
Session Review
정보를 미리 파악한 후 데이터 불러오기를 해야 하는 이유?
big data를 작업하기 위해서는 불러오는 시간이 매우 길다.
그 과정에서 정보를 파악하지 못한다면 예상치 못한 에러가 나왔을 때 해결하기 어렵다.
-> library 활용 e.g. pandas.read_csv()
❓ 좋은 데이터셋이란 무엇인가?
본인의 목적에 맞는 데이터를 가지고 있는 것. 인사이트를 얻을 수 있도록 컴퓨터가 이해하기 쉬운 형태로 가공
❓ CSV가 어떤 것을 의미하는가?
CSV는 comma-separated values로 몇가지 필드를 comma 즉, 쉼표로 구분한 텍스트 데이터 및 텍스트 파일 (출처)
❓ EDA와 Data Preprocessing의 차이는?
EDA: 데이터가 어떻게 구성되어 있는지, 어떠한 분석방법이 적합할지 확인하는 과정 / Data Preprocessing: 분석에 앞서 자료를 예쁘게 정리하고 에러를 미리 방지하는 과정 (참고자료)
EDA(Exploratory Data Analysis): 탐색적 데이터 분석
데이터가 어떤 것인지 알고 있어야 어떠한 분석이 가능한지 알 수 있다.
대부분의 raw data는 바로 분석하기 어려움(insight 얻기 어려움) -> 미리 탐색하여 "견적"내는 분석이 EDA
uni는 데이터 확인, multi-variate는 데이터를 확인하고, 더 나아가 변수들 간의 관계 파악이 주요 목적
Properties of Histogram
- quantitative data
- no gaps (between bars)
- bar width - bin size or class size (each bar width is same)
- y-axis corresponds to the frequency
[40,50) : include 40, not include 50 = 40 to 49
Stem-and-leaf plot
- 정수, 100이상, 소수 모두 key(stem) 먼저 찾고 거기에 맞춰서 leaf 나열
- 해당 stem에 해당하는 leaf 없을 경우에는 leaf 칸을 비워둠
Box and Whisker plot
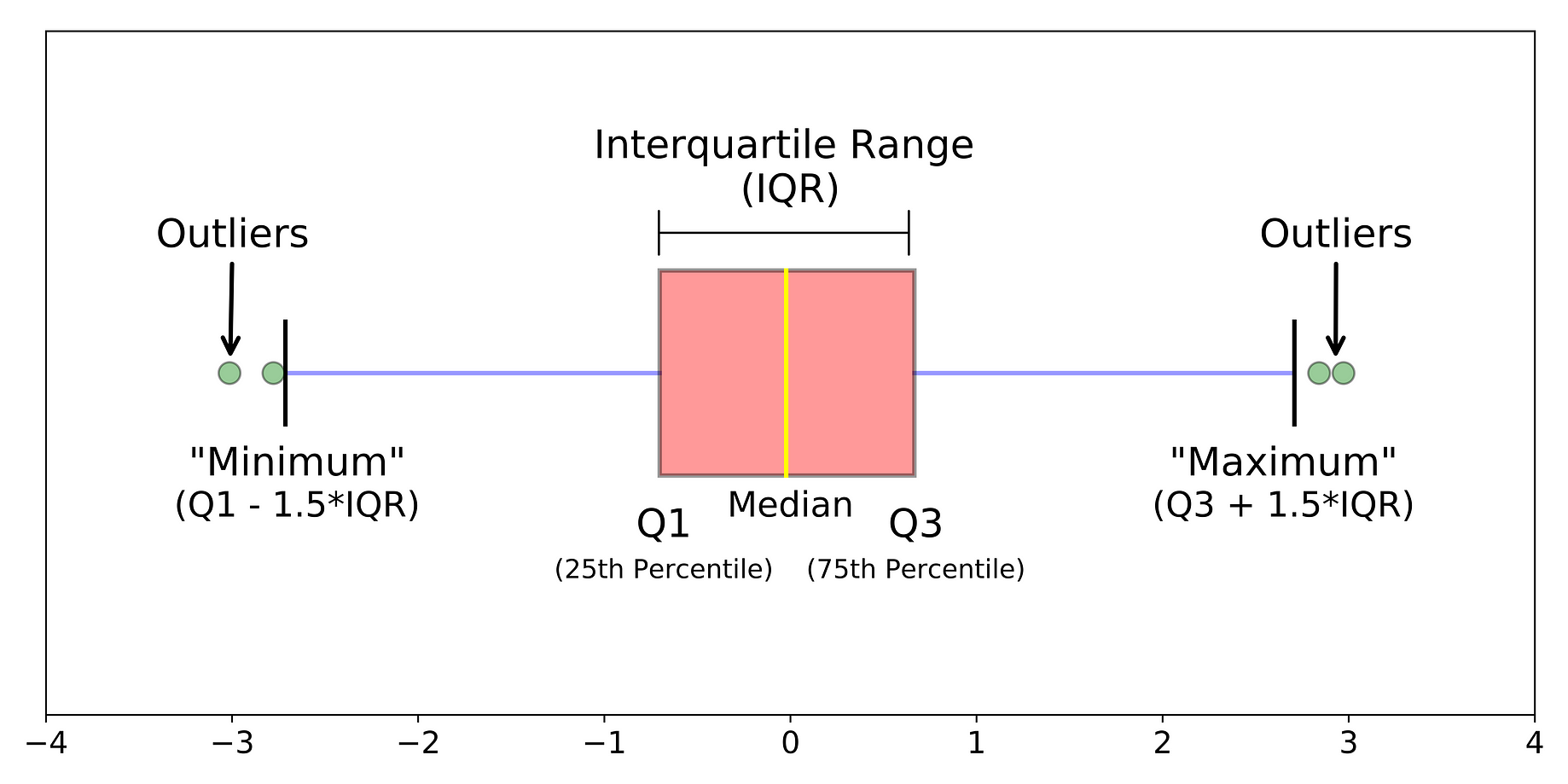
- upper quartile (Q3): 상위 25%
- lower quartile (Q1): 하위 25%
- whisker: 최소, 최대와 각 quartile들 연결하는 선
EDA를 위한 pandas Function
각각 함수들 reference 검색 후 써보기!
- isnull(), isna(): missing data 찾기
- fillna(0): missing data 0으로 대체
- df.to_cvs('name')
- gt, lt
Data Preprocessing (전처리)
Garbage In Garbage Out
e.g.문제 해결에 맞지 않는 데이터
- cleaning: noise 제거, 보정 - 오류 (missing value) 깨끗하게 다듬기
- integration
- transformation(scaling)
- reduction
Assignment
df.head() # 불러온 데이터의 상위 5개 표시
df.head # method출처: https://stackoverflow.com/questions/53999279/whats-the-difference-between-df-head-and-df-head
