-
목표
- 서울특별시 25개 행정자치구별 인구수 대비 CCTV 설치 현황 정리
- CCTV 현황 종합하여 서울특별시 전체 CCTV 설치 경향 도출
-
예상 결과물
- 분석결과 시각화 그래프
: x축 인구수, y축 CCTV 수, 서울시 전체 경향(추세)
- 분석결과 시각화 그래프
-
분석 진행 순서
(1) 서울시 구별 CCTV 현황 데이터 확보 : python, pandas
(2) 서울시 구별 인구 현황 데이터 확보 : python, pandas
(3) CCTV 데이터 & 인구 현황 데이터 합치기 : python, pandas
(4) 데이터 정리 & 정렬하기 : python, pandas
(5) 그래프 그리기 : matplotlib
(6) 전체적인 경향 파악하기 : regression using Numpy
(7) 경향에서 벗어난 데이터 강조하기 : insight & visualization
-
데이터 확보하기
: 서울시 열린데이터 광장(https://data.seoul.go.kr/index.do) > 공공데이터 -
데이터 읽기 - pandas로 CSV, xls 파일 읽기
: 파일명이 너무 길면 tab키를 활용하여 축약
: 한글은 encoding 설정 필수!!
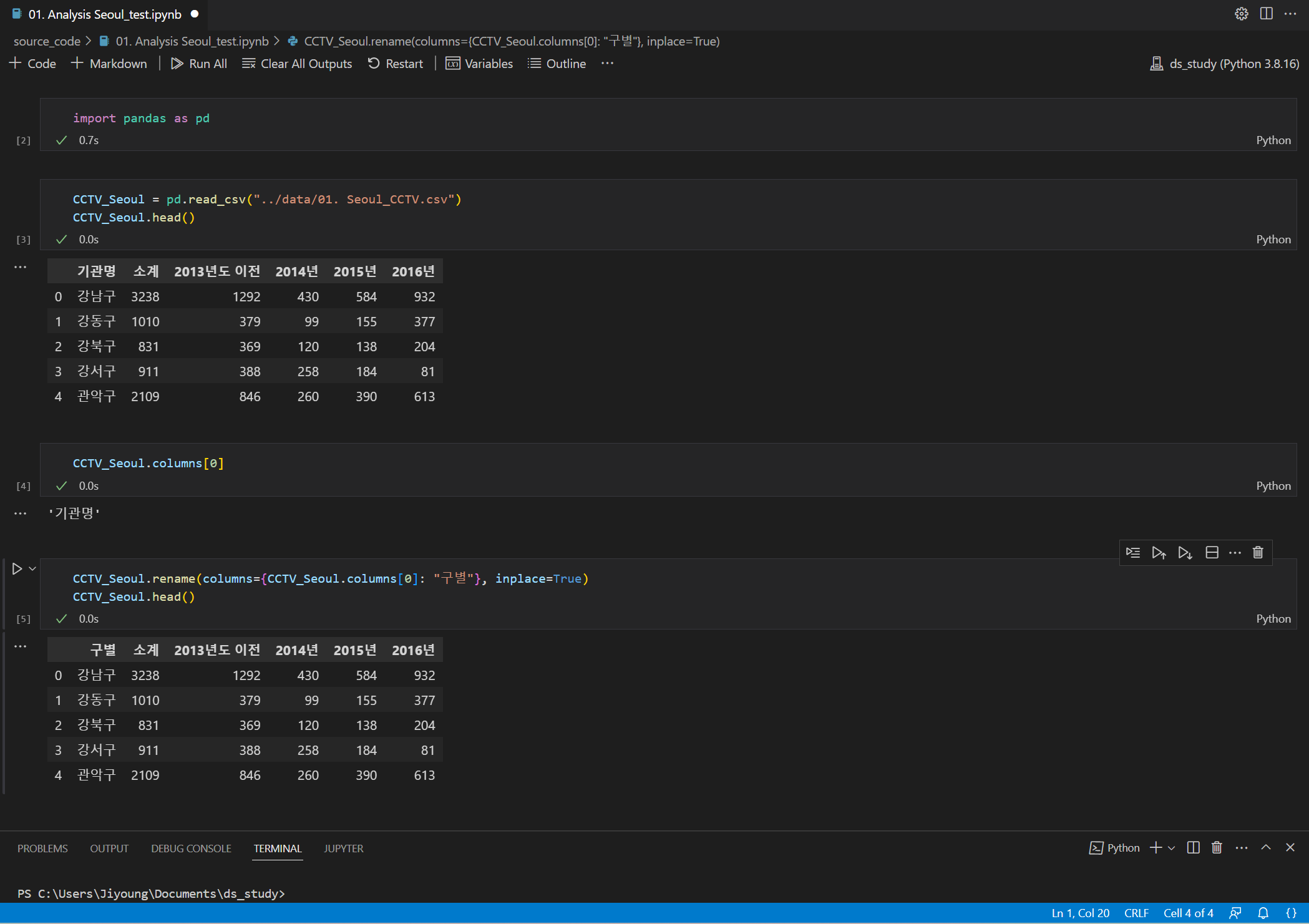
CSV 파일 데이터 읽기
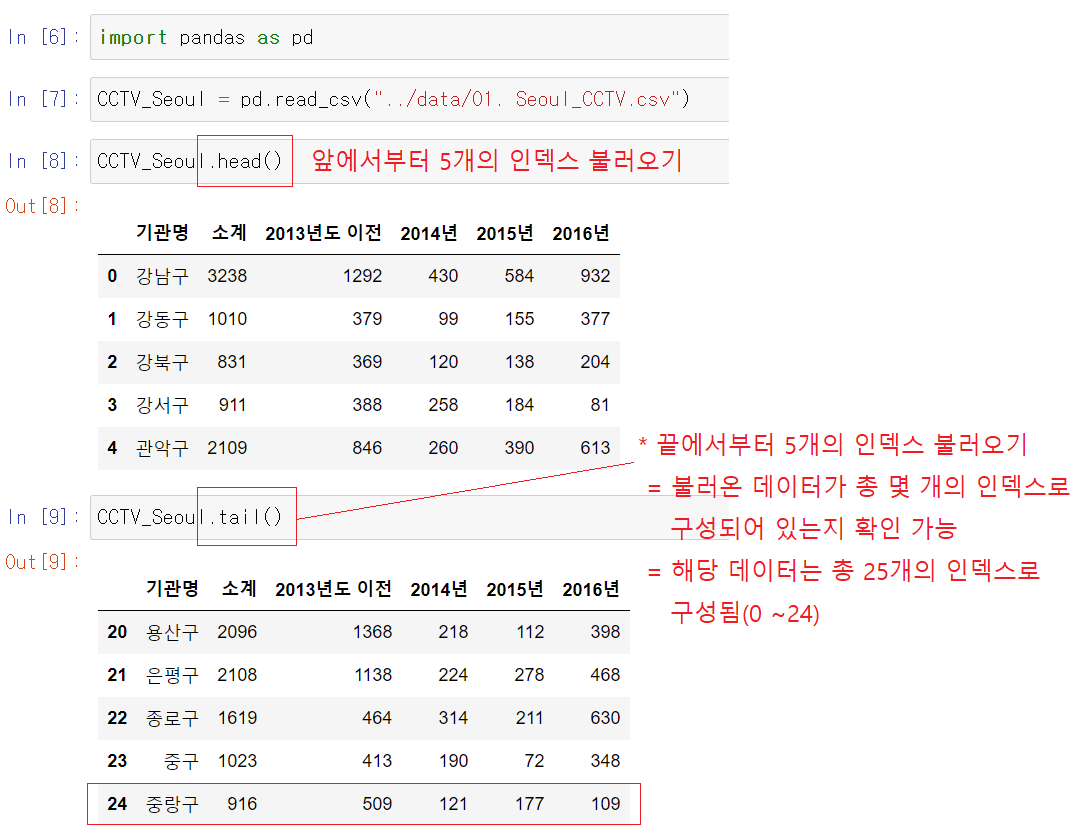
[1] head( ) 명령어 ---> 불러온 데이터 중 "앞에서 5개 까지의 값"만 미리보기 = index 0~4만 호출됨
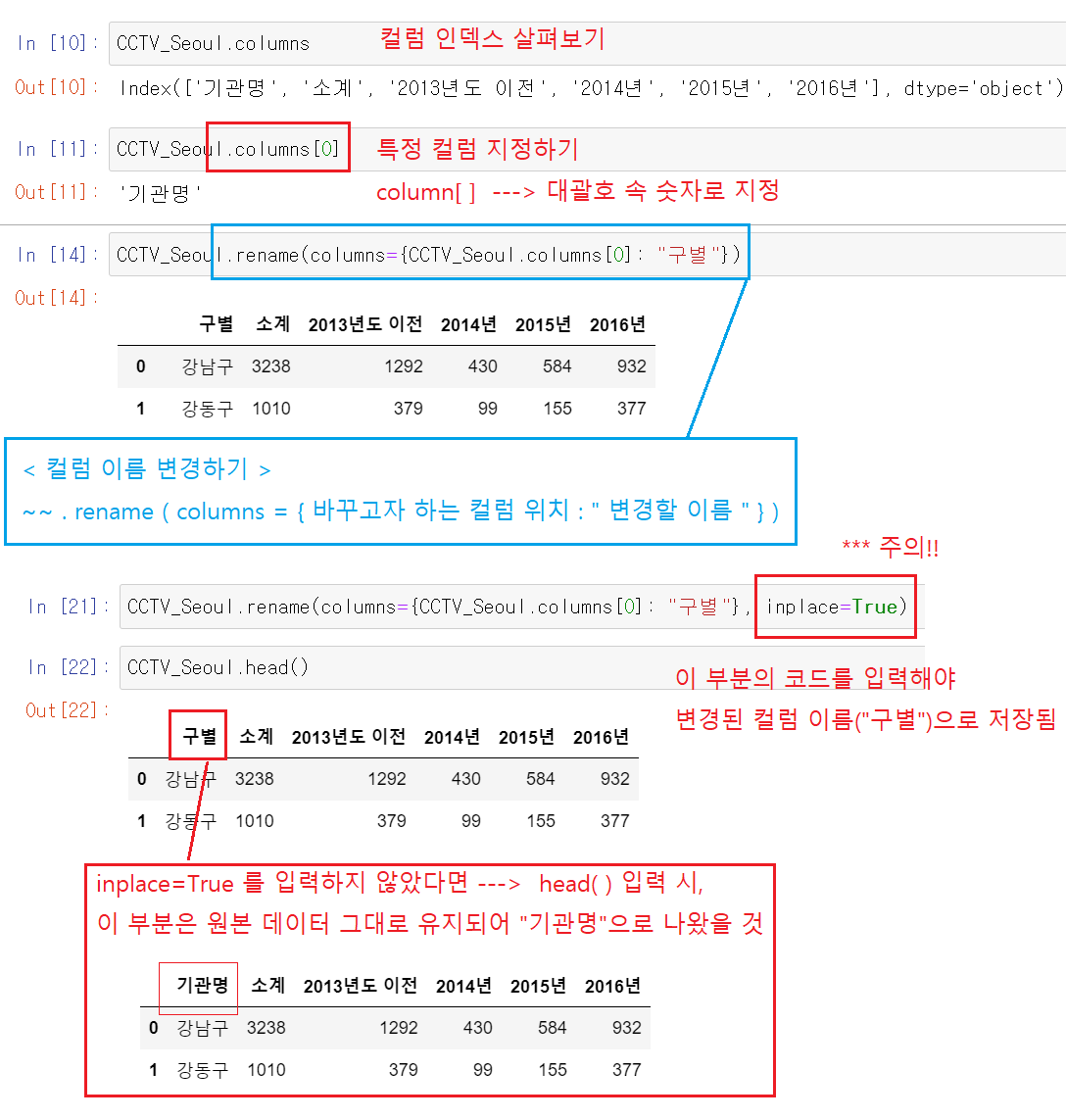
(참고 1) .columns / .columns[n]
컬럼 이름 조회하기

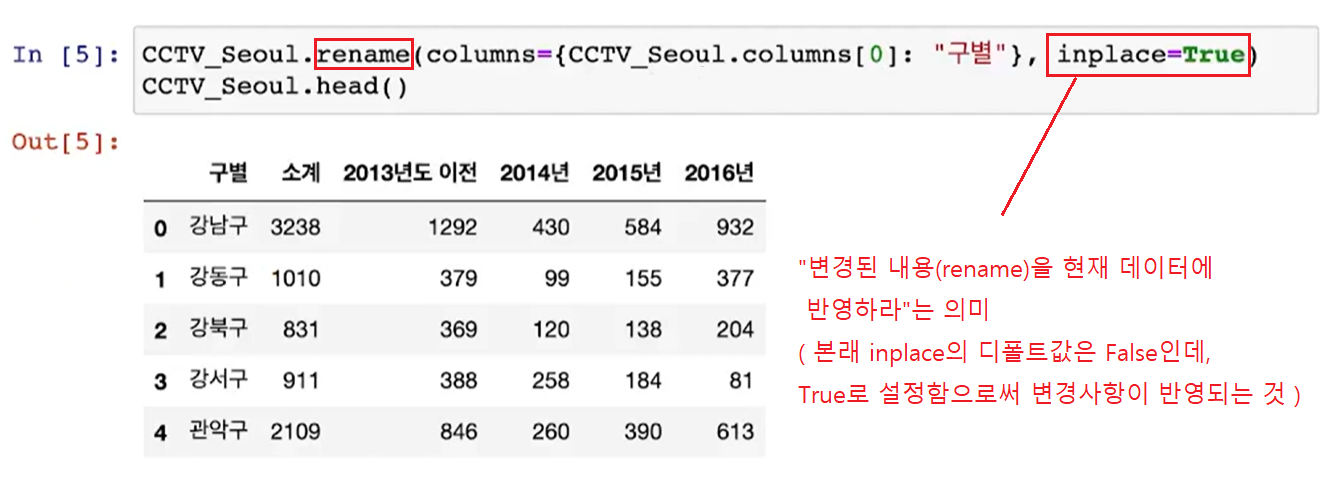
(참고 2) .rename
컬럼 이름 바꾸기
엑셀 파일 데이터 읽기
[1] 판다스는 엑셀과 달리 셀병합 개념이 없으므로, 엑셀 데이터의 형태에 따라 컬럼이 뒤죽박죽으로 엉켜있을 수 있음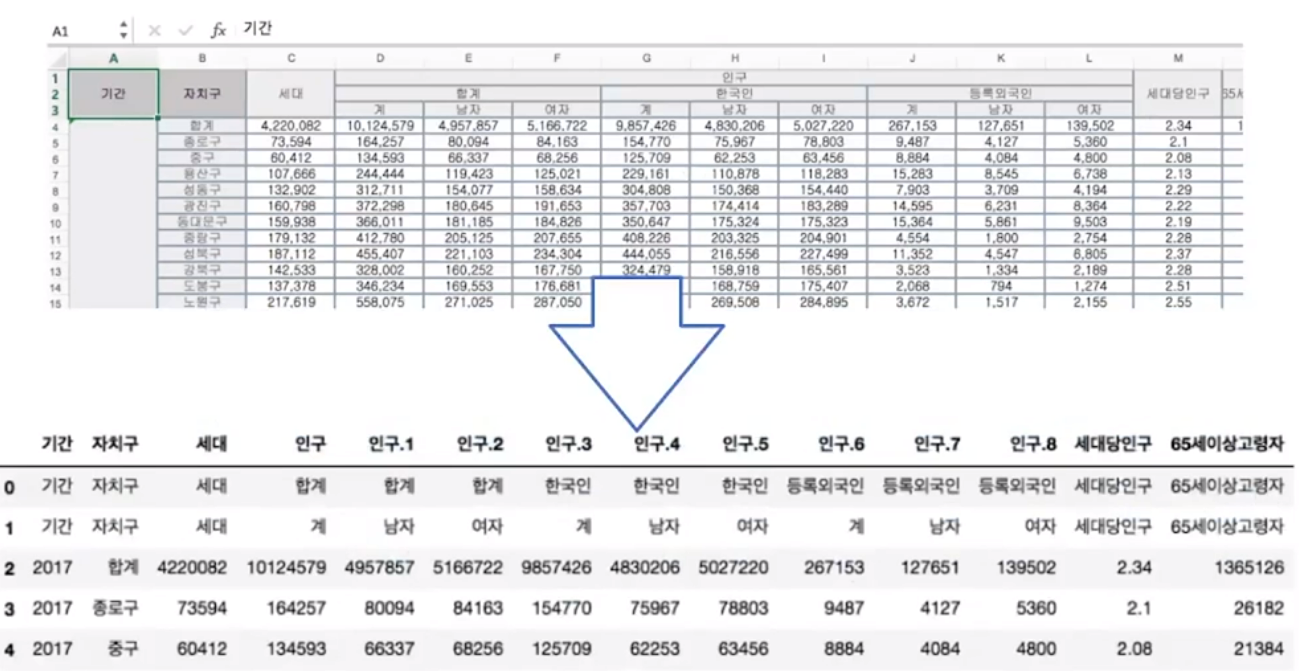
[2] 그럴 땐 엑셀 데이터 중 우리가 필요한 데이터만 자르거나, 불러오는 인덱스 또는 컬럼에 제약을 걸어서 가독성 좋게 편집할 수 있음
컬럼 편집하기(1) 자르기, 지정하기
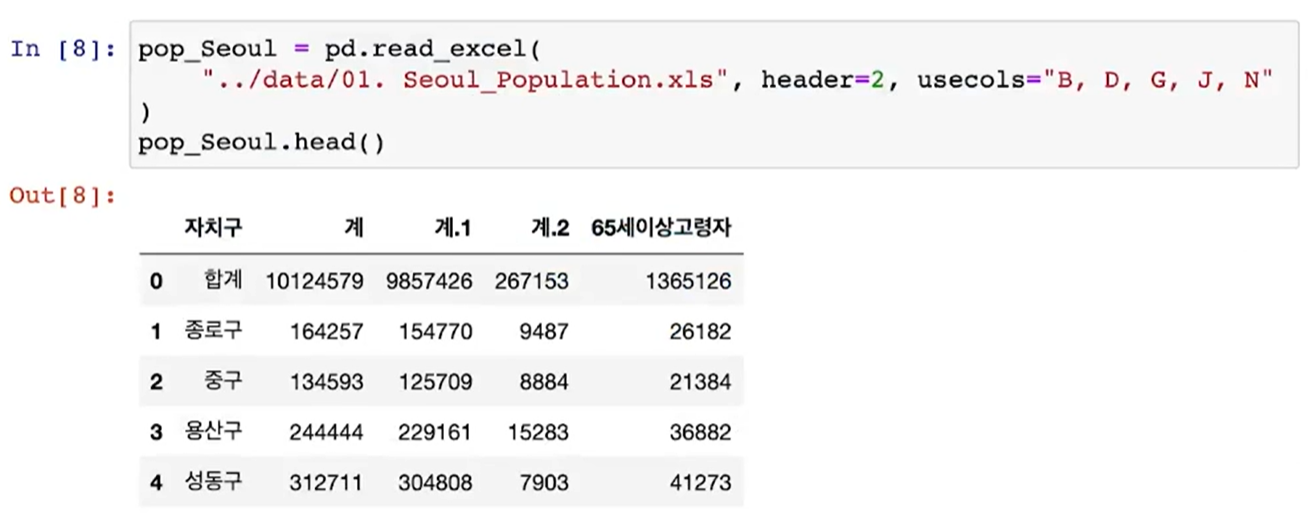
- header=2 = 자료를 읽기 시작할 행 지정 = 엑셀의 2번째 행부터 자료를 불러와 = 인덱스 1번부터 읽어라
- usecols="B, D, G, J, N" = 필요한 컬럼만 지정 = 엑셀의 B(자치구), D(계), G(계.1), J(계.2),N(65세이상 고령자) 컬럼만 불러와
컬럼 편집하기(2) 컬럼명 재지정
[3] 편집해서 불러온 엑셀 데이터의 컬럼을 다시 지정하기
[참고] pandas
- 테이블 데이터를 읽을 때 가장 많이 사용하는 모듈
- 단일 프로세스에서 최대의 효율을 발휘
- (모듈 설치 후) import 명령어로 실행 ---> import pandas as pd
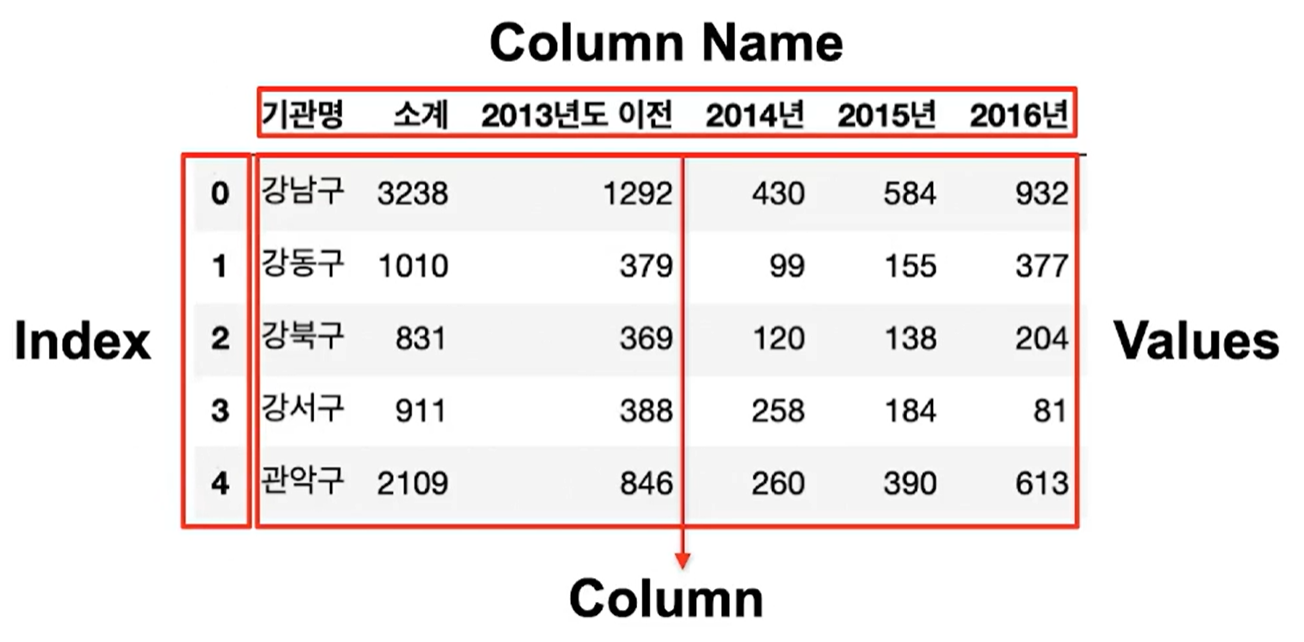
- Date Frame 구조 : index(가로), column(세로), values(데이터 값)
< 파이썬 모듈 naming 규칙 >
import MODULE : MODULE을 사용하겠다
-(사용) MODULE.function
import MODULE as md : MODULE을 사용할건데, 이 코드 안에서는 MODULE을 md라는 이름으로 부르겠다
-(사용) md.function
from MODULE import function : MODULE에 포함된 function이라는 함수만 사용하겠다
-(사용) function
[실습 시작]
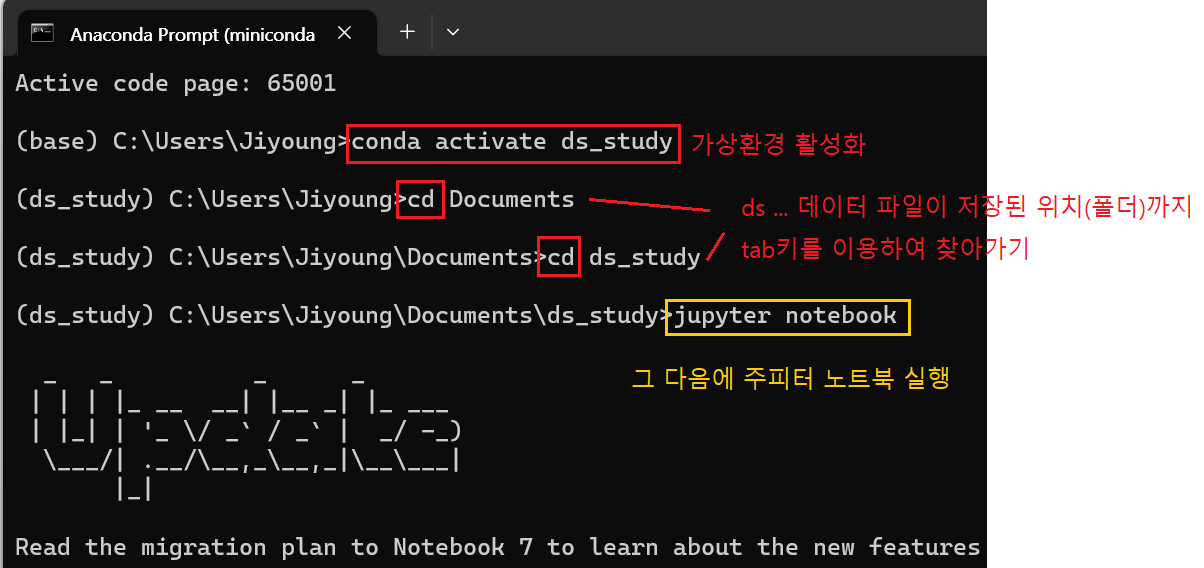
- 아나콘다 프롬프트 > 가상환경 활성화, 데이터를 불러올 폴더 지정, 주피터 노트북 실행!!( * 주피터 노트북 코드 실행 : shift + enter )
- 판다스 모듈 불러오기, 데이터 파일(CSV) 불러오기
[참고] 불러온 데이터의 한글 폰트가 깨진다면? 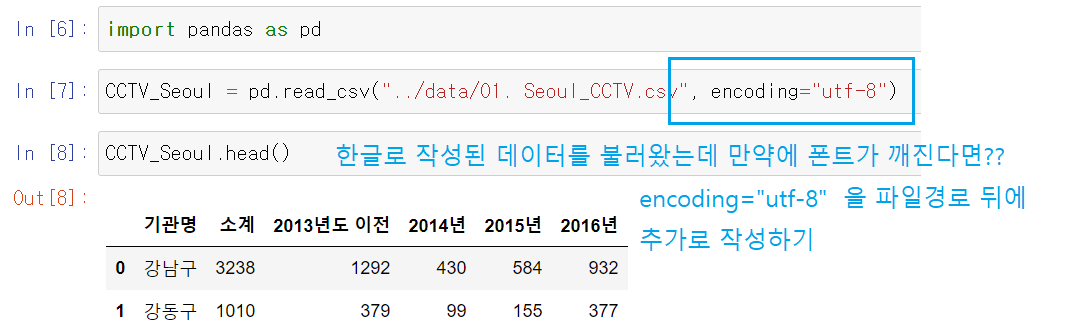
- (데이터 탐색) 컬럼 이름 변경하기
- 데이터 파일(엑셀) 불러오기
(1) 원본 데이터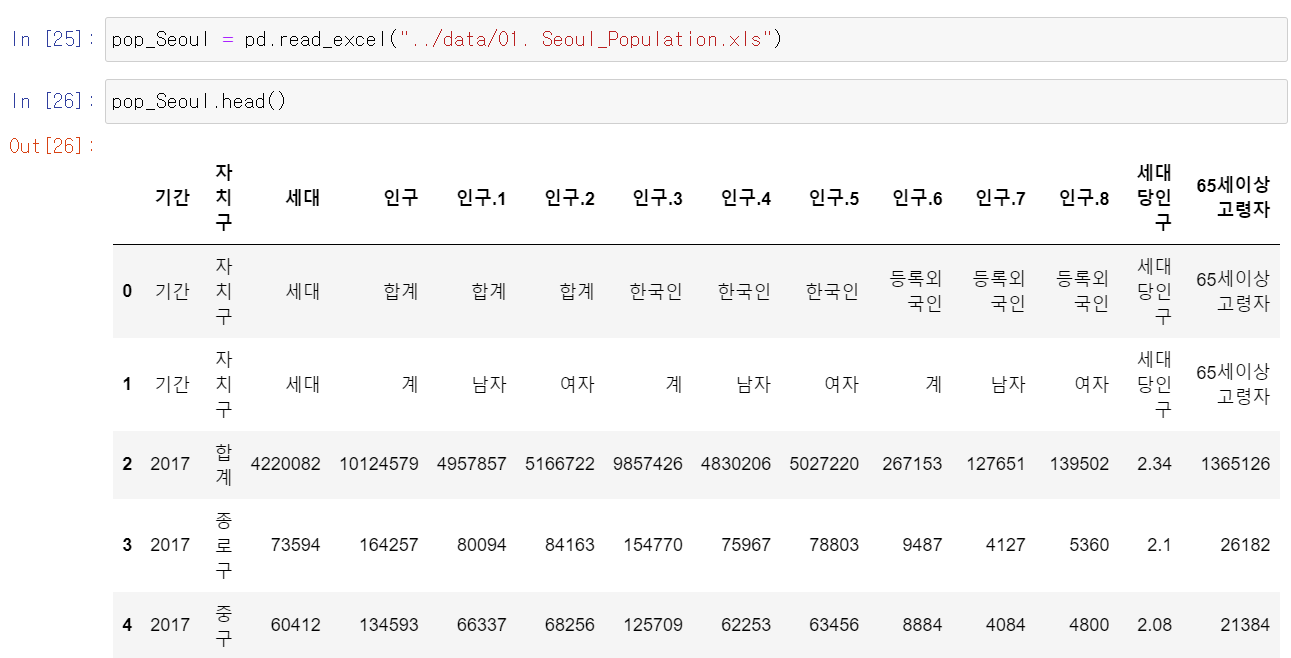
(2) 필요한 데이터만 선별하여 다시 추출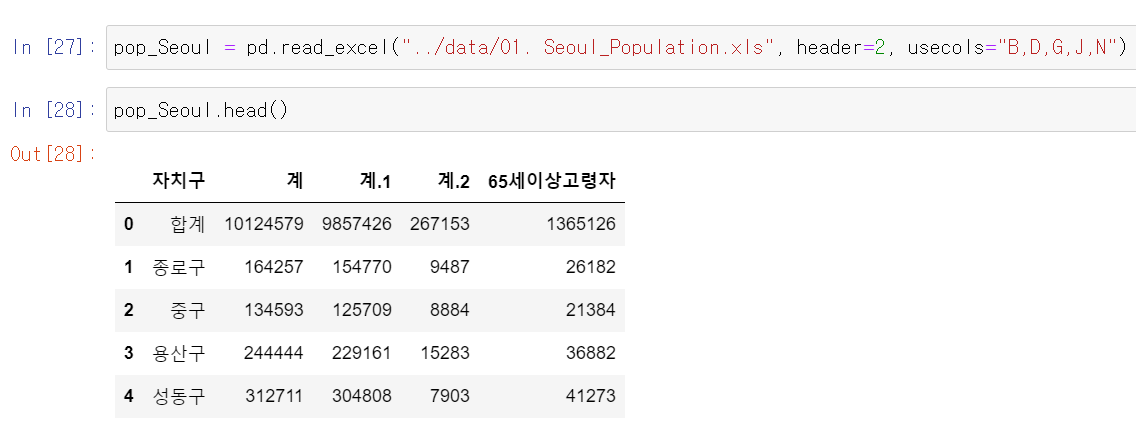
(3) 선별한 데이터의 컬럼명 변경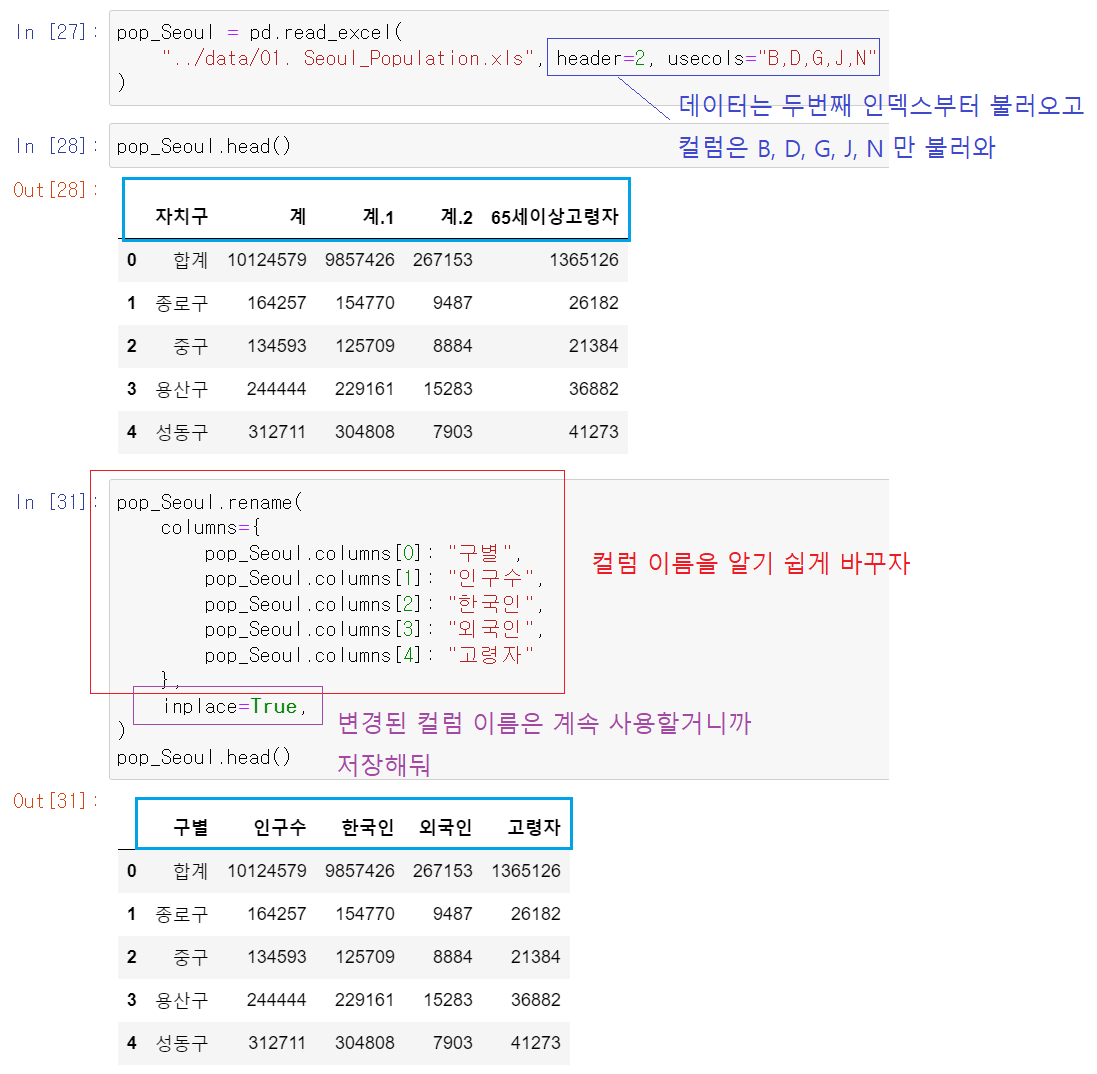
[번외] 비주얼 코드로 똑같이 작성해보기