sequential model의 정의와 종류, Recurrent Neural Networks
Sequential Model
sequential data 처리의 어려움 : 길이가 정해져있지 않기 때문에 입력의 차원을 알 수 없음
- Naive sequence model
- Autoregressive model : 과거의 timespan 고정
- Markov model : 현재 데이터는 바로 전 과거 데이터에 dependent
- Latent autoregressive model : hidden state가 과거의 정보를 summary하여 갖고 있음
Recurrent Neural Network
MLP에 hidden state를 추가
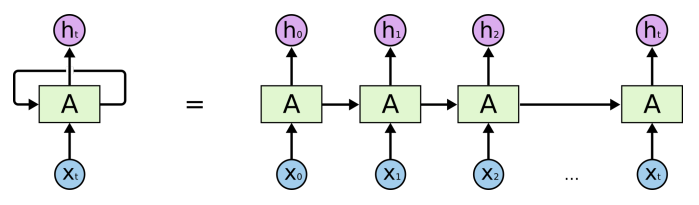
단점 : long-term dependencies를 잘 못잡음
Long Short Term Memory
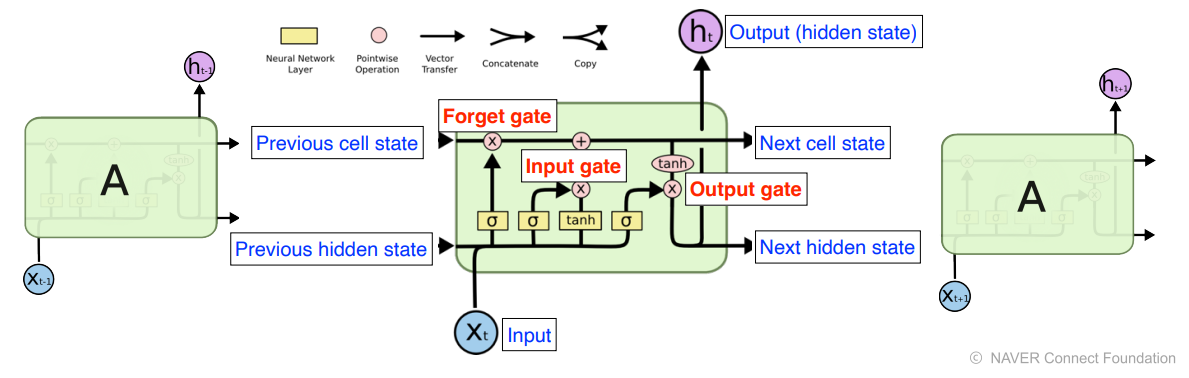
previeous cell state : hidden state, time step t까지의 정보 summarize
forget gate : 버릴 정보를 결정
input gate : 저장할 정보를 결정
update cell : (forget gate)와 (input gate)를 합쳐서 새로운 cell state를 update
output gate : update한 cell에서 빼낼 정보를 결정
Gated Recurrent Unit(GRU)
- LSTM보다 parameter을 줄임
- reset gate, update gate
- hidden gate (no cell state)
- 많은 경우에 LSTM보다 성능 향상
참고
Understanding LSTM Networks
https://colah.github.io/posts/2015-08-Understanding-LSTMs/
출처 - 부스트캠프 AI tech 교육자료
[부스트캠프 AI Tech] Week 3 - Day 2
