오늘은 우리가 서비스를 운영하다 보면 MySQL에 부하가 몰릴 까봐 분산을 해주기 위해 여러개의 DB를 검색이나, 로그 등 도메인이 다른 부분에 대해서 부하분산을 시키기도 한다.
하지만 결국 유저가 더 늘어나게 되면 데이터의 무결성을 보장해줘야 줘야 하는 중요한 MySQL 에도 부하가 몰리게 될 것이다.
- 왜냐하면 유저가 글을 작성하거나 하면 계속 저장되고 있을 것
그래서 트랜잭션을 거의 완벽하게 지원하는 MySQL 을 좀 더 안정적으로 사용하기 위해 MySQL 의 성능을 올려줘야 한다.
그렇기에 Scale Out 방식을 도입해 Mqster에서 발생한 데이터를 Slave로 자동으로 복제하는 기능인 Replication을 도입하게 되는데 이에 대해 알아보겠다.
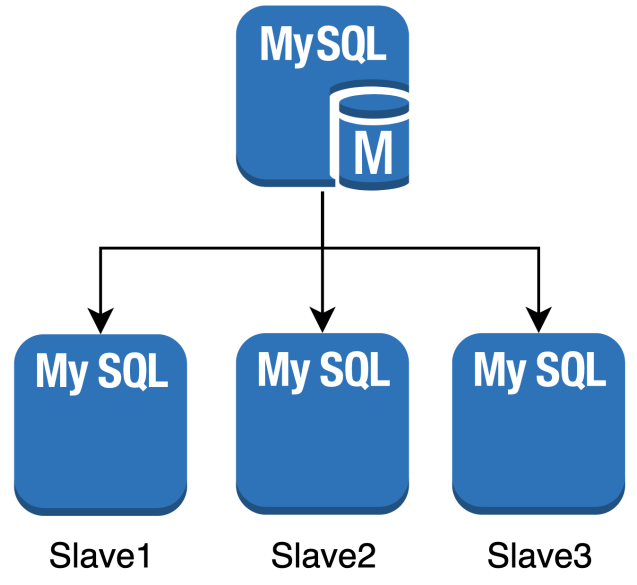
Master/Slave Replication
- 확장성, 가용성, 백업을 목적으로 Master에서 발생한 데이터 변경 사항을 Slave로 자동으로 복제하는 기능
- Master
- 모든 쓰기 작업(INSERT, UPDATE, DELETE 등)이 발생하는 서버
- Master 에서의 변경 사항은 Slave 서버로 전달
- Slave
- Master 서버에서 일어난 변경 사항을 복제받는 서버
- Slave 서버는 읽기 전용이고 읽기 작업의 부하를 분산으로 사용 가능
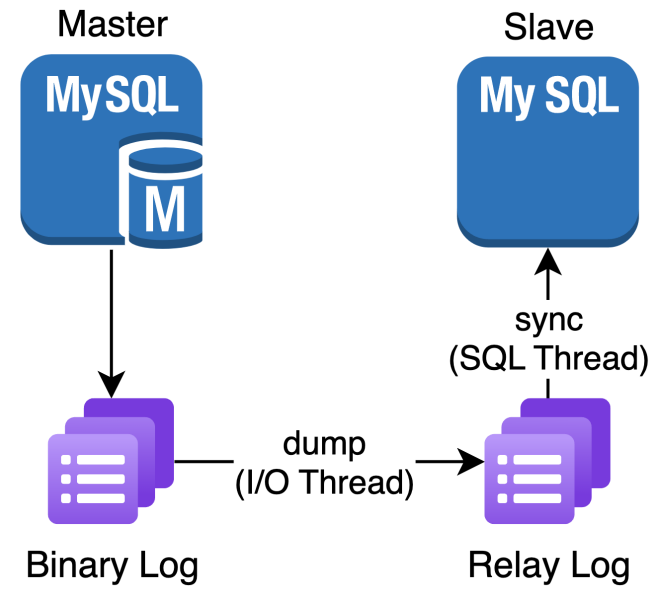
Replication 과정
- Master에서는 Binary Log(모든 데이터 변경 사항)을 저장함
- Slave는 Binary Log을 I/O Thread를 통해 dump 받음
- SQL Thread를 통해서 읽어온 로그 파일을 SQL로 실행하여 복제함
Master/Slave Replication 장/단점
- 장점
- Slave를 통한 읽기 성능 향상
- Master는 쓰기 작업만 처리하여 일부 성능 향상 가능
- 백업 및 승격을 통한 Failover
- 단점
- 비동기적 복제로 인한 데이터 일관성 문제
- 일관성 문제가 일어날 수 있기에 SQL문 기반으로 동기화
- Slave 지연에 따른 Replication Delay
- 비동기적 복제로 인한 데이터 일관성 문제
이런 점들로 읽기 성능 향상 시키는 것 하면 redis 만 생각하는데 Replication 을 사용해서 성능 향상 가능하다.
MySQL Master/Slave Replication 로 재구축
기존의 MySQL에 Replication을 도입해보겠다.
docker-compose 로 Replication을 도입할 파일을 만들어 주고 실행해보면
services:
mysql-master:
image: mysql:5.7
restart: always
platform: linux/amd64
environment:
MYSQL_ROOT_PASSWORD: code1!
MYSQL_DATABASE: code-db
MYSQL_USER: code-user
MYSQL_PASSWORD: code!
ports:
- "13306:3306"
volumes:
- db_data_master:/var/lib/mysql
command:
--server-id=1
--log-bin=mysql-bin
--binlog-format=row
networks:
- mysql-network
mysql-slave:
image: mysql:5.7
restart: always
platform: linux/amd64
environment:
MYSQL_ROOT_PASSWORD: code1!
MYSQL_DATABASE: code-db
MYSQL_USER: code-user
MYSQL_PASSWORD: code1!
ports:
- "13307:3306"
volumes:
- db_data_slave:/var/lib/mysql
command:
--server-id=2
--log-bin=mysql-bin
--binlog-format=row
networks:
- mysql-network
volumes:
db_data_master:
db_data_slave:
networks:
mysql-network:
driver: bridge
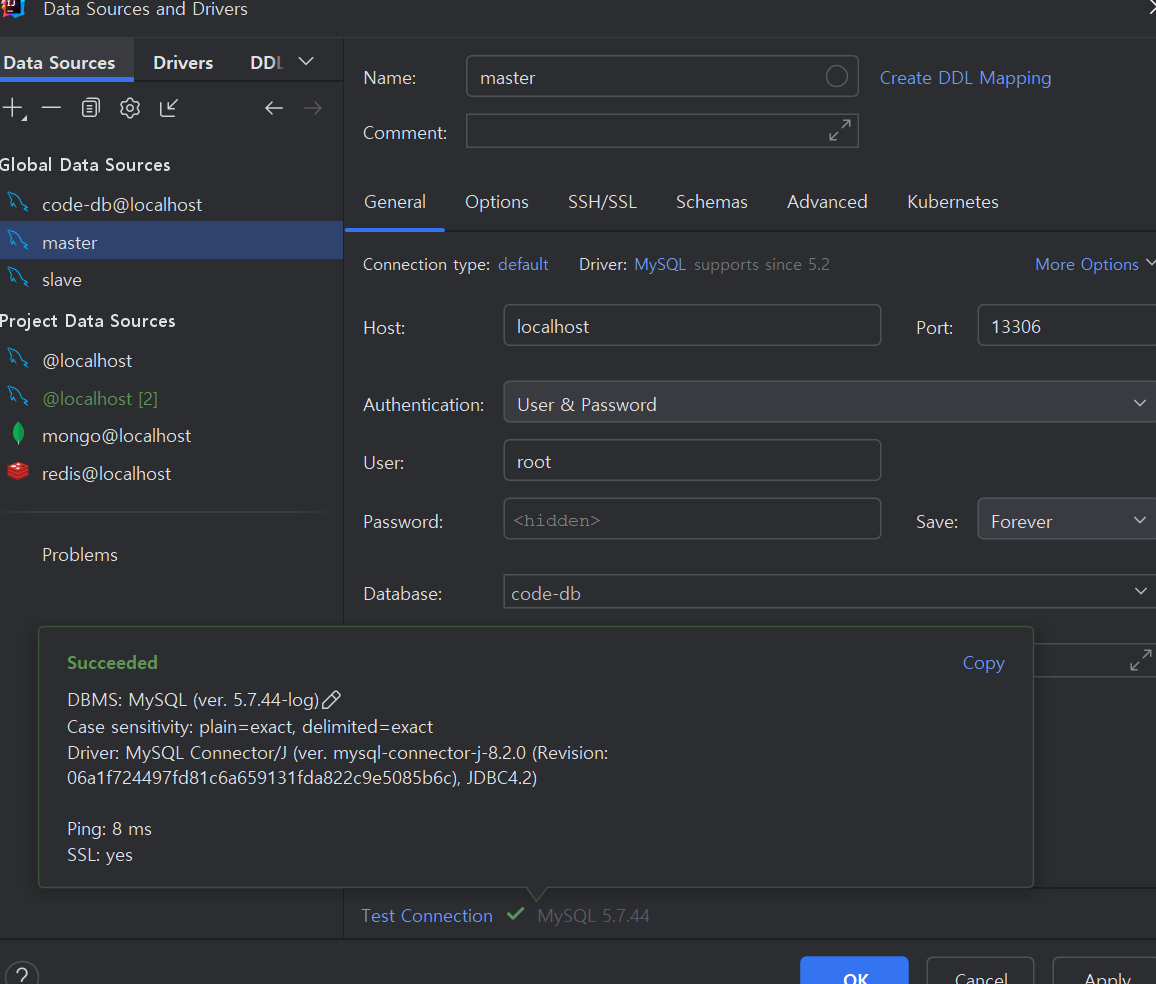
잘 뜨는 걸 확인할 수 있고 설정해준 user, password로
DataGrip으로 연결 해보면 Master 잘 되고
Slave도 잘된다.
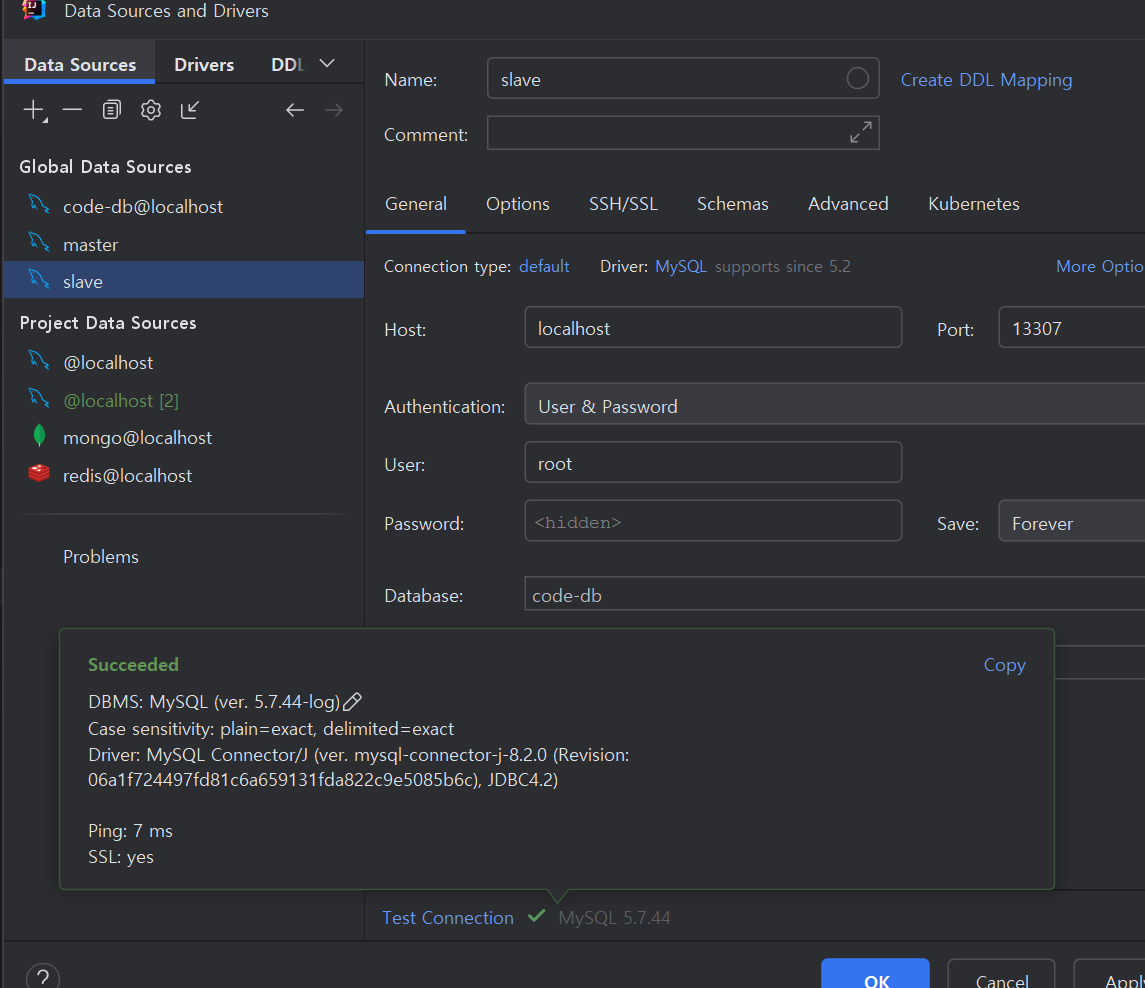
이제 Master, Slave 연결은 된 상태 이제 Slave 가 Master를 바라보게 해줘야 한다.
- Slave가 Master에 접근하기 위해서는 Master 쪽에 User가 필요하다.
그래서 replication 만 하는 User를 만들어 줄건데 cluster.sql 이라는 파일을 만들어서 User 만들 것이다.
-- 1. Master 서버 SQL
GRANT REPLICATION SLAVE ON *.* TO 'replication_user'@'%' IDENTIFIED BY '1q2w3e4r!!';
FLUSH PRIVILEGES;
SHOW MASTER STATUS;
-- 2. Slave 서버 SQL
-- STOP SLAVE;
-- RESET SLAVE ALL;
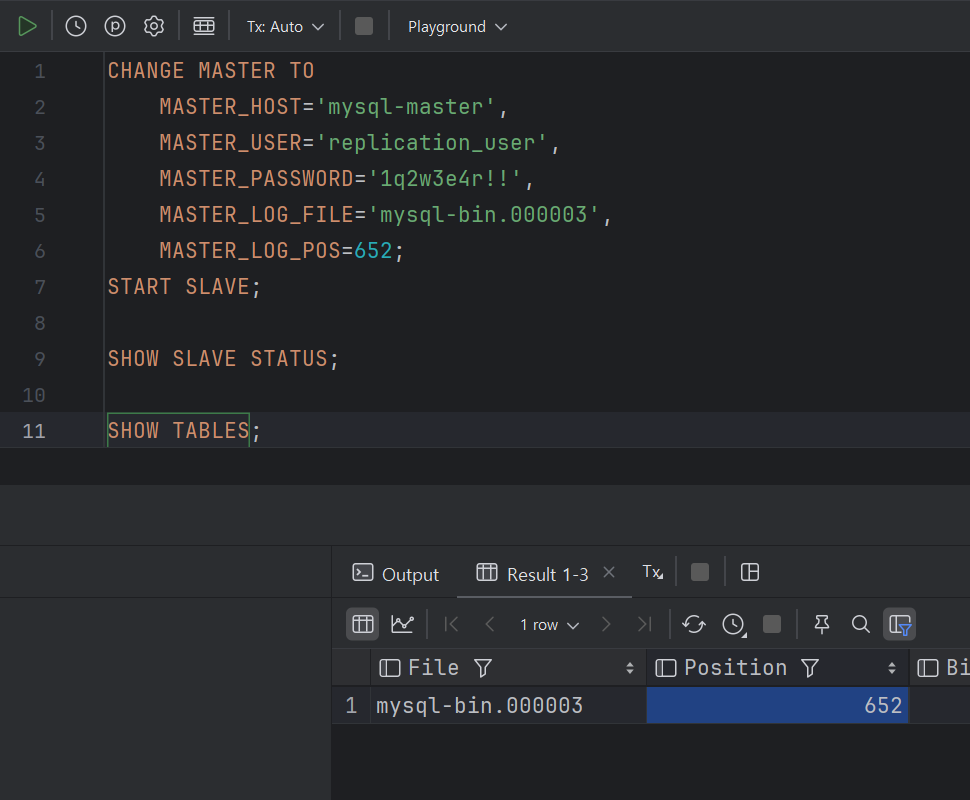
CHANGE MASTER TO
MASTER_HOST='mysql-master',
MASTER_USER='replication_user',
MASTER_PASSWORD='1q2w3e4r!!',
MASTER_LOG_FILE='<TODO>',
MASTER_LOG_POS=<TODO>;
START SLAVE;
SHOW SLAVE STATUS;
SHOW TABLES;
# SET GLOBAL read_only = OFF;- Master 에서 1번 User 생성 쿼리 실행
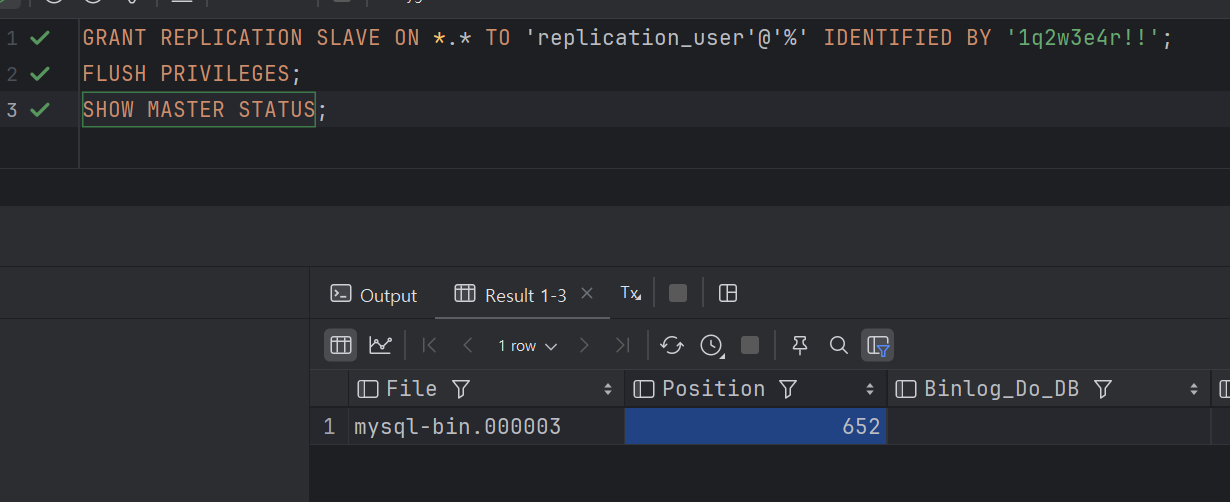
- SHOW MASTER STATUS 해서 나온 결과를 복사해서 Slave에서 사용
FIle 값에 파일이름 넣어주고
pos 에 Position 값 넣어준다.
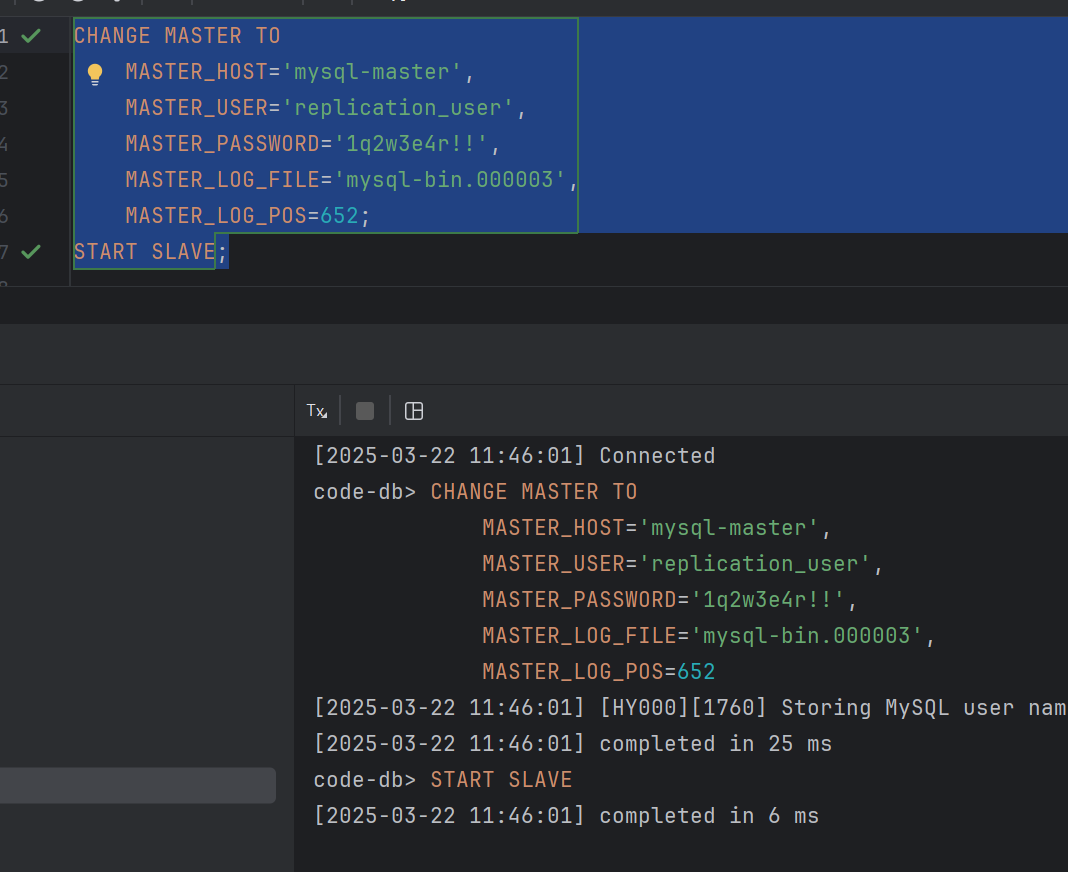
2개의 위의 쿼리 실행해주면 이제 Slave 가 진짜 Slave 역할을 하기 시작한다.
- Master를 바라보면서 replication 진행
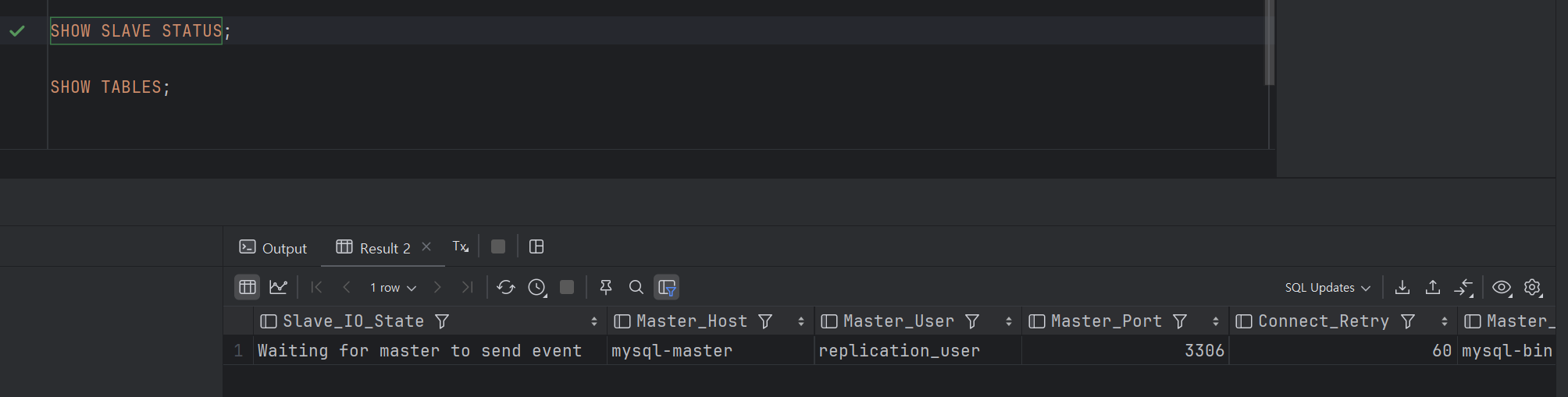
Slave 상태 쿼리 날려보면 Master 이벤트 기다리고 있다고 뜬다.
여기서 중요한 건 옆으로 넘겨서 컬럼을 보면 아래에 항목이 있다.
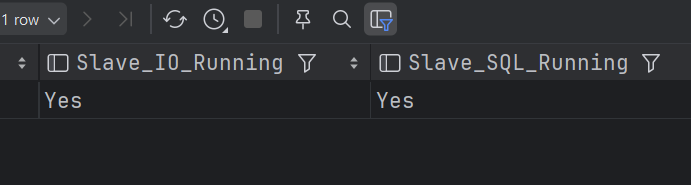
Slave가 잘 작동하고 있는지 즉 Yes 로 두 항목이 되어 있는지 체크
docker 데스크 탑에서 Slave log 보기 위해 눌러보면
- 이제 Slave 쪽에서 바이너리 로그를 다운 받아서 실행을 시킬 건데

SQL thread 를 통해서 바이너리 로그를 받아서 relay 로그로 받아온 것을 확인 할 수 있다.

이후 I/O thread 를 통해 동기화 했다고 나온다.
그러면 이제 master 입장에서 보자

start binlog_dump 해서 master 쪽에서 slave 쪽으로 복사를 해준 것을 볼 수 있다.
잘 되는지 확인 위해 값 넣어보자
- 포트에 1만 넣어주어서 master 바라보게 만들고

이러면 테이블이 master에 만들어 질 것이다. 서버를 실행해보면 JPA SQL 문 실행되면서
- master 와 slave에 자동으로 테이블이 들어간 것이 보인다.
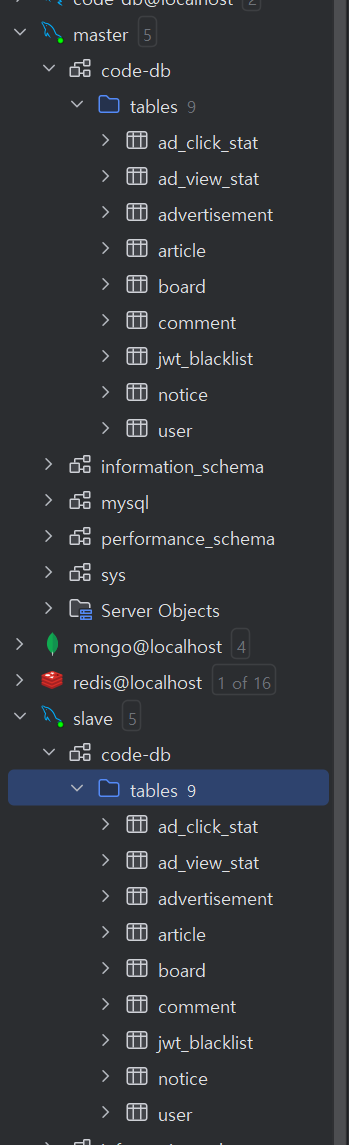
그러면 잘되나 자세히 보기 위해 간단하게 공지사항 하나 써 볼까?
notice에 test 공지사항 하나 써보고

master 쪽에서 id가 1인 데이터가 들어간 것
slave도 살펴보면 ?? 과연??

오호 복제가 잘 되었다.
