interpreter -> add package로 selenium 설치 후
# https://chromedriver.chromium.org/downloads
# 위 경로에서 chrome driver 다운로드
from selenium import webdriver
import os
import time
from selenium.webdriver.chrome.options import Options
# options = Options()
# options.binary_location = "C:\\Program Files\\Google\\Chrome\\Application\\chrome.exe"
# driver = webdriver.Chrome("chromedriver.exe", options = options)
driver = webdriver.Chrome("../tools/chromedriver_win32/chromedriver.exe")
driver.get("https://www.naver.com")
if os.path.exists("./driverImage")==False:
os.mkdir("./driverImage")
# 캡쳐하여 저장
driver.save_screenshot('./driverImage/naver.jpg')
time.sleep(2)
driver.get("https://www.daum.net")
driver.save_screenshot('./driverImage/daum.png')
검색 (개발자 도구를 이용하여 id를 가져올 수 있다)
from selenium import webdriver
import time
driver = webdriver.Chrome("../tools/chromedriver_win32/chromedriver.exe")
driver.get("https://www.naver.com")
time.sleep(0.5)
elem_search = driver.find_element_by_id("query")
elem_search.clear()
elem_search.send_keys("상선약수")
time.sleep(0.5)
elem_search_btn = driver.find_element_by_id("search_btn")
elem_search_btn.click()
time.sleep(0.5)
elem_water_word = driver.find_element_by_xpath("""//*[@id="main_pack"]/section[1]/div/div[2]/div[1]/dl/dt/a/span""")
elem_water_word.click()
셀레니움을 쓰는 이유는 동적인 페이지(주소는 똑같은데 안의 element들이 바뀔 때(ajax요청한 데이터들))에서도 데이터 수집이 가능
from selenium import webdriver
driver = webdriver.Chrome("../tools/chromedriver_win32/chromedriver.exe")
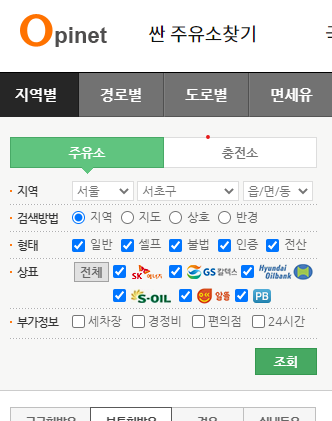
driver.get("https://www.opinet.co.kr/")
driver.implicitly_wait(1) # 1초간 대기 time.sleep(1)
driver.get("https://www.opinet.co.kr/searRgSelect.do")
# gu_list_raw = driver.find_element_by_id("SIGUNGU_NM0")
# gu_list_raw = driver.find_element_by_css_selector("#SIGUNGU_NM0")
gu_list_raw = driver.find_element_by_xpath("""//*[@id="SIGUNGU_NM0"]""")
gu_list = gu_list_raw.find_elements_by_tag_name("option")
gu_names = [gu_obj.get_attribute("value") for gu_obj in gu_list]
for gu in gu_names:
print(gu)
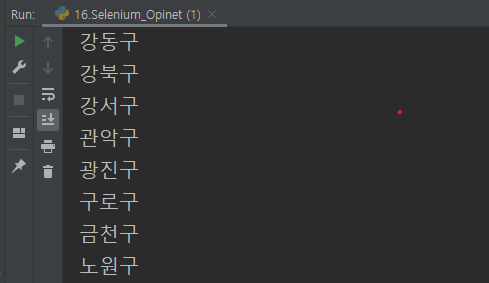
구 정보를 뽑아옴

gu_names.remove("") # 빈 데이터 삭제
print(gu_names)
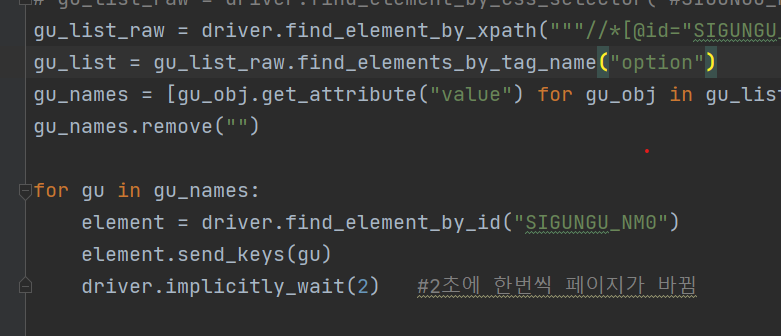
2초에 한번씩 페이지(구의 option)가 바뀐다.
엑셀 저장 버튼 누르도록 추가
for gu in gu_names:
element = driver.find_element_by_id("SIGUNGU_NM0")
element.send_keys(gu)
driver.implicitly_wait(1)
excel_btn = driver.find_element_by_xpath("""//*[@id="glopopd_excel"]/span""")
excel_btn.click()
driver.implicitly_wait(1)
다운받아진 엑셀 파일들.
beautiful soup 이용하기
코드를 실행하면 html 파일이 생성된다.
html 파일을 가져왔으므로 이제 bs 사용이 가능하다.
# 파일 저장
element = driver.find_element_by_id("SIGUNGU_NM0")
element.send_keys(gu_names[0])
driver.implicitly_wait(1)
html = driver.page_source
with open("opi.html", "w", encoding="utf-8") as f:
f.write(html)
html파일에서 bs를 이용하여 요소를 가져오도록 코드 추가
아래의 정보를 가져오기
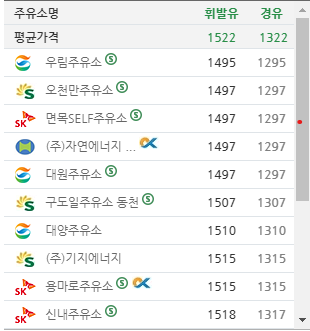
from selenium import webdriver
from bs4 import BeautifulSoup
driver = webdriver.Chrome("../tools/chromedriver_win32/chromedriver.exe")
driver.get("https://www.opinet.co.kr/")
driver.implicitly_wait(1) # 1초간 대기 time.sleep(1)
driver.get("https://www.opinet.co.kr/searRgSelect.do")
# gu_list_raw = driver.find_element_by_id("SIGUNGU_NM0")
# gu_list_raw = driver.find_element_by_css_selector("#SIGUNGU_NM0")
gu_list_raw = driver.find_element_by_xpath("""//*[@id="SIGUNGU_NM0"]""")
gu_list = gu_list_raw.find_elements_by_tag_name("option")
gu_names = [gu_obj.get_attribute("value") for gu_obj in gu_list]
gu_names.remove("")
for gu in gu_names:
element = driver.find_element_by_id("SIGUNGU_NM0")
element.send_keys(gu)
driver.implicitly_wait(1)
html = driver.page_source
soup = BeautifulSoup(html, "html.parser")
a_stations = soup.select("#body1 > tr > td.rlist > a")
station_names = [a.text for a in a_stations]
print(station_names)
# element = driver.find_element_by_id("SIGUNGU_NM0")
# element.send_keys(gu_names[0])
# driver.implicitly_wait(1)
# html = driver.page_source
# with open("opi.html", "w", encoding="utf-8") as f:
# f.write(html)
from selenium import webdriver
from bs4 import BeautifulSoup
driver = webdriver.Chrome("../tools/chromedriver_win32/chromedriver.exe")
driver.get("https://www.opinet.co.kr/")
driver.implicitly_wait(1) # 1초간 대기 time.sleep(1)
driver.get("https://www.opinet.co.kr/searRgSelect.do")
# gu_list_raw = driver.find_element_by_id("SIGUNGU_NM0")
# gu_list_raw = driver.find_element_by_css_selector("#SIGUNGU_NM0")
gu_list_raw = driver.find_element_by_xpath("""//*[@id="SIGUNGU_NM0"]""")
gu_list = gu_list_raw.find_elements_by_tag_name("option")
gu_names = [gu_obj.get_attribute("value") for gu_obj in gu_list]
gu_names.remove("")
station_names = []
for gu in gu_names:
print(gu + " - 주유소 수집")
element = driver.find_element_by_id("SIGUNGU_NM0")
element.send_keys(gu)
driver.implicitly_wait(0.1)
html = driver.page_source
soup = BeautifulSoup(html, "html.parser")
a_stations = soup.select("#body1 > tr > td.rlist > a")
names = [a.text for a in a_stations]
station_names.extend(names)
# tap은 공백으로 바꾸고 strip으로 공백 제거
station_names = [name.replace('\t', '').strip() for name in station_names]
for station in station_names:
print(station)
print("서울 총 주유소 개수 : ", len(station_names))
# element = driver.find_element_by_id("SIGUNGU_NM0")
# element.send_keys(gu_names[0])
# driver.implicitly_wait(1)
# html = driver.page_source
# with open("opi.html", "w", encoding="utf-8") as f:
# f.write(html)

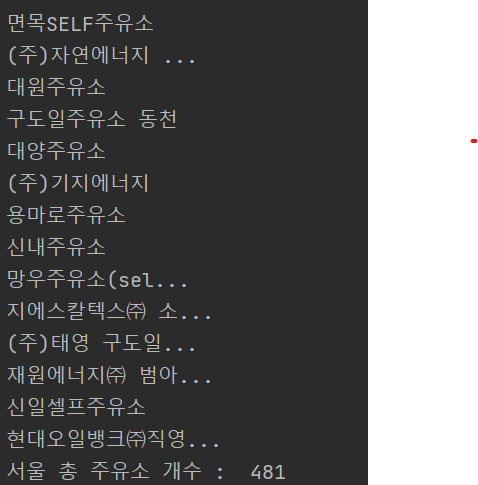
아래처럼 코드 수정시
station_names = [name.replace('\t', '').strip() for name in station_names]
for i, station in enumerate(station_names):
print(station, end="\t")
if i % 3 == 0:
print()
print("서울 총 주유소 개수 : ", len(station_names))
