
안녕하세요. 오늘은 컴퓨터 구조를 공부하다 유니코드를 학습하게 되어 자바스크립트에선 유니코드 인코딩 방식인 UTF-8 형태로 어떻게 인코딩이 가능한지 궁금한 마음에 블로그에 포스팅을 하게 되었습니다.
문자 집합과 인코딩
컴퓨터는 기본적으로 0과 1로 이루어진 비트를 통해 정보를 인식합니다.
따라서, 0과 1로 문자를 표현하는 방법을 알아야하는데 여기서 문자 집합, 인코딩, 디코딩이라는 개념이 등장 합니다.
- 문자 집합 - 컴퓨터가 인식하고 표현할 수 있는 문자의 모음
- 인코딩 - 문자 집합에 속한 문자를 0과 1로 이루어진 문자 코드로 변환하는 과정
- 디코딩 - 0과 1로 이루어진 문자 코드를 문자로 변환하는 과정
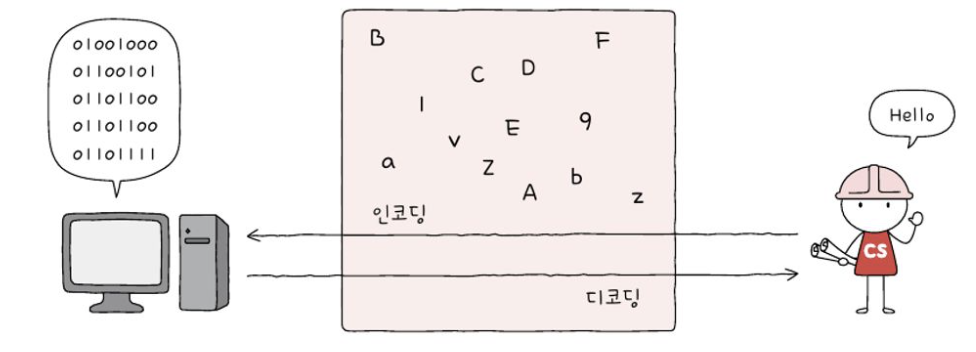
위 그림 처럼 문자를 문자 코드로 변환하는 것이 인코딩, 문자 코드를 문자로 바꾸는 과정이 디코딩 입니다.
유니코드란?
전 세계의 모든 문자를 다룰 수 있는 통일된 문자 집합
일부 문자 및 특수 문자를 지원하는 아스키 코드와 달리 한글 인코딩을 지원하며, 대부분 나라의 문자 및 특수문자, 화살표, 이모티콘 까지 코드로 표현할 수 있습니다.
또한 유니코드의 경우 글자에 부여된 값 자체를 인코딩 된 값으로 삼지 않고 다양한 방법으로 인코딩 한다는 특징이 있습니다.
글자에 부여된 값 자체를 인코딩 된 값으로 삼지 않고 다양한 방법으로 인코딩 한다?
유니코드는 U+와 16진수로 이루어진 이루어진 유니코드 코드 포인트라는 값을 가지고 있습니다.
해당 값은 UTF-16으로 인코딩 된 16진수 표현법입니다.
유니코드 인코딩 방법은 UTF-8, UTF-16, UTF-32로 총 3가지 가 있습니다.
아래 예시와 함께 함께 살펴보겠습니다.
예시) '한'과 '글'을 유니코드 방식으로 인코딩 하기(UTF-8)
UTF-8
가장 많이 사용되는 가변 길이 유니코드 인코딩 방식
UTF-8의 경우 1바이트 ~ 4바이트의 인코딩 결과를 만들어 내며, 몇 바이트가 될진 유니코드 문자에 부여된 값의 범위에 따라 설정 된다는 특징이 있습니다.
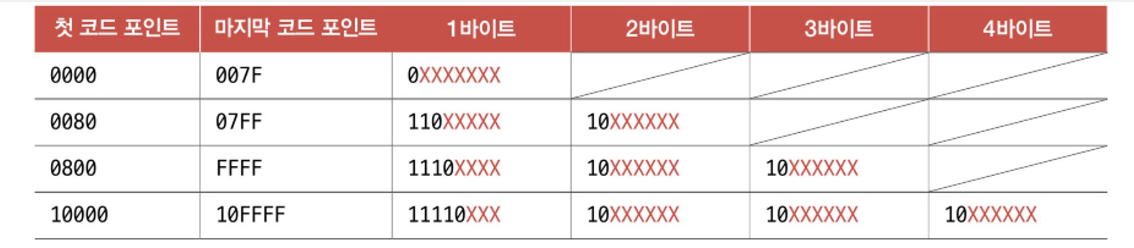
- 0000(16) ~ 007F(16) : 1바이트로 인코딩
- 0080(16) ~ 07FF(16) : 2바이트로 인코딩
- 0800(16) ~ FFFF(16) : 3바이트로 인코딩
- 10000(16) ~ 10FFFF(16) : 4바이트로 인코딩

한의 경우 U+D55C로 나타내는 것을 확인할 수 있습니다. 이는 16진수와는 다른 개념이며 단지 '한'이라는 글자를 나타내기 위한 유니코드 값인 것을 알 수 있습니다.
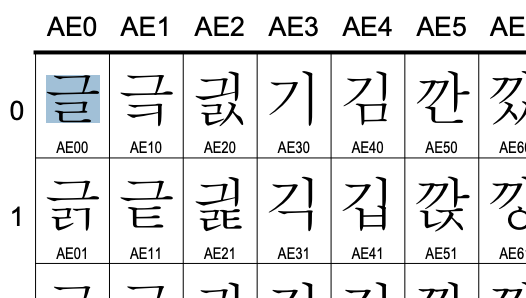
글의 경우 AE00으로 나타내는 것을 알 수 있습니다.
인코딩을 위해 2진수로 변환하게 되면 각각 1101 0101 0101 1100(2), 1010 1110 0000 0000(2)로 변환됩니다.
다시 이 표를 살펴보면 D55C(한)과 AE00(글)의 경우 0000 ~ FFFF 범위에 포함되므로 3바이트에 포함됩니다.

해당 규칙에 맞게 인코딩 하게 되면 위와 같은 결과로 인코딩 되는 것을 확인할 수 있습니다.
자바스크립트의 UTF-8 인코딩 및 디코딩
예시 1) UTF-8 형태로 '한' 인코딩
const textEncoder = new TextEncoder();
const bytes = textEncoder.encode('한') // default utf-8
console.log(bytes);
/*
Uint8Array {
'0': 237,
'1': 149,
'2': 156,
__proto__: {
constructor: ƒ Uint8Array(),
BYTES_PER_ELEMENT: 1
}
}
*/우선, TextEncoder 인스턴스를 만든 후 encode 메서드를 호출 할 때 한을 인수로 추가 합니다.
bytes의 결과 값은 UTF-8로 인코딩된 텍스트가 포함된 Uint8Array를 반환하는 것을 알 수 있습니다.
UInt8Array는 TypedArray로 각 요소는 1바이트의 값을 의미 하며 10진수의 형태입니다.
즉, UTF-8은 3바이트이기 때문에 배열의 길이가 3인 UInt8Array 배열을 반환하며 각 요소는 인코딩이 완료된 10진수 형태의 숫자 입니다.
const binaryArray = Array.from(bytes, byte => {
return byte.toString(2)
});
const binaryString = binaryArray.join(' ');
console.log(binaryString); // '11101101 10010101 10011100'따라서 각 byte를 2진수로 변환할 경우, 이전에 보았던 2진수와 동일한 형태로 인코딩 된 것을 확인할 수 있습니다.
예시 2) 인코딩 된 결과 값을 다시 디코딩
const bytes = textEncoder.encode('한')
const textDecoder = new TextDecoder();
console.log(textDecoder.decode(bytes)) // 한디코딩을 하는 건 더 간단합니다. TextDecoder 인스턴스를 생성 후 decode 메서드 내 UInt8Array 형태의 bytes를 인수로 추가하면 '한'이 디코딩 된 것을 알 수 있습니다.
charCodeAt를 통해 다시 유니코드 코드 포인트 생성
javascript의 string prototype method 중 하나인 charCodeAt을 통해 유니코드 코드 포인트를 utf-16으로 인코딩 할 수 있습니다.
// '한'을 charCodeAt을 통해 10진수로 변환 시킨 후 toString을 통해 다시 16진수로 변환
const hexaDecimal = ('한'.charCodeAt()).toString(16);
// 변환된 값 출력
console.log(hexaDecimal) // 'd55c'
'한'의 유니코드 코드 포인트였던 d55c가 출력되는 것을 확인할 수 있습니다.
fromCharCode를 통해 다시 디코딩
// '한'의 유니코드 코드 포인트를 10진수로 변환한 값
const decimalHan = parseInt(hexaDecimal, 16);
// fromCharCode를 통해 해당 값을 디코딩
console.log(String.fromCharCode(decimalHan)) // '한'유니코드 코드 포인트를 10진수로 변환하여 fromCharCode의 인자로 호출할 경우 다시 디코딩 된 '한'을 확인할 수 있습니다.
레퍼런스
- 자바스크립트 문자열의 인코딩 & 디코딩
- 유니코드 테이블 pdf
- mdn - TextEncoder
- mdn - TextDecoder
- 혼자 공부 하는 운영체제 & 컴퓨터 구조 2장
