[Deep Learning Specialization]Improving Deep Neural Networks-Practical aspects of Deep Learning

2nd course: Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization
🗂 목차
1장: Practical aspects of Deep Learning
2장: Optimization algorithms
3장: Hyperparameter tuning, Batch Normalization and Programming Frameworks
1. Practical aspects of Deep Learning
1st course에서는 neural network, 인공신경망을 구현하는 법에 대해서 배웠다면 2nd course인 Improvng Deep Neural Networks에서는 신경망이 보다 좋은 성능을 낼 수 있는 문제에 대해 다뤄보고자 한다. 인공신경망의 성능 최적화 및 향상을 위한 데이터 셋 준비부터 regularization, hyperparameter 튜닝까지 다양한 접근법에 대해서 소개하고 있다.
각 접근법의 작동 알고리즘에 대해서 어느정도 이해하고 있다면 과제의 목적 혹은 목표, 데이터의 특징에 따라 최선의 결과를 이끌어내기 보다 수월할 것으로 생각한다.
1. Train / Dev / Test sets
-
먼저 train / dev / test와 같은 데이터 셋을 잘 구축하면 좋은 성능을 갖는 neural network를 찾는 것에 도움이 됨
-
neural network을 구현할 때에는, layer의 수, hidden unit의 수, learning rate, activation function 등과 같은 결정해야할 hyperparameter가 많기 때문에 반복적인 과정을 거칠 수 밖에 없음
-
이러한 반복적인 과정을 거치는 것이 필수불가결할 때, 데이터를 적절하게 train / dev / test 로 나눔으로써 보다 효율적으로 수행할 수 있음
- train, 즉 학습 과정에서 사용된 데이터로 검증을 하게 되면 이미 데이터가 반영된 상태에서 신경망이 구성되어 있기 때문에 항상 좋은(overfitting)된 결과만을 보여주게 됨
-
일반적으로 기계학습에서는 train / test 을 70:30, train / dev / test 을 60:20:20 으로 나누게 됨
-
하지만 빅데이터 시대에 돌입하게 되면서, 다루고자하는 데이터는 수백만개를 넘어서기 때문에 dev와 test 데이터가 20%, 30%의 비율이라면 매우 큰 부분을 차지하게 됨
- dev와 test 데이터는 train 데이터로 학습된 알고리즘을 평가하기 위한 데이터이기 때문에 백만개 이상의 데이터를 보유하고 있다면 dev와 test 데이터를 전체 데이터의 1% 혹은 그 이하의 비율만으로 구성하기도 함
2. Bias / Variance
- 데이터가 학습되는 과정 속에서는 train 데이터가 모집단을 모두 반영할 수 없기 때문에 bias(편향)와 variance(편차)가 발생하는 것이 일반적임
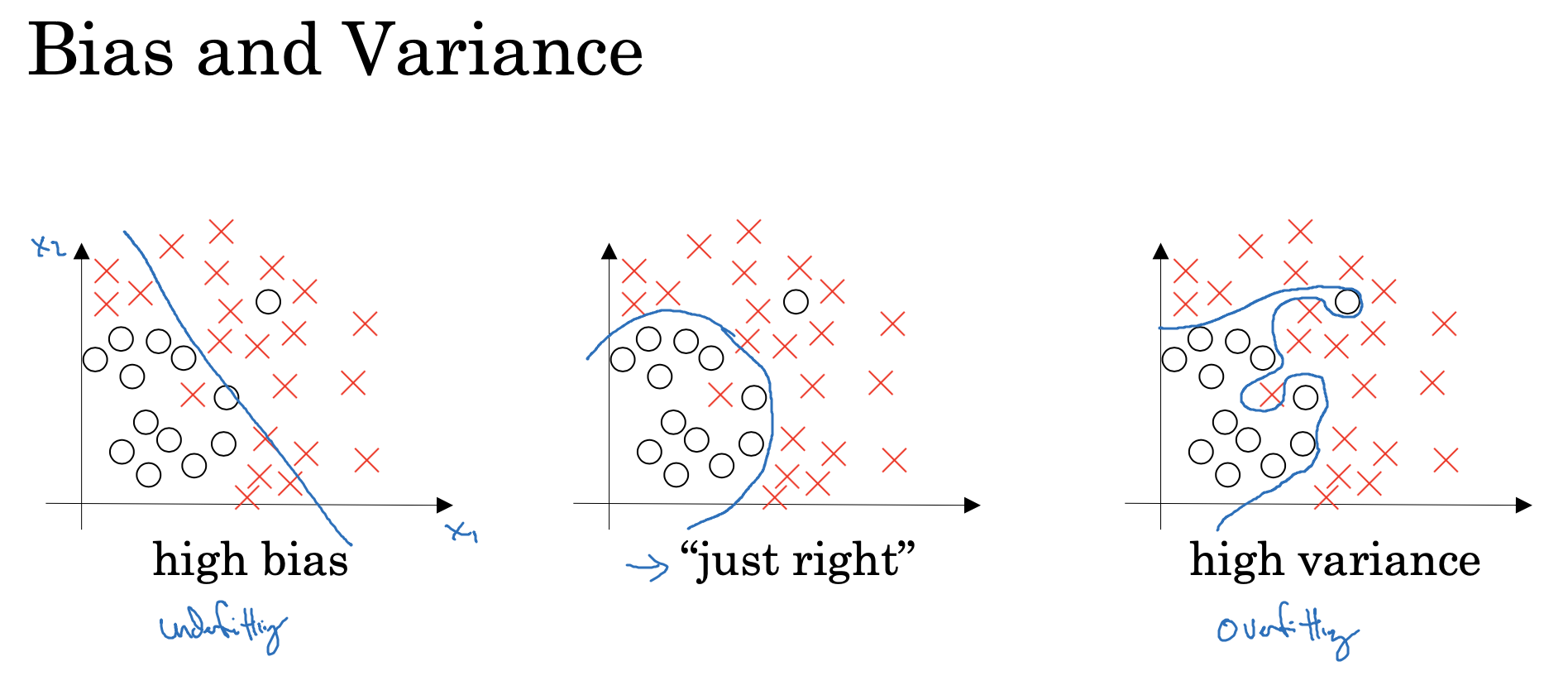
-
간단하게 logistic regression의 학습 결과로 위와 같은 3가지 결론이 도출될 수 있음
-
먼저, 좌측 결과는 학습이 제대로 되지 않아 underfitting된 문제가 발생하며, 이를 high bias(높은 편향)이라고 함
-
반대로, 우측 결과는 데이터를 완벽하게 fitting함으로써 정확하게 분류할 수 있지만 overfitting 문제가 발생할 가능성이 높으며, 이를 high variance라고 함
-

-
deep neural network에서는 train / dev / test 데이터의 error 비율을 통해 bias와 variance 문제를 확인해볼 수 있음
-
주어진 이미지에서 고양이를 classification하는 문제로 가정했을 때, 사람이 직접 판단하는 경우는 대부분 정확하기 때문에 human error는 0%에 가까움
-
train / dev 의 error가 1% / 11% 라고 한다면 train 데이터에만 overfitting된 high variance 문제를 확인할 수 있음
-
train / dev의 error가 15% / 16% 라면, train과 dev에 모두 맞지 않게 학습된 것이기 때문에 underfitting된 high bias 문제를 확인할 수 있음
-
train / dev의 error가 15% / 30% 라면, 두번째 경우처럼 high bias 문제뿐만 아니라 train에 overfitting된 문제도 포함되는 high variance까지 나타나는 가장 안좋은 결과를 말함
-
train / dev의 error가 0.5% / 1% 라면 human error와 비교했을 때에도 굉장히 정확하게 분류한 model이라고 볼 수 있음
-
-
하지만 train / dev의 error 비율을 통한 bias와 variance 문제는 데이터와 모델의 특징, Human error, Optimal Error에 따라 상대적으로 달라지기 때문에 신중한 분석이 필요함
3. Basic Recipe for Machine Learning
-
train / dev의 error를 통해서 bias와 variance 문제를 확인할 수 있는 방법은 기계학습의 baic recipe(기본적인 방법?)이며 이 과정을 통해 알고리즘의 성능을 향상 시킬 수 있음
-
좌측 결과였던, high bias의 경우에는
- neural network를 더 쌓거나,
- layer의 node를 증가시키거나,
- epoch을 증가함으로써 더 오래 학습하거나,
- 보다 최적화된 알고리즘을 적용할 수 있음
-
우측 결과였던, high variance의 경우에는
- 더 많은 데이터를 train 데이터로 사용하거나,
- regularization을 시도할 수 있음
-
-
딥러닝 초기에는 bias와 variance는 약간의 trade-off 관계라고 생각되었지만 최근에는 보다 deep한 neural network를 학습할 수 있는 환경이 가능해지면서 bias와 variance를 모두 줄일 수 있음
4. Regularization
-
위에서 overfitting된 high variance 문제를 해결하기 위한 방법으로 Regularization이 제안되었음
-
logistic regression에 Regularization을 적용하기 위해서는 cost function 좌측에 Regularization 항을 추가하게 됨
-
Regularization의 목적은 반복적으로 발생하는 cost에 영향을 미치는 w(weight)가 보다 적은 영향을 미치도록 조정해주는 역할을 함
- Regularization에는 자주 비교되는 L1 Regularization과 L2 Regularization가 있으며, L1 Regularization보다는 L2 Regularization를 일반적으로 더 많이 사용함
-
Neural Network에 적용되는 Regularization은 각 layer에 위치하게 되면서 backpropagation 과정에서 업데이트되는 parameter에 영향을 미치게 됨
- L2 Regularization을 통해 parameter가 업데이트되는 과정에서 해당 가 가져야할 원래의 영향력이 로 감소되기 때문에 'weight decay, 가중치 감쇠'라고도 함
5. Why regularization reduces overfitting?
-
위에서 L2 Regularization은 'weight decay'라고 불리는 이유로 영향을 확인할 수 있음
-
위 식에서 를 설정해줌으로써 에 대한 영향력을 조정해줄 수 있음
-
를 크게 설정하게 되면, 은 0에 가깝게 수렵하게 됨
-
아래 우측 결과, high variance 상태에서 L2 Regularization을 적용하게 해주면 좌측 상단의 그림처럼 각 hidden unit의 의 영향력이 줄어들고 variance가 줄어드는 현상을 볼 수 있게 됨(약간 그림은 dropout과 비슷하다는 느낌이 듦)
-
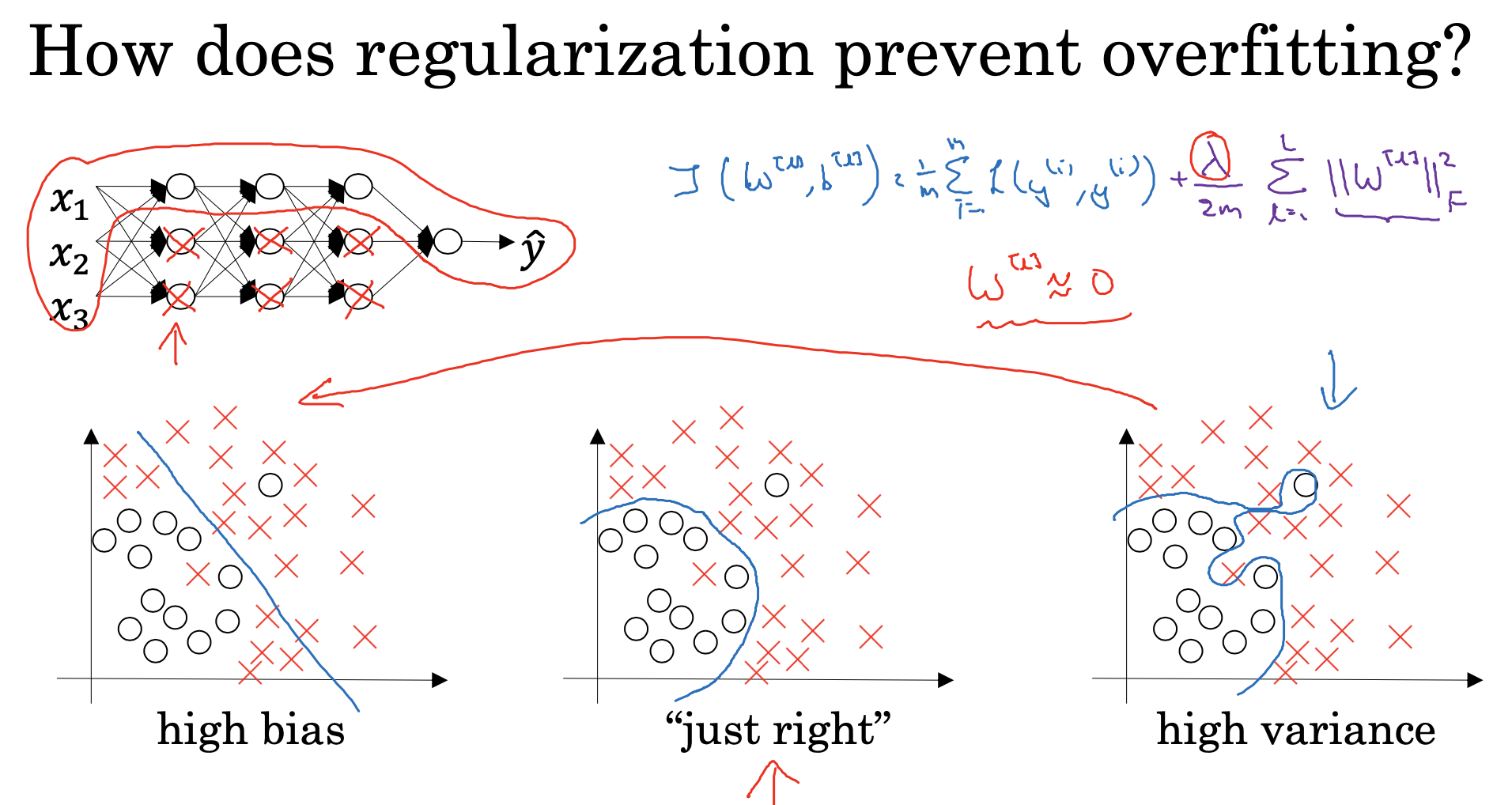
6. Dropout Regularization
-
L1, L2 Regularization에는 이외로 dropout이라 불리는 Regularization도 존재함
-
dropout은 의 영향력을 줄이는 L1, L2와는 달리, 특정 node를 생략함으로써 아예 로 발생하는 계산의 과정을 줄이는 것임
-
node를 생략하는 과정에서는 실제로 무작위로 node를 생략하기 위해서 keep-prob이라는 개념이 등장함
-
keep-prob은 무작위로 node를 생략하고 남은 node의 비율을 의미함
-
만약 keep-prob이 1이라면, dropout, 생략할 node가 없다는 것을 의미함
-
-
dropout 중 가장 흔하게 사용되는 Inverted dropout가 구현되는 과정은 다음과 같음
-
특정 layer의 차원만큼 random initialize를 생성해줌
-
keep-prob(0.8)를 설정하고 해당 keep-prob보다 작은 경우는 설정된 0.8의 keep-prob만큼의 노드가 True를 가지게 되고 0.2만큼의 노드가 False를 가지게 됨
-
layer의 노드와 keep-prob로 설정된 True/False를 곱해줌으로써 남아있거나 생략되는 노드들을 확인할 수 있음
-
마지막으로는 살아남은 노드들에 대해서 keep-prob를 나눠줌으로써 해당 layer의 expected value를 동일하게 유지해줌
-
-
assignment에서 나온 코드를 간단히 살펴보자면 다음과 같음
D1 = np.random.rand(A1.shape[0], A1.shape[1]) # Step 1: initialize matrix D1 = np.random.rand(..., ...)
D1 = (D1 < keep_prob).astype(int) # Step 2: convert entries of D1 to 0 or 1 (using keep_prob as the threshold)
A1 = np.multiply(A1, D1) # Step 3: shut down some neurons of A1
A1 = np.divide(A1, keep_prob) # Step 4: scale the value of neurons that haven't been shut down7. Understanding Dropout
-
dropout이 Regularization 효과가 나타나는 이유는 무작위로 node를 제거함으로써 neural network의 크기를 줄이는 결과를 얻을 수 있기 때문임
-
dropout을 구현하기 위해 keep-prob를 설정하는 것은 각 layer마다 다르게 설정 가능하며, keep-prob를 높게 설정하는 것은 L2 regularization에서 를 높게 설정하는 것과 동일함
- dropout은 보통 학습 데이터가 충분하지 않았던 computer vision에서 주로 사용한 테크닉으로 overfitting을 방지할 수 있었음
-
반면에 dropout의 단점으로는 cost function이 정확하게 정의되지 않는다는 점과 무작위라는 점에서 성능 체크 및 디버깅이 힘들기도 함

8. Understanding Dropout
-
Regularization을 할 수 있는 추가적인 방법으로 Data Augmentation과 Early Stopping과 같은 기법들이 있음
-
Data Augmentation은 image classification에서 주로 사용되는 기법임
-
가지고 있는 데이터에서 좌우반전, 확대, 축소, 회전, 늘림 등의 방법을 통해 다른 형태의 데이터로 인식하도록 변화를 주는 방법임
-
하지만 이러한 방법으로 생성된 새로운(가짜) 이미지는 실제 새로운 데이터를 구하는 것보다는 좋은 효과를 볼 수 없겠지만 cost가 없는 방법임
-
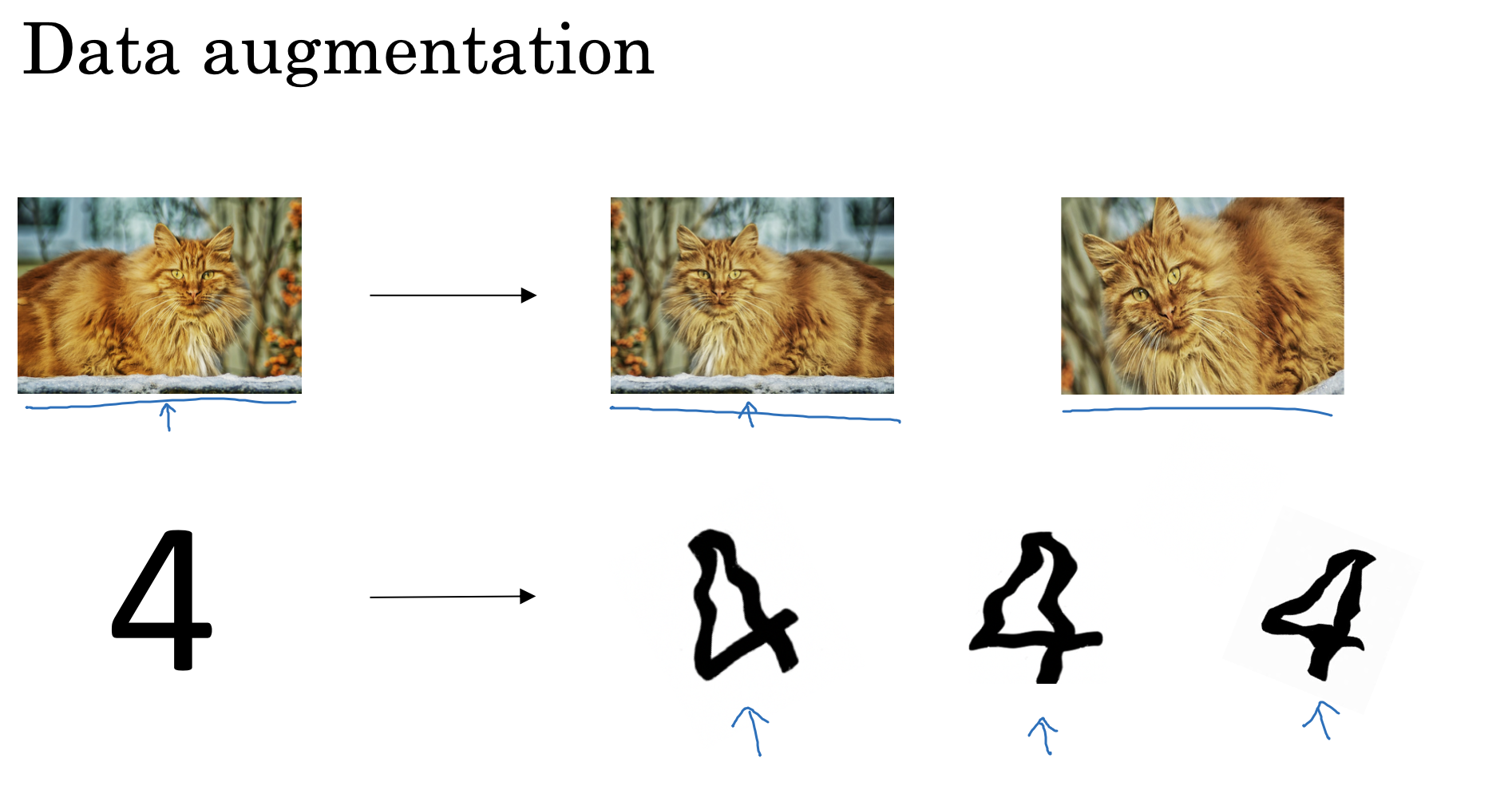
-
Early Stopping은 학습이 진행되는 과정을 모니터하면서 원래 설정한 종료 시점보다 일찍 종료함으로써 overfitting을 방지하는 기법임
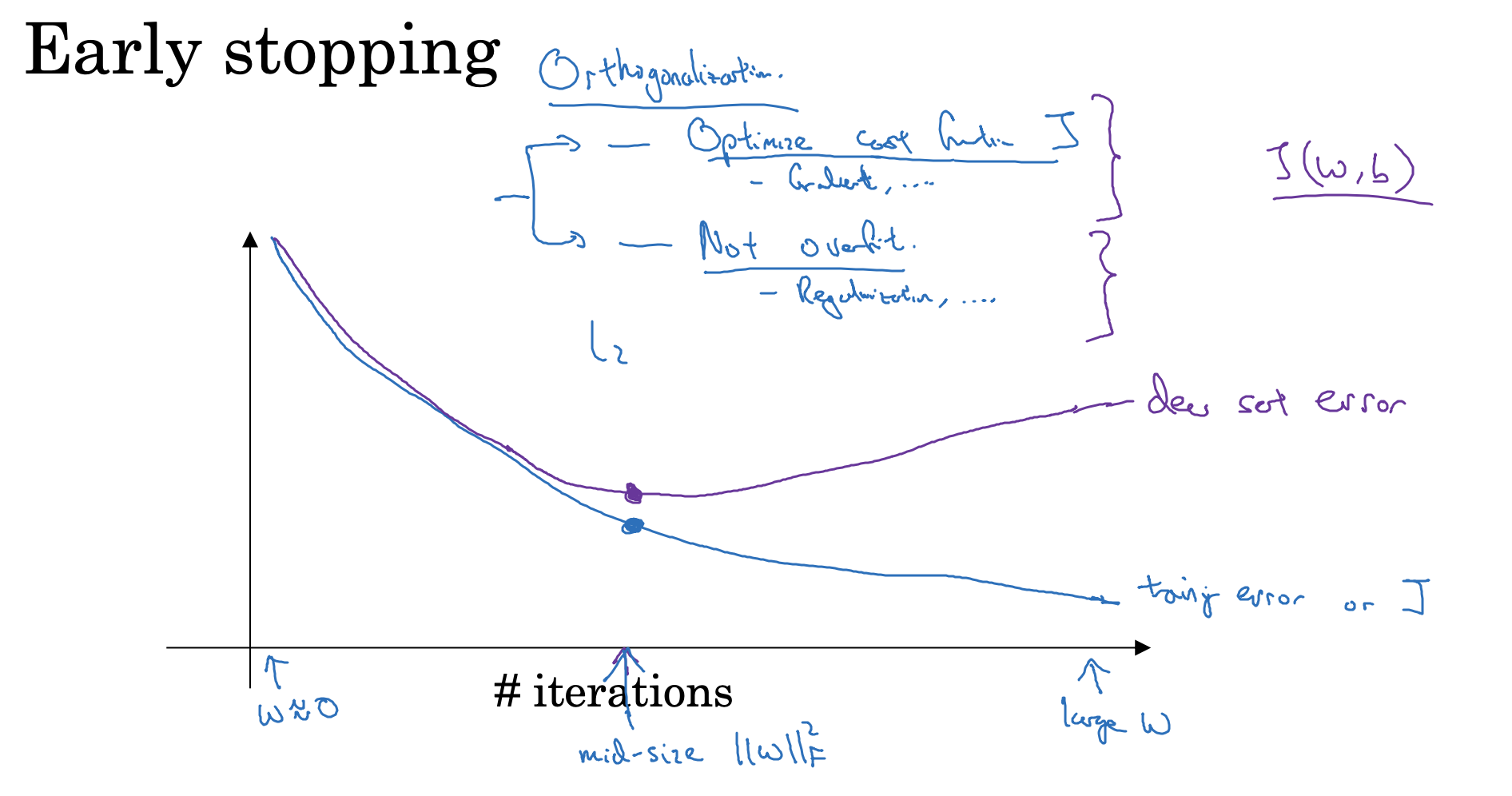
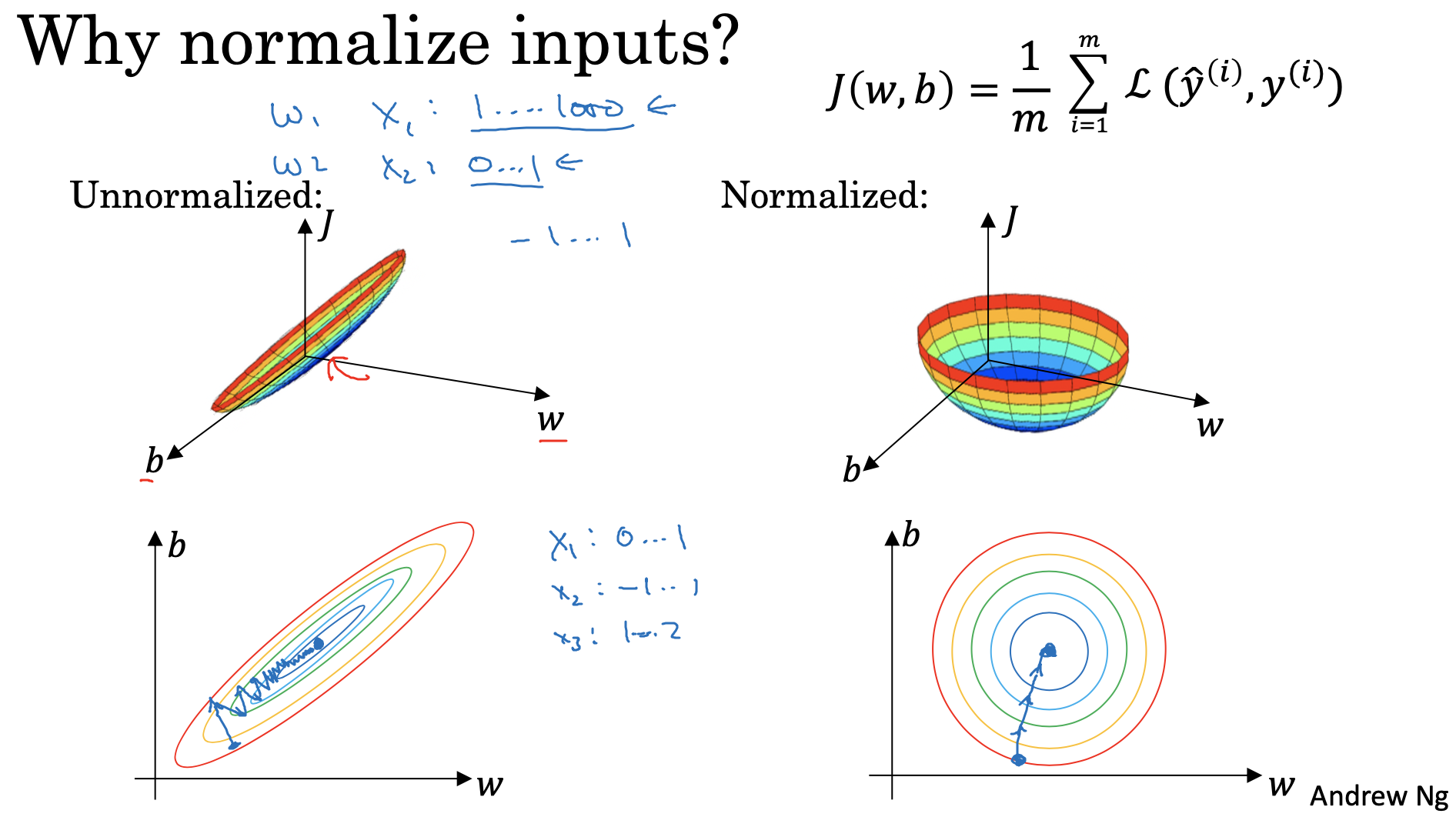
9. Normalizing inputs
-
Neural Network의 학습을 보다 최적화할 수 있는 방법으로 input 데이터를 normalize 할 수 있음
-
데이터를 normalize 할 수 있는 방법은 기존 머신러닝 데이터를 normalize 하는 것처럼, 평균을 빼주거나, 평균을 0으로 만들어주거나, 분산을 사용하여 normalize 할 수 있음
-
이렇게 normalize를 해주는 이유는, input 데이터의 scale이 다를 때, 학습하고 parameter를 업데이트를 해주는 과정에서 서로 다른 scale에 대한 parameter가 적용되어 gradient가 다르기 때문에 매우 느리게 반복 과정을 거치기 때문임
-
normalize를 하게 되면 모든 input 데이터의 scale이 같고, 그에 따른 parameter가 미치는 영향의 범위가 동일하기 때문에 gradient descent 과정이 보다 효율적으로 진행됨
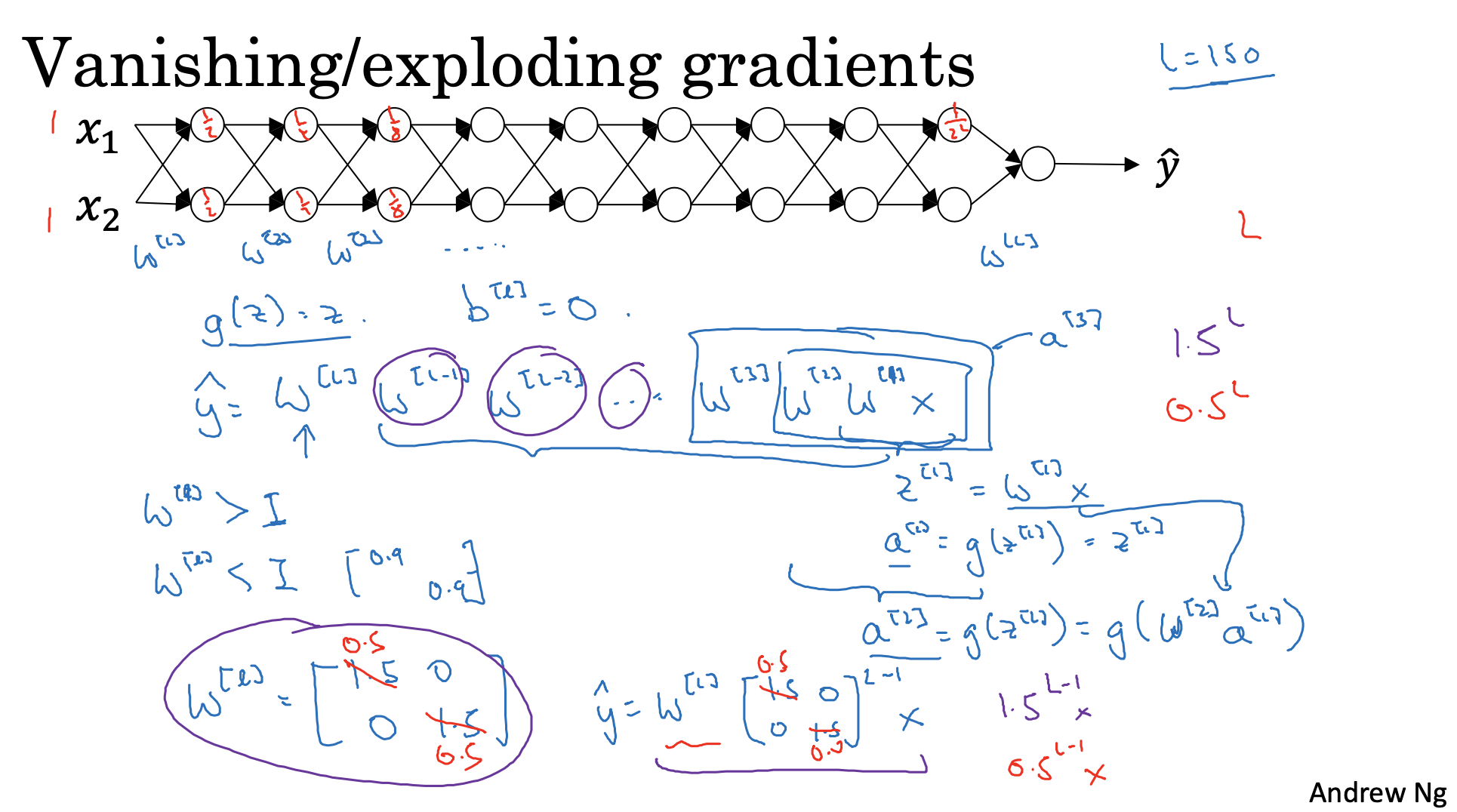
10. Vanishing / Exploding gradients
-
deep neural network에서는 학습하는 과정에서 기울기값, 즉 변화량이 매우 크거나 작게 수렴하는 문제를 Exploding / Vanishing gradients problem이 발생함
-
layer에 수만큼 곱해지는 가 기하급수적으로 증가하거나 0에 수렴할 정도로 계속해서 작아질 수 있기 때문에 발생함
-
특히 기울기가 계속해서 작아질 경우에는, gradient 변화량이 매우 작기 때문에 업데이트를 위한 학습 과정이 매우 느리게 작동됨
-
11. Weight Initialization for Deep Networks
-
이렇게 gradient가 소실되거나 증폭되는 문제를 방지하기 위해서 Weight Initialization을 설정해 줄 수 있음
-
하나의 계산에 여러 개의 가 들어오게 되면 는 자연스럽게 증가할 수 밖에 없기 때문에 각 를 normalize하는 것처럼 조정해줄 수 있음
-
activation function에 따라서 Weight Initialization를 조금씩 다르게 설정하는 것이 보다 효과적임
-
Relu 일 때는,
-
tanh 일 때는, 혹은
-

12. Numerical approximation of gradients
-
backpropagation을 할 경우에는, 해당 과정이 정확하게 이뤄졌는지 확인하기 위해 gradient checking 작업을 실시할 수 있음
-
gradient checking은 말그대로 미분값, 변화량을 비교하는 것인데 산술적으로 기울기를 구하는 방법으로는 여기서 'one-sided difference' 와 'two-sided difference'가 소개됨
-
one-sided difference:
-
two-sided difference:
-
-
two-sided difference 방법이 변화량 값에 대한 오차가 보다 작기 때문에 gradient checking을 할 때에는 해당 방법을 선호함
13. Gradient checking
-
gradient checking을 통한 디버깅은 버그를 찾아줌으로써 전체 개발 시간을 효율적으로 줄여줄 수 있는 방법임
-
gradient checking 과정은 backpropagation에서 발생하는 변화량과 해당 지점에서 계산되는 기울기값을 비교함으로써 오차를 확인하여 버그를 발견하는 과정임
-
backpropagation에서 구한 와 two-sided difference를 통해 구한 를 비교하게됨
-
오차를 통해 버그를 확인하는 방법으로는, 오차가 보다 작게 되면 만족할만한 결과이며, 이면 다른 요소에 따라 다시 확인해 볼 필요가 있으며, 보다 크게 되면 버그가 있을 가능성이 높음
-
14. Gradient Checking Implementation Notes
-
gradient checking을 적용하기 할 때, 몇 가지 주의 사항이 있음
-
Don’t use in training – only to debug: 미분 근사를 구하는 일은 상당히 느린 작업이기에 학습(training)시에는 사용하지 않음
-
If algorithm fails grad check, look at components to try to identify bug: 오차가 크게 발생했다면, 각각의 component를 비교해서, 문제되는 component를 찾을 수 있으며 오류를 발견할 수 있음
-
Remember regularization : regularization을 사용한다면, cost function(J)에 lambda 식이 더해지므로, 미분 근사치와 비교할 때 처리해 주어야 함
-
Doesn’t work with dropout: dropout을 하게 되면, J함수가 쓰기가 무척 까다로워짐. keep-prob를 1로 설정하여 dropout을 끄고 grad checking을 진행함
-
Run at random initialization; perhaps again after some training: random 초기화를 하는 경우에는, 학습을 통해 W,b를 업데이트한 이후에 grad checking을 진행함
-
