신경망 분류 기법
- Reference Representation : 정답을 어떻게 표현하는지
- Scoring Normalization : 값을 비교하기 위해 scale이 같아야 한다
- Softmax : 0~1값으로 normalization
- Cost(object, loss 등) Function Design : 예측값과 정답값의 차이를 어떻게 수치화할지. backpropagation을 통해 parameter을 업데이트 해야하므로 미분 가능해야함
- Cross Entropy
- Parameter Updatae : 정답과 예측의 차이 오류(Cost Value)가 작아지는 방향으로(오류의 양과 방향).
1. N21 problem
- N개의 input으로 1개의 output을 구함
- Encoder + Fully Connected layer 형태의 모델
- 가장 안정적인 성능을 보이는 transformer를 기본 encoder로 활용 예정
1.1 기존 모델 customizing

1. 입력을 적절한 단위로 Tokenization
2. Tokens에 대해 Encoder가 Sentence Encoding 수행
3. Encoder의 최종 Output vector를 classfication을 위한 class의 개수의 차월으로 Projection
ex) spam classifier, news classification
1.2 input / output
1.2.1 input
- CLS, SEP를 양쪽에 추가하여 tokenization
- attention_mask : self attention 되어야 하는 token은 1, 제외할것은 0 = pad 값
- token_type_ids : 두 문장이 들어왔을 때 구분하기 위한 값. 앞은 0 뒤는 1
1.2.2 output
- [batchsize, 768] 벡터값 → class개수 만큼 Fully connected layer → out features의 확률값을 softmax 처리
1.3 Loss function
Regression : output이 숫자 → Mean Squared Error(MSE)
Classification Loss : output이 category → Cross Entropy(CE)
Cross Entropy : 2개의 확률 분포가 얼마나 차이나는지 잘 잡아낼 수 있는 score
1.4 code
from_pretrained 선학습 모델을 불러옴
AutoTokenizer : hugginface에서 배포된 tokenizer들을 wrap
klue_tokenizer = AutoTokenizer.from_pretrained('klue/bert-base')
klue_tokenizer
>>>
PreTrainedTokenizerFast(name_or_path='klue/bert-base', vocab_size=32000, model_max_len=512, is_fast=True, padding_side='right', truncation_side='right',
special_tokens={'unk_token': '[UNK]', 'sep_token': '[SEP]', 'pad_token': '[PAD]', 'cls_token': '[CLS]', 'mask_token': '[MASK]'})- 각 tokenizer의 output은
input_ids,token_type_ids,attention_mask로 구성
2. N2N problem
- 문장 전체를 살피고 특정 part의 의미나 역할을 분석할 때 사용 (Sequence Labeling)
- 개체명 추출(named entity recognition), 형태소 분석(part of speech tagging) 등
2.1 Encoder 모델을 활용한 sequence labeling task
- Text에 대해 동일한 길이의 label sequence 출력
- input : 문장, 문단
- output : 모든 토큰에 대한 class label 분포
- Huggingface의 TokenClassification 활용
2.2 데이터 표현
- input 형태 : task에 맞는 다양한 형태로 sequential하게 표현, 대부분 Subword를 많이 씀
- output 형태 : input 개수에 맞게 토큰 개수 조정
- character 별로 labeling
- 대체로 part의 명확성을 위해 character 단위 사용
- BIOES 태깅 방식 : B(label 첫 글자), I(label 있음), E(label 끝 글자), S(label 1 글자), O(label 없음)
- 대부분 BIO를 씀
2.3 Loss function
- CrossEntropyLoss : N21과 같지만 출력이 N개 이므로 N번 돌려서 reduce(일반적으로 mean을 씀)
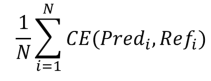
2.4 evaluation metrics
Classification의 주요 평가 metric
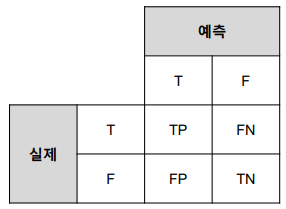

주로 F1 score을 씀
- N2N의 경우 각 라벨(형태소 등)에 대해 결과를 생성하고 그 개수를 더하여 전체를 계산
- Macro : 모든 라벨마다 score을 구하여 평균
- Micro : 전체 결과의 score
3. N2M problem
- N개의 데이터를 입력으로 M개의 데이터를 출력하는 태스크
- Encoder + Decoder 모델
3.1 Encoder & Decoder
Encoder
- 입력 정보를 잘 인코딩(숫자화)하기 위해 활용
- 긴 Sequence 정보를 잘 추출하는게 중요
Decoder - 인코딩된 정보를 활용하여 출력 Sequence를 순차적으로 생성
- 인코딩된 정보와 앞서 생성된 토큰을 함께 활용하여 다음 토큰을 생성
3.2 N2M 태스크
- 번역 문제
- 품사 태깅 : 입력된 문장의 구성요소들의 품사를 맞추는 문제
- 대화 모델링 : 질문에 답변하는 문제, 챗봇, 문제풀이
- 이미지 태깅
3.3 Encoder-Decoder 모델
- LSTM : 데이터가 길어지면 성능이 하락하는 문제
- Attention : 입력 정보에 가중치를 적용하여 정보를 취사선택, 생성해야할 토큰에 적합한 입력 정보를 골라서 사용
- Additive Attention(Bahdanau)
- Multiplicative Attention(Dot-production)
- Transformer : Attention만을 구현된 Encoder-Decoder 모델
- 주로 대규모 데이터로 선학습(Pre-training)하여 사용
- N2M 태스크에 특화된 모델
- Encoder와 Decoder를 단독으로 사용하기도 함
출처 - 부스트캠프 AI tech 교육자료
