Recurrent Neural Networks
기본적으로 Rnn은 sequence data가 입력 또는 출력으로 주어졌을 때 각 time step에서의 입력벡터 와 전 timestep의 rnn 모듈에서 계산한 hidden state 벡터 를 입력으로 받아서 현재 timestep에서의 이 출력으로 나옴.
→
- 매 timestep마다 RNN모듈이 재귀적으로 호출되어 출력 가 다음 timestep의 입력으로 들어감.
- 를 다음 입력으로 주는 동시에 출력값이 필요한 경우 로 출력된다.
- 파라미터 는 모든 timestep에서 동일한 값을 공유함
types of RNN
- one to one
Standard Neural Networks - one to many
Image Captioning - many to one : input=sequence of text
Sentiment Classification 또는 감정 분석 등 - sequence to sequence
Machine Translation, Video classification on frame level
Charater level Language Model
문자열의 순서를 바탕으로 다음 단어 예측
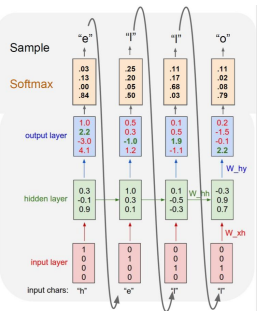
- hidden layer을 거쳐 output으로 구하려던 값의 probabilty가 1(100%)가 되는 방향으로 학습을 시켜야 한다.
- 세번째
l과 네번째l의 다음 값은 다르게 나와야한다. 네번째l은 세번째와 다르게hel까지 학습했던 데이터를 입력으로 넣어주기 때문 - 문장 뿐만 아니라 문단을 학습하려면 space, 줄바꿈,
',.등을 학습의 입력으로 넣어줘야한다.
Backpropagation through time (BPTT)
: backpropagation을 자기 자신으로 오는 weight에 대해서도 n번의 시간만큼 학습시키는 것
- 한 노드에는 input weight, output weight, self weight
Vanishing/Exploding Gradient Problem in RNN
fully connected layer로 구성된 rnn을 많이 사용하지 않음 - backpropagation 과정에서 동일한 matrix를 매번 곱해야 하기 때문에 gradient가 기하급수적으로 작아지거나 커지는 패턴이 나타나게 됨
Long Short-Term Memory (LSTM)
Solving long-term dependency problem

- i: Input gate, Whether to write to cell
- f: Forget gate, Whether to erase cell
- o: Output gate, How much to reveal cell
- g: Gate gate, How much to write to cell
Step of LSTM
Gated Recurrent Unit (GRU)
출처 - 부스트캠프 AI tech 교육자료
The Unreasonable Effectiveness of Recurrent Neural Networks - http://karpathy.github.io/2015/05/21/rnn-effectiveness/
LSTM - http://colah.github.io/posts/2015-08-Understanding-LSTMs/
[부스트캠프 AI Tech] Week 4 - Day 3
