[논문]Deep Neural Networks for YouTube Recommendations(2016, Paul Covington)
📄 Deep Neural Networks for YouTube Recommendations(2016, Paul Covington)
0. 포스팅 개요
최근 많은 사람들에게 추천 시스템의 관심이 증가하고 있는 현상에 가장 많은 영향을 끼친 것을 꼽으라면 단연코 '넷플릭스'와 '유튜브'일 것이다. 특히 '유튜버'라는 직업이 새로 생겨날정도로, 전세계적으로 많은 사람들이 이용하고 있는 유튜브는 수많은 영상 콘텐츠를 우리에게 실시간으로 제공하고 있다. 이 과정에서 소비자에게 영상 콘텐츠를 보여주는 행위를 일컫는 '유튜브 알고리즘'에 대한 궁금증과 관심이 엄청나게 증가하고 있는 것을 보면 많은 사람들이 생각보다 만족하고 있는 것 같다.
유튜브는 2010, 2016, 2019년에 유튜브 추천 시스템 관련 내용을 발표했으며 오늘 리뷰하게 될 논문은 2016년에 발표된 Deep Neural Networks for YouTube Recommendations이다. 추천 시스템은 (1)candidate generation, (2)scoring, (3)re-ranking의 과정을 기본적인 구조로 가지게 되는데, 유튜브의 추천 시스템이 이러한 기본적인 구조를 가장 잘 보여주는 것 같다.
유튜브라는 주제가 워낙 흥미롭고 익숙하다보니 논문을 읽을 때, 생각보다 재밌게(?) 읽을 수 있었다. 복잡한 수식이 나오지 않고 유튜브가 현실적으로 고려해야할 항목들에 대한 내용들이 있었기에 보다 수월했던 것 같다.
ABSTRACT
-
유튜브는 현재 매우 큰 규모와 복잡한 추천 시스템을 보여주고 있는 산업 중 하나임
-
이 논문에서는 딥러닝을 사용하여 추천 시스템의 성능을 향상시킨 것에 대해 다루며, 2가지 기본 구조를 따르고 있음
-
첫번째는 deep candidate generation model이며, 두번째는 separate deep ranking model임
-
또한, 추천 시스템 설계 및 학습, 서빙 과정에서 얻게 된 현실적인 깨달음과 인사이트에 대해서도 언급할 예정임
-
1. INTRODUCTION
-
유튜브는 계속해서 올라오는 새로운 영상 콘텐츠들로부터 수억명의 사용자들에게 개인화된 콘텐츠를 제공하기 위한 미션을 항상 가지고 있음
-
특히 3가지 측면에서 유튜브는 항상 도전하고 있음
-
Scale
- 계속해서 새로운 기술의 추천 알고리즘이 발표되고 있지만 수많은 사용자와 영상 콘텐츠가 존재하는 유튜브에 적용할 수 있는 추천 알고리즘은 많지 않음
- 높은 규모의 scale과 latency를 고려한 효율적인 추천 알고리즘을 적용할 수 있는 방법을 항상 강구해야함
-
Freshness
- 유튜브에는 매 초마다 수만개 이상의 영상 콘텐츠가 새롭게 업로드 되고 있음
- 또한, 새로운 영상 콘텐츠에 따른 사용자의 반응도 실시간으로 발생하고 있으며, 추천 시스템에서는 이러한 실시간 반응 요소들을 적절하게 적용 및 반영할 수 있는 방법을 찾아야함
-
Noise
- sparsity와 보이지 않는 외부 요인 때문에 사용자의 행동을 예측하기란 쉽지 않음
- 사용자 만족도에 대한 explicit feedback을 구하기 굉장히 힘들기 때문에 implict feedback을 사용하게 되며, 메타데이터가 잘 구축되지 않기도 함
-
-
유튜브 또한 거의 모든 학습 분제를 딥러닝을 사용하는 파라다임으로 바꾸고 있으며 Google에서 제공하고 있는 TensorFlow를 기반으로 하고 있음
-
Matrix Factorization에 대한 많은 연구가 진행되었던 반면에, 추천 시스템에서 딥러닝을 활용한 연구는 상대적으로 적었음
-
딥러닝을 활용한 추천 시스템에 관한 이번 논문에서 목차는 다음과 같음
- Section 2: 전체적인 시스템에 대한 간단한 개요
- Section 3: candidate generation model에 대한 구체적인 설명
- Section 4: ranking model에 대한 구체적인 설명
- Section 5: 결론 및 시사점
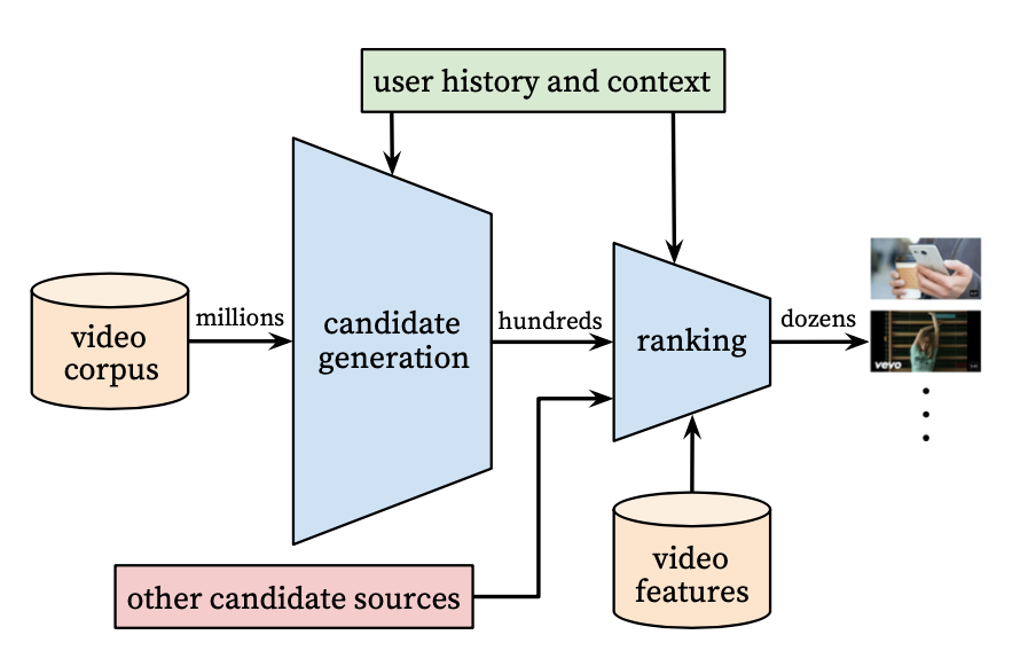
2. SYSTEM OVERVIEW

-
위 그림에서 알 수 있듯이, 유튜브 추천 시스템은 크게 candidate generation model과 ranking model인 2단계로 구성되어 있음
-
candidate generation model
-
해당 단계에서는 사용자의 유튜브 행동 기록들을 사용해서 모든 영상 중에서 해당 사용자에게 어느정도 개인화된 영상들로 후보를 만들어주는 과정임
-
Collaborative filtering을 적용하여 어느정도 개인화가 적용된 상태에서, 영상 콘텐츠와 검색어, 그리고 인구통계학 정보로 사용자간 유사도를 계산함
-
-
ranking model
-
best 추천 리스트를 만들기 위해서는 후보군들에서 높은 점수를 받은, 상대적으로 중요한 아이템을 구별하는 것이 중요함
-
ranking network에서는 영상 콘텐츠와 사용자의 보다 많은 feature를 사용해서 각 아이템에 점수를 매기고 순위를 부여하게 됨
-
-
2단계의 추천 알고리즘 과정을 거치면서 수많은 영상 콘텐츠를 개인화된 영상 콘텐츠 후보군으로 좁힐 수 있게 됨
-
개발 과정에서는 precision, recall, ranking loss 등과 같은 광범위한 offline metrics를 구축하여 성능을 향상 시킴
-
하지만, 실제 환경에서의 A/B 테스트를 통해 최종 알고리즘의 효율성을 결정하며 이 때, CTR, 시청 시간 등과 같은 사용자의 행동을 측정할 수 있는 다른 방법들을 측정할 수 있음
-
offline metrics 결과와 A/B 테스트 결과가 항상 일치하는 것은 아니기 때문에 실제 환경에서 이뤄진 A/B 테스트 결과로 최종 알고리즘을 결정하는 경향이 있음
-
3. CANDIDATE GENERATION
-
candidate generation, 후보 생성 단계에서는 엄청난 규모의 영상 콘텐츠에서 사용자와 관련된 몇 백개의 영상으로 후보군을 만드는 작업이 진행됨
-
이전에는, rank loss를 기반으로 한 matrix factorization 방법론이 사용되었으며, 사용자의 과거 시청 기록 임베딩과 간단한 인공신경망으로 해당 과정을 시도해보기도 하였음
-
이 관점에서 보면, 이러한 접근은 factorization의 non-linear generalization로 볼 수 있다고 함
3-1. Recommendation as Classification
-
사용자(U)와 Context(C)를 기반으로 특정 시간(t)에서 수백만개의 아이템(V) 중 각 아이템(i)의 시청 class를 예측하는 multiclass classification으로 추천 문제를 정의할 수 있음
-
사용자(U)의 u는 사용자의 임베딩을 의미하며, 아이템(V)의 v는 각 후보 영상 콘텐츠의 임베딩을 의미함
-
사용자의 기록과 context의 역할을 하는 u 벡터를 학습으로 후보 아이템의 시청 확률을 예측하는 softmax classifier임
-

-
유튜브에는 explict feedback이 존재하지만, 사용자가 시청 완료한 영상 콘텐츠를 positive로 분류하여 implicit feedback을 학습함
-
explicit feedback은 굉장히 sparse하기 때문에, 사용자의 implicit한 기록을 보다 활용하고 좀 더 deep한(?) 추천을 하기 위해서 implicit feedback을 사용함
Efficient Extreme Multiclass
-
softmax classification의 개수가 늘어남에 따라 효율적인 학습을 가능하게 하기 위해서, negative sampling을 시도함
-
모델 serving을 위해서는, 사용자에게 Top N개의 아이템을 추천하기 위한 N 클래스를 계산하는 과정이 진행됨
- 수만개의 아이템을 점수화하는 serving latency를 줄이기 위해서 hashing을 사용하여 sublinear하게 해결했고, 이번에도 비슷한 방법을 적용함
3-2. Model Architecture

-
정해진 vacabulary(각 영상 콘텐츠의 내용을 의미하는 것으로 생각됨)로 이루어진 각 아이템의 임베딩을 구함
-
사용자의 시청 기록은 위에서 임베딩된 아이템 벡터를 사용하여 임베딩할 수 있으며, 이 때 고정된 차원이 요구됨으로 다양한 시도 끝에, 시청한 아이템 벡터의 평균을 적용하게 됨
-
wach vector(시청 기록), search vector(검색 기록), geographic embedding(지리 정보), example age, gender 등을 모두 concat하여 사용자 벡터인 u를 구할 수 있게 됨
3-3. Heterogeneous Signals
-
MF를 인공신경망으로 사용하는 가장 핵심 이점은 다양한 continuous와 categorical features를 모델에 쉽게 추가할 수 있다는 것임
-
검색 기록(search history)는 시청 기록과 유사하며, unigrams이나 bigrams을 활용하여 임베딩할 수 있음
-
인구통계학정보는 새로운 유저에게 합당한 추천을 하기 위한 중요한 feature이며 지리적 정보, 접속 device, 성별, 나이 등 또한 임베딩되어 들어감
-
"Example Age" Feature
-
유튜브에는 매 초마다 '새로운' 아이템들이 업로드 되며, 사용자들은 '새로운' 아이템을 보통 선호나는 것으로 관측되기 때문에 추천에 있어 '새로운' 아이템은 굉장히 중요함
-
하지만 머신러닝 시스템에서는 과거 데이터를 바탕으로 미래의 행동을 예측하는 것이기 대문에 종종 과거의 아이템(past)에 대한 결과를 보여주는 경향(bias)이 종종 있음
-
앞서 언급했듯이, 시청 기록에 있어 아이템 벡터의 평균을 적용하기 때문에 시간적 요소에 대한 sequence가 반영되지 않는데, 이를 보정하기 위해서 아이템의 나이, 즉 영상 콘텐츠의 Age에 해당하는 feature를 추가하게 됨
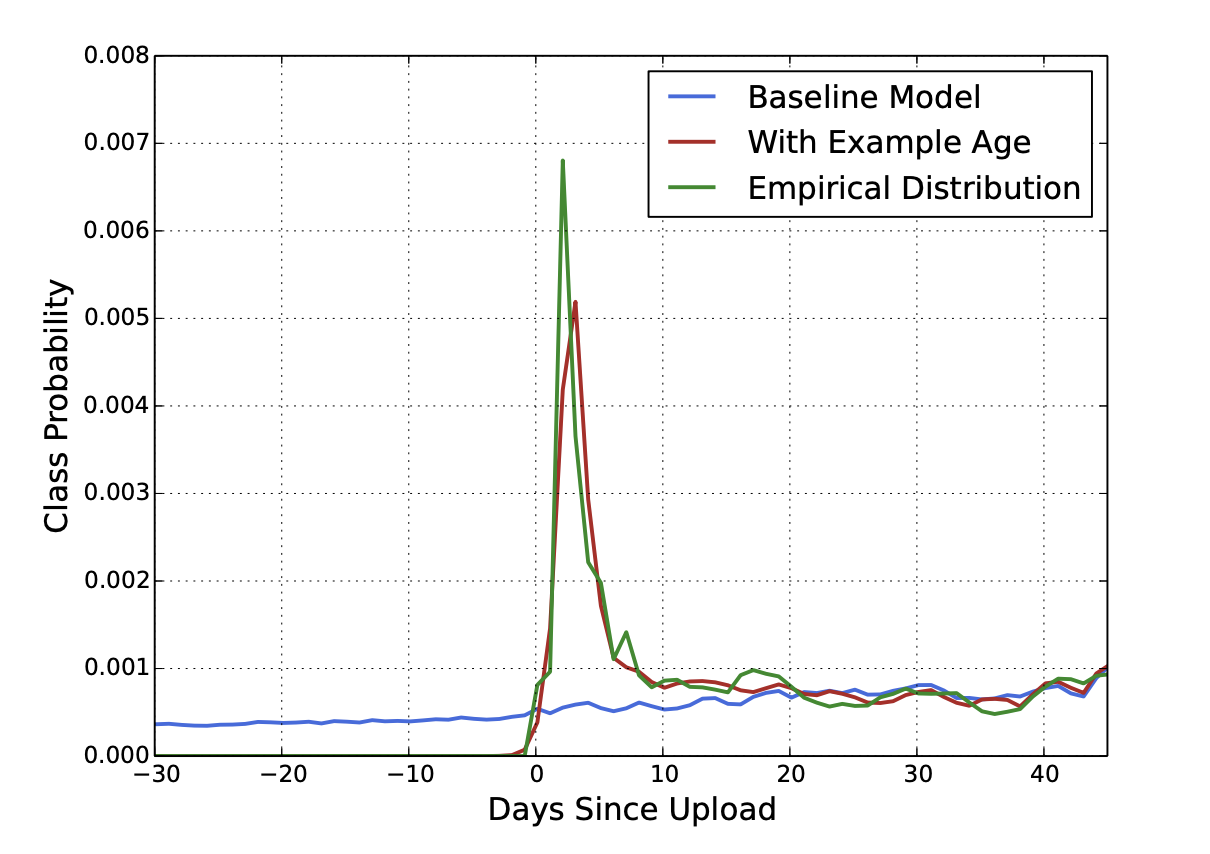
- 'Example Age'를 적용하게 된 모델의 성능을 보면 baseline 모델보다 엄청난 성능 향상을 보이는 것을 알 수 있음
3-4. Label and Context Selection
-
추천 시스템은 대부분 surrogate problem가 발생함
*surrogate problem: 개발한 추천 엔진에 대한 평가는 직접 서빙하여 사용자로부터 피드백을 받는 것이지만 항상 이러한 형태의 평가가 불가능함으로, RMSE 혹은 MAP와 같은 성능 지표를 활용하여 모델을 평가하는 과정 -
학습 데이터는 유튜브 추천 시스템으로 만들어진 데이터 이외의 방법으로 만들어진 데이터까지 포함하는 것이 좋음
-
그렇지 않다면, 데이터 자체가 오로지 유튜브 추천 시스템에 의한 결과이기 때문에 bias가 자연스럽게 생길 수 있으며 새로운 아이템을 탐색하기 어려워짐
-
사용자가 유튜브 추천 시스템이 아닌 다른 방법으로 영상 콘텐츠를 시청했다면, 우리는 그 데이터를 활용해서 또 다른 collaborative filtering이 가능함
-
-
또 다른 방법으로는, 모든 사용자의 가중치를 동일하게 유지하기 위해서 사용자마다 학습 데이터의 수를 고정하는 것임
- 이 방법은, 매우 활동적인 사용자의 영향을 방지하기 위해서임
-
학습 데이터를 선정하고 추천 아이템을 예측하는 과정에서 어떤 사용자의 무작위로 선정된 아이템을 예측하는 것보다 next 아이템을 예측하도록 데이터를 구성하는 것이 효과적임
- 아래 우측 그림(b)는 특정 시점의 아이템을 예측하기 위해 특정 시점 이전의 데이터로만 학습 데이터를 구축한 것을 의미함
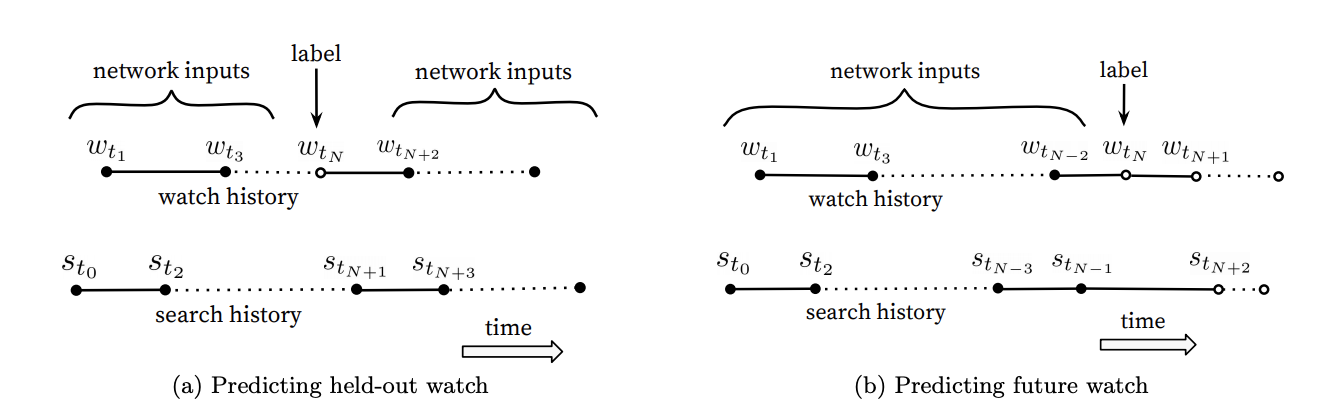
4. RANKING
-
ranking 모델의 주 역할은 각 사용자의 feature를 사용해서 후보 아이템을 특성화하고 조정하는 것임
-
ranking 모델 단계에서는 겨우 몇 백개의 아이템에 불과하기 때문에 아이템에 대한 사용자의 action 및 feedback이 훨씬 dense함
-
candidate generation 모델과 구조 자체는 유사하며, 각 아이템에 score(점수)를 할당하게 함으로써 정렬하여 사용자에게 반영함

4-1. Feature Representation
-
features는 데이터 형태에 따라 categorical(범주형)과 continuous(연속형)로 구분할 수 있음
- categorical feature의 경우에는 binary 데이터, 사용자의 마지막 검색 기록, 점수를 부여할 아이템 ID, 최근 본 N개의 아이템 ID이 있음
Feature Engineering
-
ranking 모델에서는 수백개의 feauture가 사용됨
-
딥러닝이 feature engineering에 대한 수고스러움을 덜어주지만, 신경망에 넣어주기 위해서는 어느정도 raw data에 대한 전처리가 필요함
-
가장 중요한 과제는 사용자 행동에 대한 sequence를 반영하는 것과 어떻게 사용자 행동을 아이템 점수화와 연관시킬 것인지임
- 해당 채널에서 시청한 영상의 개수, 해당 이슈와 관련된 영상을 시청한 마시막 시점 등과 같은 연속적인 feature는 아이템과 연관된 사용자의 과거 행동이기 때문에 매우 효과적임
Embedding Categorical Features
-
영상 콘텐츠, 즉 아이템의 ID와 검색 기록을 임베딩하여 인공신경망에 input함
-
categorical 데이터가 지나치게 많을 경우, click의 빈도수를 기반으로 top N을 선정함
-
반대로 부족한 경우에는 zero 임베딩을 함(padding 개념으로 이해함, 데이터가 부족한 경우)
-
candidate generation 과정처럼 multivalent feature(최근 본 N개의 아이템)의 경우에는 평균을 적용함
-
Normalizing Continuous Features
- continuous feature의 경우에는 0~1로 scaling해주며 super/sub-linear한 특징을 배우기 위해서 의 데이터 또한 input으로 넣어줌
4-2. Modeling Expected Watch Time
-
우리의 목표는 주어진 학습 데이터에서 사용자가 클릭한 아이템(positive)와 클릭하지 않은 아이템(negative)의 기대 watch time(시청 시간)을 예측하는 것임
-
positive 아이템의 경우 사용자가 시청한 시간에 대한 기록이 남겨져 있으며, weighted logistic regression을 사용해서 예측할 수 있음
4-3. Experiments with Hidden Layers
5. CONCLUSIONS
-
Youtube의 영상 콘텐츠를 추천하는 딥러닝 모델인 candidate generation과 ranking 모델에 대해 소개했음
-
deep collaborative filtering 모델은 이전에 사용했던 MF와 비교하여 많은 signals과 interaction을 활용할 수 있었고 더 좋은 성능을 보여줌
-
ranking은 여전히 고전적인 머신러닝에 가깝지만(feature engineering 때문에 이렇게 표현한 것 같음), 선형 및 tree 기반 방법보다 더 좋은 성능을 보여줌
-
추천 시스템은 특히 사용자의 과거 행동이 특징된 feature로 부터 좋은 효과를 얻게 됨
-
인공신경망은 임베딩되거나 정규화되어 있는 categorical, continuous한 데이터가 필요함
-
-
사용자가 본 아이템(positive)으로부터 watch time(시청 시간?)을 학습한 weighted logistic regression은 CTR을 직접적으로 예측하는 metrics보다 좋은 성능을 보여줌
