Logistic Regression
- 훈련/검증/테스트(Train/Validate/Test)데이터 분리 이유 이해 및 사용
- 분류Classification 문제와 회귀 문제의 차이점 파악, 적절 모델 선정 가능
- 로지스틱회귀 Logistic Regression 이해, 모델 학습 가능
데이터 훈련/검증/테스트 세트 분리
- 훈련 데이터 : 모델을 Fit(학습)하는데 사용
- 검증 데이터 : 예측 모델을 선택하기 위해, 예측의 오류를 측정을 위해 사용. 훈련세트로 모델을 완전하게 학습시키기 어려워, 튜닝된 여러 모델을 학습한 후 어떤 모델이 학습이 잘 되었는지 검증하고, 선택하는 과정에서 필요함
- 테스트 데이터 : 일반화 오류를 평가하기 위해 선택된 모델에 한하여 마지막에 한번 사용. 테스트 데이터는 훈련/검증에서 사용되면 안됨.
훈련 데이터가 너무 훈련이 잘되어, train 모델에 완전 적합하게 되어 test data에는 맞지 않는 수준 = "과적합"
모델 검증
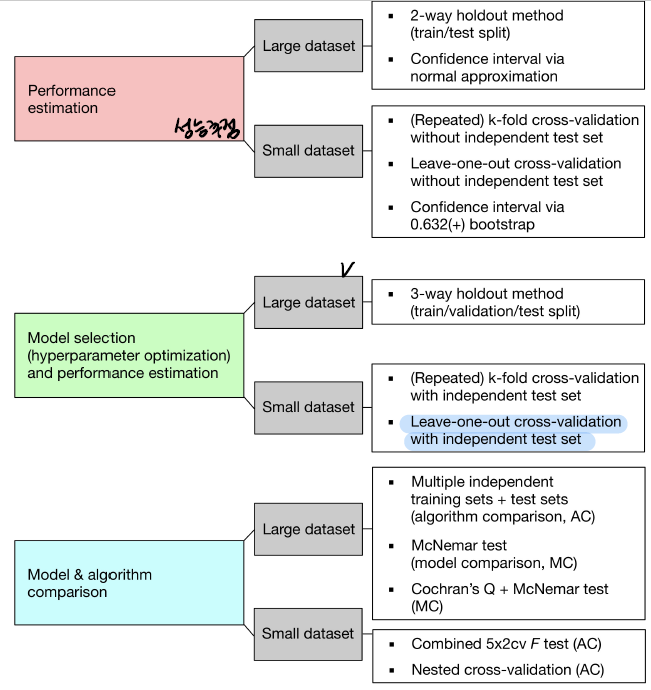
학습 모델 개발 시, 모델 선택 Model Selection을 수행해야 한다. 이때 하이퍼파라미터Hyperparameter 튜닝을 하게 되는데, 튜닝 효과를 보기 위해서는 검증세트가 필요하다. 데이터가 많을 경우에는 전체 데이터를 훈련/검증/테스트 세트로 나누면 되지만, 상대적으로 데이터 수가 적으면 K-Fold 교차 검증을 진행하면 된다.
Kaggle에서의 Titanic:Machine Learning from Disaster 데이터로 학습한다.

Logistic Regression
다수 클래스를 기준모델로 정하는 방법 Majority Class Baseline에 대해 알아 봅시다.
- 회귀문제 : 보통 타겟 변수의 평균값을 기준 모델로 사용
- 분류문제 : 보통 타겟 변수의 가장 빈번하게 나타나는 범주가 기준 모델
- 시계열Time-Series : 보통 어떤 시점을 기준으로 이전 시간의 데이터가 기준 모델
- 분류 문제에서는 타겟 변수가 편중된 범주 비율을 갖고 있는 경우가 많음. 이를 주의하여 더 좋은 성능을 가지는 모델을 만들이 위하여 노력해야함.
1. 타겟 범주의 비율 확인

2. (분류 문제의 기준 모델) 범주 0 (majority class)으로 모든 예측 수행

3. Accuracy 평가 지표 사용
- 회귀 평가 지표, 분류 평가 지표 절대적인 구분 필요
- Accuracy는 분류 문제의 평가 지표

최다 클래스의 빈도가 정확도가 된다.

검증 세트에서의 정확도 확인

4. Logistic Regression
<<Logistic 함수>>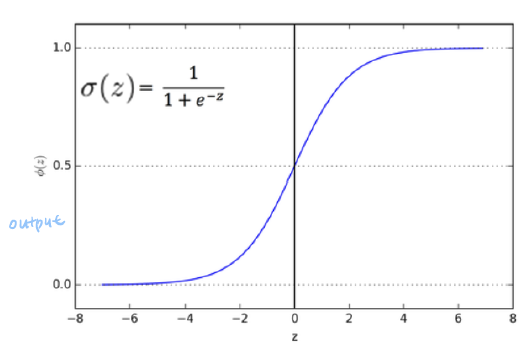
관측치가 특정 클래스에 속할 확률값으로 계산. 분류 문제에서는 확률값을 사용하여 분류를 한다. eg. 확률값이 정해진 기준값 보다 크면 1 if not 0.
Logit Transformation
로지스틱 회귀 계수는 비선형 함수 내에 있어서 직관적으로 해석하기가 어려워 Odds를 사용하여 선형 결합 형태로 변환하고, 이를 ㅇ해석한다.
Odds : 실패확률에 대한 성공확률의 비
Odds를 확률로 해석을 하려면 exp(계수) = p를 계산해서 특성 1단위 증가량 확률이 p배 증가한다고 해석할 수 있다.
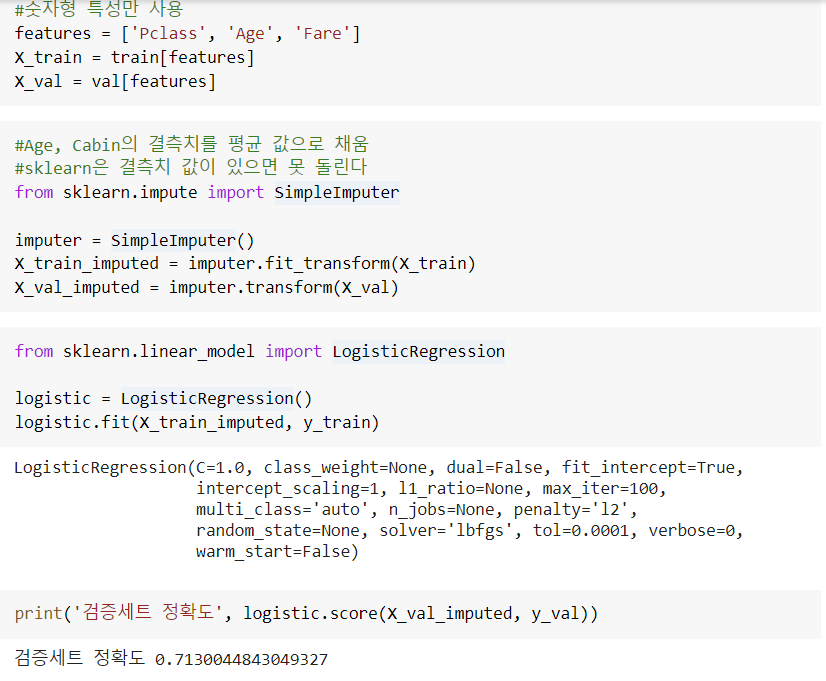
분류에 기준이 되는 각 클래스에 속할 확률 값 확인 가능 0번 클래스dead될 확률0.0174, 1번 클래스 alive될 확률 0.982
0번 클래스dead될 확률0.0174, 1번 클래스 alive될 확률 0.982
transformer 정리
-
category_encoders.one_hot.OneHotEncoder
:카테고리 데이터 처리 -
sklearn.impute.SimpleImputer
: 결측치 처리
-
sklearn.preprocessing.StandardScaler
: 특성들의 척도를 맞추기 위해 표준화하는 ScalerScaler 종류
-
StandardScaler 기본 스케일, 평균과 표준편차 사용
-
MinMaxScaler 최대/최소값이 각각 1,0 되도록 스케일링
-
MaxAbsScaler 최대절대값과 0이 각각 1,0이 되도록 스케일링
-
RobustScaler 중앙값Median과 IQRinterquartile range 사용, 아웃라이어의 영향을 최소화
모든 스케일러 처리 전에 아웃라이어 제거가 선행되어야 한다. 데이터의 분포에 따라 적절한 스케일러 적용
실습) Titanic 데이터의 모든 특성을 사용한 모델


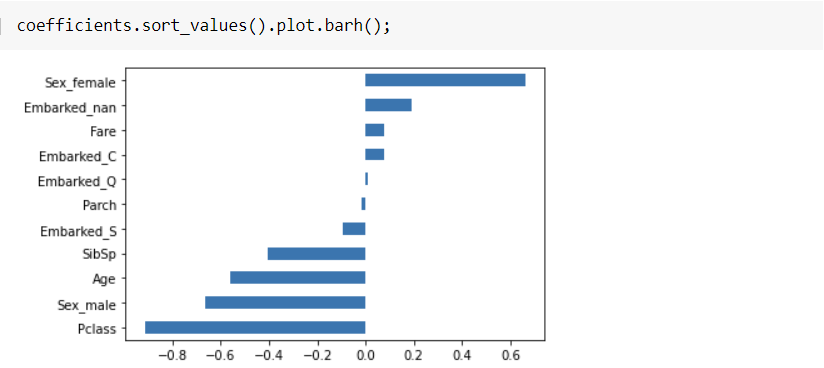
결론) 좌석의 등급이 고급일수록, 나이가 어릴 수록, 남성보다는 여성의 생존이 더 높아짐을 계수들의 수치로 확인할 수 있다.
번외
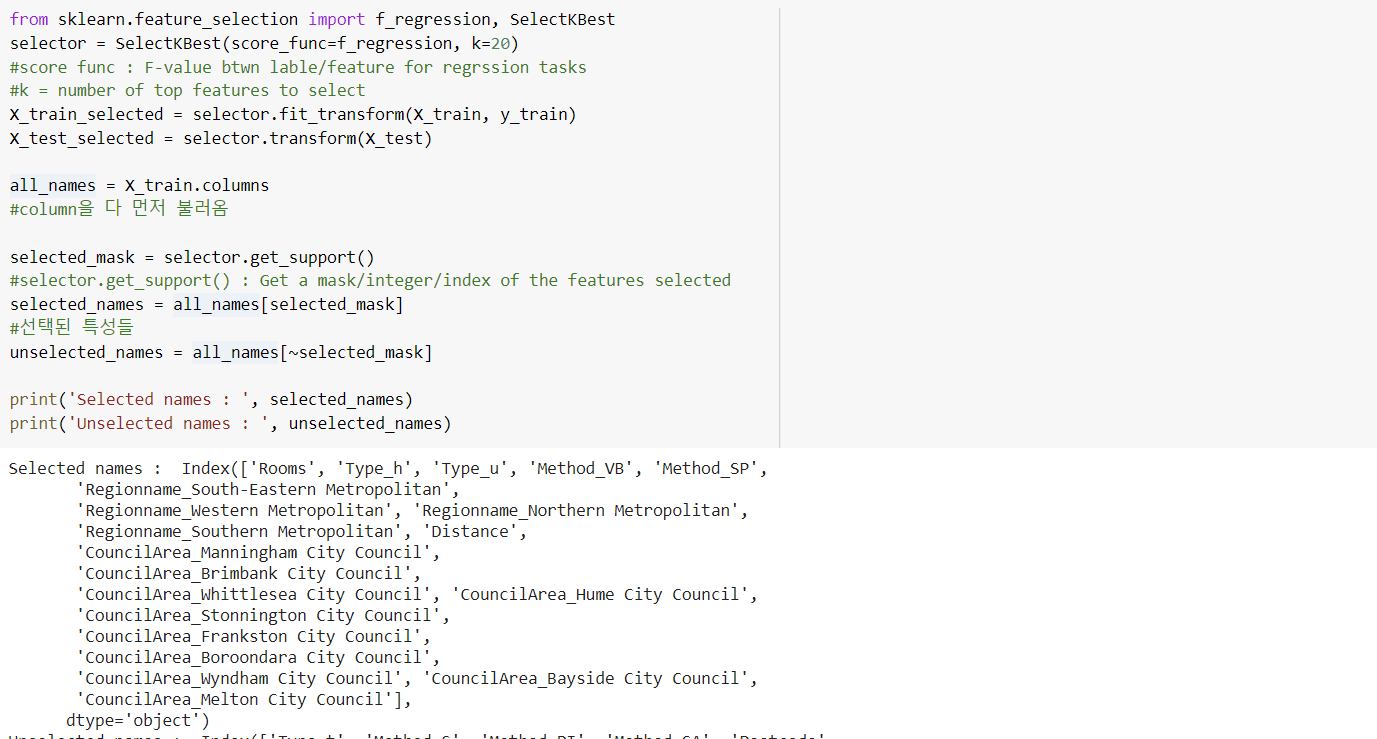
Feature Selection (특성 선택)
: 필요한 좋은 특성만 선택하는 것
SelectKBest (선형회귀, Ridge에서 사용/ not on Tree-based)