검색알고리즘에 대하여 알아보자!
이번에 자동완성알고리즘에 대해 공부하게 되었다...!
여태 한번도 어떻게 자동완성이 되는지 궁금해본적이 없는데 이번 기회에 생각해보게 되었다. 단순히 알고리즘 구현과제였지만 실제로 어떻게 쓰이는지 궁금하여 동작원리를 알아보았다.
1. 이벤트 호출 방법
- input이 change가 될때마다 이벤트가 발생한다.
- 많은 데이터가 없을 경우 한번에 서버에서 데이터를 가져온다음 filter를 해 보여준다.
우선 구글이 어떻게 관리하는지 궁금해져서 네트워크 탭을 살펴보았다.
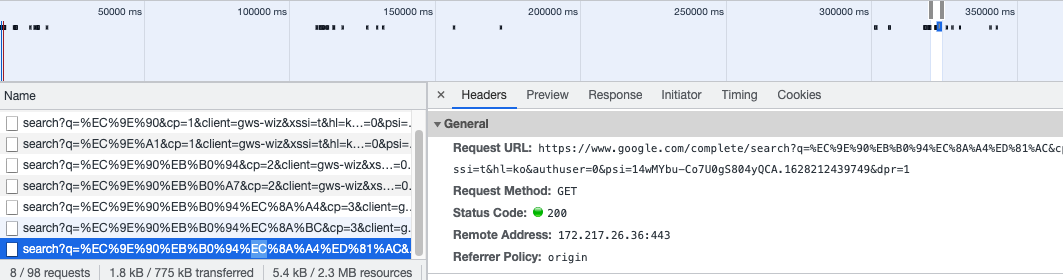

까보니 이렇게 input이 변경될때마다 데이터를 받아서 보여주는것 같다!!
이제 알고리즘을 구현해보자!
트라이 알고리즘
원리
이름에서 유추할수 있지만(?) 트리의 개념을 이용해 만들어져있다!
(트리 트리이 트라이..?)사실 이름의 유래는 Retrieval에서 나왔다고 한다
예시를 드는게 이해하기 더 편하니 cat, cow, rat을 저장해보자!
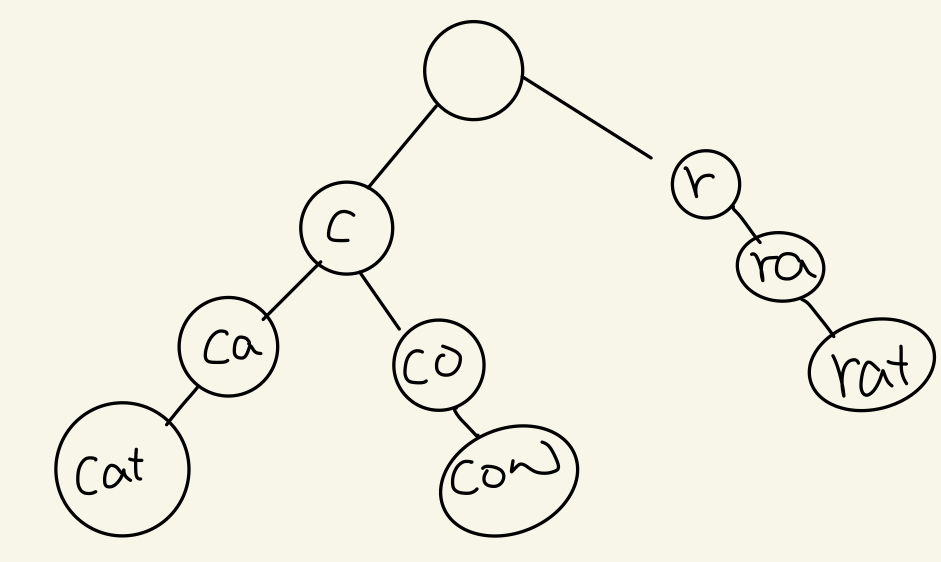
이러한 형태로 구현이 된다.
구현
강의에서 보았던 기본적인 트라이 알고리즘으로 구현하려고 했지만 몇몇의 문제가 존재해 트라이 알고리즘을 내가 보기 편하기 수정하였다!
기존의 알고리즘은 Node의 프로퍼티가 value와 children만 존재한다
또한 children이 Map의 인스턴스로 생성되었기 때문에 해당 노드가 트리의 마지막인지 확인하기 어려웠다
Map(2) {
'a' => Nodes { value: 'ca', children: Map(1) { 'n' => [Nodes] } },
's' => Nodes { value: 'cs', children: Map(1) { 'z' => [Nodes] } }
}
Nodes {
value: 'ca',
children: Map(1) { 'n' => Nodes { value: 'can', children: Map(0) {} } }
}
Map(1) { 'n' => Nodes { value: 'can', children: Map(0) {} } } childnode. children위의 코드는 트리를 depth가 증가할때마다 node의 프로퍼티들이다. 마지막을 보면 n의 value에서 children의 프로퍼티가 Map(0)이 되어있는데 이놈의 길이를 알수있는 방법을 잘 모르겠다,,,
추가적인 길이를 판별하는 로직을 만들었지만 다른 좋은 방법을 고민하다 Node클래스의 구조를 변경하였다!
바뀐 Node class
class Node {
constructor() {
this.next = {}
this.depth = 0
this.words = new Set()
this.last = false
}
}위와 같이 변경하여 last요소인지 확인할때 직관적으로 확인할 수 있게 하였다.
이제 구현을 할 때 더 편하게 할 수 있었다.
이렇게 부분 코드만 가지고 서술을 하니 두루뭉실한것 같지만... 추후에 깃헙 링크를 달도록 하겠다!!
느낀점
단순히 사용만하던 자동완성을 직접 생각하면서 만들다 보니까 생각할것도 많았다. 추후에는 간단히 백엔드도 만들어서 해보면 재밌을것 같다..!
ps) 추합으로 들어왔는데 적응하는데 많이 도움주신 리아님 그리고 팀원분들 감사합니다👍👍
