Attention
encoding 과정에서 마지막에는 앞 단어의 모든 정보가 들어가 있음. 하지만 hidden state 차원이 정해져 있기 때문에 정해진 차원안에 압축하여 집어넣어야 함. 즉, 멀리 있는 정보는 소실될 수 있다.
👉 순차적으로 나온 encoder hidden state 벡터 중 decoder에서 단어를 생성할 때 각 timestep에서 필요한 정보를 encoder에서 선별하여 가져옴
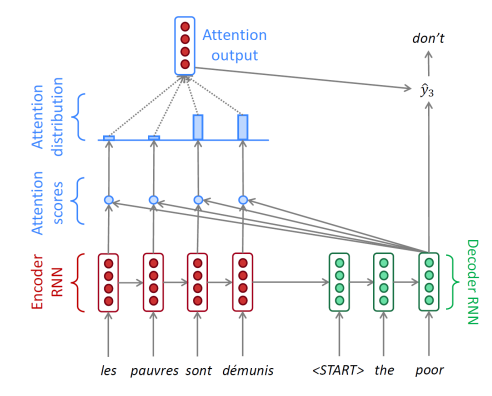
- decoder hidden state 벡터 하나와 encoder hidden state 벡터 set이 attention의 입력으로 들어감
- attention output(가중평균 된 encoder의 output)과 decoder hidden state 벡터를 이용해서 예측
Teacher forcing : 전 timestep에서 잘못된 예측을 했어도 다음 step에서 정답 input을 넣어줌. 학습이 빠르고 용이하게 진행되지만 실제 test과정과 다르기 때문에 둘을 적절히 결합한 방식도 있음.
Attention Mechanisms
-
Luong attention
- dot
- general
- concat
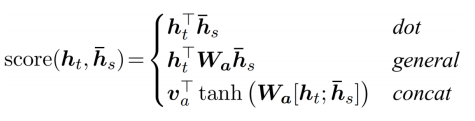
-
Bahdanau attention
- concat-score
Beam Search
greedy decoding : 다음 단어를 예측할 때 가장 높은 확률을 가진 단어 하나만을 선택하여 decoding
all possible sequences y : 한 timestep 에서 다음으로 나올 단어의 모든 수를 예측. 예측 가능 단어 수를라 할때 의 복잡도를 가지므로 기하급수적으로 증가하는 경우의 수를 계산하기는 힘들다
- 이 둘의 사이의 차선책이 beam search
: decoder의 매번 timestep마다 사전 정의한 개의 가능한 경우의 수를 고려하여 decoding 후 최종적으로 나온 개의 후보 중 가장 확률이 높은 것을 선택. = beam size (일반적으로 5 ~ 10)

probability에 log를 취함으로 확률 값이 클수록 결과도 커짐.
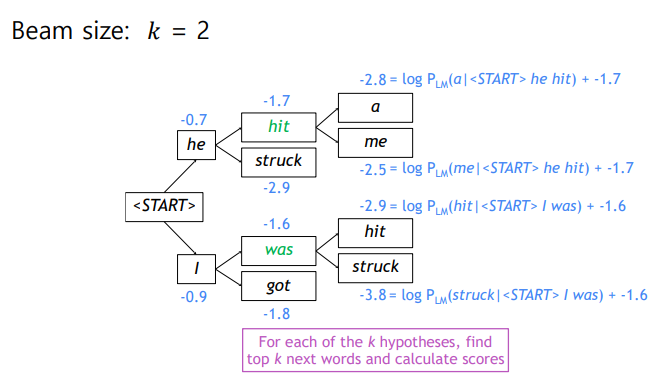
-
각 timestep에서 k의 경우의 수 루트마다 확률 값을 계속 더함
-
두 번의 timestep으로 경우의 수가 개 만큼 늘었지만 각 루트마다 최댓값만을 뽑기 때문에 결국 개의 경우로 추릴 수 있다.
-
각 경로마다 <END> 토큰이 나오면 해당 경로는 일시 중지하고 이에 대한 정보를 따로 저장
-
beam search의 종료 방법 : 1.미리 timestep 를 정함 2. <END>토큰의 수 을 정함
-
예측 문장이 길어진 경로에서는 상대적으로 score가 낮을 수 밖에 없다
→ normalize by length
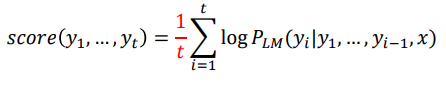
Precision and Recall
기존 방식으로 모델을 테스트할 때 단어 하나를 추가할 경우에는 sequence의 위치가 하나씩 밀려나므로 정확도 낮게 평가되는 오류를 일으킬 수 있음.
→ 문장 전체를 평가해야함

- 일치하는 단어의 수를 고려하기 때문에 순서가 바뀌어도 F-measure은 변하지 않음.
BLEU score
기계 번역의 정확도를 평가하는 척도
N-gram overlap : 연속된 n개의 단어의 문구가 ground truth와 얼마나 겹치는가
- precision만을 고려 → 번역된 문장에서 문맥상 어느 정도 생략되는 단어가 있음. 재현율 보다는 prediction에서 정확도만 고려

brevity penalty : reference보다 짧은 문장을 생성한 경우에는 그 비율만큼 낮춤
BLEU score가 번역 문장 평가에 있어서 갖는 단점
참고: Tangled up in BLEU: Reevaluating the Evaluation of Automatic Machine Translation Evaluation Metrics
출처 - 부스트캠프 AI tech 교육자료
https://web.stanford.edu/class/cs224n/slides/cs224n-2019-lecture08-nmt.pdf
dot product attention - https://wikidocs.net/22893
attention mechanism 부분별 자세한 설명 - https://bigdaheta.tistory.com/m/67
Bahdanau Attention(concat attention) - https://wikidocs.net/73161
[부스트캠프 AI Tech] Week 5 - Day 1
