 상태라고 한다면,
해당 환경의 configuration 탭으로 이동하여 위 항목을 수정하여 추가해주면 된다.
2) buildspec
buildspec에는 artifacts.files를 명시해야 한다.
다음 배포 단계에서 활용할 파일들을 적어주는 건데,
여기에 cron.yaml을 빼먹을 경우 서버는 돌아가더라도 크론 작업을 진행하지 못한다.
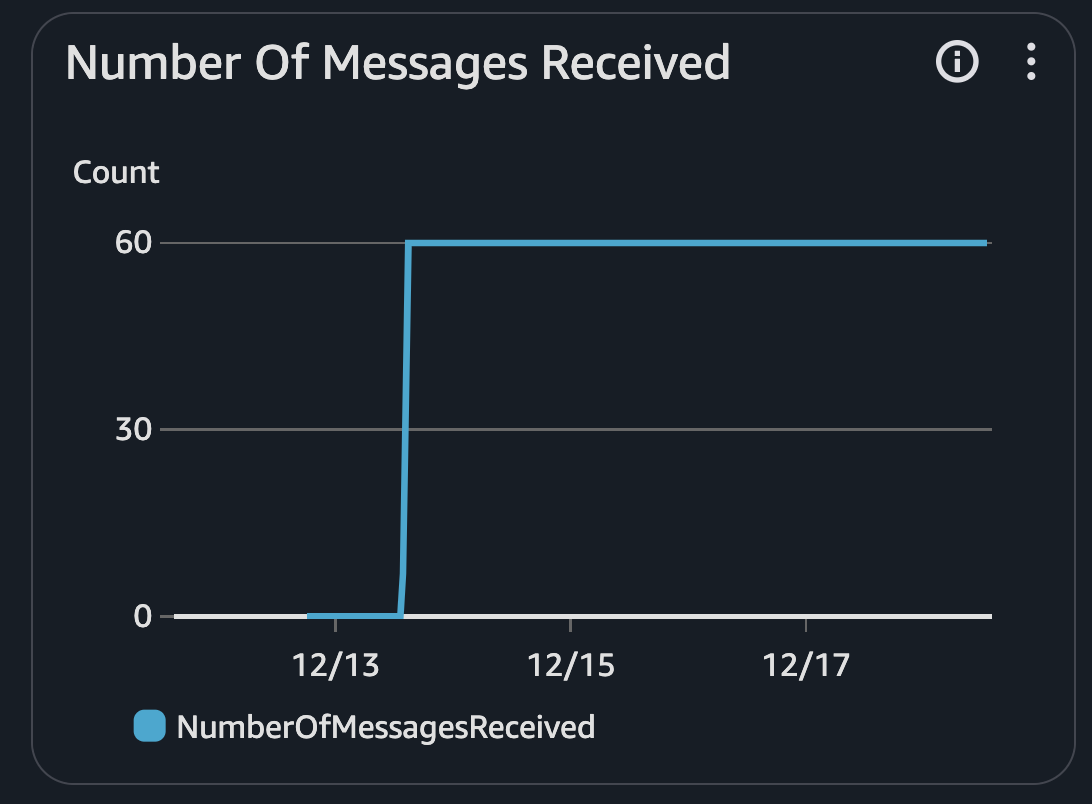
만약 크론 작업이 정상적으로 진행될 경우, SQS 콘솔 내 해당하는 큐의 모니터링 지표를 보면
number of messages received에서 0보다 큰 값이 뜨는 걸 확인할 수 있다.
3) 보안그룹
프로젝트마다 환경이 다르겠지만,
워커 환경에서 RDS를 사용하는 경우 보안그룹을 자세히 살펴봐야 한다.
RDS의 인바운드 그룹에 내 EC2 인스턴스의 보안그룹이 포함되어 있지 않은 경우
서버를 정상적으로 실행하지 못하고 DB에 연결하지 못한다는 로그를 보게될 것이다...
4) Queue
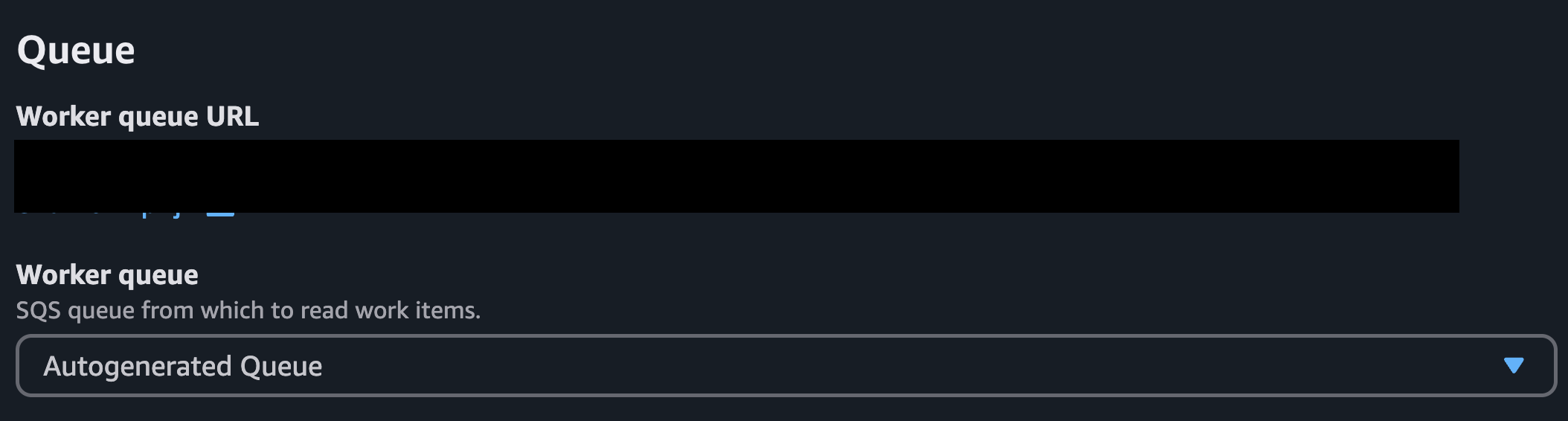
Beanstalk 워커 환경을 생성할 때는 사진과 같이 SQS 큐를 지정해야 한다.

그런데 AWS 문서에 의하면 이미 만들어졌고,
이미 존재하고 FIFO인 큐를 사용할 경우 크론 작업이 불가능하다고 한다.
따라서 그냥 자동으로 생성해주는 큐를 사용하는 것을 추천한다.

(그래서?)
7. 결론
위에서도 밝혔듯 워커 환경은 반복적으로 실행하되
웹 서버에서 요청을 받아 처리하기에는 다소 시간이 걸리고 복잡한 작업을 실행하기에 적합하다.
나의 경우에는 DB에서 조회한 정적 데이터를 캐싱한다는 점에서
이 조건을 충족하는지는 의문이지만 AWS를 사용할 수 있는 한가지 방법을 터득했다는 데 의의를 두겠다.
만약 단순히 웹 서버에서 실행해도 문제는 되지 않지만
서버가 여러 대라 중복으로 실행하는 것을 피하기 위해서는 이 글을 참고하여 Redis 락을 사용해보자.
