
(개발자는 캐시(cache)를 좋아합니다)
0. 배경
이 글에서도 밝혔듯 올해 목표는 DB 엔진 이해하기다.
그래서 그 대상이 되는 PostgreSQL이 캐시를 사용하는 방법에 대해 다루겠다.

보통 cache라 하면 이 친구를 많이 떠올릴 것이다.
그렇지만 캐시는 사실 RDBMS에서도 필수적으로 사용되고 있으며 심지어 OS에서도 사용한다.
오늘은 PostgreSQL에서 캐시를 어떻게 다루는지 살펴볼 것이며
그중에서도 shared buffer에 대해 톺아볼 것이다.
본격적으로 글을 작성하기에 앞서 이 글은 해당 블로그에서 많은 도움을 얻어 작성되었으며
여기 작성된 글의 요약본과 다름없음을 미리 밝힌다.
(또한 이 글에서 등장하는 그림들은 모두 해당 블로그에 출처를 두고 있음도 밝힌다)
1. shared buffer란
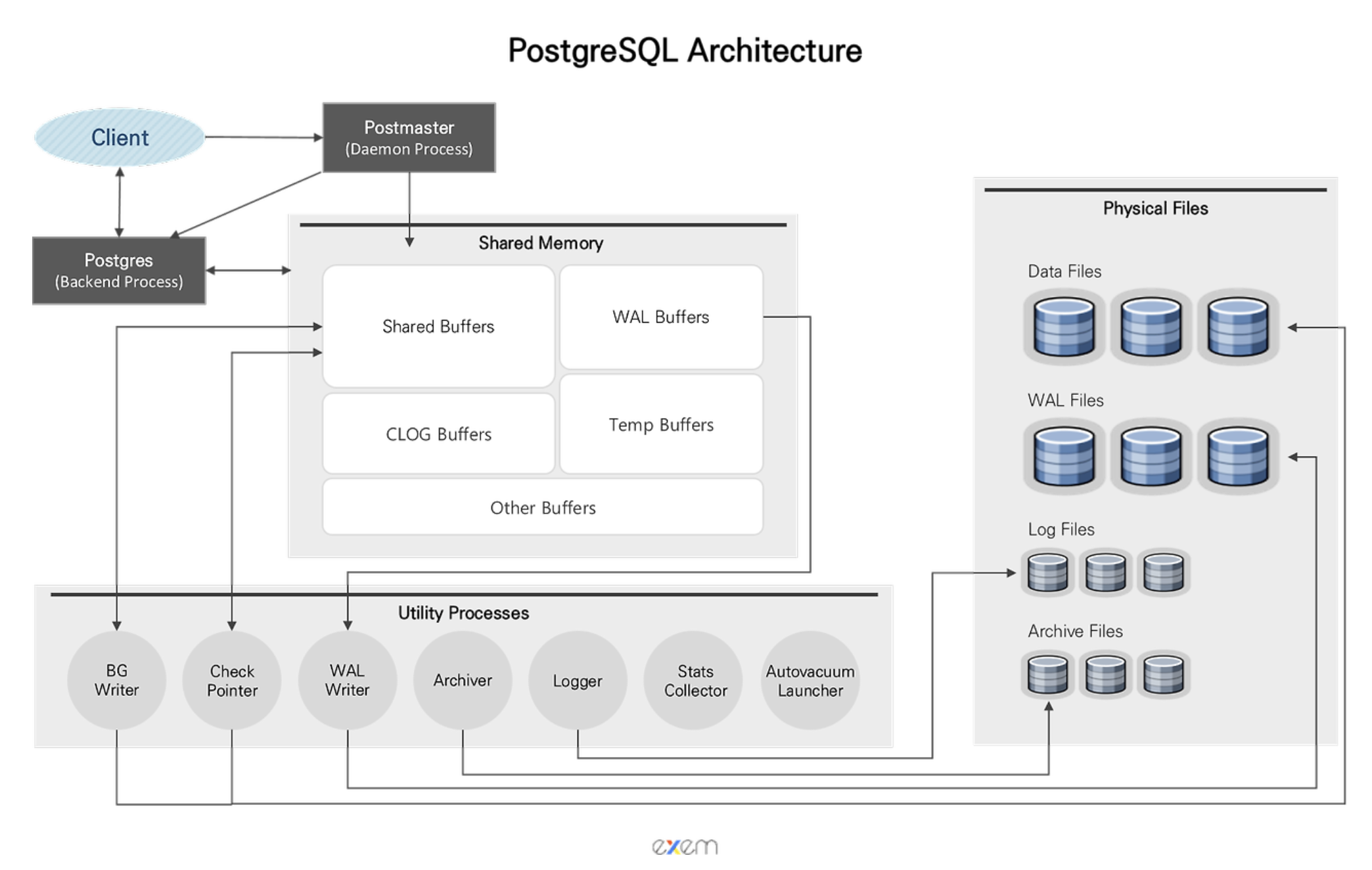
shared buffer는 공용 메모리 공간인 shared memory 영역에 속한 메모리 공간이다.
또한, 공용이기 때문에 shared buffer는 모든 프로세스가 공유한다.
shared buffer 안의 데이터는 페이지 단위로 이뤄져 있으며
프로세스가 디스크 접근을 최소화하기 위해 공용으로 사용한다.
따라서, 여기에는 테이블의 레코드가 저장되어 있기 때문에
자주 호출되는 쿼리에 대해 동일한 응답을 반환하는 데에 사용된다.
(그것이 바로 캐시)
2. shared buffer 설정
방법
shared buffer는 postgresql.conf 파일에서 shared_buffers 파라미터를 통해 설정할 수 있다.
혹은 RDS를 통해 관리하는 경우 파라미터 그룹에서 수정할 수 있다.
설정
기본적으로 32MB로 설정되어 있다.
RDS의 프리티어 인스턴스 클래스인 db.t3.micro가 1GB임을 감안하면 생각보다 적다.
이 문서에서 추천하는 값은 1GB 이상의 메모리를 가진 경우 25%를 할당할 것을 추천한다.
반대로 1GB가 되지 않을 경우 15% 정도가 적절하다고 한다.
⚠️ 주의 ⚠️
다만, 이 값은 다다익선이 아니다.
PostgreSQL에서는 OS 레벨의 캐시도 사용하기 때문에 적절한 정도만 설정하자.
3. postgresql의 읽기 & 쓰기 작업 처리
postgresql이 읽기, 쓰기 작업을 처리하는 방식은 shared buffer와 밀접한 관련을 맺는다.
읽기 작업
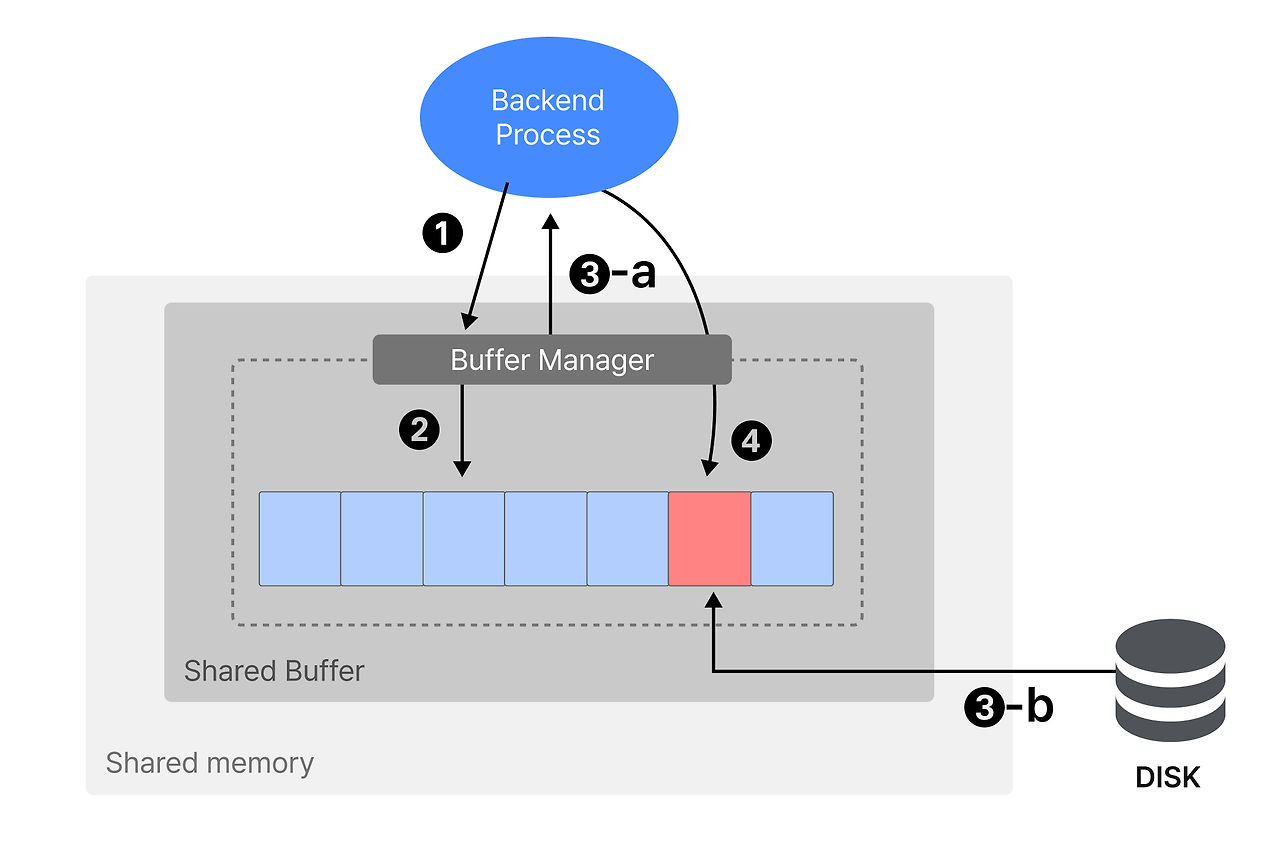
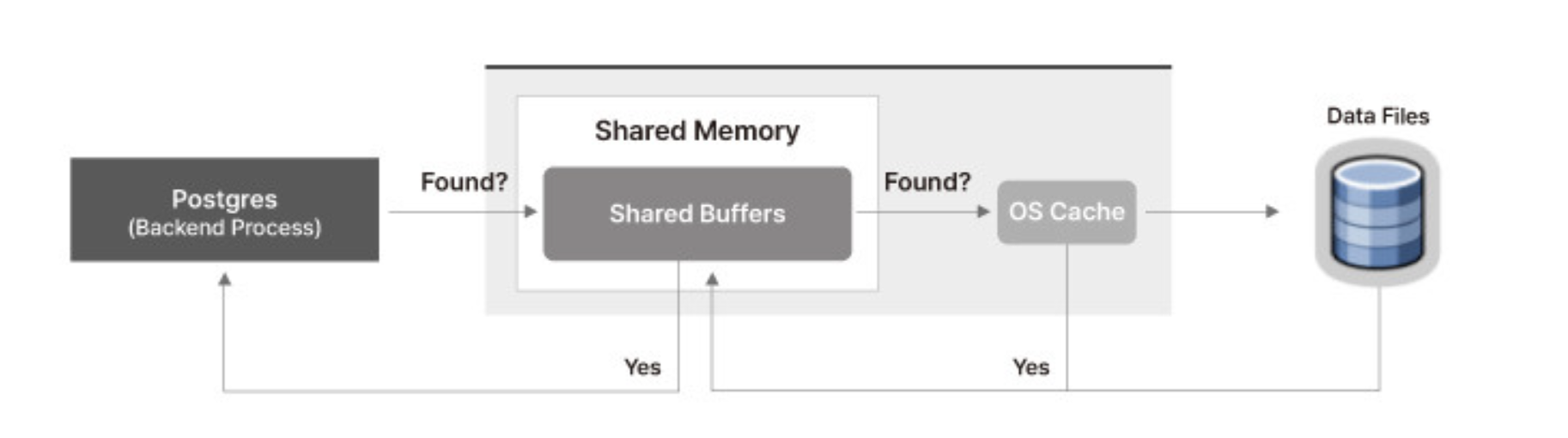
postgresql은 shared buffer를 먼저 찾는다.
이때 shared buffer 내 데이터와 백엔드 프로세스가 원하는 데이터 사이를 매개하기 위해 buffer tag를 사용한다.
buffer tag를 buffer manager에게 전달하면,
해시 함수를 통해 해시 키를 얻고 이를 활용해 해시 테이블에 접근할 수 있게 된다.
(더 자세한 건 밑에서 다룬다)
만약 해시 테이블에 있을 경우 그대로 반환하지만 없을 경우 OS 캐시를 다음으로 찾는다.
OS 캐시는 디스크에서 읽은 파일의 데이터를 저장하기 때문에 접근하게 된다.
(그렇다! DB에서 저장하는 모든 데이터는 결국 파일이다)
그럼에도 불구하고 존재하지 않을 경우, 최후의 보루로 디스크에 접근한다.
(이미 알고 있겠지만 디스크에 접근하는 건 그만큼 비용이 큰 연산이다)
그리고 디스크에서 얻어낸 데이터는 곧바로 백엔드 프로세스로 반환하지 않고
shared buffer에 캐시된 이후에 반환된다.
쓰기 작업
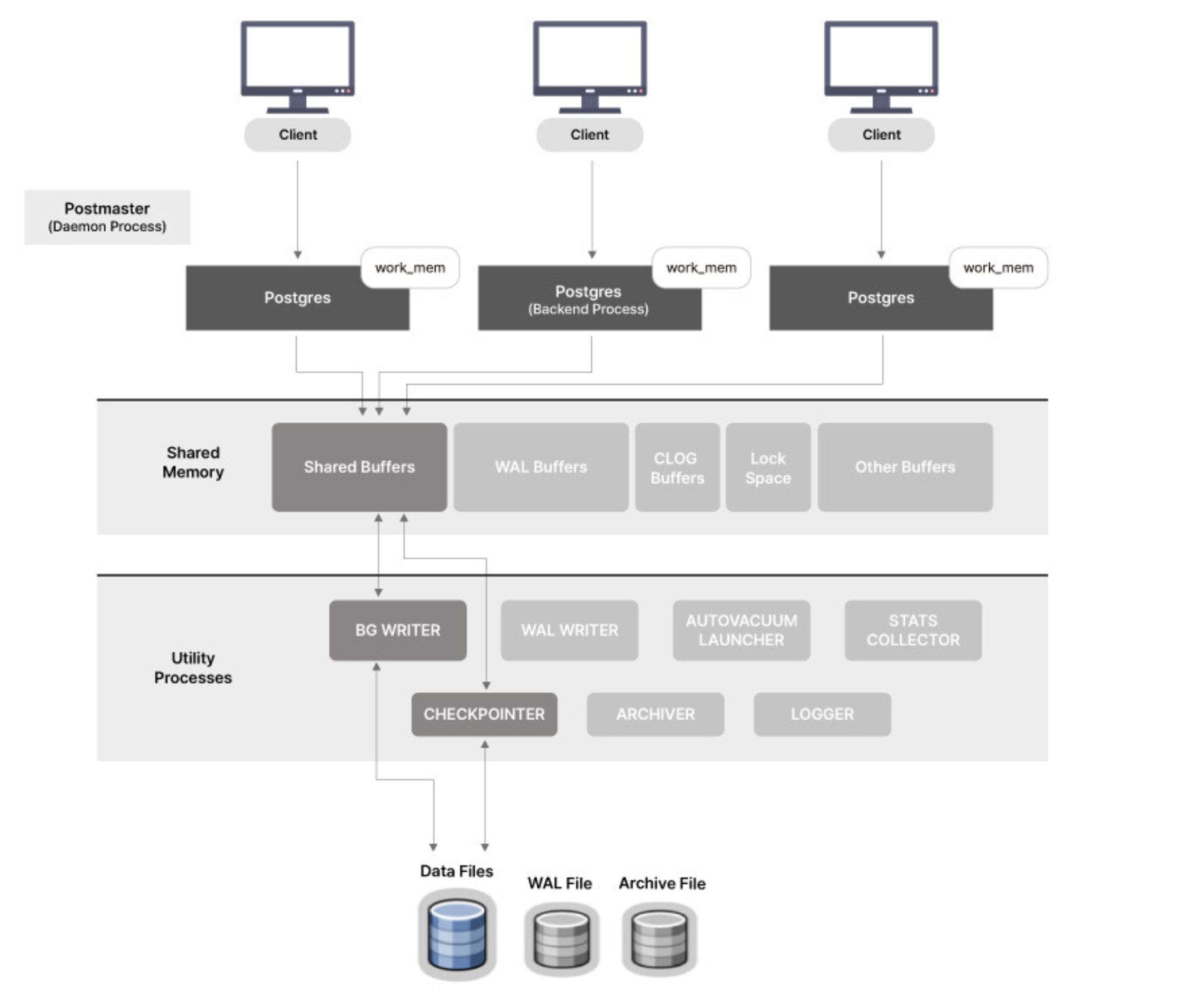
쓰기 작업은 먼저 shared buffer에서 처리된다.
그리고 이처럼 shared buffer에만 쓰인 데이터는 dirty block이라고 칭한다.
이 데이터는 이후 BG writer와 checkpointer에 의해 디스크에 쓰인다.
checkpointer
checkpoint_timeout 파라미터 값만큼 시간이 지났거나 (기본값은 5분)
WAL 파일의 용량이 max_wal_size 파라미터 값을 넘겼을 때 디스크에 쓴다.
BG writer
checkpointer의 부담을 덜기 위해 dirty block의 일부를 정기적으로 디스크에 쓴다.
(그래서인지 background의 준말인 BG가 붙었다)
4. shared buffer의 구조
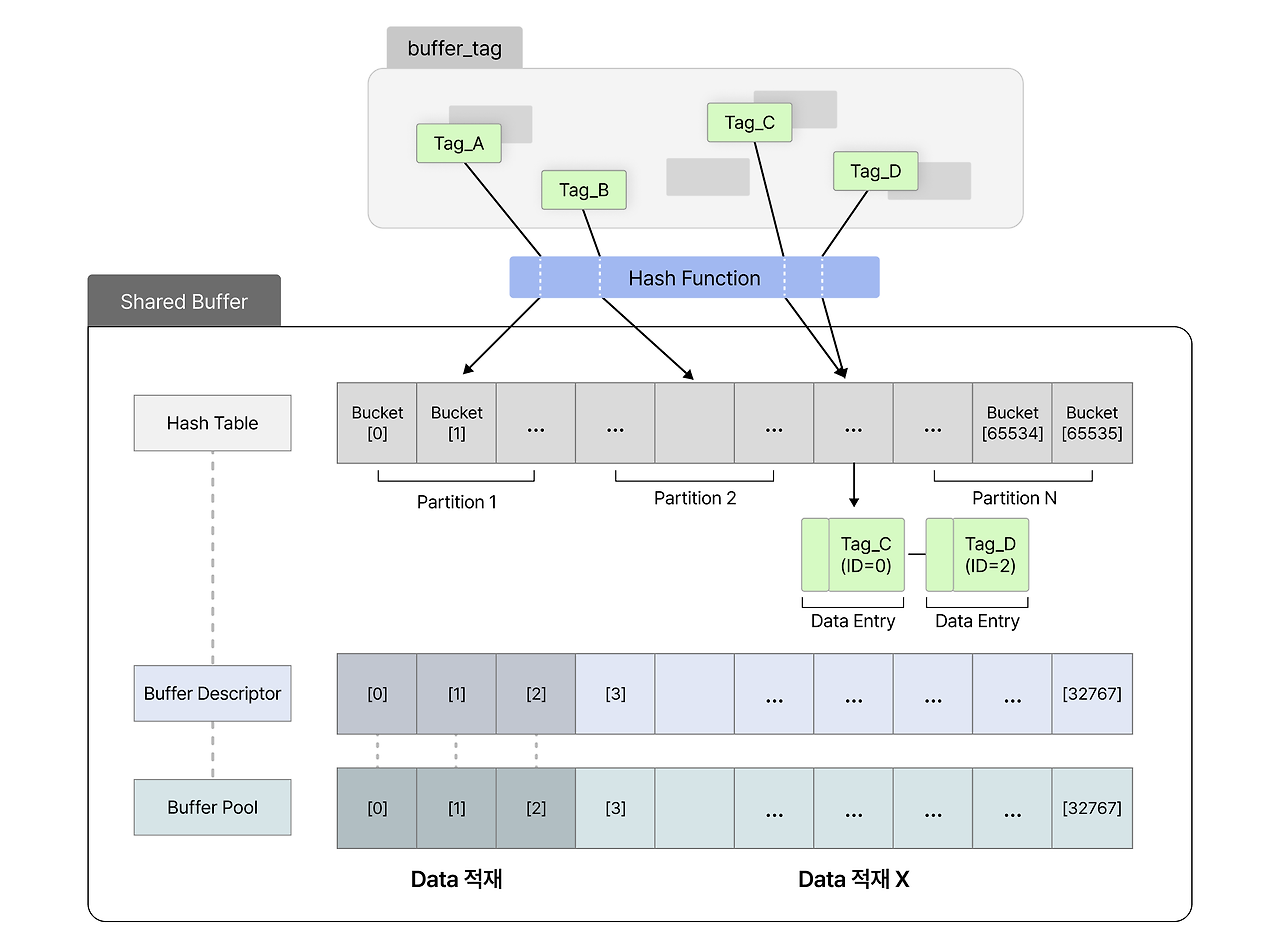
shared buffer는 hash table -> buffer descriptor -> buffer pool의 3중 구조로 이뤄져 있다.
각 구조에 대해 간단하게 살펴보자.
hash table
백엔드 프로세스가 원하는 데이터와 buffer pool에 실제로 저장된 데이터를 연결하기 위해 존재한다.
hash table은 다시 partition -> bucket -> entry로 쪼개진다.
그리고 위에서 살펴봤듯, 생성된 buffer tag는 해시 함수를 거쳐 얻어낸 해시 키로 대응되는 bucket과 연결된다.
그리고 bucket 내에서 일치하는 buffer tag를 찾아 entry를 특정한다.
entry에는 buffer id가 있기 때문에 buffer descriptor를 특정할 수 있게 된다.
buffer descriptor
데이터 page에 관한 메타데이터를 저장하고 있는 배열이다.
page가 실제로 저장된 buffer pool과 1대1 관계를 이루고 있다.
buffer descriptor의 메타데이터는 총 3개로 나뉜다.
-
buffer tag
여기서도 필요한데, 백엔드 프로세스가 원하는 데이터가 buffer pool의 것과 실제로 동일한지 해시 충돌의 상황에서도 확인해야 하기 때문에 필요하다. -
buffer id
hash table의 entry에서 buffer descriptor와 대응하기 위해 필요하다. -
state
현재 사용중인 프로세스 수를 나타내는ref_count와 얼마나 사용되었는지 나타내는usage_count, dirty와 같은 페이지 상태를 나타내는flag로 나뉜다.
buffer pool
실제 데이터 page를 가지고 있는 배열이다.
참고로, buffer pool에서의 인덱스와 buffer id가 일치한다.
(즉, buffer id가 0이면 buffer pool에서 첫번째에 위치한다)
5. shared buffer의 동작원리
백엔드 프로세스로부터 요청을 받아 실제로 buffer manager가 이를 처리하는 과정을 알아보자.
이 과정은 page가 shared buffer에 존재하는지 여부에 따라 나뉜다.
shared buffer에 있는 경우
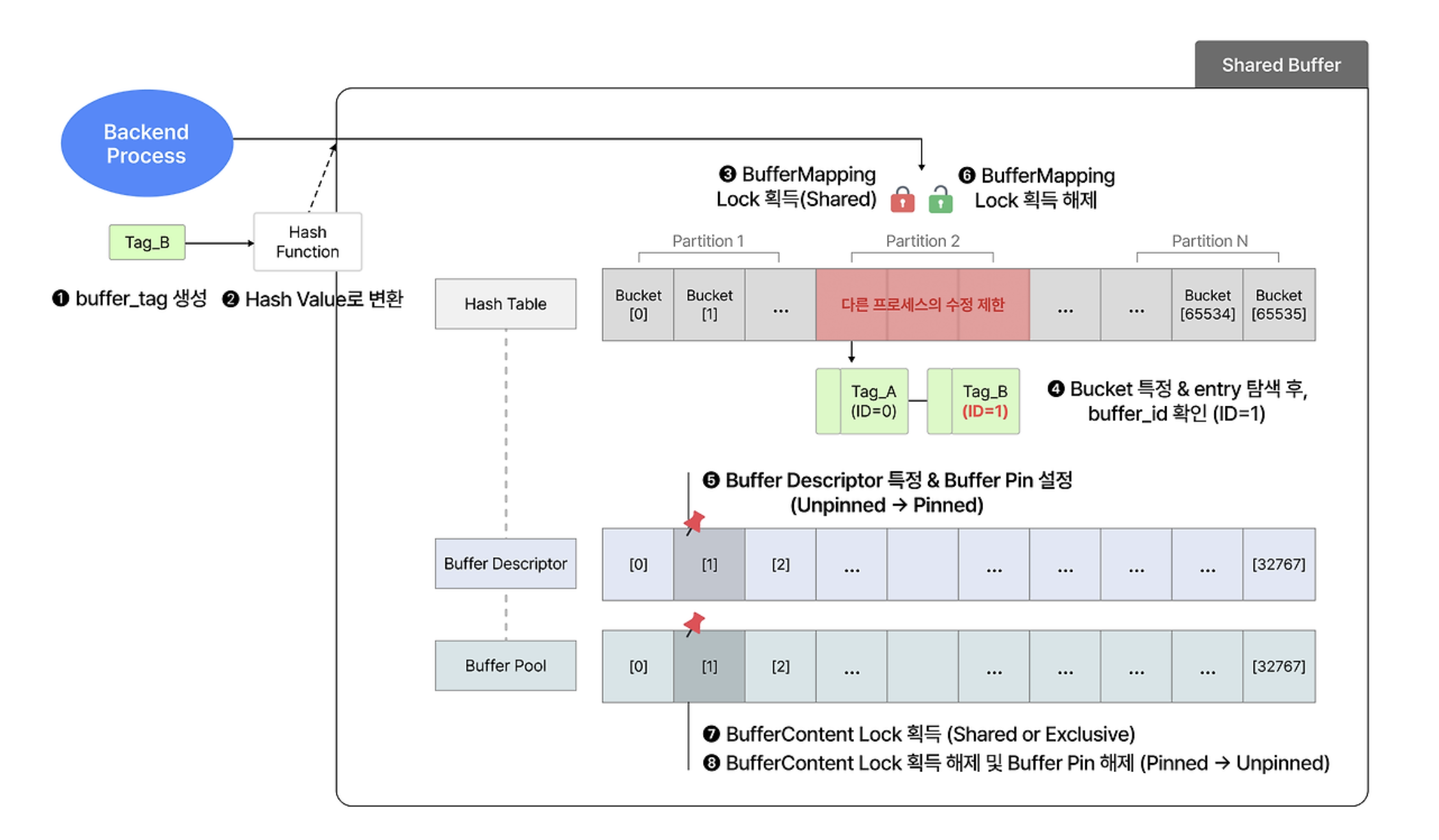
-
buffer tag를 생성한다.
-
해시 함수를 거쳐 해시 값으로 변환된다. (해시 값 != buffer id)
-
대응하는 partition에 대한 BufferMapping lock을 shared mode로 획득한다.
- shared mode는 읽기 전용의 다른 프로세스도 동일 partition에 접근할 수 있음을 의미한다.
- BufferMapping lock은 LWLock 유형의 lock인데, 이에 대해서는 하단에서 다룬다.
-
해시 값으로 bucket을 특정하고, bucket과 연결된 entry 중 buffer tag가 일치하는 것을 찾는다.
-
entry의 buffer id와 일치하는 buffer descriptor를 찾아 Buffer Pin을 설정한다.
- Buffer Pin은 일종의 flag 개념으로 사용된다.
- 다른 프로세스가 해당 buffer를 다른 것으로 교체하지 않기 위해 사용한다.
- Buffer Pin 설정 후, BufferMapping lock은 해제됩니다.
-
buffer descriptor에 대응하는 buffer pool의 페이지에 대한 BufferContent lock을 획득한다.
- BufferMapping lock과 같이 LWLock 유형의 lock이다.
- shared mode 혹은 exclusive mode로 설정할 수 있다.
- shared mode는 읽기 작업 때, exclusive mode는 쓰기 작업 때 각각 설정한다.
-
page에 대한 작업을 진행하고, 완료시 BufferContent lock과 Buffer Pin을 차례대로 해제한다.
LWLock
light-weight lock의 준말이다.
말 그대로 가벼운 lock이라는 뜻인데, 적은 오버헤드를 가지고 빠른 lock 획득, 해제가 가능해서 그렇다.
vs. spin lock
OS 수업에서 배우는 것처럼 while 문에 가둬놓고 계속 시도하는 방식은 spin lock이다.
즉, 지속적으로 락 획득을 시도하기 때문에 CPU 사용량도 많아 busy waiting이라고도 한다.
반대로 LWLock은 락 획득에 n회 실패한 경우 일정 기간 스레드를 재우기 때문에 CPU 사용량이 적다.
따라서 버퍼를 읽고 쓰고 교체하는 등의 오래 걸리는 작업에 적합하다.
BufferContent lock vs. Buffer Pin
BufferContent lock과 Buffer Pin은 모두 buffer descriptor에 걸리는 lock이다.
굳이 동일한 리소스에 2개 lock을 거는 것을 이해하지 못해 따로 찾아 비교해본다.
Buffer Pin은 lock이 아닌 flag 개념으로, 단순히 해당 buffer를 사용한다는 점을 알리기 위해 사용한다.
따라서, Buffer Pin이 설정되어 있는 buffer는 교체할 수 없다.
반대로 BufferContent lock은 buffer 내 데이터에 대한 정합성을 지키기 위해 필요하다.
그래서 데이터를 읽거나 수정할 때 shared 혹은 exclusive 모드로 걸리게 된다.
요약하자면, buffer pin이 걸려있을 땐 수정 트랜잭션만 끼어들지 못할 뿐이지만
BufferContent lock이 exclusive 모드로 걸릴 때에는 읽기 트랜잭션도 끼어들지 못하므로 더 엄격한 lock이라 할 수 있겠다.
shared buffer에 없는 경우
shared buffer에 데이터가 없는 경우 디스크에서 읽어오기도 해야 하지만,
그보다 중요한 건 디스크에서 읽은 데이터를 shared buffer 내 마땅한 공간에 저장하는 것이다.
그리고 stack, queue 같은 거 배울 때도 많이 봤겠지만
빈 공간이 있으면 그냥 넣으면 되지만 그렇지 않은 경우에는 적절한 엔트리를 하나 제거해야 한다.
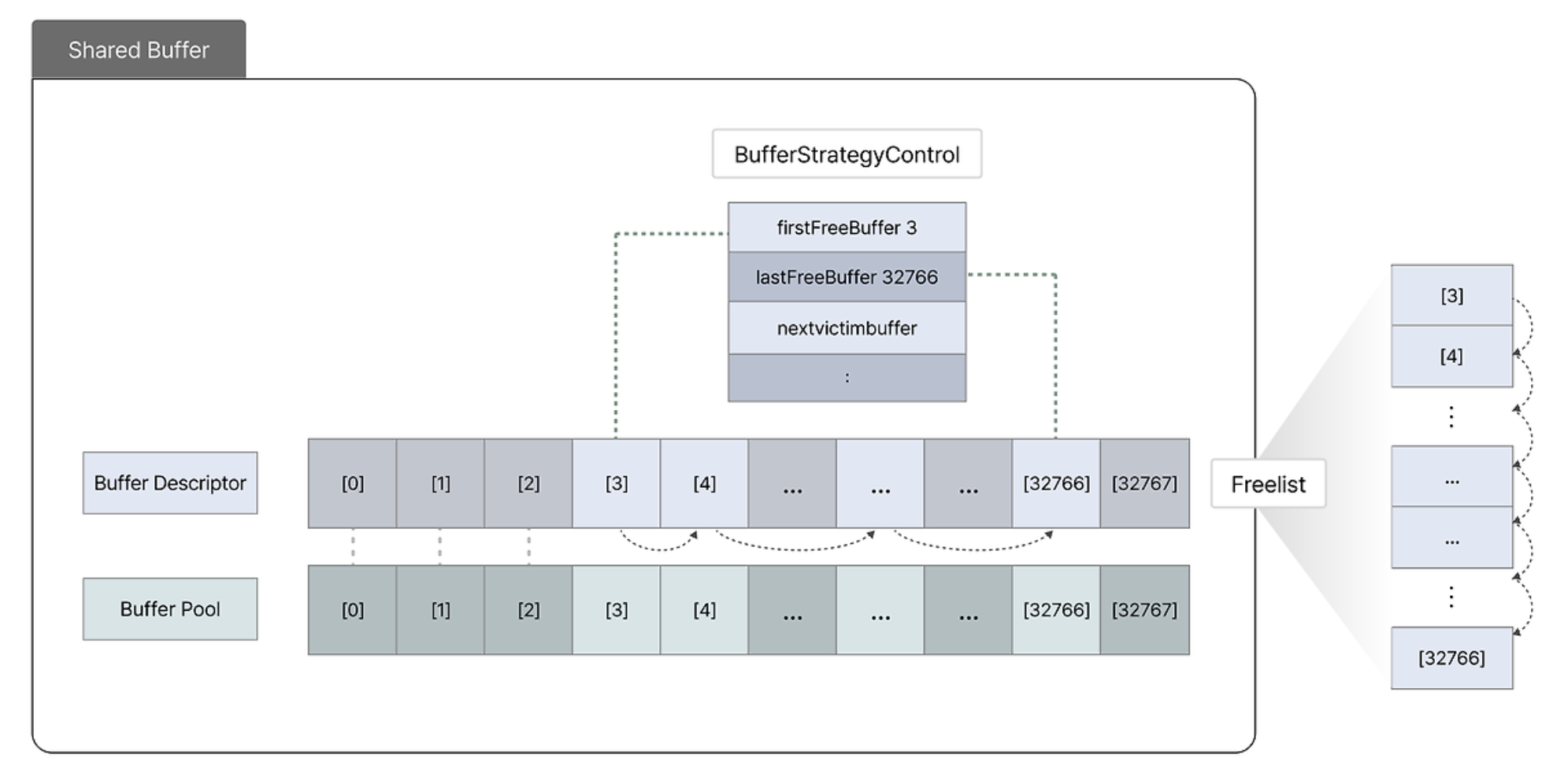
그래서 shared buffer는 현재 사용하지 않는 buffer descriptor를 참조하여 관리하는
일종의 포인터 연결 리스트로써 Freelist를 두고 관리한다.
Freelist는 BufferStrategyControl이라는 구조체(struct)를 통해 실질적으로 표현되며,
첫번째 가용 버퍼를 가리키는 firstFreeBuffer와 lastFreeBuffer를 포함한다.
(참고로 firstFreeBuffer의 값이 -1이면 빈 버퍼가 없다는 뜻이다)
이제 이 Freelist에 빈 buffer descriptor가 있는 경우와 그렇지 않은 경우를 나누어 살펴보자.
Freelist에 빈 buffer descriptor가 있는 경우
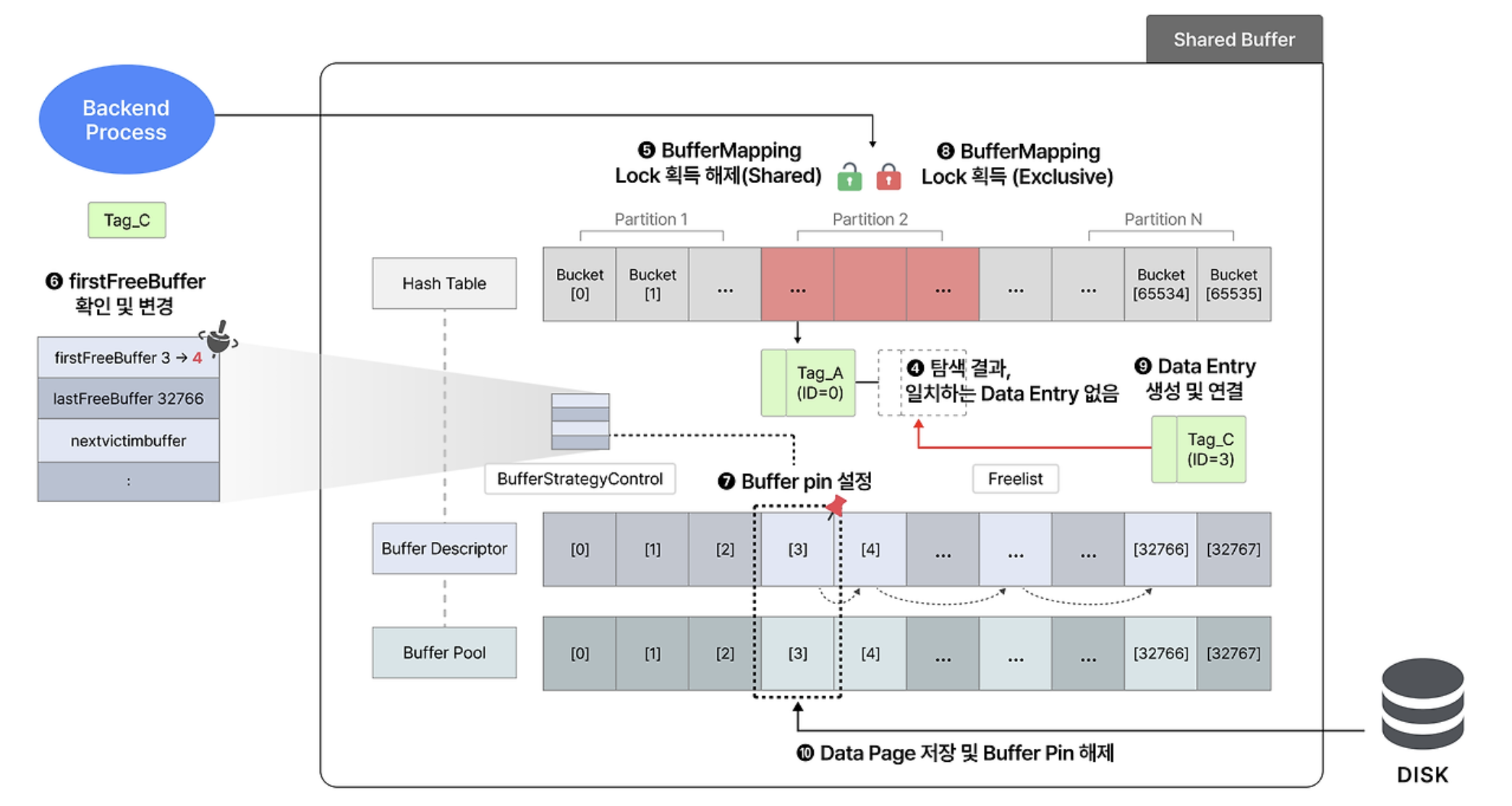
-
buffer tag로 해시 값 얻어서 BufferContent lock 걸고 bucket에 접근한다.
-
bucket에서 entry를 찾았는데 일치하는 것이 없다는 것을 깨닫고 BufferContent lock을 해제한다.
-
firstFreeBuffer값을 확인하고, 이제 빈 곳을 사용할 것이므로 변경한다. -
Freelist에서 할당받은 빈 buffer descriptor에 대해 Buffer Pin을 설정한다.
-
해시 값에 맞는 partition에 대해 BufferMapping lock을 exclusive mode로 건다.
- 이번엔 entry를 bucket에 추가하기 때문에 exclusive mode가 필요하다.
-
해당하는 entry를 생성한 후에 BufferMapping lock을 해제한다.
-
디스크에서 page를 읽어와 buffer pool에 저장하고 Buffer Pin을 해제한다.
Freelist에 빈 buffer descriptor가 없는 경우
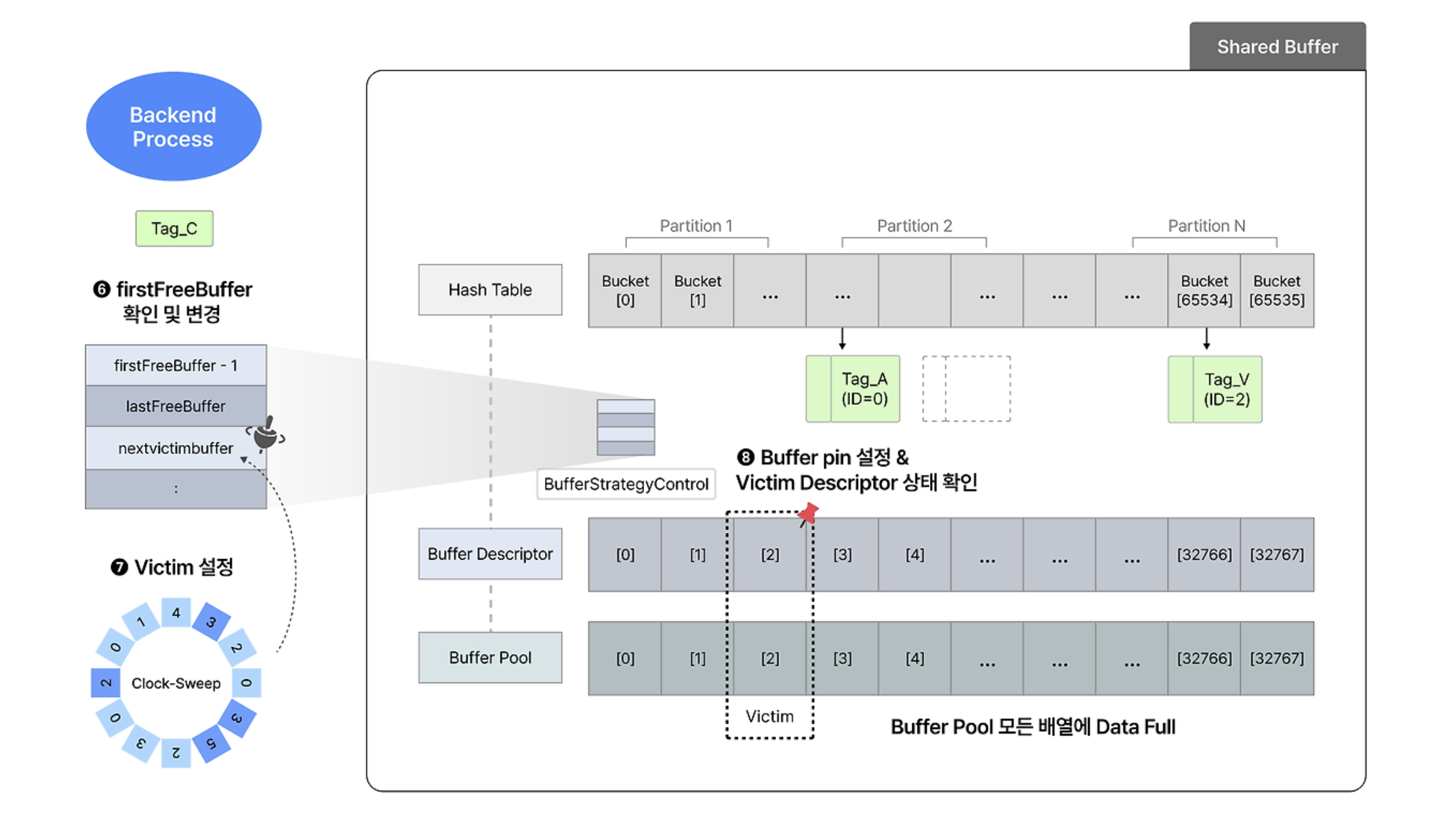
-
buffer tag로 해시 값 얻어서 BufferContent lock 걸고 bucket에 접근한다.
-
bucket에서 entry를 찾았는데 일치하는 것이 없다는 것을 깨닫고 BufferContent lock을 해제한다.
- 따라서 여기까진 빈 buffer descriptor가 있는 경우와 동일하다.
-
firstFreeBuffer값이-1임을 확인하고, 이미 사용 중인 buffer 중 victim을 선정한다.- 이 때 clock-sweep 알고리즘을 사용하는데, 이에 대해 밑에서 다룬다.
-
선정된 victim buffer descriptor에 대해 Buffer Pin을 걸고,
dirty flag가 세워진 경우 flush되어야 하므로 다른 vicitm을 찾는다.- victim이 이미 다른 프로세스에 의해 접근되었다면 필요하다는 뜻이므로 다시 victim을 찾는다.
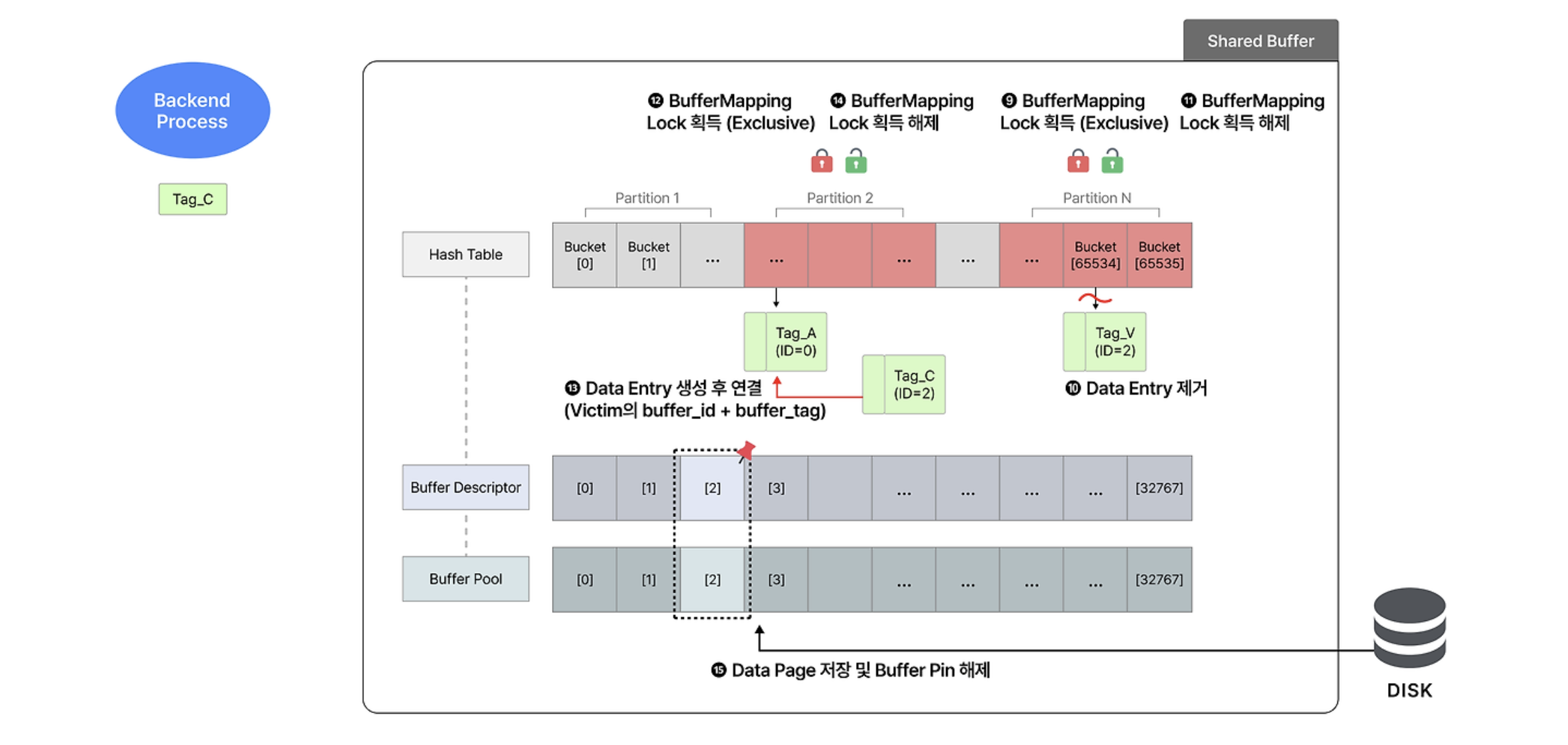
-
victim buffer descriptor의 buffer id와 일치하는 hash table entry를 찾는다.
- entry가 속한 partition에 BufferMapping lock을 exclusive mode로 건다.
- 해당 entry를 제거한 후 lock을 해제한다.
-
새로운 partition에 BufferMapping lock을 exclusive mode로 건다.
- 새로운 entry를 생성한 후
기존 buffer id + 새로운 buffer tag값을 할당한다. - entry 생성을 완료했으므로 lock을 해제한다.
- 새로운 entry를 생성한 후
-
디스크에서 page를 읽어 와서 buffer pool에 적재한 후 Buffer Pin을 해제한다.
clock-sweep 알고리즘
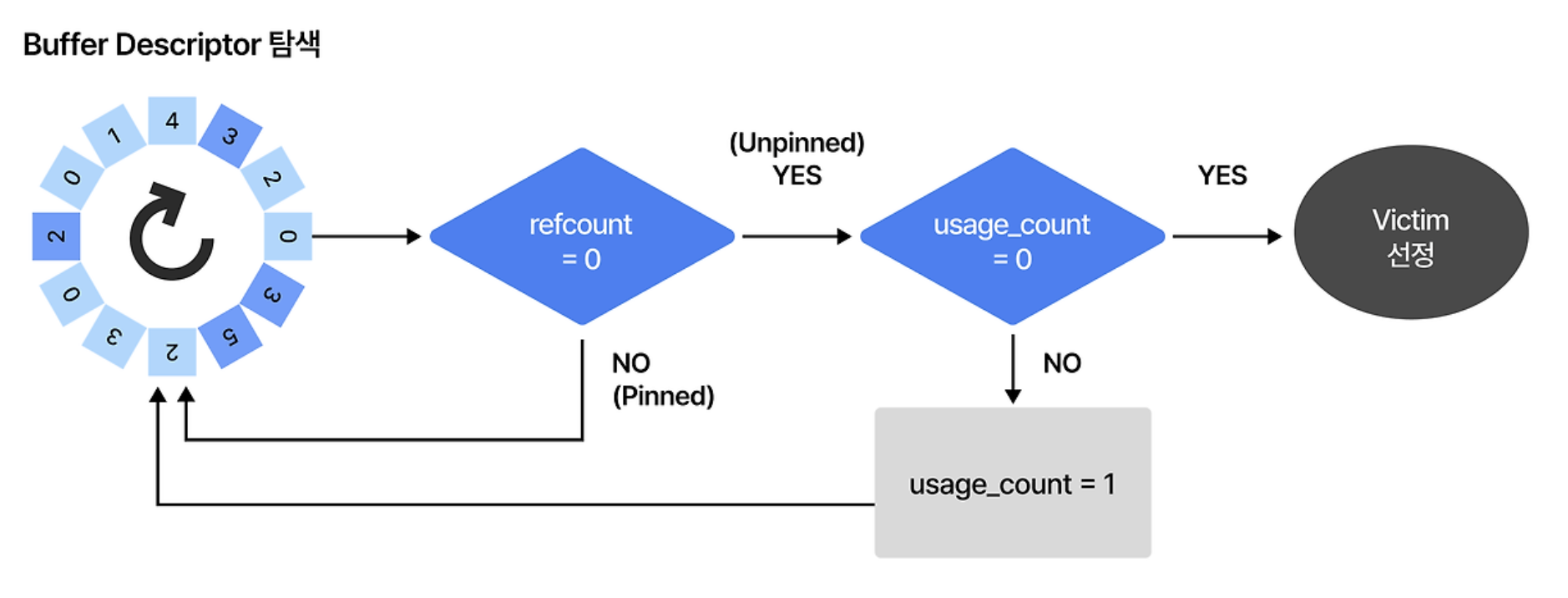
buffer descriptor의 ref_count와 usage_count를 참조하여 victim을 선정한다.
ref_count: 현재 얼마나 많은 프로세스가 동시에 참조중인지usage_count: 여태까지 얼마나 많은 작업에 사용되었는지
먼저, ref_count가 0이 아니면 buffer descriptor가 참조중이므로 다른 victim을 찾는다.
0일 경우, 나아간다.
다음으로, usage_count가 0이 아니면 최근에 사용되었다는 뜻이므로 값을 -1로 변경하고 다른 victim을 찾는다.
(그림의 usage_count = 1은 오타다)
usage_count가 0일 경우, victim으로 선정된다.

(그래서?)
6. 결론
이번 시간을 통해 데이터베이스가 캐시를 어떻게 이용하는지 알아볼 수 있었다.
여기 등장하는 lock에 대한 매커니즘이 어떻게 되는지와 디스크에서 어떻게 데이터를 가져오는지는
조금 더 시간을 두고 알아볾 문제인 것 같다.
다음 PostgreSQL 컨텐츠는 아마 vaccum에 대해 다루지 않을까 한다.
아무래도 학술적인 것을 다루다보니 글이 다소 재미가 없어지는 경향이 있는데, 양해 부탁한다.
