최근 수업의 일환으로 딥러닝과 관련하여 주제를 잡고 논문을 읽어 개선점 및 활용점을 제출할 일이 생겼다.
글에 들어가기 앞서..
1차 학기인 나로서는 당황할 수 밖에 없는 수준이라고 생각이 든다. 그래도 해야지..
연구 주제를 정함에 있어서 짧은 시간이나마 몇 가지 요소들을 고려해 봤고, 이번 포스팅 주제가 나오게 되었다.
우선, viso.ai에 잘 정리가 되어 있는 Human Pose Estimation with Deep Learning - Ultimate Overview in 2023을 읽은 것을 시작으로 해당분야의 정리 및 논문 탐색을 해보려 한다.- viso.ai/deep-learning 관련 글
해당 기고문은 가장 최근의 발전된 pose estimation algorithm과 AI Vision 기술 그리고 이들의 application과 use case 그리고 한계점에 대해 전반적으로 기술하고 있기 때문에 overview에 적합하다고 생각 된다.
Contents
(1)정의 : Pose Estimation이란 무엇일까?
- Bottom up vs. Top down methods
- Pose Estimation의 중요성
(2)예시
- Human pose estimation
- Head pose estimation
- Animal pose estimation
(3)동작 원리
(4)Use Case & Applications
Pose Estimation이란?
Pose Estimation(이하 'P.E')은 컴퓨터 비전과 AI 분야에서 기본이 되는 task이다. 대상 이미지나 영상 속에서 묘사되는 인체 부위가 갖는 방향성이나 위치를 감지(Detecting)하고 연결(Associating), 추적(Tracking)하는 것을 포함하고 있기 때문이다.
감지, 연결, 추적의 대상은 Semantic Key point이며 인간의 pose를 estimation할 경우 대표적인 예로 "right shoulders","left knees"가 있다.
사물의 pose를 estimation할 경우(Object pose estimation) 대표적인 예로 자동차의 "left brake lights of vehicles"가 있다.

라이브 영상에서 semantic keypoint를 추적하게 된다면, P.E의 정확도에 Limit을 걸어도 매우 큰 컴퓨팅 리소스를 필요로 하게 된다.
다만, Hardware와 모델 효율성이 최근에 크게 발전함에 따라 real-time 처리의 요구가 있는 새로운 application이 구현 및 경제적 실현이 가능해지고 있는 추세다.
여기서는 모델에 대해서만 이야기 해보겠다. 최근 이미지 처리 분야에서 가장 powerful한 model은 다수가 CNN(Convolutional Neural Network)를 기반으로 하고 있다. 따라서 인간과 물체의 pose를 추론하는 application의 SOTA(State-of-the-Art) method는 CNN Architecture기반으로 이뤄진다.
Bottom-up Vs. Top-down methods
P.E의 모든 접근법은 두 그룹으로 나뉠 수 있다.
-
Bottom-up methods
우선 신체에 있는 모든 관절을 estimate한다음, 특정한 포즈 또는 하나의 사람 객체의 포즈로 그룹지어주는 방식이다.
"DeepCut모델"이 선도한 영역이라고 한다.
이 방식의 문제점음 찾은 관절을 매칭할 수 있는 조합이 매우 많고(가령, 사람 1의 팔꿈치를 사람2에 붙일 수도 있겠다) 이를 적절하게 매칭하는데 시간이 많이 걸리며 정확도를 높이는 것이 힘들다.
하지만 사람을 먼저 감지하는 과정을 거치지 않기 때문에 Real-time에 적용이 가능하다. -
Top-down methods
사람을 먼저 detecting한 후 detecting box 안에 있는 신체 관절을 estimate한다. 문제점은 사람을 인식하지 못하면 자세 자체를 측정할 수 없고 사람의 수가 많아지면 계산량도 많아진다.
어떤 방식이 맞을지는 추후 공부해보면서 파악해봐야겠다.
Pose Estimation의 중요성
전통적인 object detection에서 인간은 오직 bounding box로만 인식이 되었다.
네모 박스는 그저 인간의 위치만 파악할 뿐 해당 인간이 어떠한 의도가 있는지, 자세는 어떤지, 어떠한 상황인지를 파악하기 어렵다.
그렇기 때문에 Pose를 detection하고, tracking함으로서 컴퓨터는 인간의 body language를 더욱 잘 이해할 수 있게 되는 것이다.
그러나 기존의 pose tracking 방법은 Occlusion을 이겨낼 만큼 robust하지도, fast하지도 않은 한계가 존재했다.
그럼에도 최근에는 고성능의 real-time pose detection과 tracking이 비전 분야에서 메가 트렌드로 자리매김하고 있다. 예를 들어, 인간의 pose를 real-time으로 추적하면 컴퓨터가 인간 행동을 보다 세밀하고 자연스럽게 이해 할 수 있게 된다.

자율 주행, 스포츠, 헬스케어 등등 많은 산업군에 영향을 미칠 수 있게 되는 것이다. 오늘날 자율 주행 자동차의 사고(사실 진정한 의미의 자율주행은 아닌 단계이다. 산업계에서 자율주행차라고 지칭하는 것으로 이해하자.)의 대부분은 테슬라의 오토파일럿과 같이, 기술이 미성숙한 상태에서 인간이 완전히 기계를 믿기에 발생하는 건이다.
만약 인간의 pose를 detection하고 tracking할 수 있다면, 컴퓨터는 보행자나 in cabin의 행동을 더욱 이해하여 안전하고 natural한 driving을 할 수 있을 것이다.

예시
Human Pose Estimation
이제는 P.E의 구체적이 예시를 깊이 들여다 보자.
Human P.E는 이미지나 비디오 상에 나오는 신체나 관절의 pose를 예측하는 것을 주 목적으로 한다. pose의 모션은 인간의 특정한 행동에 의해 발생되기 때문에 신체의 pose를 이해하는 것은 동작인식과 video 상의 인간의 동작을 이해하는 Video understanding 분야에서 매우 중요한 문제이다.

2D Human Pose Estimation이란?
인체의 keypoint의 2D 위치 또는 공간 위치를 추정하는 것을 의미한다. 전통적인 2D Human P.E 방법은 개별 신체 부위에 대해 각기 다른 수작업 특징 추출 기술을 사용하였다.
초기 컴퓨터 비전 작업은 global pose structure를 얻기 위해 인간의 신체를 막대기 모양으로 묘사했다. 그러나 최신 딥러닝 기반 접근 방식은 single-person과 multi-person의 P.E 분야에서 모두 성능을 크게 개선하였다.
대표적인 2D Human P.E 기법으로는 OpenPose, CPN, AlphaPose, HRNet이 있다.

3D Human Pose Estimation이란?
3D 공간 상에서 신체 관절의 위치를 예측하는 것을 의미한다. 게다가 3D 포즈 외에도 일부 방법은 이미지 또는 비디오에서 3D 인간 메쉬를 복구한다. 이 분야는 인체의 광범위한 3차원 구조 정보를 얻는 데에 활용되기 때문에 최근 많은 관심을 받고 있다. (나도? ㅎ)
다양한 분야에 사용될 수 있는데, 3D 애니메이션 분야, VR/AR, 3D 행동 예측 분야 등이 대표적인 예이다. 3D Human P.E는 monocular 이미지 또는 비디오에서 수행될 수 있다.
multiple viewpoint 혹은 IMU, Lidar와 같은 센서를 사용하는 퓨전 기술을 적용한 3D P.E는 매우 어려운 작업이라고 한다. 2D Human dataset은 얻기가 쉬운 반면, 3D는 상대적으로 어렵다. 3D pose의 정확한 image annotaion은 너무 많은 시간이 소요되며, 수동 레이블링(manual labeling)은 실용적이지도 않고 비용이 많이 든다.
그래서 비록 3D P.E이 최근 몇년 간 2D P.E의 진전으로 인하여 상당한 발전을 이뤘지만 극복해야할 몇 가지 산이 있다고 한다.
대표적 예시는 아래와 같다.
- Model generalization
- robustness to occlusion
- computation efficiency.
실시간 3D Human P.E를 위해 Neural Network를 사용한 대표적인 라이브러리로는 OpenPose가 있다.
3D Human Body Modeling
human P.E에서 인체 부위의 위치는 시각적 입력 데이터로부터 인체 표현(ex: skeleton pose)을 구축하는 데에 사용 된다. 즉, 시각적 입력 데이터에서 추출한 특징 및 키포인트를 나타내는 데에 사용된다. 그렇기에 Human body Modeling이 human P.E에서 중요한 것이다.
일반적으로 모델 기반의 접근 방식은 인체 pose를 설명 및 추론하고 2D 혹은 3D 포즈를 렌더링 하는 데에 사용 된다.
대부분의 방법은 N-joint kinematic model을 사용한다. 이 모델은 인체를 신체 운동학적 구조와 체형 정보를 포함하는 관절과 팔다리가 있는 개체로 표현한다.
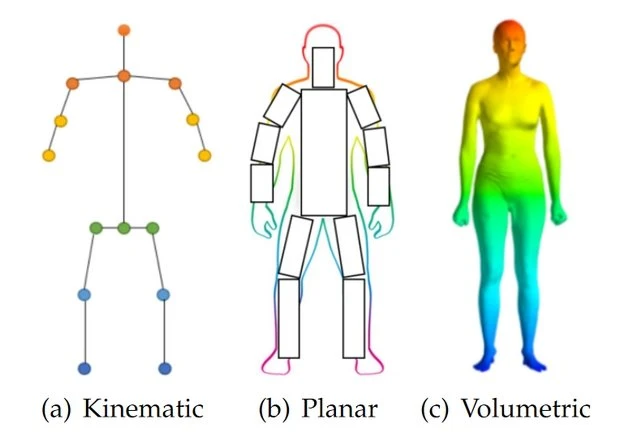
Body Modeling에는 3가지 타입이 있다.
Kinematic Model
Skeleton-based model이라고도 불리며, 2D와 3D P.E에 사용 된다. 직관적인 바디 모델로서, 관절의 위치나 팔다리(사지)의 방향과 같이 인체 구조를 나타내는 핵심 정보를 포함하고 있다.
이에, 서로 다른 신체 부위 간의 관계를 포착하는 데에 활용되기도 한다. 하지만, 해당 모델은 Texture 혹은 shape에 관한 정보를 표현하는 데에 부족하다는 한계점이 있다.
Planar Model
Contour-based model이라고도 불리며, 2D P.E에 사용 된다. 이는 인체의 shape과 appearance를 나타내는 데에 사용 된다. 주로, 인체의 외곽선을 따라 내부를 최대한 꽉꽉 채우는 작은 직사각형들로 인체의 부위를 표현한다.
대표적인 모델로 Active Shape Model(ASM)이 있으며, Principle component analysis(주성분 분석)을 이용하여 전체 인체 그래프와 실루엣 변형을 포착하는 데에 활용 된다. 이는 60,000개 이상의 고해상도의 전신 스캔 데이터셋에서 훈련된 완전히 훈련 가능한 end-to-end 딥러닝 파이프라인이다. 이를 통해 통계적이며, 관절로 분절된 3D 인체 shape과 pose을 모델링 할 수 있다.
Volumetric Model
3D P.E에 사용 된다. 3D human mesh 복구를 위한 딥러닝 기반의 3D human P.E에 사용 되는 몇몇 인기 있는 3D 신체 모델이 있다. 대표적인 예로 GHUM & GHUML(ite)이 있다.
Pose Detection의 주요 챌린지
Human P.E은 신체의 외형이 계속해서 변해가기 때문에 매우 어려운 Task중 하나이다. 옷의 형태, randomic하게 occlusion되는 경우, 시야각, 배경의 문맥(상황이라고 이해해본다) 등 많은 요소로 인해 변화가 일어난다. 나아가 P.E는 빛이나 날씨와 같은 리얼 세계의 수많은 변화에 대응할 수 있을만큼 robust해져야 한다는 도전 과제가 쌓여 있다.
Head Pose Estimation
인간 머리의 pose를 estimate하는 것은 유명한 computer vision 문제이다. 여기에는 여러 application이 활용되는데 aiding in gaze estimation, modeling attention, fitting 3D models to video, performing face alignment 등이 대표적이다.
전형적으로 머리 pose를 찾을 때는 대상 얼굴의 keypoint를 사용하고 2D에서 3D pose로의 대응 문제는 mean human head model로 해결한다.
머리의 3D pose 리커버 능력은 딥러닝 기법을 활용한 2D facial keypoint 추출에 기반한 keypoint-based 표정 분석으로 부터 나오게 된다. 해당 방식을 통해 occlusion과 다양한 포즈 변화에 강건한 형태가 되었다.
Animal Pose Estimation
대부분 SOTA를 달성한 기법들은 인체 포즈에만 관심이 있지만, 몇몇 모델은 동물과 자동차(사물)을 Estimation하기 위해 개발되어 왔다.
Human E.P와 달리 추가적인 어려움이 존재하는데, 제한된 라벨 데이터(데이터를 수집하고 수동으로 이미지에 주석을 추가해야하는 등)와 너무도 많은 self-occlusion이 문제다. 그래서 동물 포즈 추정을 위한 데이터셋은 아주 제한된 숫자의 동물 종을 포함하고 있다.
이렇게 사용 가능한 데이터가 한정적이고 작은 데이터셋으로 작업을 수행할 때는 Active learning과 data augmentation 기법이 필요로 하게 된다. 양 기술은 vision 알고리즘을 더욱 효과적으로 학습시키고 맞춤형 AI model 학습을 위한 annotation 작업량을 감소시켜 준다.

또한, 다수의 동물의 포즈를 추정하는 것은 어려운 computer vision 문제이다. 동물간 빈번한 상호작용으로 인해 occlusion을 야기하고 감지된 keypoint를 올바르게 객체마다 할당하는 것을 복잡하게 만들기 때문이다. 나아가 인간이 볼 때, 매우 비슷하게 생긴 동물이 통상 인간 세계의 상호 작용보다 더욱 긴밀하게 상호작용한다면 이때의 다수 동물의 포즈를 추정하는 것도 어렵겠다.
이러한 문제를 해결하기 위해 인간에서 동물로 방법을 다시 적용하는 transfer learning 기술이 개발 되었다. 대표적인 예시로 다수의 동물의 포즈를 추정하고 추적할 때 DeepLabCut을 사용한다. 이는 인간과 동물의 포즈를 추정하는 오픈 소스 툴 박스이며 SOTA를 찍는 모델이다.
동물 포즈 추적에 관련한 컴퓨터 비전 기술의 응용은 아래 글을 참고하면 된다.
Computer vision in agriculture
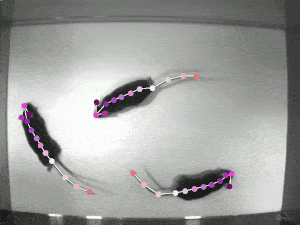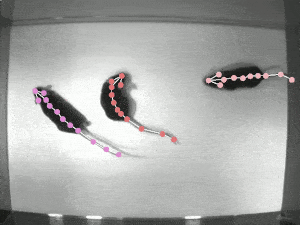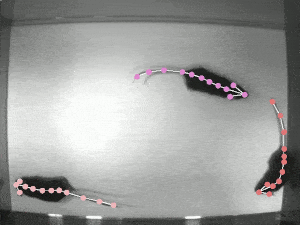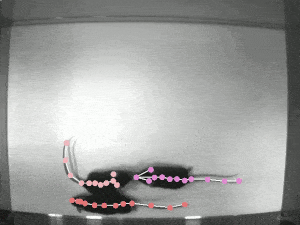
Video Person Pose Tracking
복잡한 상황에서의 Multi-frame human pose estimation은 매우 복잡하고 높은 컴퓨팅 파워를 요한다. 인간의 관절 detector가 정적 이미지에서는 좋은 성능을 발휘하는 반면에, ML 모델이 실시간 포즈 추적을 위해 비디오 시퀀스에 적용될 때는 성능이 종종 부족해진다.
가장 큰 문제들 중 일부는 motion blur 처리, video defocus, pose occlusion, 비디오 프레임 간의 시간적 종속성을 포착할 수 없는 등의 어려움이 있다.
기존의 RNN을 적용하면, 특히 pose occlusion을 처리하는데에 공간의 컨텍스트를 모델링하는 데에 경험적인 어려움이 발생하게 된다. multi-frame에서 인간의 자세를 추정하는 SOTA를 찍는 프레임워크인 "DCPose"는 비디오 프레임 사이의 풍부한 temporal 단서를 활용하여 eypoint detection을 용이하게 한다.

Pose Estimation은 어떻게 동작할까?
대부분의 포즈 추정기(pose estimator)는 2단계의 프레임워크로 구성되어 있다. 인간의 bounding box를 감지한 다음 각 box내에서 포즈를 추정한다.
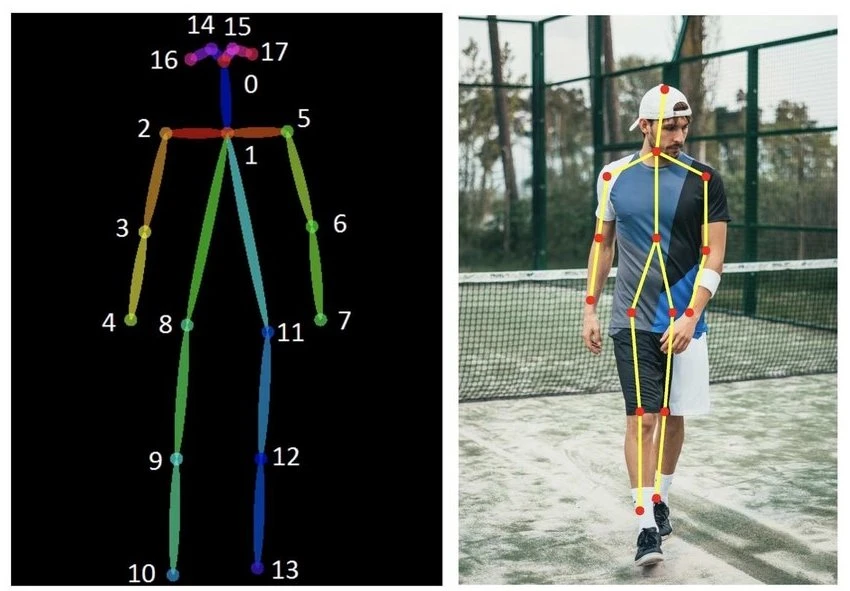
포즈 추정은 사람이나 사물의 keypoint를 찾는 방식으로 작동한다. 예를 들어 사람의 팔꿈치, 무릎, 손목 등과 같은 관절이 핵심 포인트가 된다.
보편적인 MS COCO 데이터셋에서의 인간 자세 추정은 17개의 서로 다른 keypoint(class)를 감지할 수 있다. 각 키포인트에는 세개의 숫자(x,y,v)가 annotated된다. x,y는 target point의 좌표이고, v는 키포인트인지 아닌지 여부를 나타낸다.
(key : v=1, non-key : v=0)
"nose", "left_eye", "right_eye", "left_ear", "right_ear", "left_shoulder", "right_shoulder", "left_elbow", "right_elbow", "left_wrist", "right_wrist", "left_hip", "right_hip", "left_knee", "right_knee", "left_ankle", "right_ankle"
딥러닝 기반의 Pose Esimation
딥러닝의 최근 급격한 발전으로 인해 기존 컴퓨터 비전 분야에서 image segmentation / object detection 분야의 좋은 성과를 내왔다. 그 결과 P.E 분야에도 좋은 성과를 낼 수 있었다.
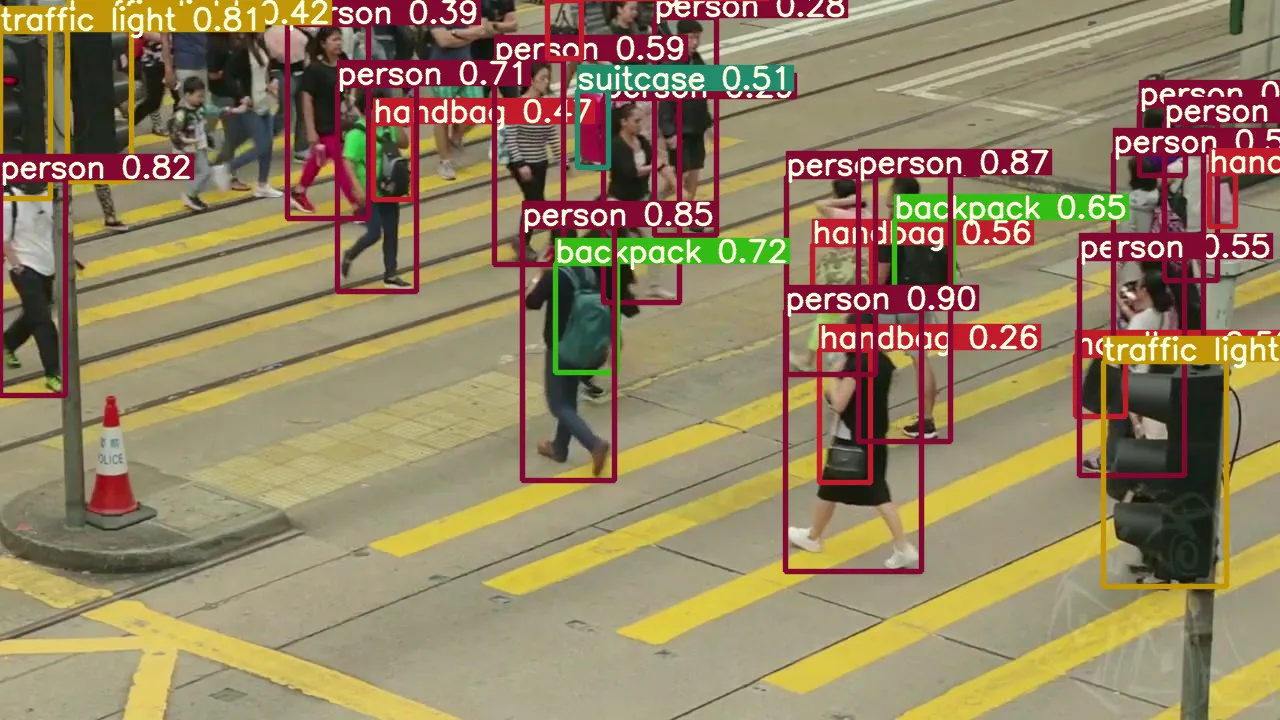
가장 유명한 Pose Estimation 기법
- Method #1: OpenPose
- Method #2: High-Resolution Net (HRNet)
- Method #3: DeepCut
- Method #4: Regional Multi-Person Pose Estimation (AlphaPose)
- Method #5: Deep Pose
- Method #6: PoseNet
- Method #7: Dense Pose
상기 기법들의 설명
포즈 추정은 비교적 쉽게 적용해볼 수 있는 비전 기술이기 때문에, 기존 아키텍처를 사용하여 맞춤형 포즈 추정기를 구현해볼 수 있다. 이를 위한 기존 아키텍쳐는 아래와 같다.
-
OpenPose
가장 유명한 bottom-up 방식의 multi-person human pose estimation 기법이다. 신체, 발, 손 및 얼굴 키포인트를 높은 정확도로 감지하는 오픈 소스 실시간 다중 사람 감지가 가능하다. OpenPose API의 장점은 사용자가 카메라 필드, 웹캠 등에서 소스 이미지를 선택할 수 있는 유연성을 제공한다는 점이다.(예를 들어 CCTV 카메라와 시스템과의 통합) CUDA GPU, OpenCL GPU 또는 GPU 전용 장치와 같은 다양한 하드웨어 아키텍쳐를 지원한다. 경량 버전은 Edge device에서 실시간으로 온디바이스 프로세싱이 가능한 edge 추론 어플리케이션으로 충분히 사용 가능하다. -
High-Resolution Net(HRNet)
인간 포즈 추정을 위한 neural network이다. 이미지에서 특정 개체 또는 사람과 관련하여 키 포인트(관절)로 알고 있는 것을 찾기 위해 이미지 처리애 사용되는 아키텍쳐이다. 다른 아키텍처에 비해 이 아키텍처의 장점은 대부분의 기존 방법이 고해상도 네트워크 사용과 관련하여 저해상도 표현에서 자세의 고해상도 표현과 일치한다는 점이다. 이 bias 대신, 신경망은 자세를 추정할 때 고해상도 표현을 유지한다. 예를 들어, TV 스포츠에서 사람의 자세를 감지하는 데에 도움이 된다. -
DeepCut
또 다른 bottom-up 방식의 multi-person human P.E기법이다. 이미지 상에서 사람의 수를 감지한 다음, 각 이미지마다의 관절의 위치를 예측한다. DeepCut은 가령 비디오 상에서의 농구, 축구 등 스포츠나 기타 상황에서 인간과 물체를 estimating하는 데에 적용할 수 있다. -
Regional Multi-Person Pose Estimation(AlphaPose)
유명한 top-down 방식의 P.E이다. 부정확한 인간 Bounding box가 있을 때 포즈를 감지하는 데에 유용하다. 즉 최적으로 검출된 바운딩 박스를 통해 인간 포즈를 추정하기 위한 최적의 아키텍쳐이다. 이미지나 영상에서 싱글 혹은 다수의 사람의 포즈를 검출하는 데에 사용될 수 있다. -
DeepPose
Deep Neural network를 활용한 human P.E이다. 모든 관절을 포착하고 pooling layer, convolution layer, fully-connected layer를 연결하여 계층의 일부를 형성한다. -
PoseNet
브라우저나 모바일 장치와 같은 가벼운 장치에서 실행하기 위해 tensorflow.js에 구축된 포즈 추정기 아키텍처이다. 따라서 PoseNet를 사용하여 단일 혹은 여러 포즈를 추정할 수 있다. -
DensePose
RGB이미지의 모든 인간 픽셀을 인체의 3D 표면에 매핑하는 것을 목표로하는 P.E 기법이다. 단일/다수의 P.E에 적용할 수 있다. -
TensorFlow Pose Estimation
-
OpenPifPaf
P.E를 위한 오픈 소스 형 컴퓨터 비전 라이브러리 및 프레임워크이다. 이미지 또는 비디오에서 인체 부위를 식별하고 위치를 파악하는 것과 관련이 있다. PyTorch 딥 러닝 프레임워크 위에 구축되었으며 multi-task learning 접근 방식을 사용하여 정확하고 효율적인 포즈 추정을 한다. 사용성이 좋으며 강건성, 어려운 P.E 시나리오(가령, occlusion, cluttered background)를 다룰 수 있기 때문에 유명해졌다.

Use Cases & Applications of Pose Estimation
가장 유명한 Pose Estimation applications
다양한 분야에서 사용된다 가령. Human-computer interaction(HCI), Action Recognition, Motion Capture, Movement analysis, Augmented reality, Sports and Fitness, Robotics.
- Application #1: Human Activity Estimation
- Application #2: Motion Transfer and Augmented Reality
- Application #3: Motion Capture for Training Robots
- Application #4: Motion Tracking for Consoles
- Application #5: Human Fall Detection

상기 applications의 설명
- Human Activity Estimation
확실한 사용처는 인간의 활동과 움직임을 추적하고 측정하는 것이다. DensePose, PoseNet, OpenPose는 종종 활동, 제스처 또는 보행 인식에 사용된다. 자세 추정을 통한 인간 활동 추적의 예는 다음과 같다.
-
앉은 제스처 감지, 손 제스처 인식 또는 얼굴 표정 분석을 위한 애플리케이션
-
운동 선수에 대한 AI 기반 분석
-
댄스 기술 분석을 위한 애플리케이션(예: 발레)
-
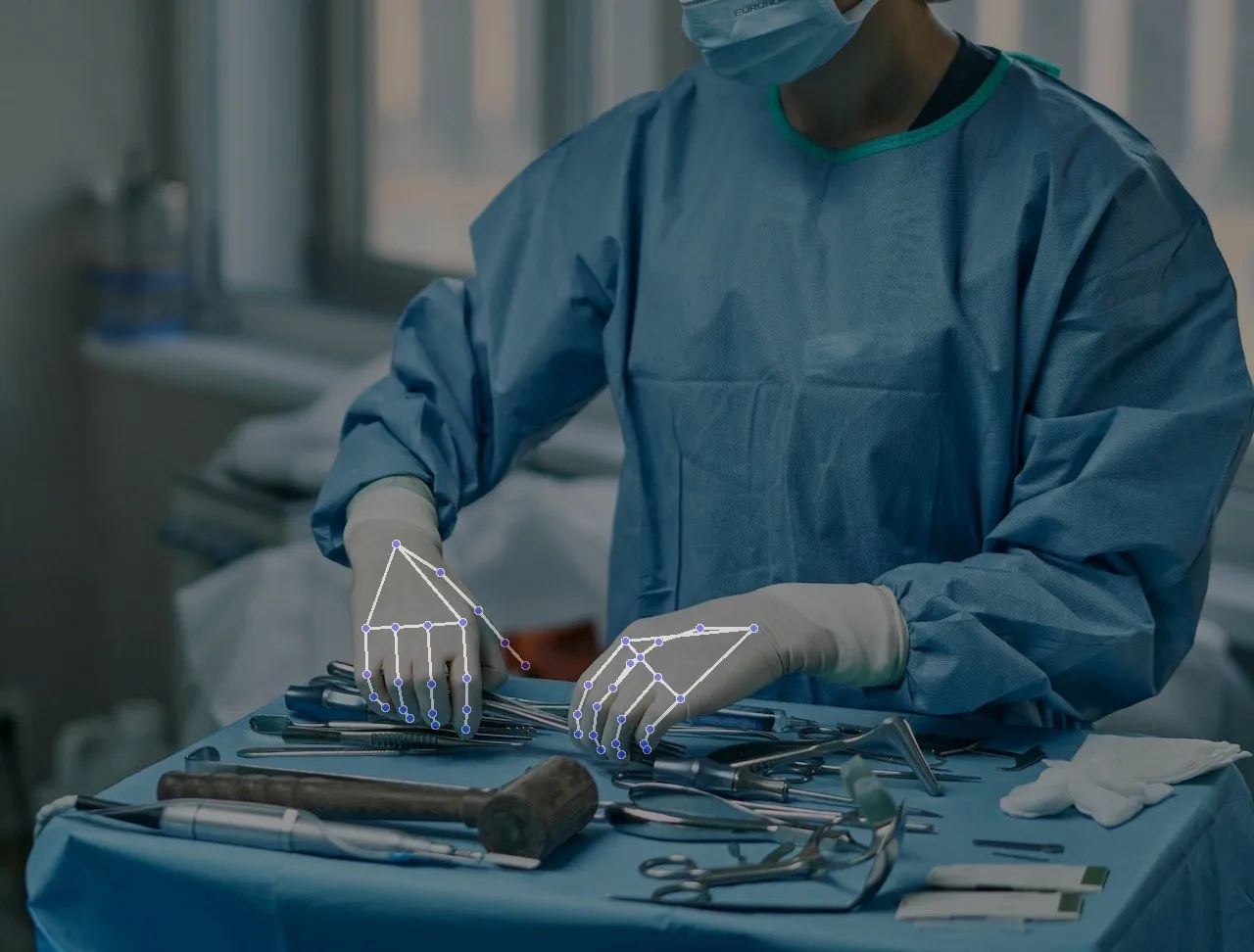
의료 수술 서비스의 품질을 평가하기 위한 컴퓨터 비전 시스템
-
운동의 실행 형태를 감지학 반복 횟수를 카운트하는 피트니스 어플리케이션
-
전신/ 수화 커뮤니케이션(예 : 교통 경찰 신호)
-
넘어지는 사람의 감지 혹은 특정 질병의 진행과정을 감지하는 지능형 어플리케이션
-
Augmented Reality and Virtual Reality
현재 AR/VR에 반영된 P.E기술은 사용자들에게 더 나은 온라인 경험을 제공하고 있다. 예를 들어 사용자는 포즈를 취하는 가상 튜터를 통해 테니스를 배우는 사례가 있다.또한 포즈 추정기는 증강 현실 기반 응용프로그램과 인터페이스할 수도 있다. 예를 들어 미 육군은 전투에 사용할 증강 현실 프로그램을 실험하기도 한다. 이 프로그램은 병사들이 피아식별을 하고 야간 시력을 향상시키는 것을 목표로 한다고 한다.

-
Training Robots with Human Pose Tracking
포즈 추정기의 일반적인 사용 사례는 로봇이 특정 기술을 배우도록 하는 어플리케이션에 있다. 궤적을 따르도록 수동으로 로봇을 프로그래밍하는 대신 로봇이 교사의 자세, 외모나 외형을 따라하여 행동을 배우도록 할 수 있다.
-
Human Motion Tracking for Consoles
게임 내 응용 프로그램으로도 사용할 수 있다. 인간이 대화형 게임 경험을 위해 게임 환경에 포즈를 자동 생성하고 주입하게 된다. 가령, Microsoft는 3D 포즈 추정(IR Sensor사용)을 사용하여 인간 플레이어의 동작을 추정하고 이를 사용하여 캐릭터의 동작을 게임 환경에 가상으로 렌더링했다.
Reference
#1: https://ctkim.tistory.com/101
#2: viso.ai
