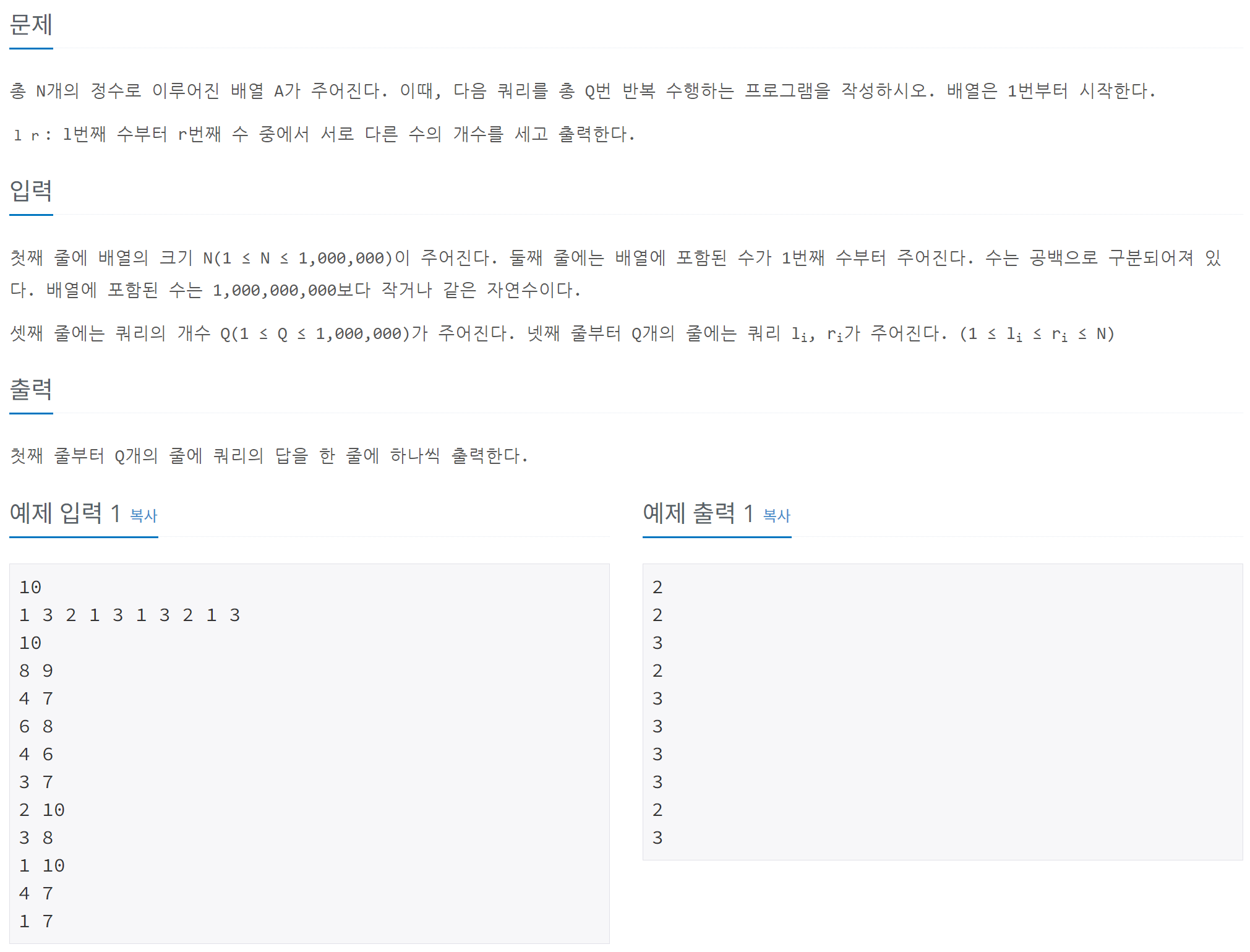
문제 설명
배열 A가 주어지고, 다음과 같은 Q개의 쿼리를 처리하는 문제이다:
- 쿼리 형태:
l r
배열의l번째부터r번째까지의 구간에서 서로 다른 수의 개수를 출력한다.
제약 조건
- 배열의 크기
N: 최대 1,000,000 - 쿼리의 개수
Q: 최대 1,000,000 - 각 수의 크기: 최대 1,000,000,000 이하의 자연수
문제 요구사항
- 각 쿼리에 대해 구간
[l, r]에서 서로 다른 수의 개수를 효율적으로 계산해야 한다.
코드
import java.io.*;
import java.util.*;
public class Main {
static class Query implements Comparable<Query> {
int idx, left, right, block;
Query(int idx, int left, int right, int block) {
this.idx = idx;
this.left = left;
this.right = right;
this.block = block;
}
@Override
public int compareTo(Query other) {
if (this.block != other.block) {
return Integer.compare(this.block, other.block);
}
return Integer.compare(this.right, other.right);
}
}
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
int n = Integer.parseInt(br.readLine());
int sqrtN = (int) Math.sqrt(n);
int[] arr = new int[n];
StringTokenizer st = new StringTokenizer(br.readLine());
for (int i = 0; i < n; i++) {
arr[i] = Integer.parseInt(st.nextToken());
}
// Coordinate compression
int[] compressed = Arrays.copyOf(arr, n);
Arrays.sort(compressed);
Map<Integer, Integer> valueToIndex = new HashMap<>();
int idx = 0;
for (int val : compressed) {
if (!valueToIndex.containsKey(val)) {
valueToIndex.put(val, idx++);
}
}
for (int i = 0; i < n; i++) {
arr[i] = valueToIndex.get(arr[i]);
}
int q = Integer.parseInt(br.readLine());
Query[] queries = new Query[q];
int[] results = new int[q];
for (int i = 0; i < q; i++) {
st = new StringTokenizer(br.readLine());
int l = Integer.parseInt(st.nextToken()) - 1;
int r = Integer.parseInt(st.nextToken()) - 1;
queries[i] = new Query(i, l, r, l / sqrtN);
}
Arrays.sort(queries);
int[] freq = new int[n];
int distinctCount = 0;
int currentLeft = 0, currentRight = -1;
for (Query query : queries) {
while (currentRight < query.right) {
currentRight++;
distinctCount += add(arr[currentRight], freq);
}
while (currentRight > query.right) {
distinctCount -= remove(arr[currentRight], freq);
currentRight--;
}
while (currentLeft < query.left) {
distinctCount -= remove(arr[currentLeft], freq);
currentLeft++;
}
while (currentLeft > query.left) {
currentLeft--;
distinctCount += add(arr[currentLeft], freq);
}
results[query.idx] = distinctCount;
}
for (int result : results) {
bw.write(result + "\n");
}
bw.flush();
bw.close();
}
private static int add(int value, int[] freq) {
if (freq[value] == 0) {
freq[value]++;
return 1;
}
freq[value]++;
return 0;
}
private static int remove(int value, int[] freq) {
if (freq[value] == 1) {
freq[value]--;
return 1;
}
freq[value]--;
return 0;
}
}풀이 과정
- 좌표 압축 (Coordinate Compression)
- 배열
a[i]의 범위가 최대 (10^9)이므로, 각 값을 압축된 값으로 치환하여 메모리 사용량 및 처리 효율을 높인다. - 구현 과정:
- 배열을 복사하여 정렬한다.
- 정렬된 배열에서 중복을 제거하며 각 값에 대해 새로운 인덱스를 할당한다.
- 시간 복잡도: (O(N \log N))
- 배열
int[] compressed = Arrays.copyOf(arr, n);
Arrays.sort(compressed);
Map<Integer, Integer> valueToIndex = new HashMap<>();
int idx = 0;
for (int val : compressed) {
if (!valueToIndex.containsKey(val)) {
valueToIndex.put(val, idx++);
}
}
for (int i = 0; i < n; i++) {
arr[i] = valueToIndex.get(arr[i]);
}- 쿼리 정렬 (Mo's Algorithm)
- 쿼리를 블록 크기에 따라 정렬한다.
- 정렬 기준:
- 왼쪽 값
(l)을 기준으로 정렬. - 같은 블록 내에서는 오른쪽 값
(r)을 기준으로 정렬.
- 왼쪽 값
- 블록 크기는 (\sqrt{n})으로 설정하여 쿼리 처리의 효율성을 높인다.
이렇게 하면 구간 이동 횟수를 최소화하면서 최적의 성능을 유지할 수 있다.
int sqrtN = (int) Math.sqrt(n);
Query[] queries = new Query[q];
for (int i = 0; i < q; i++) {
int l = Integer.parseInt(st.nextToken()) - 1;
int r = Integer.parseInt(st.nextToken()) - 1;
queries[i] = new Query(i, l, r, l / sqrtN);
}
Arrays.sort(queries);- 구간 확장 및 축소
- 현재 구간
[currentLeft, currentRight]를 유지하며, 각 쿼리에 맞게 구간을 이동한다. - 구간 이동 시 숫자를 추가하거나 제거하며, 서로 다른 숫자의 개수를 동적으로 갱신한다.
- 현재 구간
for (Query query : queries) {
while (currentRight < query.right) {
currentRight++;
distinctCount += add(arr[currentRight], freq);
}
while (currentRight > query.right) {
distinctCount -= remove(arr[currentRight], freq);
currentRight--;
}
while (currentLeft < query.left) {
distinctCount -= remove(arr[currentLeft], freq);
currentLeft++;
}
while (currentLeft > query.left) {
currentLeft--;
distinctCount += add(arr[currentLeft], freq);
}
results[query.idx] = distinctCount;
}- 숫자 추가 및 제거
-
add함수:- 새로운 숫자가 추가되면 개수를 증가시키고, 새로운 숫자가 처음 추가되었다면
distinctCount를 증가시킨다.
- 새로운 숫자가 추가되면 개수를 증가시키고, 새로운 숫자가 처음 추가되었다면
-
remove함수:- 숫자가 제거되면 개수를 감소시키고, 해당 숫자가 완전히 사라지면
distinctCount를 감소시킨다.
- 숫자가 제거되면 개수를 감소시키고, 해당 숫자가 완전히 사라지면
private static int add(int value, int[] freq) {
if (freq[value] == 0) {
freq[value]++;
return 1;
}
freq[value]++;
return 0;
}
private static int remove(int value, int[] freq) {
if (freq[value] == 1) {
freq[value]--;
return 1;
}
freq[value]--;
return 0;
}So...
이 문제는 Mo's Algorithm을 활용하여 효율적으로 쿼리를 처리한 예시이다.
가장 큰 고민은 ( O(N + Q\sqrt{N}) )로 처리 가능한 알고리즘을 설계했으며, 좌표 압축과 구간 이동을 결합하여 메모리 및 처리 시간을 최적화했다.
실제 구현에서는 ( N )과 ( Q )가 매우 클 수 있기 때문에, 메모리 관리와 효율성에 초점을 맞췄다.

개발이란 무엇인가..를 공부하는 거북이의 성장일기 🐢