Decision Tree(결정트리)
- 사이킷런 파이프라인pipeline을 이해하고 활용
- 사이킷런 결정트리Decision Tree 활용
- 결정트리의 특성 중요도(feature importance)활용
- 결정트리 모델의 장점 이해, 선형회귀모델과 비교
결정트리는 선형회귀처럼 특성해석에 좋음
다른 모델보다 성능이 조금 떨어져도, 해석이 좋아 자주 사용
샘플에 따라 트리 구조가 바뀌고, 이에 따라 해석도 바뀌는 단점
회귀/분류 모두 사용 가능
Ensemble방법의 기초
1. EDA, Prepocessing
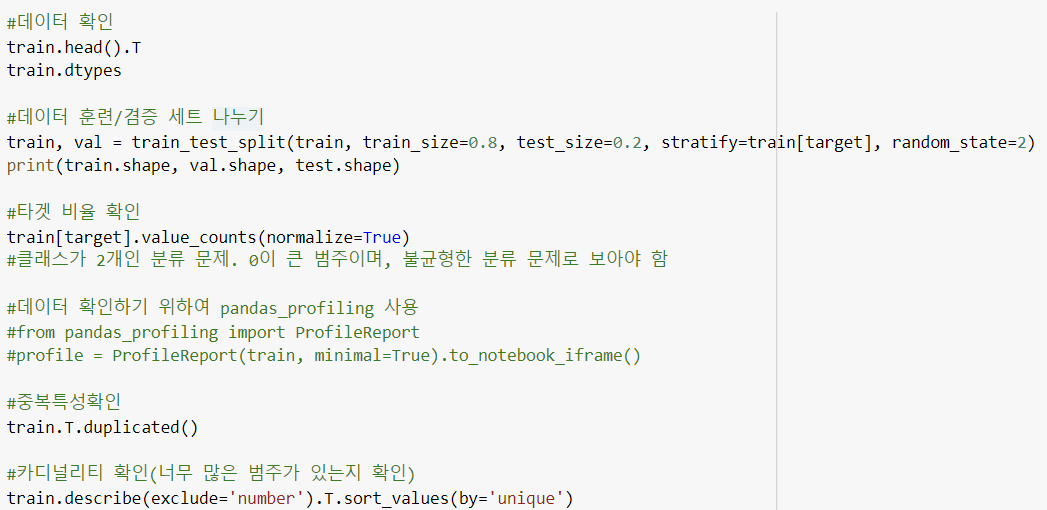
2. 특성엔지니어링
3. 특성/타겟 분리 + 훈련/검증/테스트 데이터 특성/타겟 분리
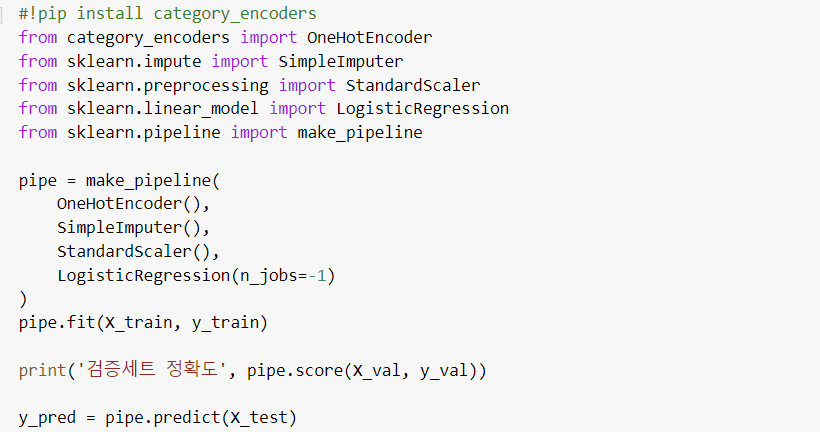
4. 파이프라인 사용

5. 결정트리 Decision Tree Model
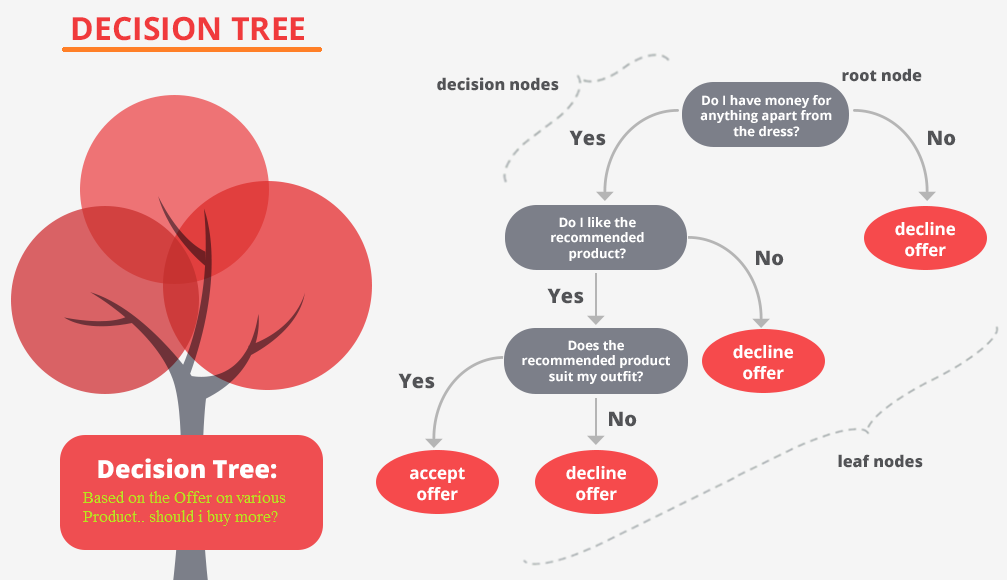
5-1 결정트리 학습 알고리즘
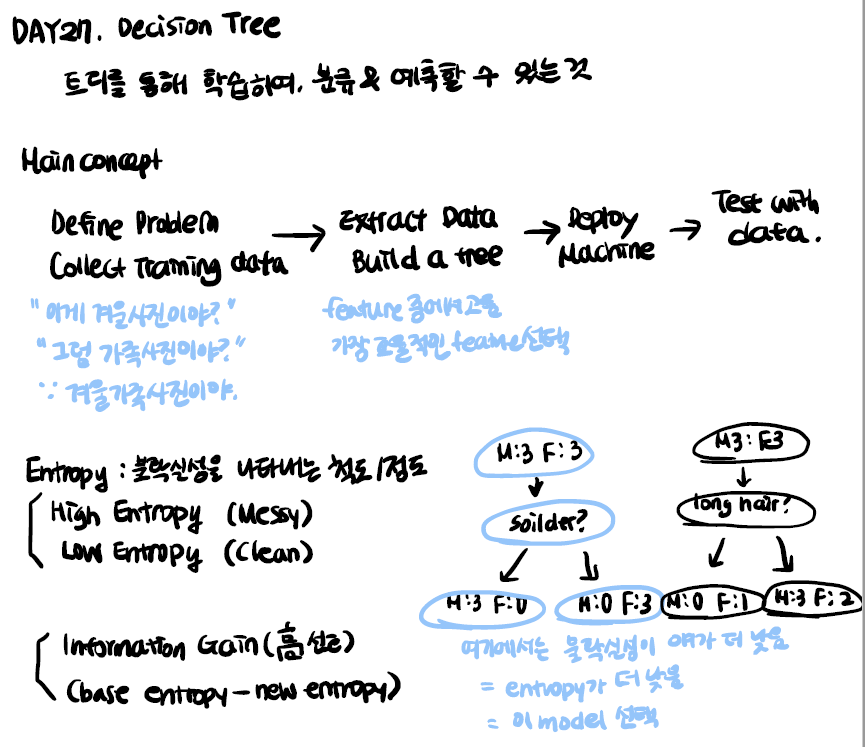
결정트리를 학습하는 것은, 노드를 어떻게 분할하는가에 대한 문제.
노드 분할 방법에 따라 트리구조가 다른 모양으로 만들어지기 때문.
결정트리의 비용함수를 정의하고, 그것을 최소화 하도록 분할하는 것이 트리모델 학습 알고리즘이 된다.
= Decision Tree를 만들 때, 각 node들의 복잡성 즉 impurity가 가장 낮은 방향으로 tree가 만들어진다.
= 결과 노드 안에 섞여 있는 정도가 가장 낮은 tree를 만드는 것이 목표.
이를 측정하는 방법 2가지
1. Entropy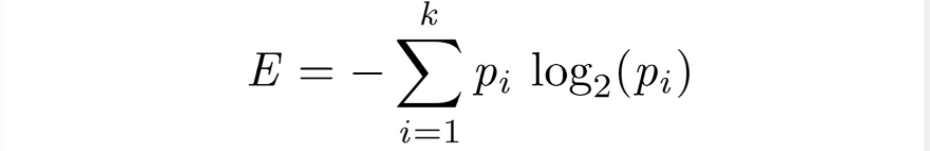
열역학의 개념. 한 노드에서 모든 샘플이 같은 클래스이때 0디이 된다.
2. Gini Impurity, Gini Index
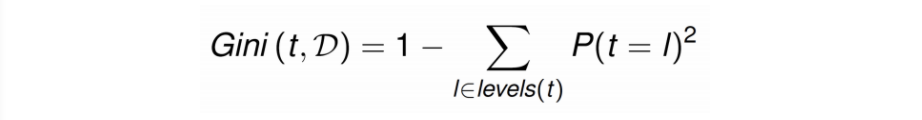
트리의 한 노드의 모든 샘플이 같은 클래스에 속했을때 값이 0이 되고, 이때를 '순수'범주들이 섞여있을 수록 이 수치가 올라가게 되어있다.
eg. (45%, 55%)인 샘플(두 범주 수가 비슷)은 불순도가 높은 것이며
(80%, 20%)인 샘플이 있다면 상대적으로 위의 상태보다 불순도가 낮은 것 입니다.(순수도(purity)는 높음)
3. Information Gain정보 획득
각 node의 impurity를 바탕으로 (decision tree에 의해 나누기 전의 impurity - 나누어진 subset들의 impurity)값을 통해 impurity 개선 정도를 계산할 수 있음, 이를 Information Gain이라고 한다.
= 불순도의 감소가 클수록 정보 획득량이 크다
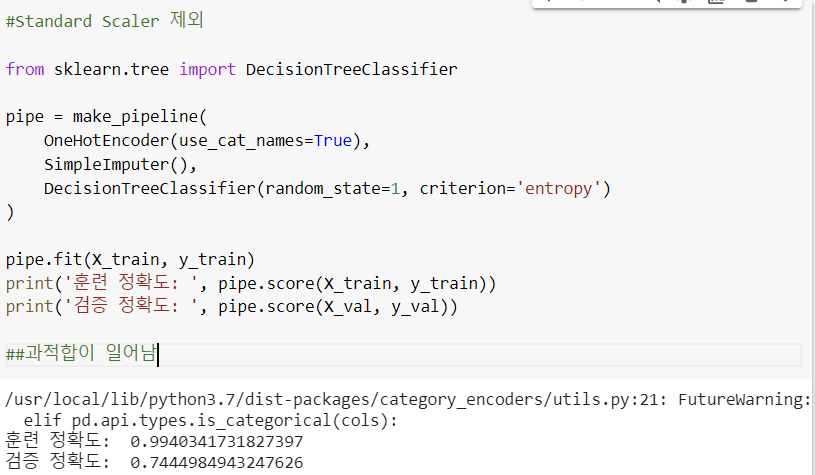
4. 과적합 해결하기
복잡한 트리는 과적합 가능성을 높이기에, 복잡도를 낮추어 일반화를 유도

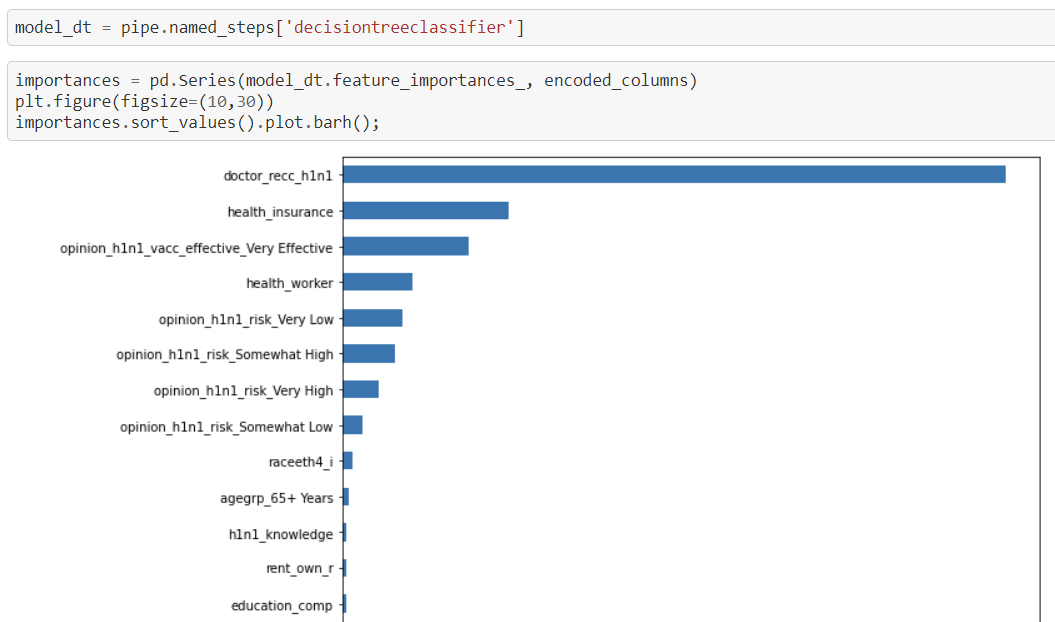
5. 결정트리의 확인가능한 특성 중요도 Feature Importance
선형모델에서는 특성-타겟 관계 확인 위해 회귀계수Coefficients를 사용. 결정트리에서는 특성중요도로 확인. 회귀계수와 달리 특성 중요도는 항상 양수값을 가진다. 이 값을 통해 특성이 얼마나 일찍 그리고 자주 분기에 사용되는지 결정
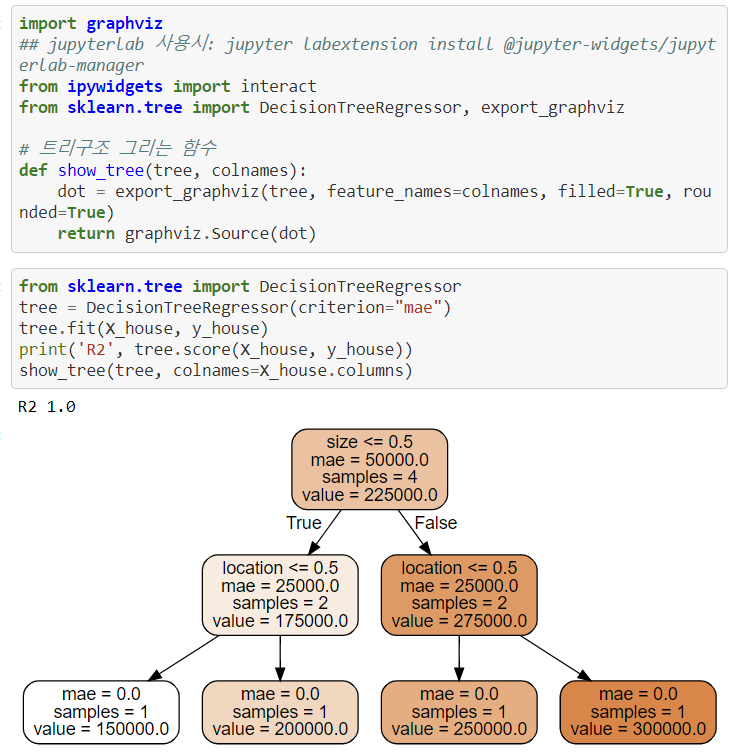
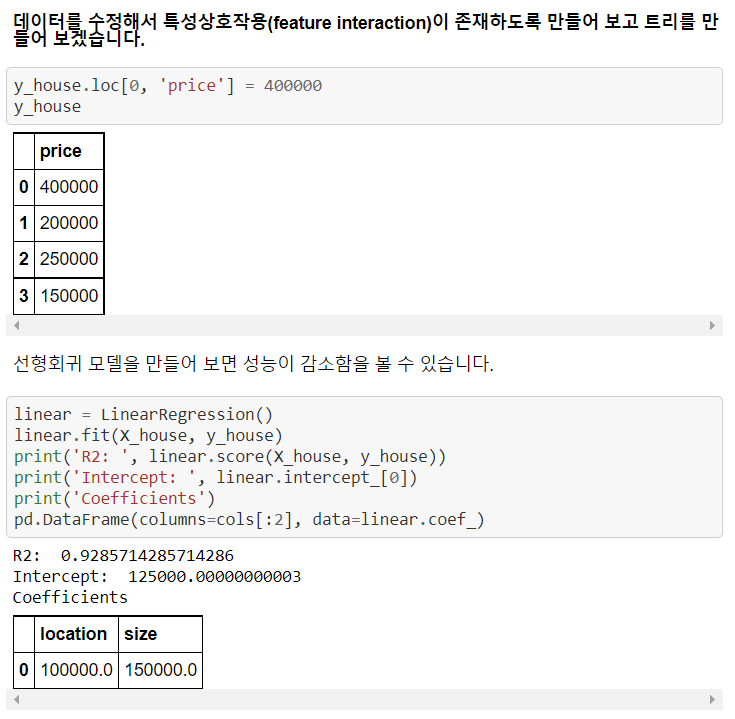
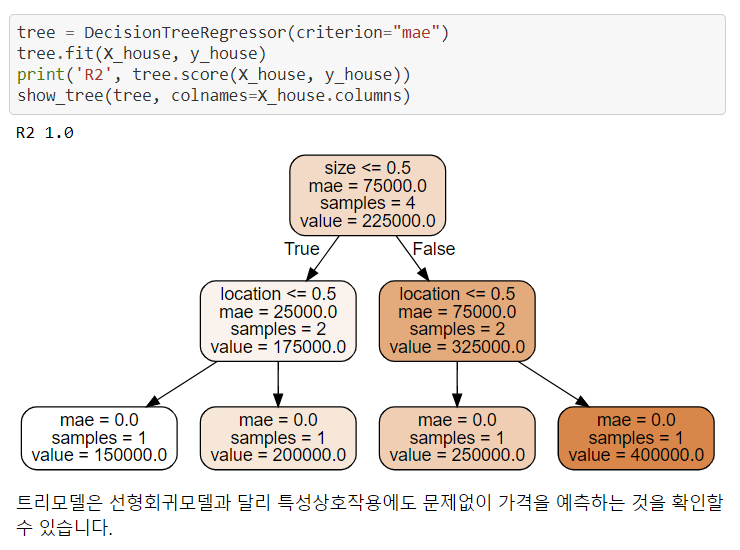
6. 특성상호작용
특성상호작용은 특성들끼리 서로 상호작용을 하는 경우를 말한다.
회귀분석에서는 서로 상호작용이 높은 특성들이 있으면 개별 계수를 해석하는데 어려움이 있고, 학습이 올바르게 되지 않을 수 있다. 하지만 트리모델은 이런 상호작용을 자동으로 걸러내는 특징이 있다.
!pip install pandas-profiling==2.7.1
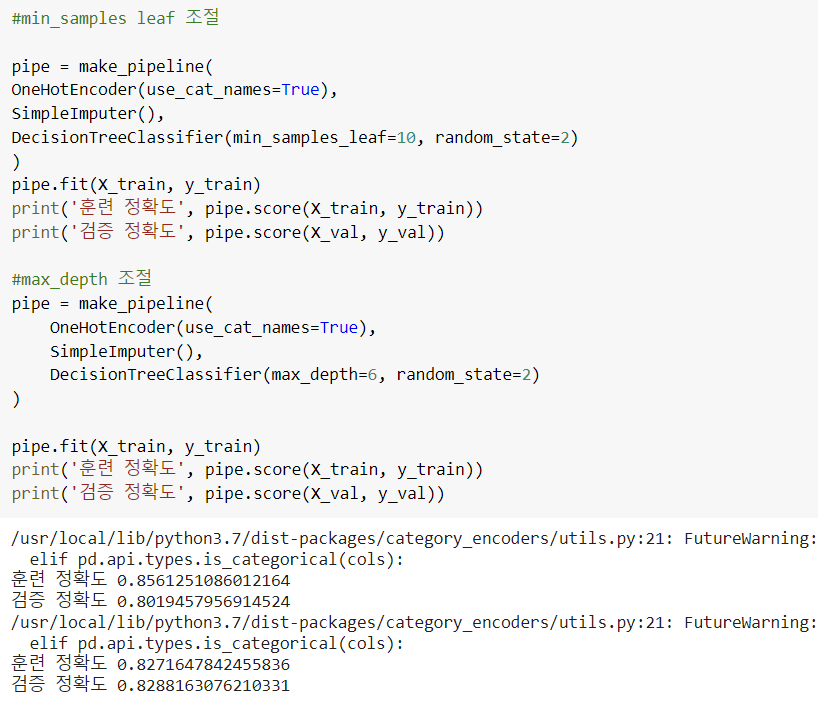
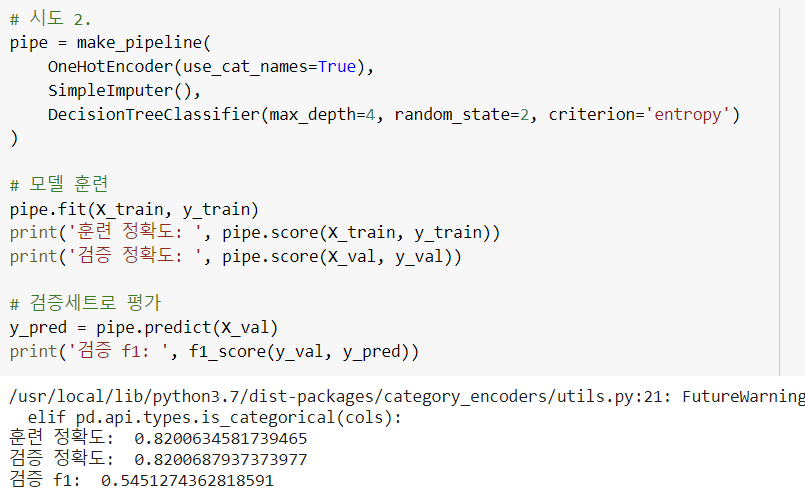
하이퍼파라미터 수정하여 성능 높이기 예시

Reference---------------------------------------
https://youtu.be/r3iRRQ2ViQM
https://datascience.foundation/sciencewhitepaper/understanding-decision-trees-with-python
https://process-mining.tistory.com/106
