Pandas
이전 이론 자료 https://velog.io/@jinus/python-Pandas
Series : 1차원 배열 형태 (인덱스에 의한 저장과 검색)
- List, Numpy의 Array, dictionary를 통해 생성
pd.Series()
DataFrame : 2차원 배열 형태 (인덱스와 칼럼에 의한 저장과 검색
- List, Numpy의 Array, dictionary를 통해 생성
pd.DataFrame(data)
데이터 선택
column과 row의 범위를 이용하여 데이터 선택 가능
data['column명'],data[0:3]
Index의 이름(row명)으로 데이터 선택
data.loc['가'],data.loc['가', 'A']
Index 번호 탐색
data.iloc[0:2, 3:4]0~1번째 행과 3번째 열의 데이터
조건 지정
data[data > 0]값이 양수일 때 값이 보여지고 나머지는 NaN으로 보임data['A'] = ['1','2','3','4']일치하는 행의 데이터 출력data[data['A'].isin(['true','false'])]A열의 값이 true이거나 false인 열들만 출력. 한가지 조건일때는==로도 가능
여러 함수들
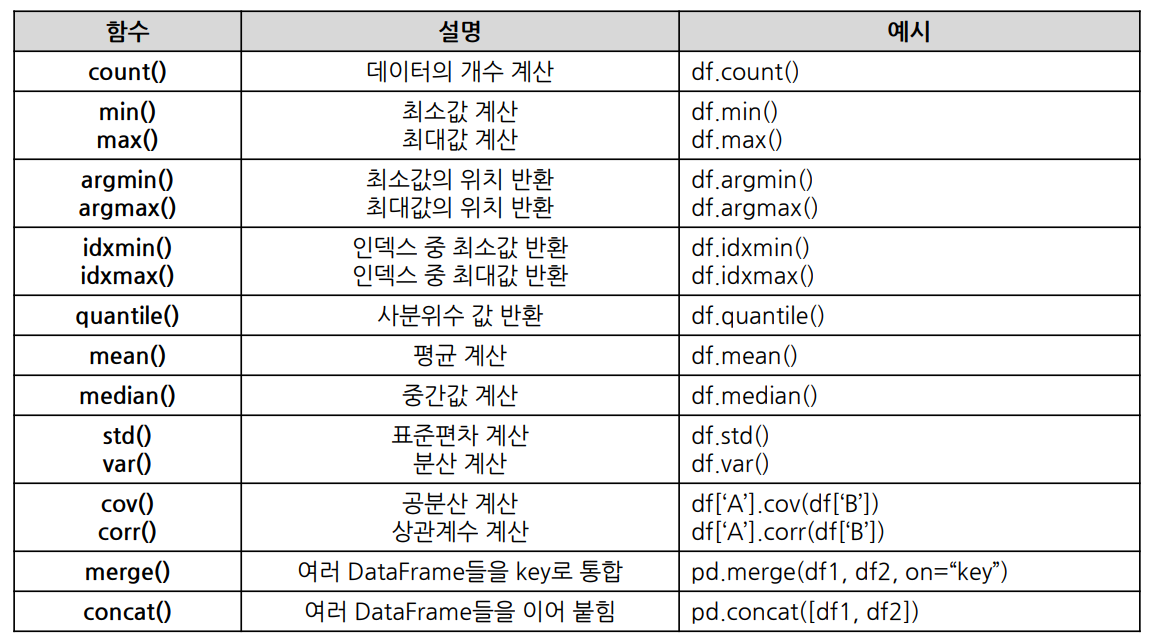
Pandas with NLP
Excel, csv, json등 다양한 텍스트 데이터들이 있음. Dataloader가 필요
-
row 범위, 다양한 column명, 조건 지정 등으로 데이터 탐색
-
출력된 데이터를 이용하기 위해 values로 array형태로 변경 가능
data.loc['A'].values -
histogram으로 데이터 시각화, 분석
# str 형태로 처리 후 premise_len 열 생성 및 길이 값 추가
df['premise_len'] = df['premise'].str.len()
df['hypothesis_len'] = df['hypothesis'].str.len()
# 각 두 문장의 길이가 담긴긴 column의 histogram 출력 (default: 10개 bar)
df.hist(column=['premise_len', 'hypothesis_len'])
출처 - 부스트캠프 AI tech 교육자료
