이미지가져오기
import urllib.request
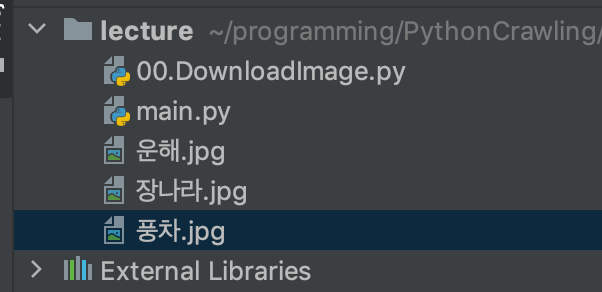
url0 = "https://i.pinimg.com/originals/88/de/d8/88ded8a13a6d4e992c3b8117616e6880.jpg"
savename0 = "운해.jpg"
url1 = "https://mblogthumb-phinf.pstatic.net/MjAxODA1MjFfNjYg/MDAxNTI2ODMxOTQxMTg3.YaofIpVwvtTxx7XVbMw0as5S7YNjHy3EDEPal8Qpj_Mg.89J8otfldn0bDNLc5M7_TbdSDW-mfyls0AY56BufIuog.JPEG.queen0113/wkdskfkdkwltbrk1.jpg?type=w800"
savename1 = "장나라.jpg"
# 1) 저장까지 바로 해줌
urllib.request.urlretrieve(url0, savename0)
#2) 이미지를 mem에 저장했다가 파일로 저장
mem = urllib.request.urlopen(url1).read()
with open(savename1, "wb") as f:
f.write(mem)
print("저장되었습니다")
데이터 가져오기
text와 같은 데이터, html의 경우에는 url으로만 가져올 수 없다.
이 때 분석을 위해 사용해야 하는 도구가 beautifulsoup이다.
html은 부모-자식 관계인 계층 구조로 되어있다.
from bs4 import BeautifulSoup
# 웹페이지에서 html을 가져왔다는 가정하에 데이터를 추출
html = """
<html>
<body>
<h1>스크레이핑이란</h1>
<p>웹 페이지를 분석하는 것</p>
<p>원하는 부분을 추출하는 것
</body>
</html>
"""
# html 분석하기
soup = BeautifulSoup(html, 'html.parser')
# 원하는 부분 추출하기(soup 객체는 계층구조로 분석한다)
h1 = soup.html.body.h1
p1 = soup.html.body.p
p2 = p1.next_sibling.next_sibling # 두번째 p태그
# 출력하기
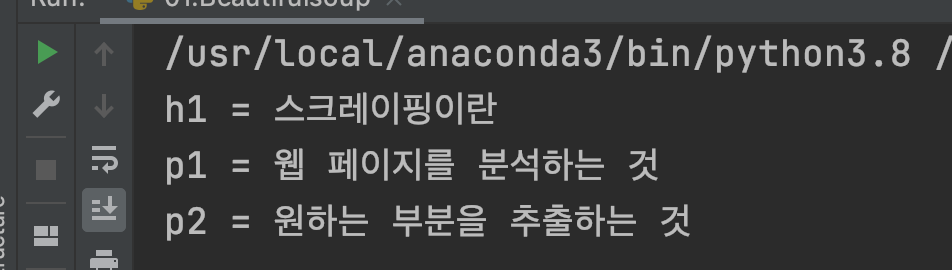
print("h1 = " + h1.string)
print("p1 = " + p1.string)
print("p2 = " + p2.string)
그런데 위와 같은 방법은 일일이 찾아줘야 하므로 복잡한 html 구조에서는 무리이다.
이럴 때 id값을 가져올 수 있는 soup.find 함수를 쓸 수 있다.
from bs4 import BeautifulSoup
# 웹페이지에서 html을 가져왔다는 가정하에 데이터를 추출
html = """
<html>
<body>
<h1 id="title">스크레이핑이란</h1>
<p>웹 페이지를 분석하는 것</p>
<p id="body">원하는 부분을 추출하는 것
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
title = soup.find(id="title")
body = soup.find(id="body")
print(title)
print(body)
print("#title=" + title.string)
print("#body=" + body.string)

findAll
from bs4 import BeautifulSoup
html = """
<html>
<body>
<ul>
<li><a href="https://www.naver.com">Naver</a></li>
<li><a href="https://www.daum.net">Daum</a></li>
</ul>
</body>
</html>
"""
soup = BeautifulSoup(html, 'html.parser')
links = soup.find_all("a") # <a></a>태그를 다 찾아라
print(links)
for a in links:
href = a.attrs['href']
print(href)
아래의 형태로 가져오는 것도 가능
for a in links:
text = a.string
href = a.attrs['href']
print("{}:{}".format(text, href))
as~ : 별명
res = req.urlopen(url) : 분석 전
그러나 어차피 url 라이브러리 객체로 받기 때문에 res, html 둘 중 아무거나 써줘도 된다.
from bs4 import BeautifulSoup # html, xml 분석도구
import urllib.request as req # 웹 html/이미지 수집도구
url = "http://www.weather.go.kr/weather/forecast/mid-term-rss3.jsp?stnId=108"
# 데이터 가져오기
res = req.urlopen(url)
# html = res.read().decode("utf-8") # 문자열 가져오기
# print(html)
# html 분석하기
soup = BeautifulSoup(res, 'html.parser') # XML도 html.parser로 해도 됨
# soup = BeautifulSoup(html, 'html.parser')
# title과 wf를 추출하기
title = soup.find("title").string # 태그사이의 문자열 추출
wf = soup.find("wf").string
print("[{}]\n{}".format(title, wf))

replace로 br, ㅇ 제거
# title과 wf를 추출하기
title = soup.find("title").string # 태그사이의 문자열 추출
wf = soup.find("wf").string
wf = wf.replace("○", "")
wf = wf.replace("<br />", "\n")
print("[{}]\n{}".format(title, wf))

selector 이용하기
from bs4 import BeautifulSoup
html = """
<html>
<body>
<div id="meigen">
<h1>경전</h1>
<ul class="items">
<li>대학</li>
<li>중용</li>
<li>논어</li>
<li>맹자</li>
<li>채근담</li>
</ul>
</div>
</body>
</html>
"""
soup = BeautifulSoup(html, "html.parser")
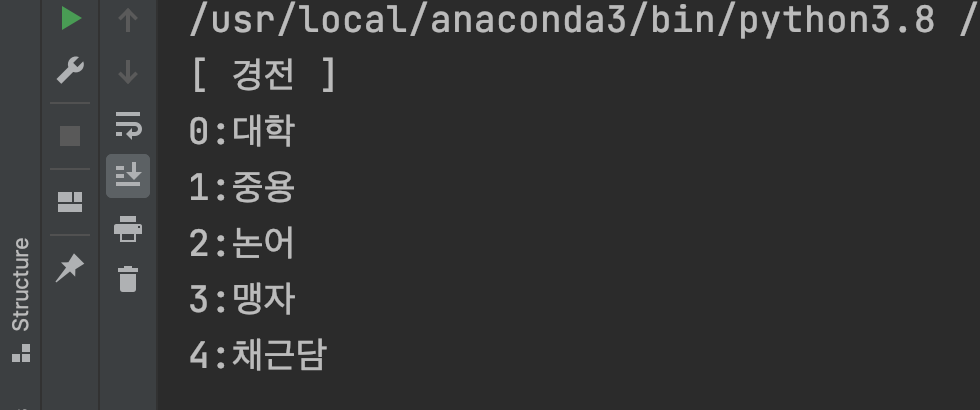
h1 = soup.select_one("div#meigen > h1").string
li_list = soup.select("div#meigen > ul.items > li")
print("[ " + h1 + " ]")
for li in li_list:
print("li = " + li.string)
soup = BeautifulSoup(html, "html.parser")
h1 = soup.select_one("div#meigen > h1").string # 1개만
li_list = soup.select("div#meigen > ul.items > li") # 1개 이상
print("[ " + h1 + " ]")
for i, book in enumerate(li_list):
print(str(i) + ":" + book.string)