RNN 모델의 경우 멀리 떨어져있는 데이터의 정보를 가져올 때 gradient vanishing, exploding, long term dependencing과 같이 정보의 손실, 변질이 일어남
B-Directional RNNs : 순차적으로 왼쪽의 정보를 가져오는 Forward RNN과 오른쪽에서 정보를 가져오는 Backward RNN을 병렬적으로 사용. 각 단어의 hidden state를 concat하여 사용
query : 어느 벡터를 선별적으로 가져올지 기준이 되는 벡터
key : query와 내적이 되는 재료벡터
- query벡터를 통해서 주어진 key벡터 들 중에 어느 벡터가 높은 유사도를 갖는지
- values와 key의 개수는 동일


- query와 key의 내적을 softmax한 값과 values를 곱하여 각 단어에 대한 유사도의 가중평균치를 구함(output vector)
- query의 row값들에 대해 병렬적 계산 가능
Scaled Dot-Product Attention
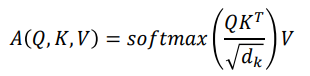
- query와 key벡터의 차원 수 에 대해 차원 수가 많아질수록 분산이 커지고 softmax값이 한 쪽으로 치우져저 있음. 작을 수록 좀더 고르게 분포
👉 softmax값이 query와 key의 dimension에 영향을 받기 때문에 학습을 안정화해주기 위해 로 나눠줌.(scaling)
Multi-Head Attention
- 동일한 sequence가 주어졌어도 특정 query에 대해 다른 측면에서 여러 정보를 가져오기 위해
- 병렬적으로 계산하므로 충분한 gpu가 있다면 sequential operation와 maximum path length 에 대해 의 복잡도를 가진다. (RNN의 경우 )
Transformer 후처리 과정
- Block-Based Model : 두개의 sub-layer, Add & Norm(residual connection & Layer Normalization)
- Residual connection : attention 결과를 자기 자신과 더해줌(multi head attention 입,출력 차원이 같기 때문에 가능)
- Layer Normalization : 벡터의 각 차원 값을 정규화하여 평균과 분산을 같게
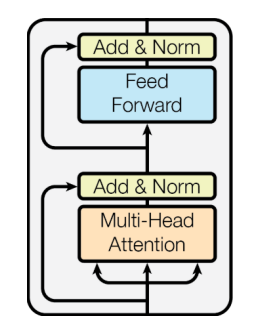
- Positional Encoding : 각 벡터에 단어의 위치정보를 더하여 모델의 입력으로 사용
- Warm-up Learning Rate Scheduler : 학습을 좀 더 빠르게 수행하기 위해 적절히 learning rate라는 hyperparmeter의 값을 적절히 조정
- Masked Self-Attention : 사용하지 않는 학습 과정에서 뒤 단어의 정보를 0으로 처리. 정보의 접근 가능여부
출처 - 부스트캠프 AI tech 교육자료
http://jalammar.github.io/illustrated-transformer/
[부스트캠프 AI Tech] Week 5 - Day 4
