
Intro
AIDT 프로젝트에서 대시보드 API를 개발하면서 도움이 되었던 책인 <업무에 바로 쓰는 SQL 튜닝> 을 소개하면서 이 책을 바탕으로 어떻게 내가 업무에서 쿼리를 개선했는지 적어보았다.
AIDT Dashboard
교육 시스템의 학생 대시보드 API를 개발했다.
대시보드는 주로 조회용이기에 조회 시 인덱스 설계가 중요했다.
사수와 2인 체제로 대시보드 데이터베이스 설계를 할 때도 사전 인덱스를 어떻게 설정할 지 간단히 이야기하고 설계를 들어갔다.
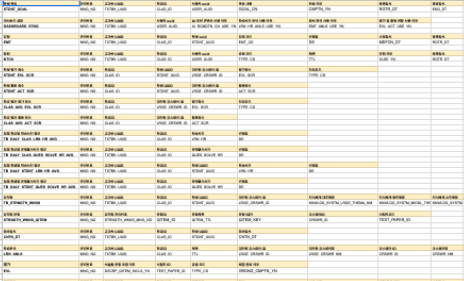
(이후에 변경되었다)
인덱스 설계
API 개발을 다 하고 나서 기존에 짠 쿼리를 보면서 인덱스 설계를 진행한다.
관리번호는 PK로서 자동으로 인덱스가 추가되기에 인덱스 설계에서 제외한다.
데이터 설계상 UK로 설정해야 하는 컬럼들 또한 자동으로 인덱스가 추가되기에
그냥 인덱스 추가와는 구분했다.
인덱스 2개 (단일과 다중)
학생의 감정을 저장하는 감정 테이블의 경우 인덱스가 2개 구성이었는데,
하나는 학생별 조회를 위한 핛를 단일 컬럼 인덱스로 하고,
다른 하나는 교, 학, 핛로 다중 컬럼 인덱스를 구성했다.
항상 인덱스는 인덱스 컬럼 순서가 중요한데, 학생 기준으로만 조회할 일이 있는데
막상 다중 컬럼이라서 교, 학 뒤에 학생이 있으면 제 역할을 못한다.

(이후에 변경되었다)
쿼리 고치기
API 개발 이후 기능 이슈 등을 수정하면서 쿼리 지적을 받거나 위 책에서 읽은 내용들에 대해서 쿼리를 개선한다.
1. 인덱스 컬럼 순서 조정하기
프로젝트의 인덱스는 교, 학, 기타 순으로 정해져 있다.
따라서 where절 조건절 컬럼의 순서도 따라 맞춰야 한다.
학급, 교과서처럼 인덱스 순서와 맞지 않는 컬럼들을 조정한다.
2. 불필요한 처리 없애기
<책 내용>
- NOT NULL 컬럼에 IFNULL() 함수를 적용할 필요가 없다.
- 중복되지 않을 데이터에 DISTINCT를 적용할 필요가 없다.
- SUBSTR() 등의 함수를 꼭 사용해야 하는 경우인가? 범위 조건절로 처리하거나 여러 where 조건절로 처리할 수 없는지 고민해보자.
IFNULL()을 해놓고 또 IFNULL()을 한 경우가 있어서 개선했다.
날짜 비교를 위해 DATE_FORMAT()을 사용할 때 인덱스 컬럼인지 확인했다.
3. 중복이 아닌 데이터를 합치려면 UNION ALL
<책 내용>
- UNION ALL은 단순히 합치기 작업만 하지만, UNION은 합치기 + 중복 제거까지 하기 때문에 불필요하게 성능을 낮출 수 있다.
UNION을 사용한 쿼리들을 살펴보며 쿼리들이 서로 중복 가능성이 있는지 재확인했다.
중복 가능성이 없으면 UNION ALL로 바꿔놔야지;
4. 대체적으로 서브쿼리보단 조인을
<책 내용>
- 대체적으로 서브쿼리보다는 조인이 성능상 낫다.
- 인덱스 컬럼을 조건으로 한 스칼라 서브쿼리는 많은 리소스를 소모하지 않는다.
(때로는 불필요한 정보를 가져오는 것보다 서브쿼리가 나을 때도 있음)
나의 경우는 서브쿼리에서 조인으로 많이 바꿨다.
서브쿼리로 가져올까 했던 것들은 UNION으로 고친 다음에 FROM 인라인 뷰로 SELECT했다.
5. 의도적 인덱스 파괴, 함수의 대안 찾기
<책 내용>
- 데이터 타입을 확인해서 자동 형변환으로 인덱스가 깨지지 않도록 해라.
- 데이터가 많은 경우 인덱스를 의도적으로 IGNORE하거나 YEAR()등의 함수로 인덱스를 깨뜨린다.
- '1988%' 보다는 '1988-01-01' ~ '1988-12-31'을 범위로 조건절을 주는 게 더 낫다.
- 이름의 경우 대문자 컬럼을 추가해서 조건절에서 대문자로 찾는 게 낫다.
(lower() 말고)
UPDATE등 할 때는 인덱스가 오히려 느려진다고 함.
수정/삭제할 때는 where 조건절 여러 개보다 가능하면 관리번호 등으로 슥 찾아서 하는 게 더 낫지 않나? 생각해 봄.
명령어
EXPLAIN과 DESC로 실행 계획이나 컬럼 타입 등을 잘 체크하자.
Outro
책을 대시보드 하기 전에 1번, 하고 나서 1번 읽었는데, 닥쳐보니 책이 더 잘 와닿더라.
막상 해보니 거창한 쿼리 개선이라기보다 대부분 불필요했던 것들을 제거하는 과정이었다.
데이터의 타입, 도메인에 대한 이해가 선행되어야 하는 작업이다.
책에서는 프로젝트에 적용한 일부만 적어봤지만, 실제로 책은 나 같은 신입에게 실제로 만날 법한 예시를 잘 들어주었다.
힌트 사용도, 더 높은 쿼리 개선에 대해서도 더 알고 싶다.
친절한 SQL 튜닝 책이 생각난다. MYSQL 강의와 함께 재복습을 해봐야겠다.
