그룹 함수
1. GROUP BY
| 함수 | 설명 |
|---|---|
| GROP BY | 조건에 따라 집계된 값을 가져옴 |
ex1)
SELECT Country FROM Customers;
같은 나라의 이름도 각 각 떨어져있음
ex1-1)GROP BY 적용
SELECT Country FROM Customers
GROUP BY Country;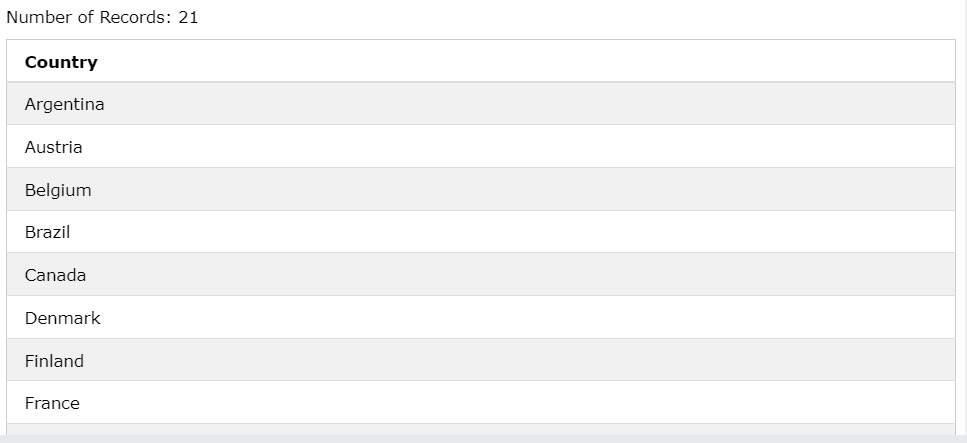
겹치지 않고 하나로 뭉쳐짐
ex2) 응용
SELECT
ProductID, Quantity
FROM OrderDetails;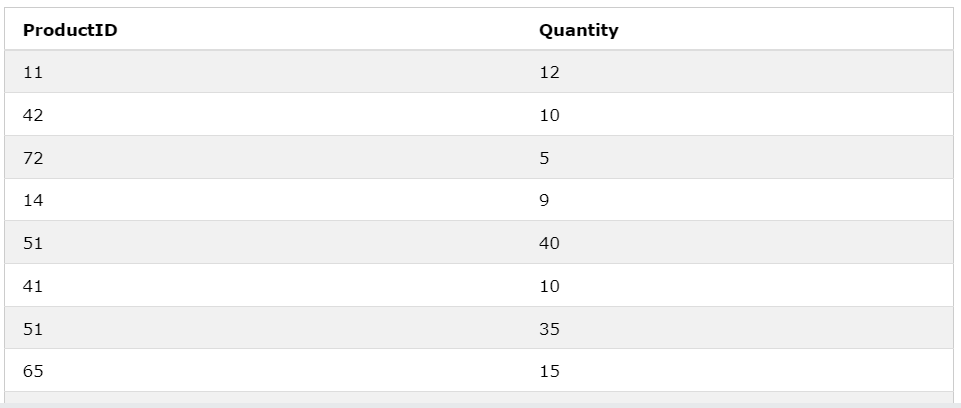
위의 데이터를 서로 같은 ProductID 별로 묶은뒤 Quantity 값을 합해본다.
ex2-1) GROUP BY 적용
SELECT
ProductID,
SUM(Quantity) AS QuantitySum
FROM OrderDetails
GROUP BY ProductID
ORDER BY QuantitySum DESC;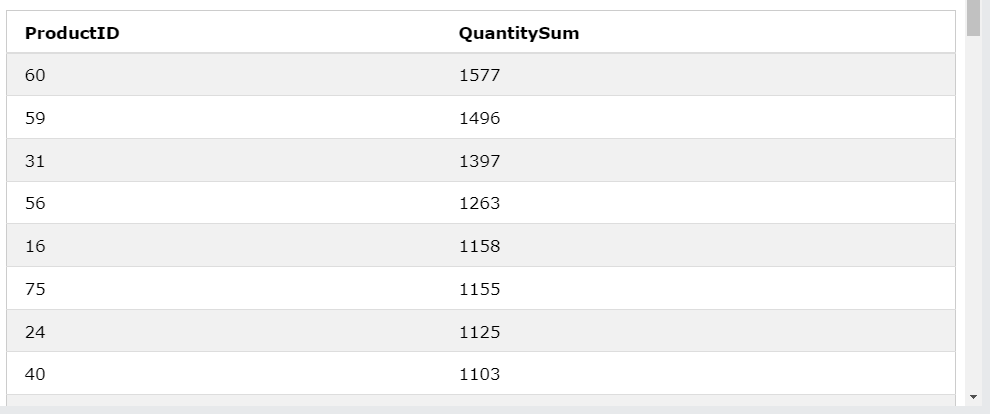
ProductID가 같은 것끼리 묶고 Quantity 값을 합해서 컬럼명을 QuantitySum이라 정하고 합한 값의 내림차순으로 정렬했다.
2. WITH ROLLUP
| 함수 | 설명 |
|---|---|
| WITH ROLLUP | 전체의 총합 (* ORDER BY와 함께 사용 될 수 없음) |
ex1)
SELECT
Country, COUNT(*)
FROM Suppliers
GROUP BY Country
WITH ROLLUP;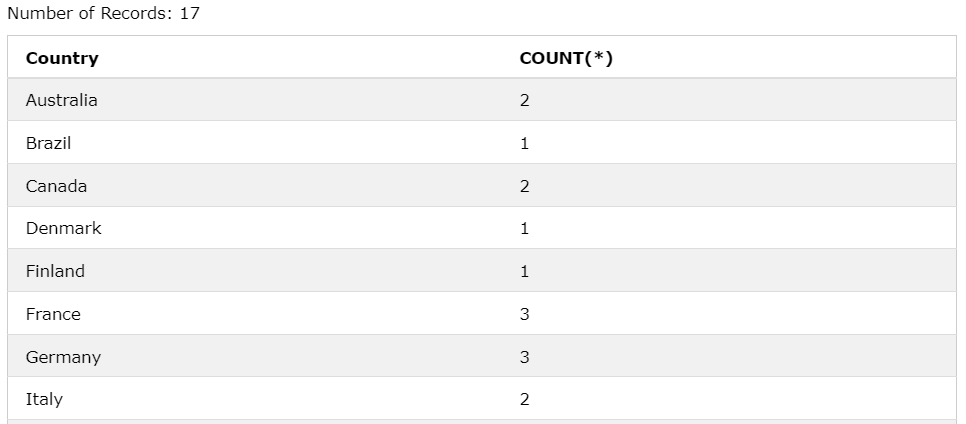
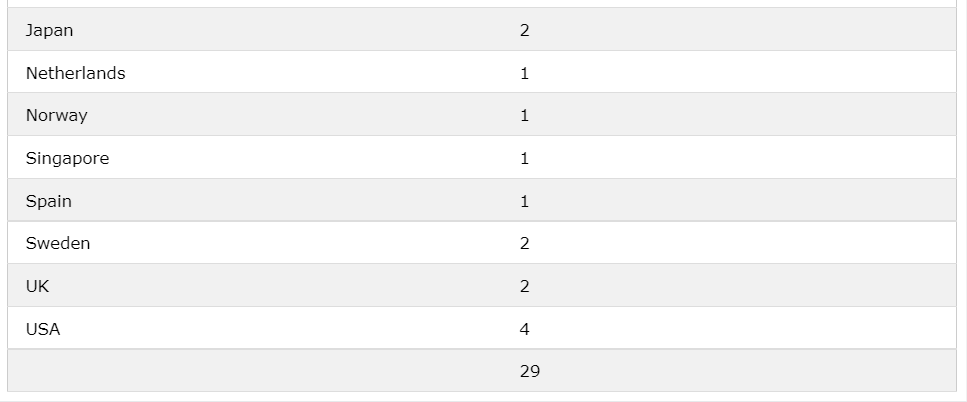
Country의 갯수와 그 총 합을 보여준다.
3. HAVING
| 함수 | 설명 |
|---|---|
| HAVING | 그룹화된 데이터 걸러내기 |
ex1)
SELECT
Country, COUNT(*) AS Count
FROM Suppliers
GROUP BY Country
HAVING Count >= 3;
Country의 갯수 중 3보다 같거나 큰 값만 보여준다.
* WHERE 과 HAVING의 차이점
WHERE은 그룹화 하기 전 데이터를 HAVING은 그룹화 후 데이터를 조건 별로 추출 할 수 있다.
ex2) WHERE
SELECT
COUNT(*) AS Count, OrderDate
FROM Orders
WHERE OrderDate > DATE('1996-12-31')
GROUP BY OrderDate;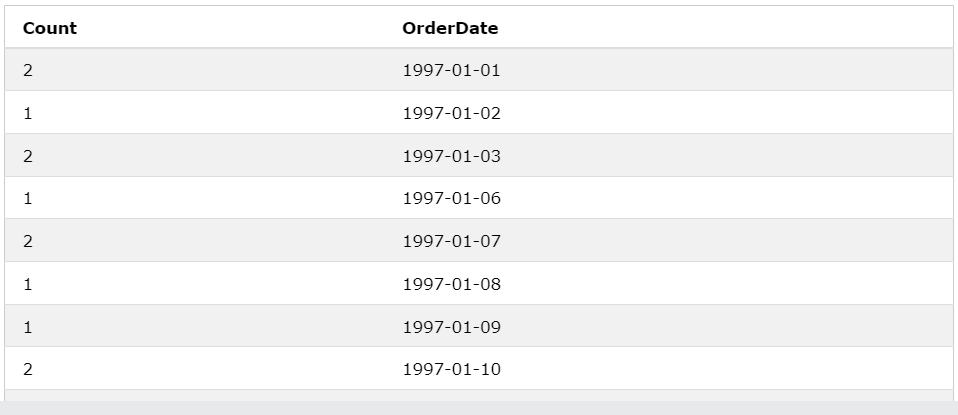
1996-12-31 보다 큰 데이터 즉 보다 최신의 데이터만 걸러 내서 OrderDate끼리 그룹화 했다.
ex2-1) HAVING
SELECT
COUNT(*) AS Count, OrderDate
FROM Orders
WHERE OrderDate > DATE('1996-12-31')
GROUP BY OrderDate
HAVING Count > 2;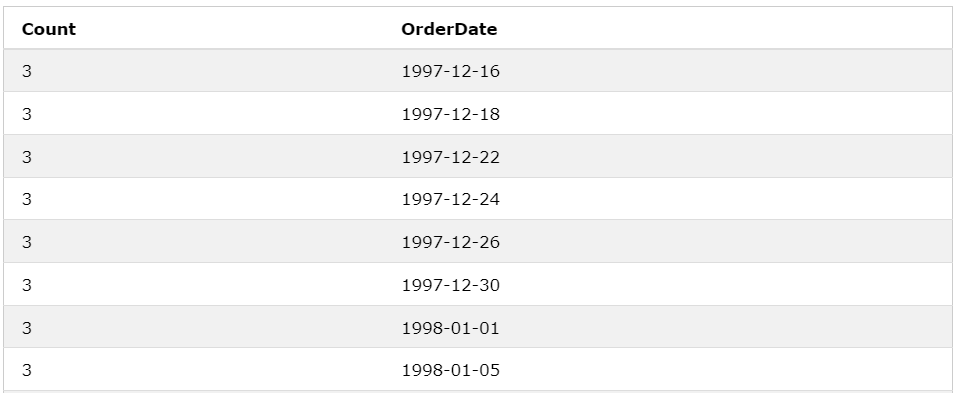
그룹화 된 데이터에 조건을 걸어 Count가 2보다 큰 데이터만 보여준다.
4. DISTINCTE
| 함수 | 설명 |
|---|---|
| DISTINCTE | 중복된 값들을 제거한다 |
단지 특정 컬럼의 중복을 제거한다.
GROUP BY 보다는 가볍다.
ex1)
SELECT DISTINCT CategoryID FROM Products;
*GROUP BY와 달리 정렬하지 않으므로 더 빠르다.
ex2)
SELECT COUNT DISTINCT CategoryId
FROM Products;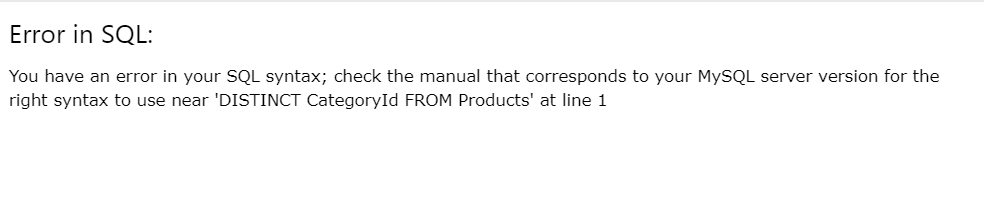
GROUP BY와 달리 집계함수와 같이 사용되지 않는다.
ex3) GROUP BY와 함께 사용
SELECT
Country,
CITY
FROM Customers
ORDER BY Country;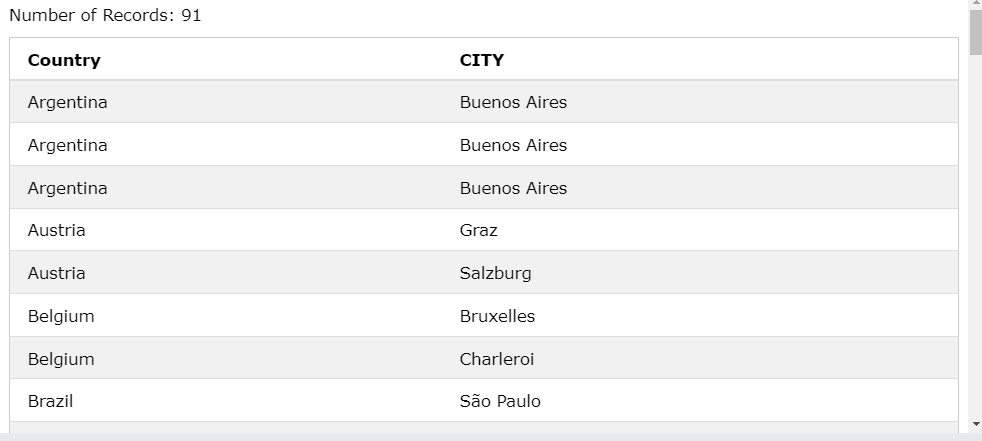
현재 Customers 테이블의 컬럼 Country, CITY의 데이터 값이다.
ex3-1) GROUP BY 사용
SELECT
Country,
COUNT(CITY)
FROM Customers
GROUP BY Country;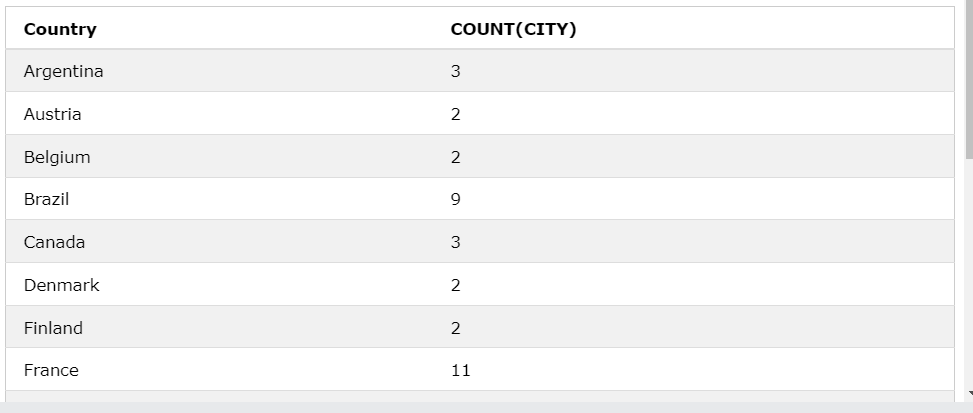
GROUP BY로 Country를 중복 없이 묶은 후 CITY의 수를 보았을때 아르헨티나의 CITY의 수가 3이 나왔다.
ex3-2) DISTINCT 사용
SELECT
Country,
COUNT(DISTINCT CITY)
FROM Customers
GROUP BY Country;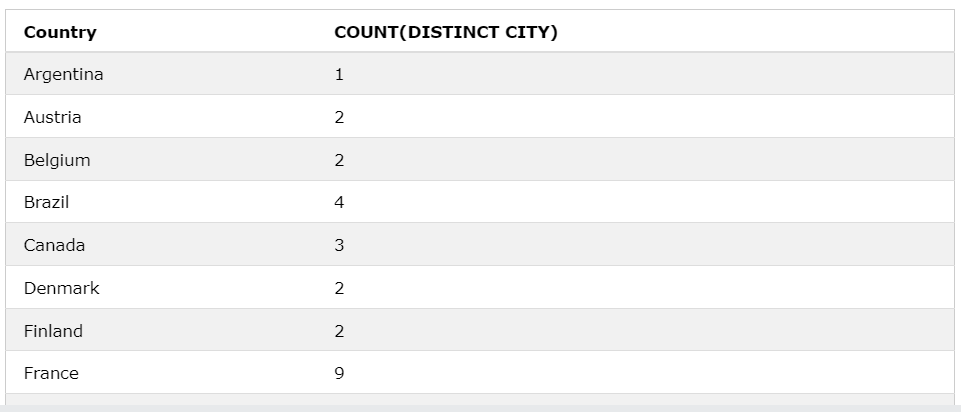
CITY의 값 중에 중복된 것들은 삭제를 해서 아르헨티나의 CITY의 수가 1이 나왔다.

개린이