서브쿼리
1. 비상관 서브쿼리
쿼리문 안쪽의 또다른 쿼리문 으로 바깥쪽의 쿼리와 안쪽의 서브쿼리문은 독자적으로 실행되며 서로 상관하지 않는다.
ex1)
SELECT
CategoryID, CategoryName, Description,
(SELECT ProductName FROM Products WHERE ProductID = 1)
FROM Categories;
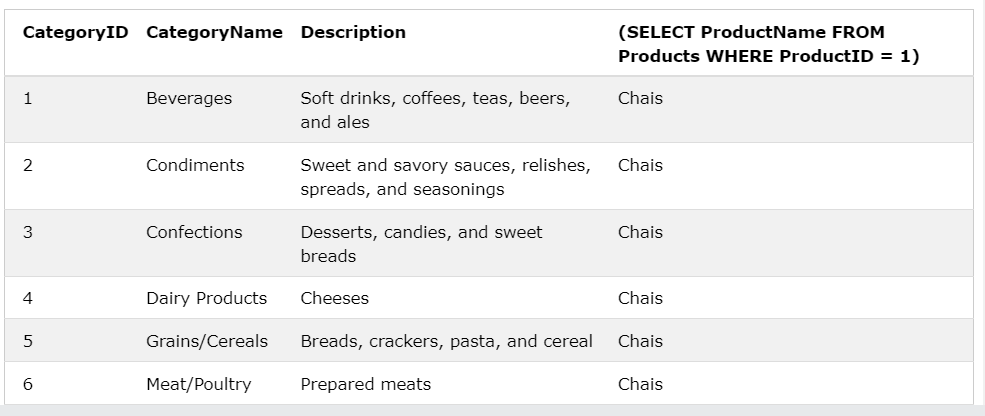
쿼리문 안에 또 다른 쿼리문을 넣어서 다른 테이블에서 데이터를 불러옴
ex2)
SELECT * FROM Products
WHERE Price < (
SELECT AVG(Price) FROM Products
);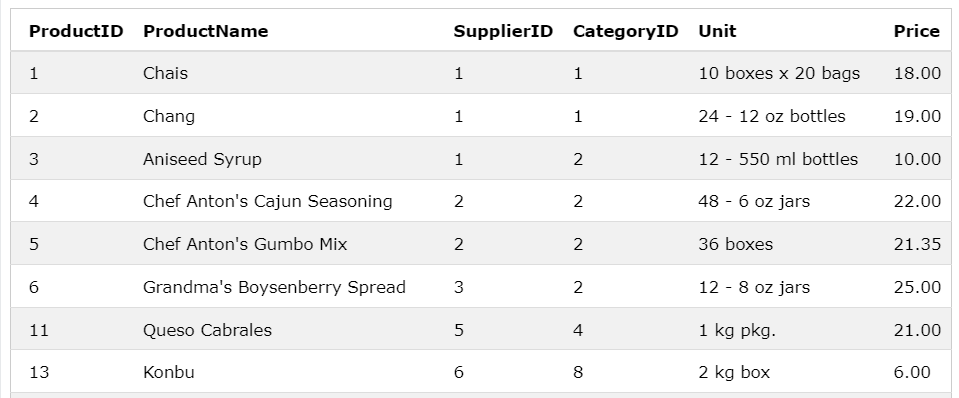
서브쿼리를 이용해서 Price의 평균을 구하고 평균 보다 낮은 값을 추출한다.
ex3)
SELECT CategoryID, CategoryName, Description
FROM Categories;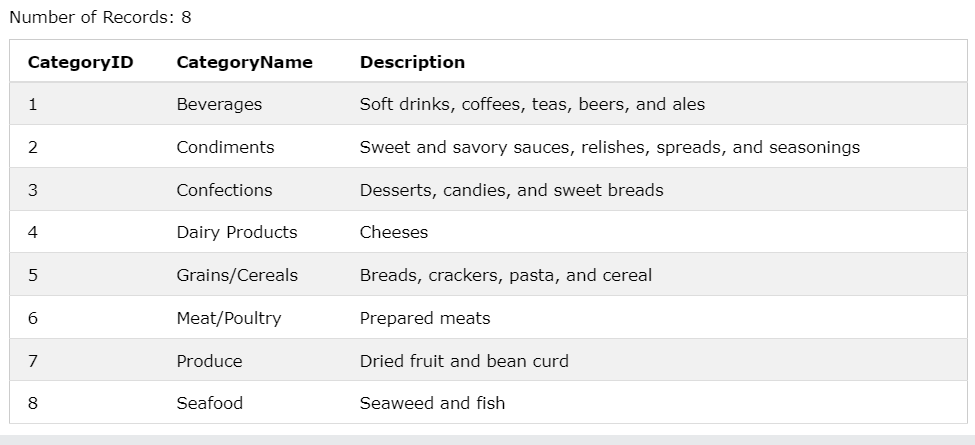
Categories테이블의 CategoryID, CategoryName, Description 컬럼
ex3-1)
SELECT CategoryID FROM Products
WHERE Price > 50;
Poducts 테이블의 Price가 50보다 큰 값을 가진 CategoryID들
ex3-2)합쳐 보기
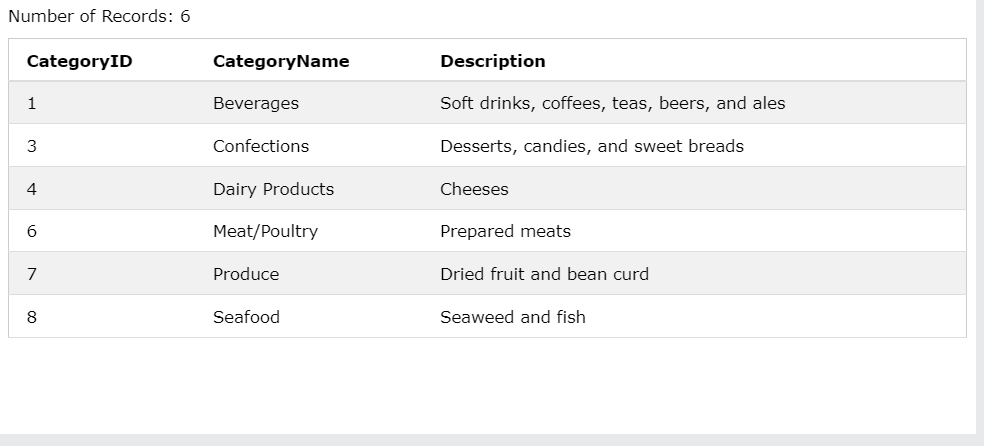
Poducts 테이블의 Price가 50보다 큰 값을 가진 CategoryID를 추출해서 Categories테이블의 CategoryName, Description 컬럼을 데이터를 불러옴
ALL, ANY
| 연산자 | 의미 |
|---|---|
| ~ALL | 서브쿼리의 모든 결과에 대해 ~하다 |
| ~ANY | 서브쿼리의 하나 이상의 결과에 대해 ~하다 |
ex1) ALL
SELECT Price FROM Products
WHERE CategoryID =2;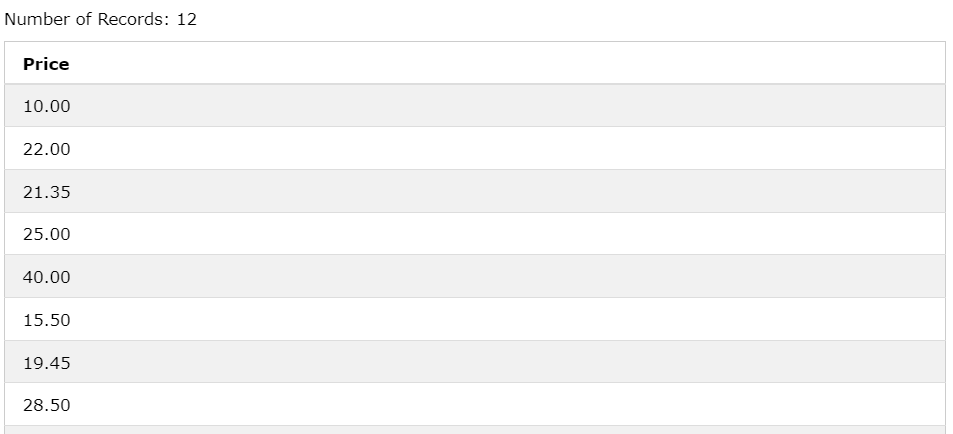
CategoryID가 2인 것 들을 추출해서 Price를 보여줌
ex1-1) ALL 적용
SELECT * FROM Products
WHERE Price > ALL(
SELECT Price FROM Products
WHERE CategoryID =2
);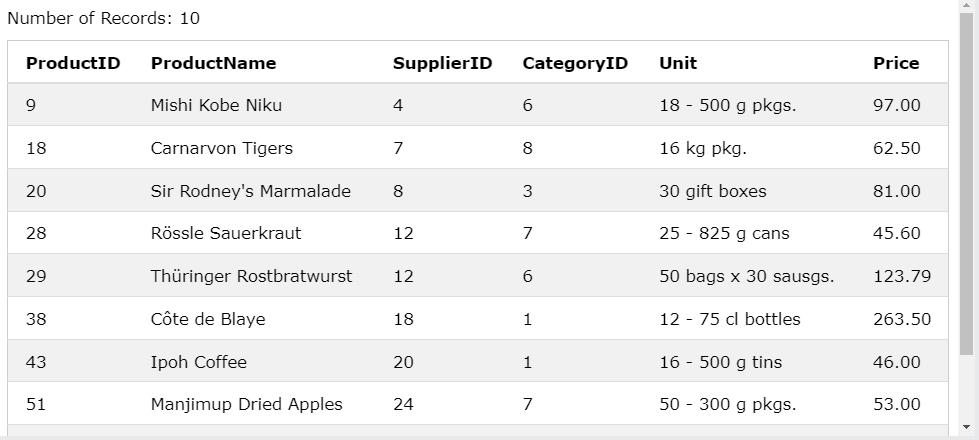
CategoryID가 2인 것 들의 Price보다 큰 Price 값을 보여준다. 즉 CategoryID가 2인 것 들 중 Max값 보다 큰 값을 보여줌
ex2) ANY
SELECT CategoryID FROM Products
WHERE Price > 50;
Price가 50보다 큰 값의 CategoryID
ex2-1) ANY 적용
SELECT CategoryID, CategoryName, Description
FROM Categories
WHERE CategoryID = ANY (
SELECT CategoryID FROM Products
WHERE Price > 50);
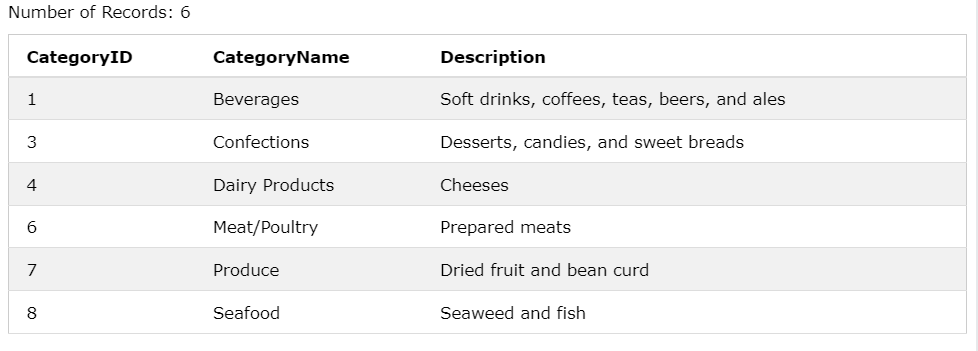
Price가 50보다 큰 값의 CategoryID 중 같은 값이 있으면 해당 값을 보여준다.
"CategoryID = ANY" == "CategoryID IN"
2. 상관 서브쿼리
바깥쪽의 쿼리와 안쪽의 서브쿼리가 맡물려 돌아간다.
ex1)
Products 테이블
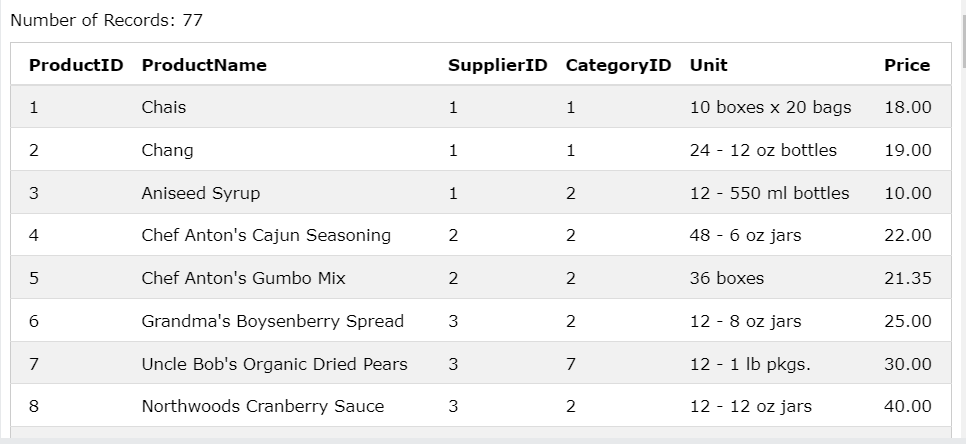
Categories 테이블
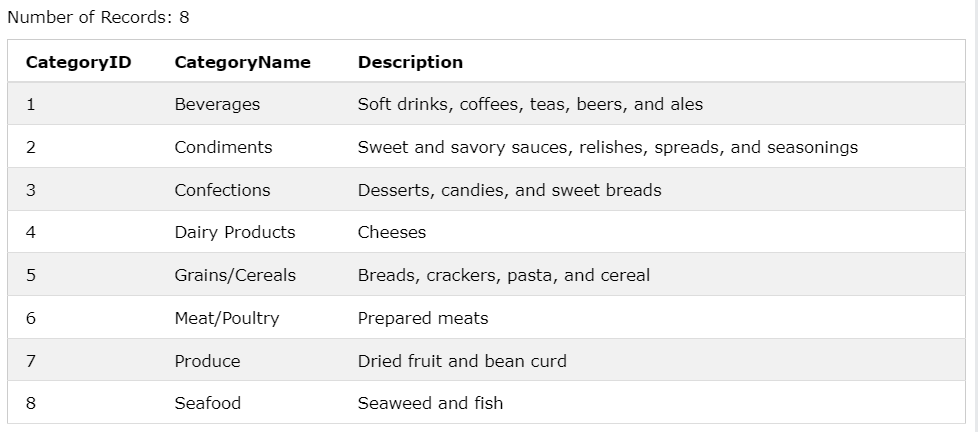
Products 테이블은 CategoryID를 가지고 있고,
Categories는 각 각의 CategoryID가 가지는 데이터들이 있다.
SELECT ProductID, ProductName,
(
SELECT CategoryName FROM Categories C
WHERE C.CategoryID = P.CategoryID
) AS CategoryName
FROM Products P;
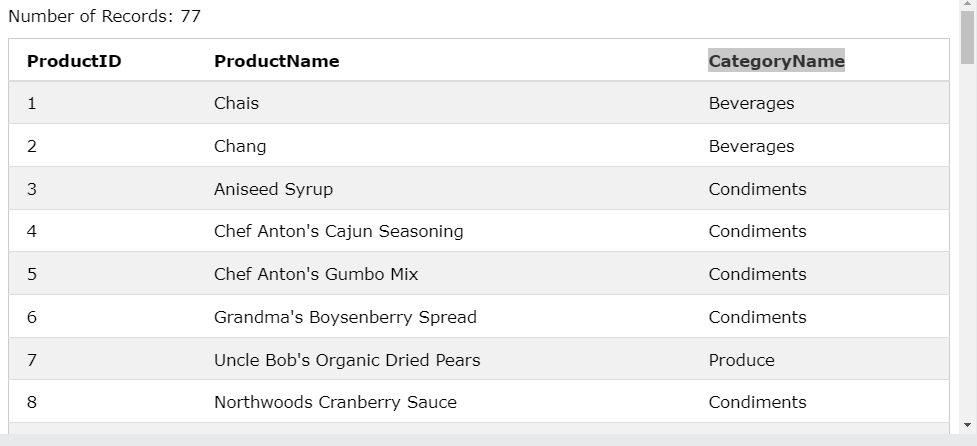
- Categories C, Products P 각 테이블의 별명을 정함
- P 테이블에서 ProductID, ProductName을 가져옴
- C 테이블에서 CategoryName을 가져옴
- C. CategoryID 와 P. Category 아이디가 같은 것끼리 묶음
- P 테이블의 ProductID, ProductName 와 C 테이블의 CategoryName을 한 테이블에서 볼 수 있음
ex2)
Suppliers 테이블

Customers 테이블

각 각의 테이블이 가지고있는 County와 City 정보를 이용해 하나의 테이블로 정리한다.
SELECT SupplierName, Country, City,
(
SELECT COUNT(*) FROM Customers C
WHERE C.Country = S.Country
) AS CustomersInTheCountry,
(
SELECT COUNT(*) FROM Customers C
WHERE C.Country = S.Country AND C.City = S.City
) AS CustomersInTheCity
FROM Suppliers S;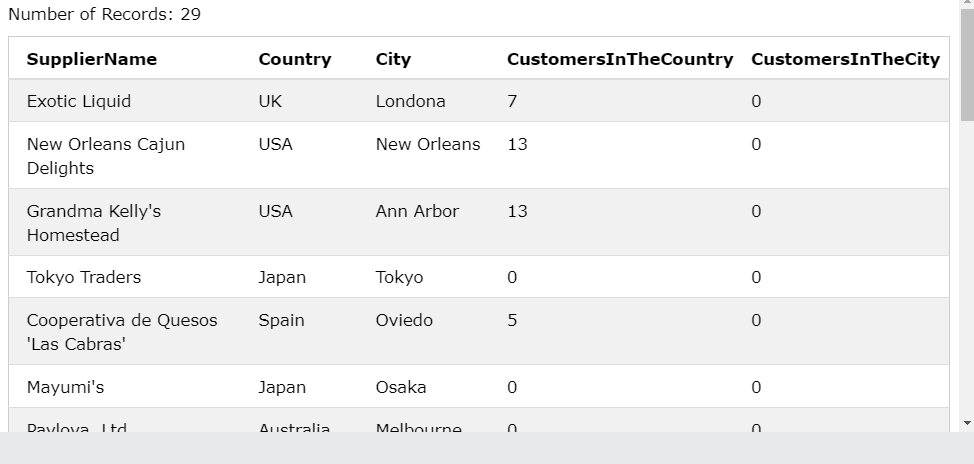
- Suppliers S, Customers C 각 테이블의 별명
- S 테이블에서 SupplierName, Country, City 정보를 가져옴
- C 테이블에서 C와 S의 Country 정보가 같은 테이터를 가져와서 COUNT, 컬럼명 CustomersInTheCountry
- C 테이블에서 C와 S의 Country 정보가 같고 C와 S의 City 정보가 같은 것들을 COUNT, 컬럼명 CustomersInTheCity
- 그 결과를 한 테이블에서 보여줌
EXISTS / NOT EXISTS
| 연산자 | 의미 |
|---|---|
| EXISTS | 존재 하는가 |
| NOT EXISTS | 존재하지 않는가 |
ex1) EXISTS
SELECT CategoryID, CategoryName
FROM Categories C
WHERE EXISTS(
SELECT * FROM Products P
WHERE P.CategoryID = C.CategoryID AND P.Price > 80
);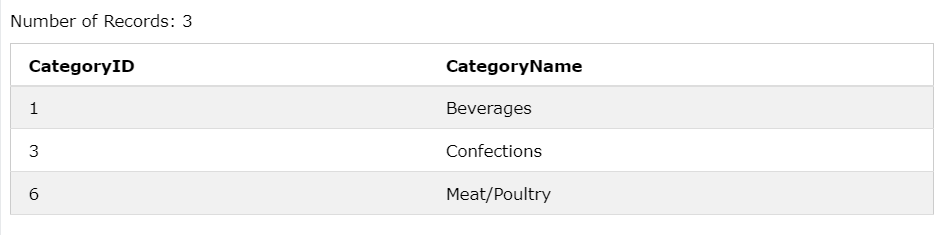
P.Category Id 와 C.CategoryID가 같은고 price가 80이 넘어가는 데이터가 존재한다면 해당 데이터를 보여준다.
ex2) NOT EXISTS
SELECT CategoryID, CategoryName
FROM Categories C
WHERE NOT EXISTS(
SELECT * FROM Products P
WHERE P.CategoryID = C.CategoryID AND P.Price > 80
);
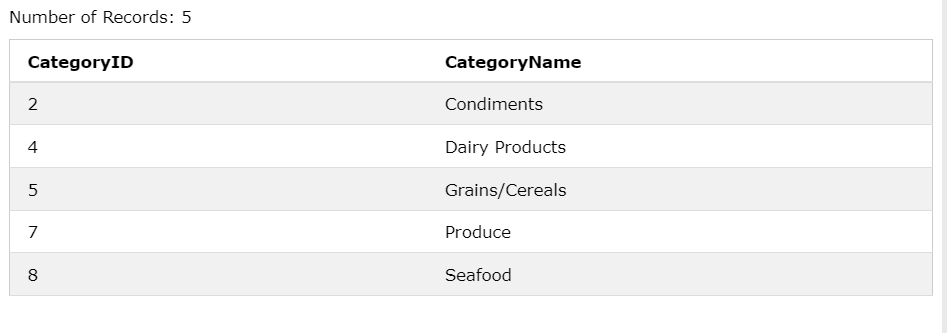
P.Category Id 와 C.CategoryID가 같은고 price가 80이 넘어가는 데이터가 존재하는것을 제외하고 보여준다.
