Session Review
Train data - Test data
훈련데이터와 테스트데이터로 나누는 이유?
당연히 훈련한 데이터로 테스트까지 진행하면 모든 데이터를 설명 가능
but, 이것이 모델이 좋아서 잘 예측한 것인지 아니면 이미 이 데이터를 학습했기 때문에 잘하는 것인지 확인하기 어려움
❗️시계열 데이터
시간이 모델에 중요한 요인으로 작용한다면
시간 순서에 따라, 오래된 데이터를 훈련데이터로, 비교적 최근의 데이터를 테스트데이터로 채택
-> 시간이 뒤죽박죽인 경우 제대로된 결과 나올 수 없음
BUT, 데이터에 시계열 데이터가 들어있다고 해서 무조건 시계열 중심으로 train, test를 나눠서는 안됨
-> 우리가 찾고자 하는 것이 어떤 특성을 중심으로 하는 것인지 (e.g. 미래의 집값을 예측하는 것인지 아니면 단순히 집값만 예측하면 되는 것인지)를 파악한 후 어떻게 데이터를 나눌지 결정
Train data - Test data 비율
보통 80:20 or 75:25 정도가 일반적
만약, 나누는 비율에 따라 모델 결과(R2 값)가 극명하게 달라질 경우 -> 그 모델은 쓰지 못함!!
(물론, 약간의 오차는 허용됨)
다중선형회귀
다중선형회귀모델:
feature 2개 이상인 선형회귀모델
-> feature를 계속해서 넣어준다는 것은 dimension이 늘어난다는 것 = 데이터가 더 입체감이 생김 -> 데이터를 분리해서 캡쳐하기 용이
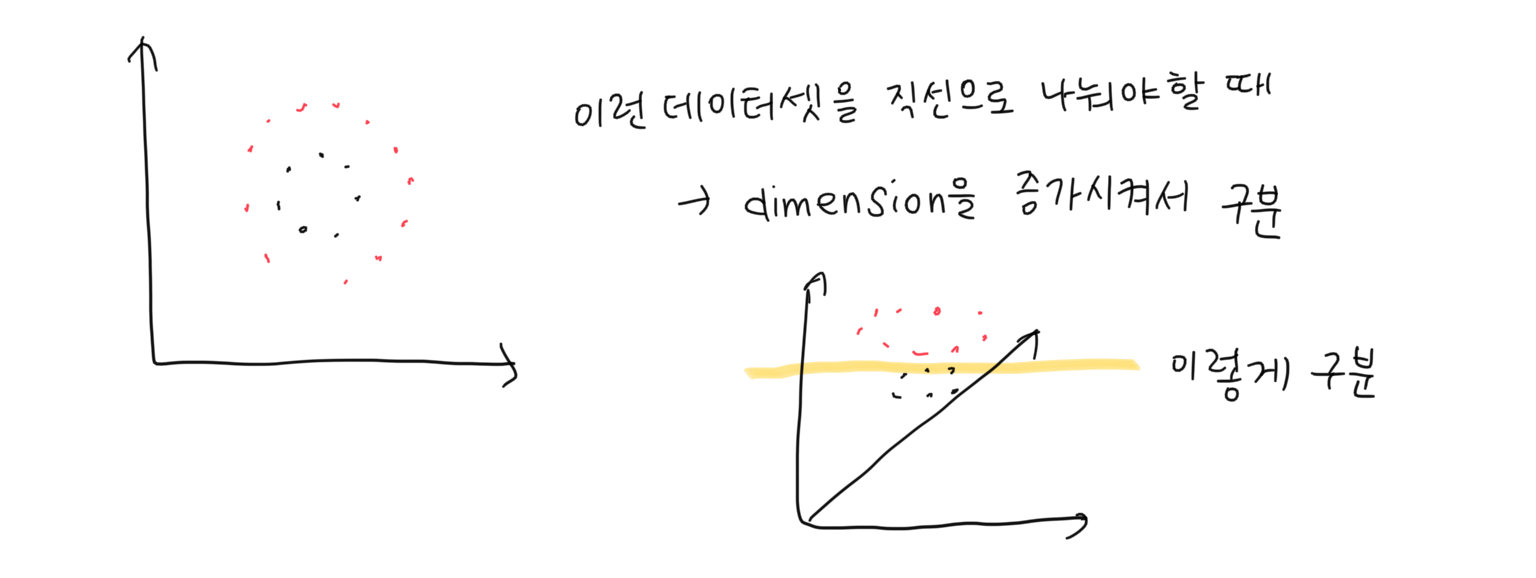
Feature importance
여러 feature 중에 어떤 것이 내가 원하는 target을 잘 예측할 것인가를 결정할 때 feature importance를 고려함
b.c. feature를 증가시키는 것은 다 cost -> 적당한 수준에서 끊어서 몇 개만 골라서 채택
+) feature들 간의 관계는 correlation을 통해 알 수 있음 (상관관계)
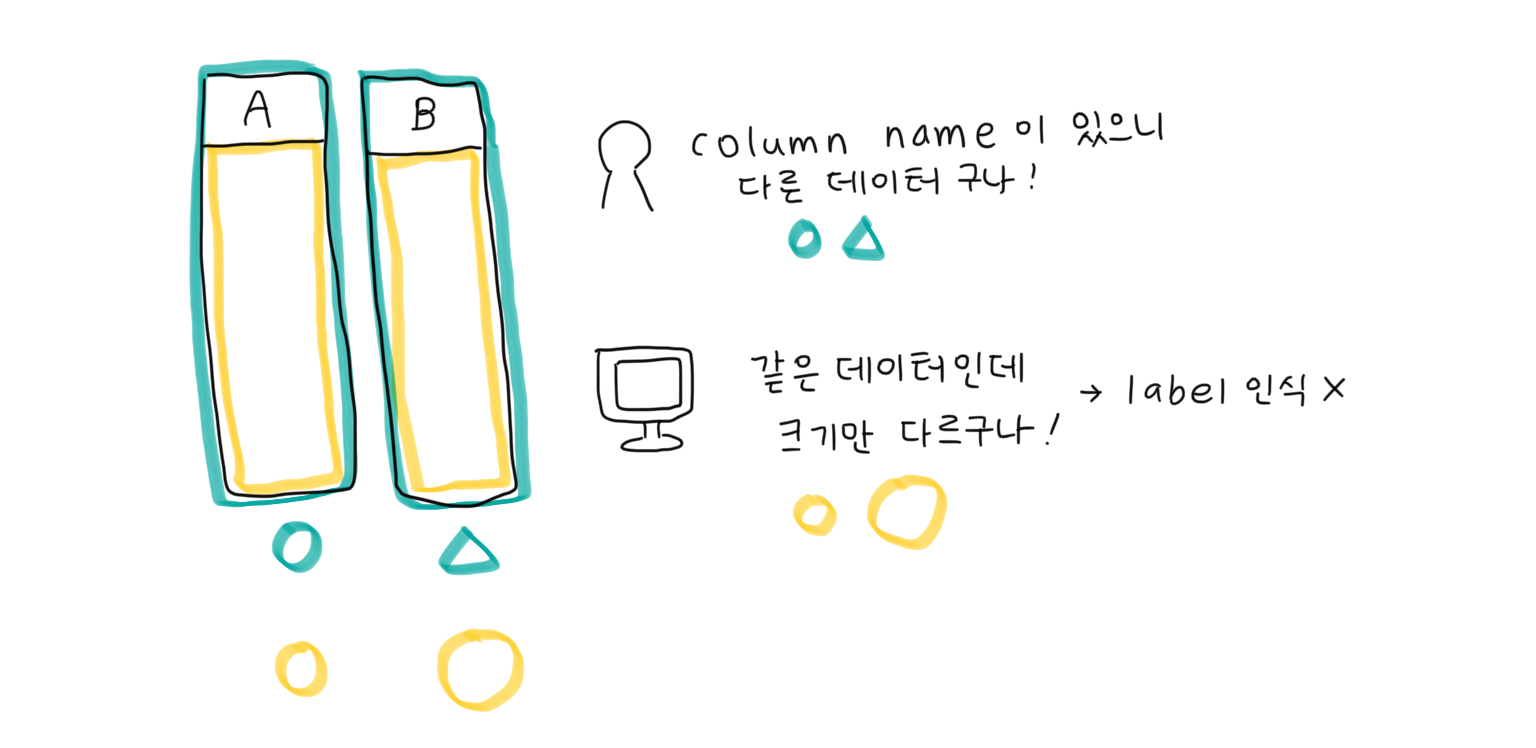
Multicollinearity(다중공선성)
feature 간의 상관관계(correlation)가 너무 높을 때 발생하는 것 = 크기만 다른 동일한 데이터일 때
사람이 보기에는 column name이 있어서 다른 데이터라고 생각할 수 있지만, 모델은 이러한 column name 없이 데이터(숫자)만 받아오기 때문에 크기만 다르고 실질적으로는 동일한 feature들이 들어온다고 인식함
-> 크기가 큰 feature만 받아들이고, 크기가 작은 feature는 제대로 반영되지 않음
회귀 평가지표 (Evaluation Metrics)
- MSE: 보통 많이 사용하는 지표 but, 제곱을 하다보니 이상치에 다른 지표들보다 민감함 + 단위 스케일에 따른 오류의 양을 직관적으로 확인하기 어려움
- MAE: 제곱을 하지 않기 때문에 단위 스케일이 변화하지 않기 때문에 오류가 발생할 경우 그 양을 직관적으로 확인 가능 -> 설명이 쉬움
- RMSE: MSE의 단점을 보완한 방법 (스케일을 실제와 비슷하게 만들어주려고)
- R-squared: 회귀모델의 설명력을 보여줌 (1에 가까울수록 모델이 데이터에 대한 설명력이 높다) -> 음수가 나온경우에는 기준모델보다 내가 만든 모델이 더 못한 경우
-> cost function을 계산할 때, MSE 자주 사용
데이터가 있고, 그 데이터의 패턴을 캡쳐하는 모델을 만들려고 하는 것이 model development
-> 어떻게 그 패턴을 ‘잘’ 캡쳐하나?
잘 '캡쳐'한다 = 데이터와 모델의 예측 간의 거리인 에러(cost)를 최소화하는 방법으로 만들어준다 = cost function을 최소화
👀 회귀모델을 만들 때 봐야 하는 것
R2(MSE), p-value, coefficient size(계수의 크기)
❗️MSE는 제곱하는 것이라 에러가 더 커지는거 아닌가요? RMSE 대신에 MSE 를 쓰는건 데이터의 종류에 따라 다른건가요?
데이터 분석에서 중요한 것은 ‘상대성’ -> 비교대상과의 차이를 통해 모델을 만드는 것
=> MSE의 경우 비교대상과의 차이를 더욱 극대화하기 때문에(현미경 역할) 더욱 효과적으로 비교가 가능함
+) 에러의 역할에 따라 다름: 객관적인 성능을 파악하기 위하는 것이 아니라 다른 모델과의 비교를 위해서 에러를 사용할 때에는 MSE가 유용
❗️왜 모델이 기준모델과 동일할 경우 r-squared 값이 0이 나오는가?
기준모델과 같으면 -> SSE/SST 값이 1이므로 1 - (SSE/SST)는 0이 됨
Overfitting - Underfitting
- Overfitting(과적합): 훈련데이터의 특수한 성질까지 과하게 학습하여, 일반화를 못해 결국 테스트 데이터에서의 오차가 커지는 현상 = 분산이 높은 상태
- Underfitting(과소적합): 훈련 데이터에 과적합도 못하고, 일반화 성질도 학습하지 못해 훈련/테스트 데이터 모두에서 오차가 크게 나오는 현상 = 편향도 높고, 분산도 높은 상태
Bias - Variance
- Bias(편향): 선형회귀와 같은 머신러닝 method가 트레이닝 과정에서 데이터 간의 진짜 관계를 파악하지 못하는 것 (e.g. 선형회귀는 직선으로만 예측선을 긋기 때문에 커브가 있는 데이터간의 관계는 제대로 파악하지 못함) = train data와 model 사이의 오차
- Variance(분산): 데이터셋 간의 fit 차이 = test data와 model 사이의 오차
e.g. 단순선형모델 - 비선형모델
| Property | Straight line(단순선형모델) | Squiggly line(비선형모델) |
|---|---|---|
| Bias | Relatevely high bias: Train set 데이터의 실제 관계를 파악하지 못함 | Low bias: Training set의 모든 데이터를 포함 |
| Variance | Relatively low variance: 데이터셋이 달라져도 예측선부터 데이터까지 거리의 제곱합이 거의 비슷 | High variability: 데이터셋에 따라 라인에서부터 데이터까지의 거리의 제곱합이 매우 달라짐 |
| Evaluation | 엄청 좋지는 않지만 그래도 보통 정도의 예측 가능 -> 편차가 많이 없는 설명력 제공 | Hard to predict how well the line will perform -> 데이터셋에 따라 어떨 때는 엄청 잘하고, 어떨 때는 엄청 못하기 때문 |
-> 비선형모델의 경우 train set에서는 엄청나게 fitting이 잘 되지만, 막상 test set에서는 그 능력이 떨어지는 overfitting이 발생
=> 가장 이상적인 모델은 low bias, low variance인 모델
훈련 과정에서 편향이 작으면 모델이 데이터를 과하게 캡쳐하게 되고, 이는 새로운 데이터가 들어와서 테스트할 때, 오차가 커질 가능성을 높임 -> 이는 분산이 높아질 가능성이 많아진다고 할 수 있음
❗️ 편향과 분산의 트레이드오프
나에게 딱 맞는 옷(편향이 낮음)은 동생과 같이 입을 수 없음(분산이 높음) <-> 널널한 옷을 사면 동생과 같이 입을 수 있지만(분산이 낮음), 나에게 딱 맞지는 않음(편향이 높음)
Food for Thought
R-squared vs. SEE
- R-squared: compare distance between actual-mean and distance between estimated - mean (기준모델과 비교했을 때 내 모델이 얼마나 더 실제 데이터를 잘 설명했는지 확인)
- SEE(Standard Error of the Estimate): calculate distances between estimated and actual values (distances = errors) -> 분모인 n-2는 degree of freedom(자유도)
회귀계수 부호의 해석
회귀계수의 부호는 중요하지 않음 (x의 나열 순서에 따라 달라질 수 있기 때문) -> 다만, 해석이 중요함
e.g. 당뇨환자의 포도당 수치에 따른 건강상태를 예측할 때, 포도당 수치를 1,2,3 순서로 하면 회귀계수는 음수가 됨 (x가 우측으로 이동할수록(포도당 수치가 높아지면) 건강은 나빠지니까)
but, 포도당 수치를 3,2,1 순서로 하면 회귀계수는 양수가 됨 (x가 우측으로 이동할수록(포도당 수치가 낮아지면) 건강은 좋아지니까)
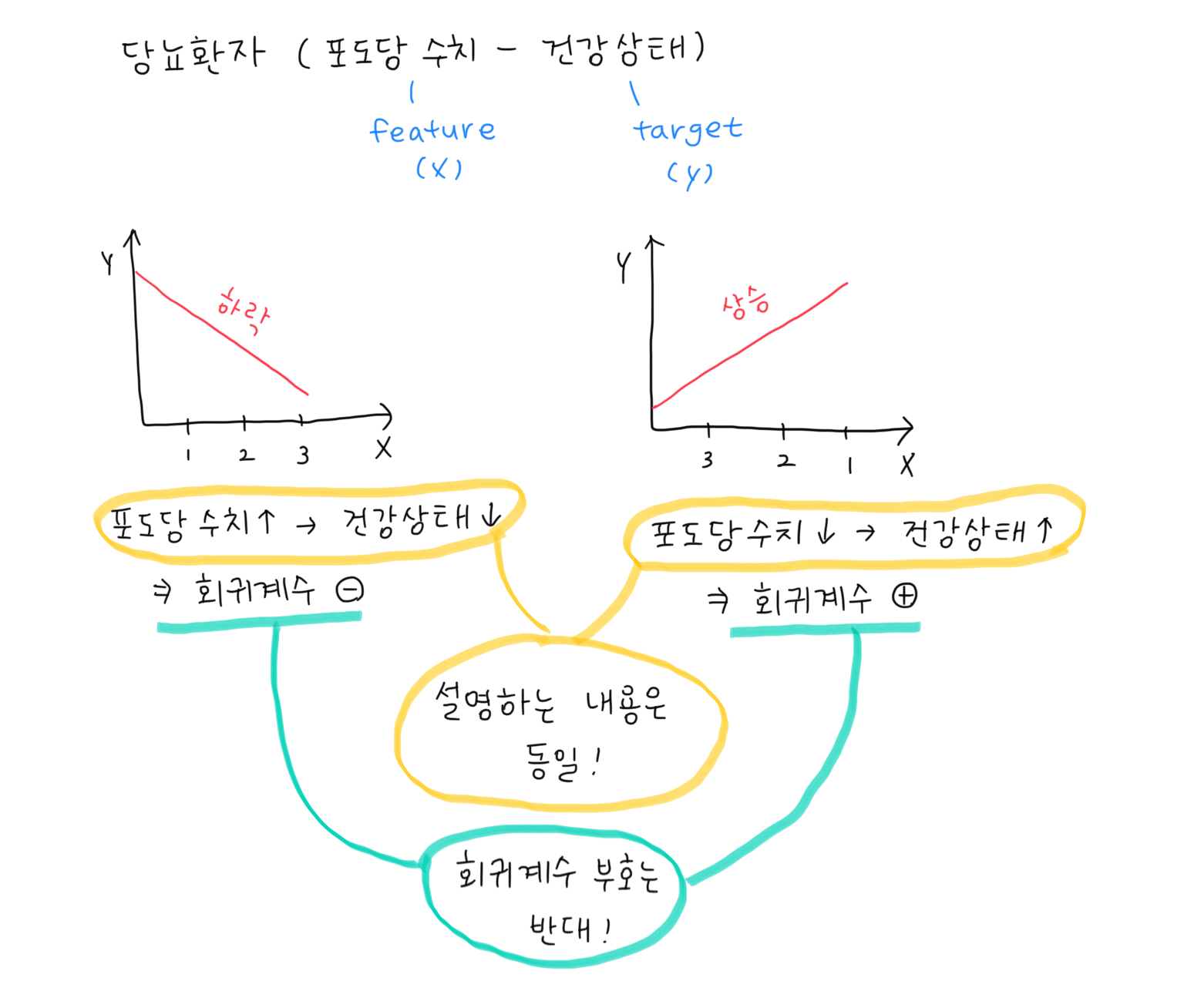 -> 회귀계수의 부호는 다르나 결과적으로 말하고자 하는 바는 동일 -> 해석이 중요!
-> 회귀계수의 부호는 다르나 결과적으로 말하고자 하는 바는 동일 -> 해석이 중요!
