
< pandas basic >
- pandas는 통상적으로 pd로 import 한다
- 수치해석적 함수가 많은 numpy는 통상 np로 import 한다
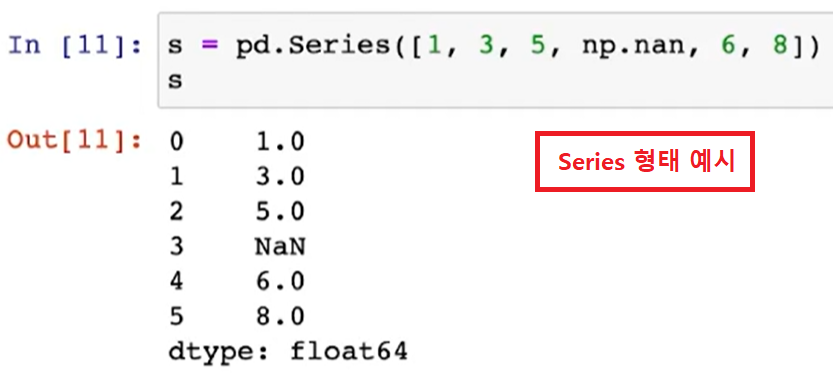
- pandas의 데이터형을 구성하는 기본은 Series이다
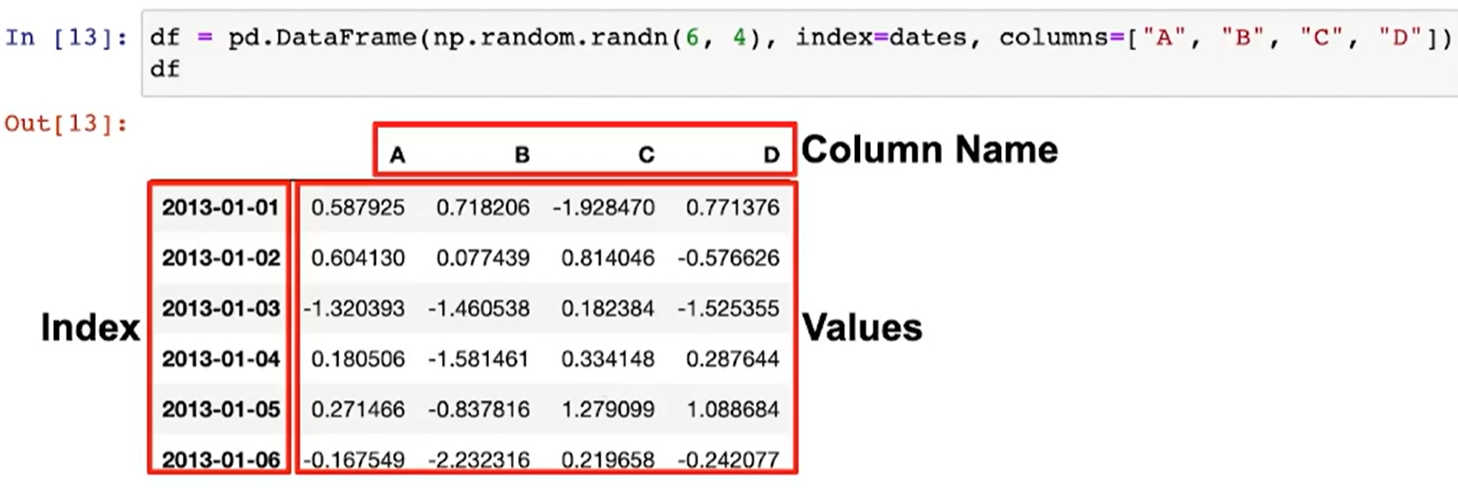
- pandas에서 가장 많이 사용되는 데이터형은 DataFrame이다
(= index와 columns를 지정하면 됨)
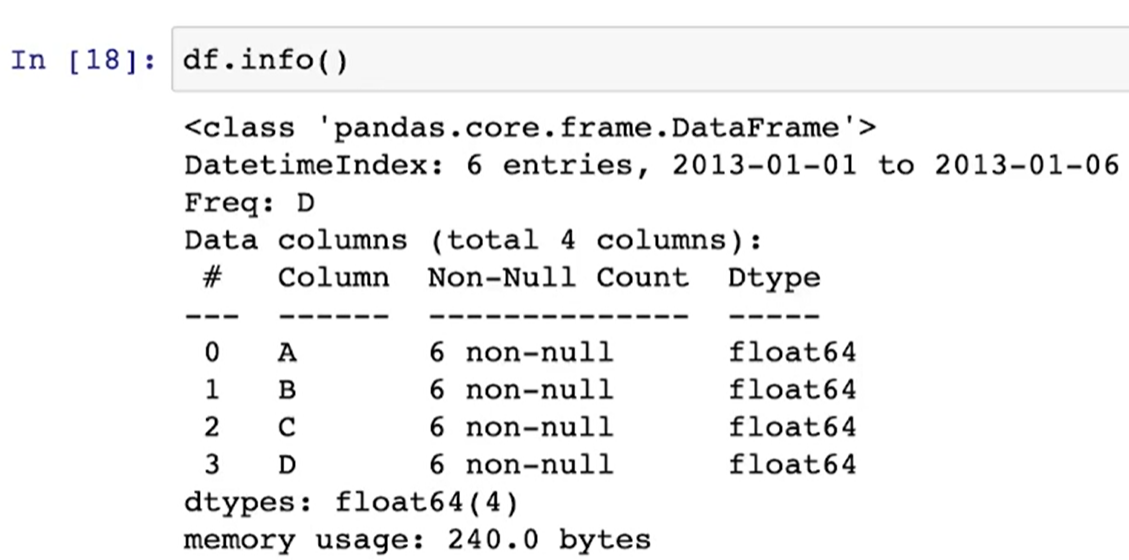
df.info( )
- DataFrame 기본정보 확인(for 컬럼의 크기, 데이터 형태 확인)
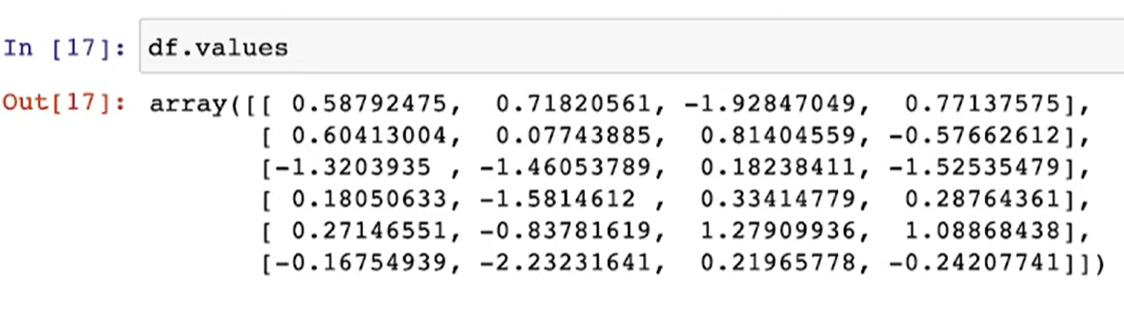
df.index / df.values
- DataFrame의 인덱스, 컬럼, 값 확인

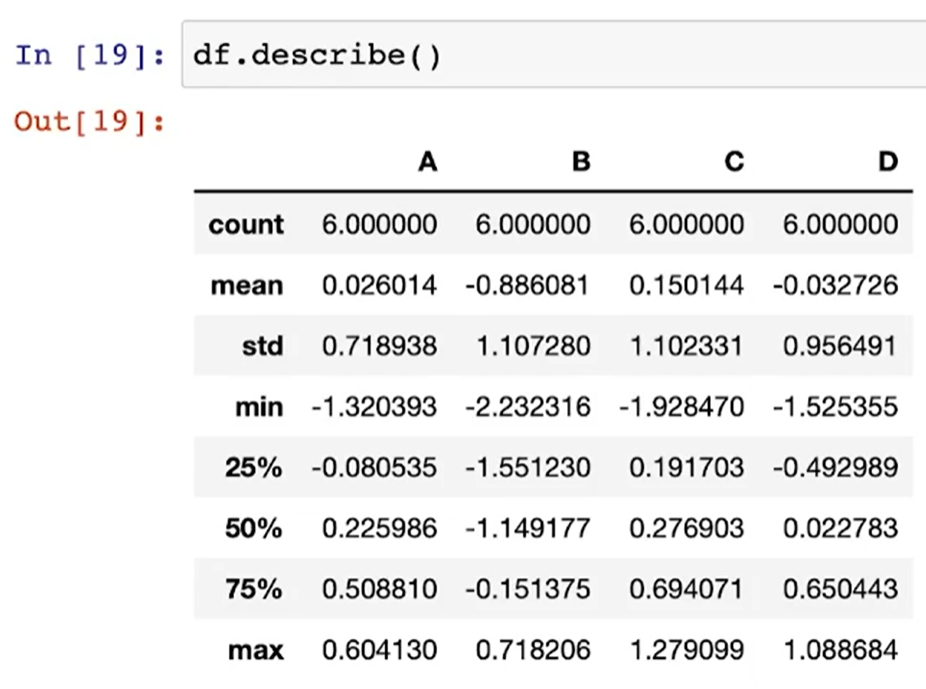
df.describe( )
- DataFrame의 통계적 기본정보 확인
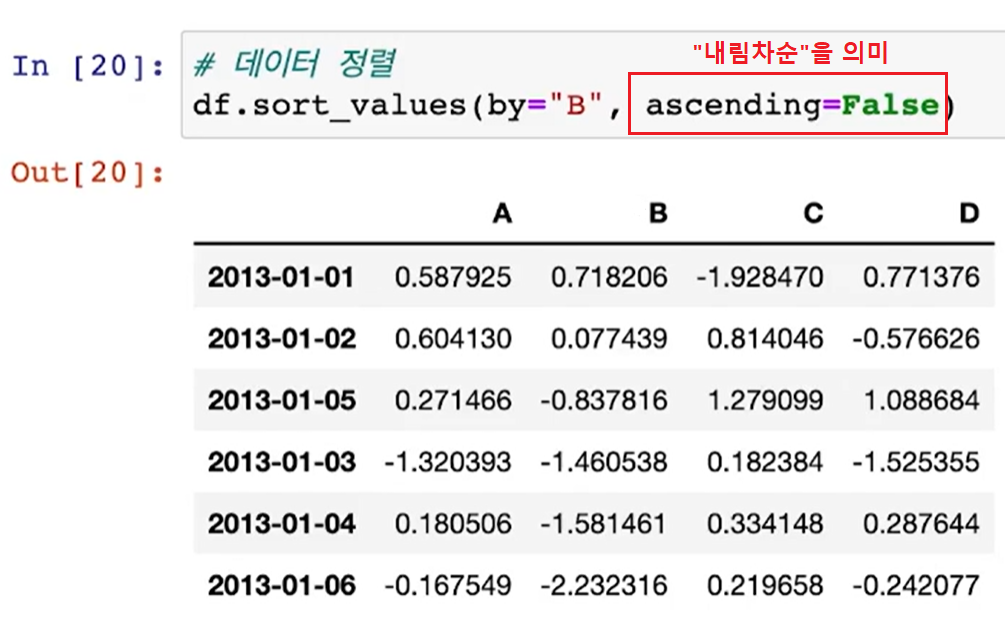
df.sort( )
- 기준값(by=?)을 잡고 데이터 정렬
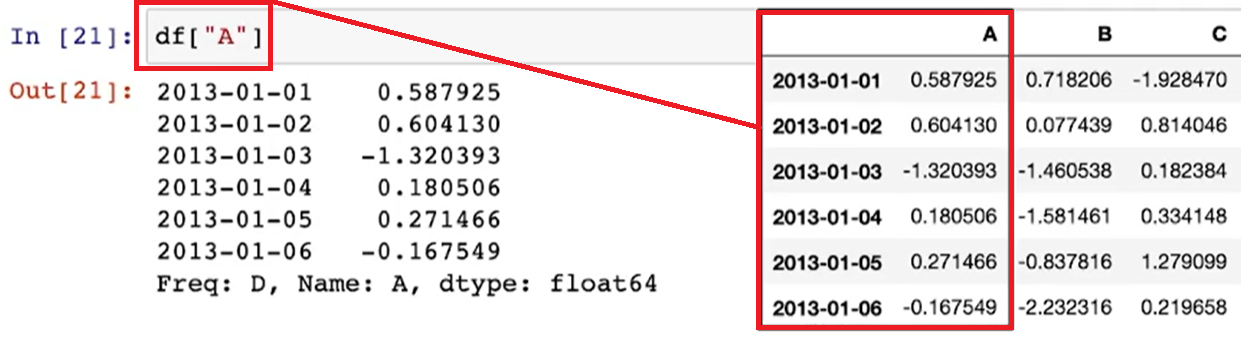
df[" "] / df[m:n]
- 특정 컬럼만 슬라이싱해서 읽어오기
~ Data Slice ~
(참고 1) df [ 0 : 3 ] = 인덱스를 0에서부터 3개(0,1,2)만 읽어와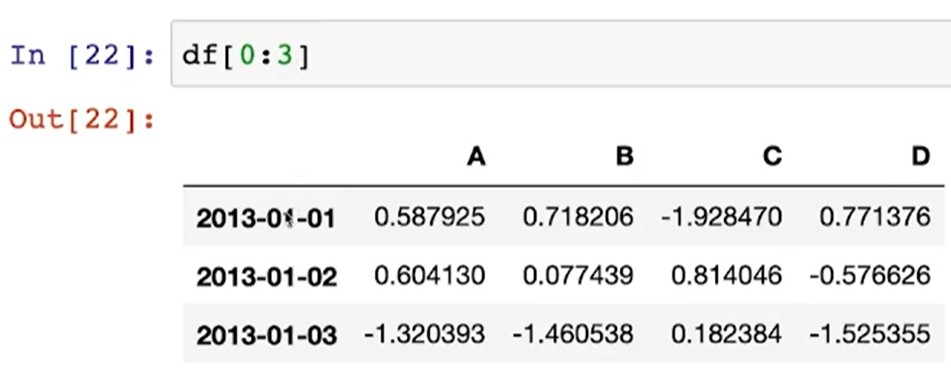
(참고 2) 인덱스명으로 직접 지정할 수도 있음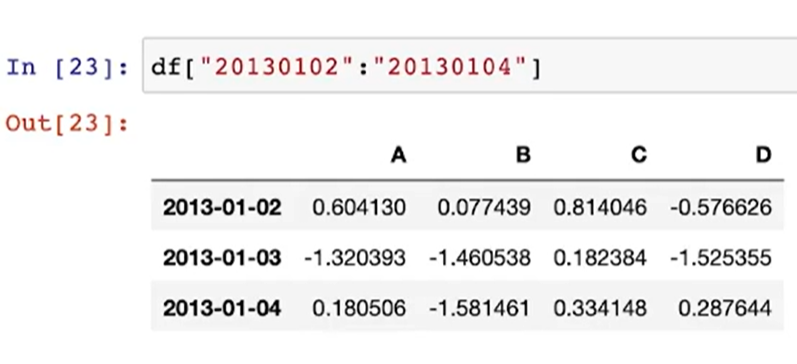
df.loc[ ]
(참고 3) 로케이션(loc)를 활용하여 "행,열"의 형태로 지정할 수도 있음
(참고 4) 특정 인덱스의 특정 컬럼만 지정할 수도 있음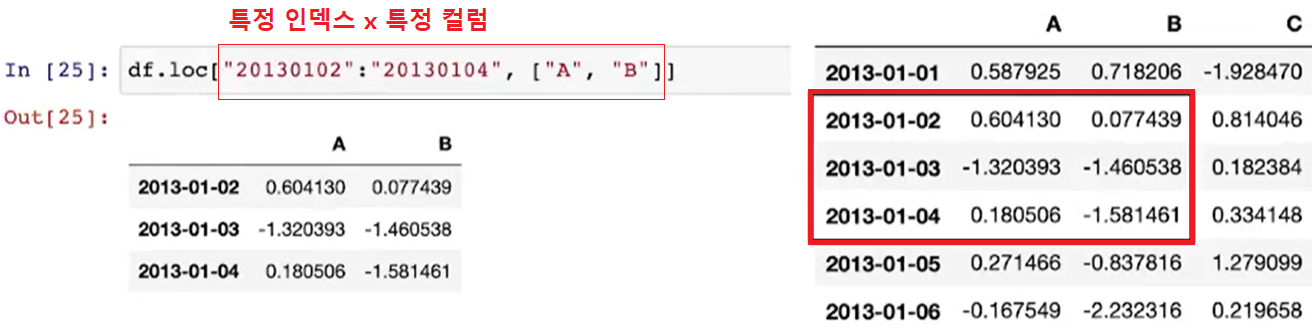
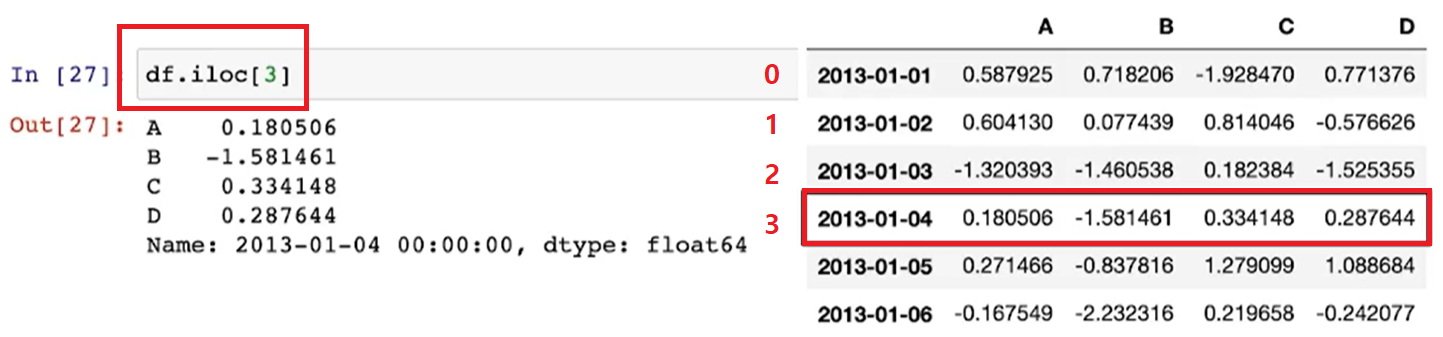
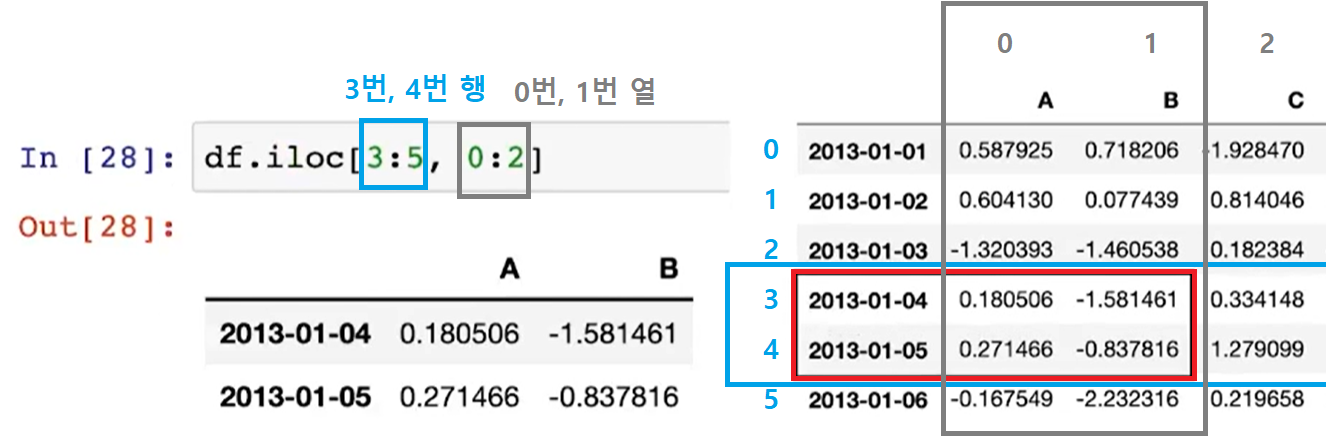
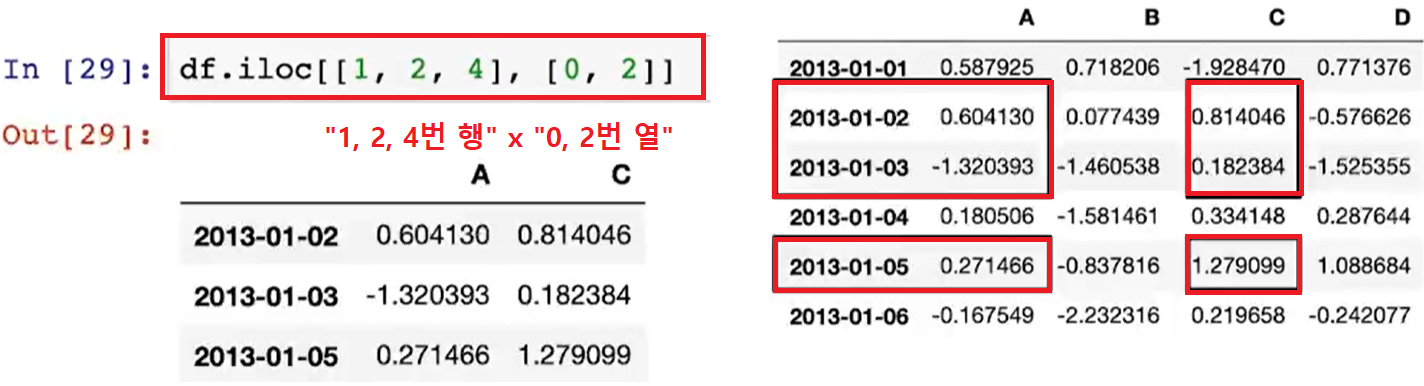
df.iloc[ ]
(참고 5) 변수명을 이용(loc)하지 않고 "번호(iloc)"로 지정할 수도 있음
(!!주의!!) df [ condition ] 과 같이 사용하는 것이 일반적인 형태임
단, pandas 버전에 따라 허용하는 문법이 조금씩 다름
= 인터넷에서 확보한 소스코드를 돌릴 때는 pandas의 버전도 함께 확인해야 함
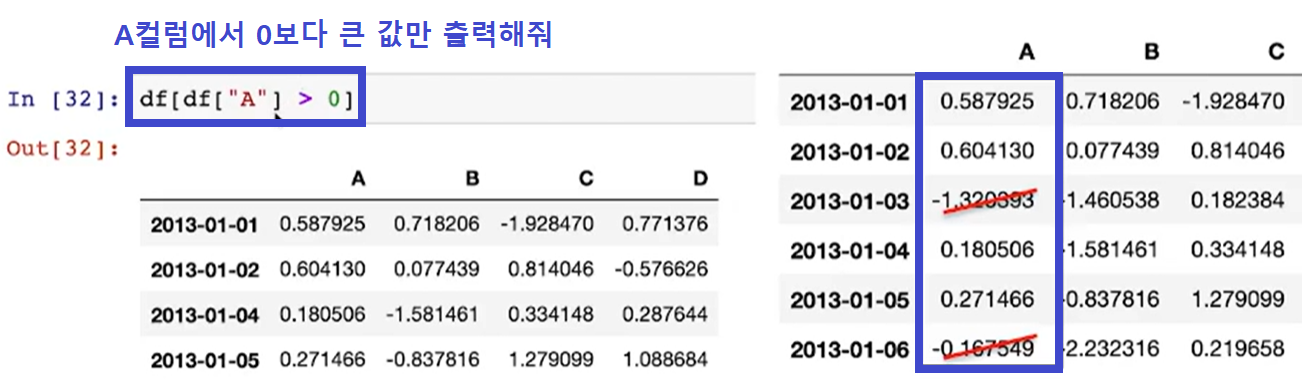
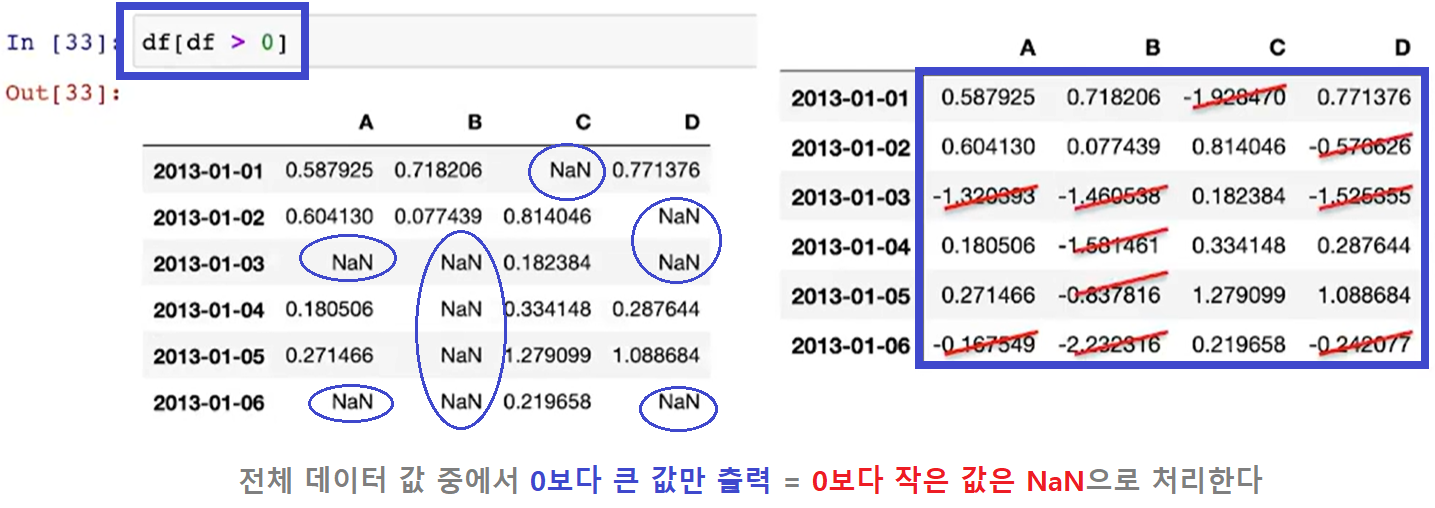
df[조건문]
(참고 6) 조건문 적용할 수 있음
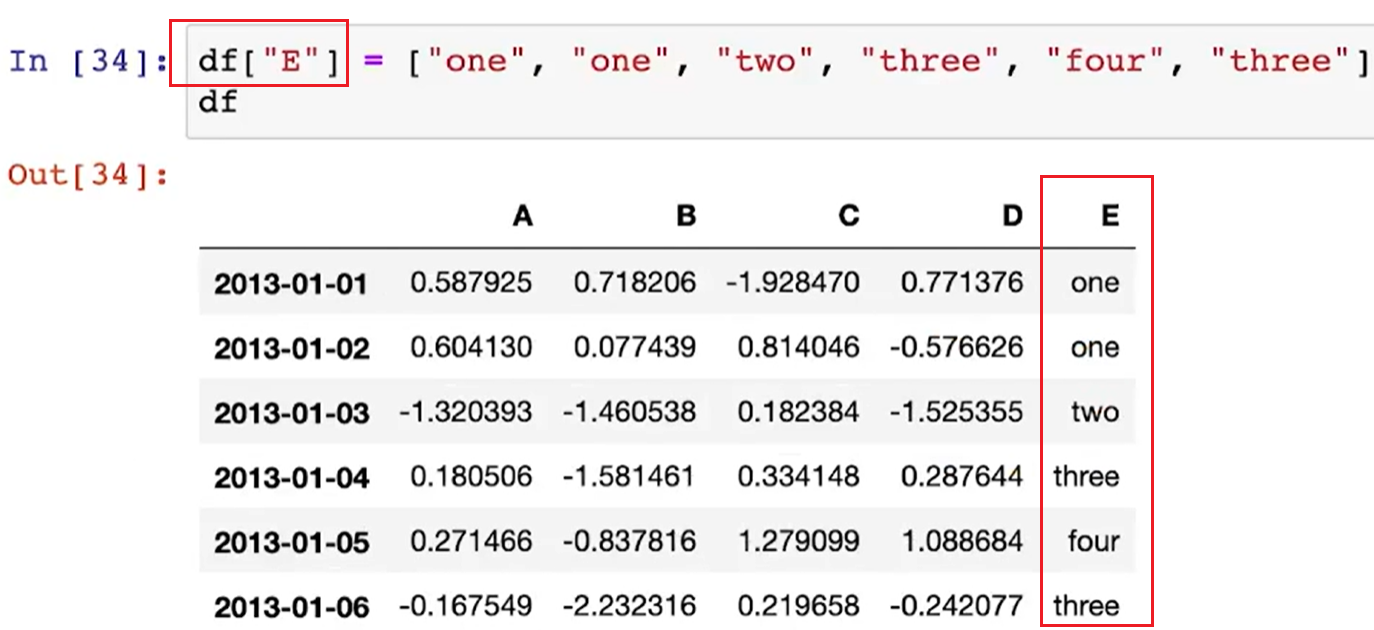
df[" "] = [ , , , ]
- 새로운 컬럼 생성(추가) : 기존에 없는 컬럼은 추가, 기존에 있던 컬럼은 덮어쓰기
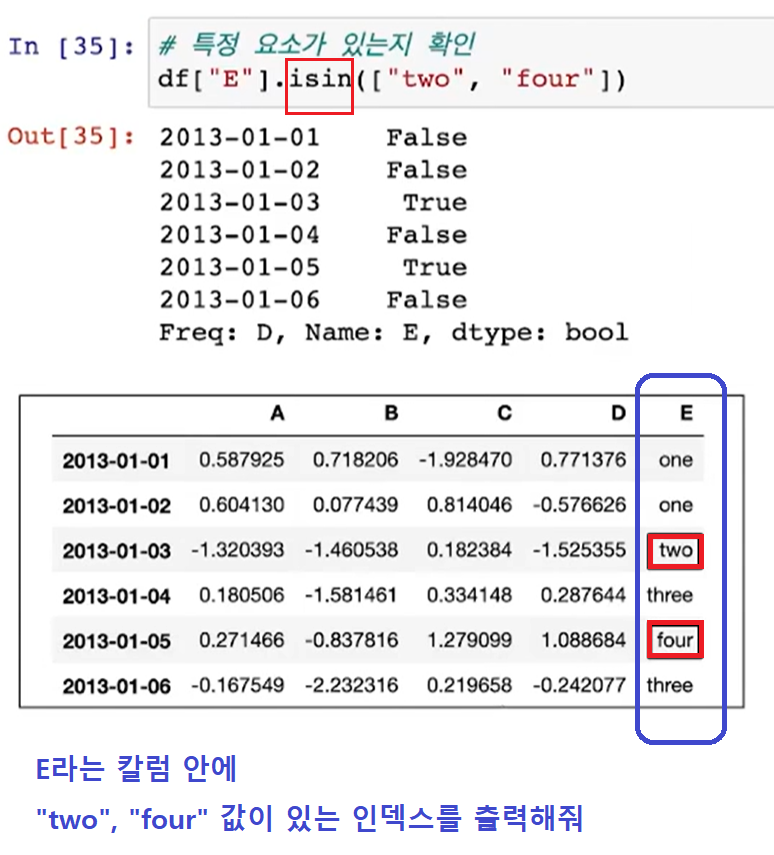
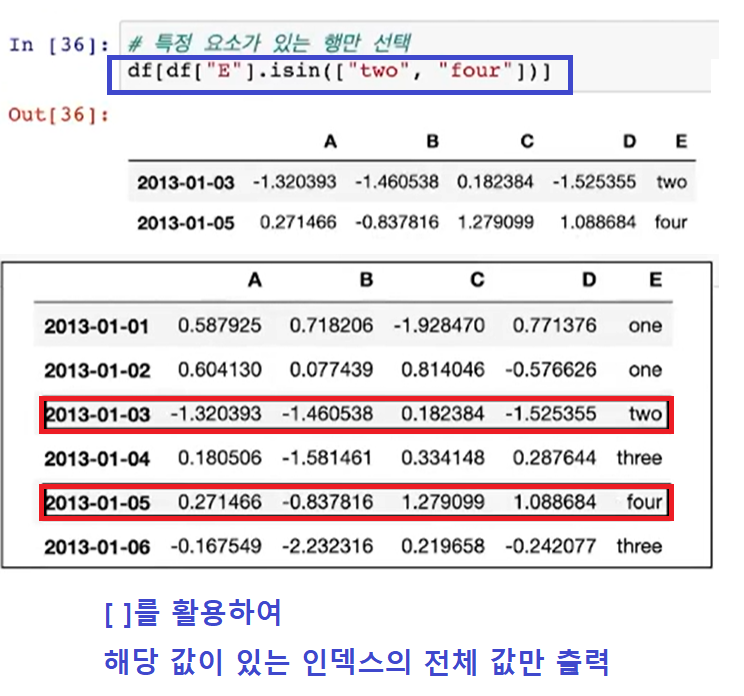
.isin( )
- 특정요소 검색
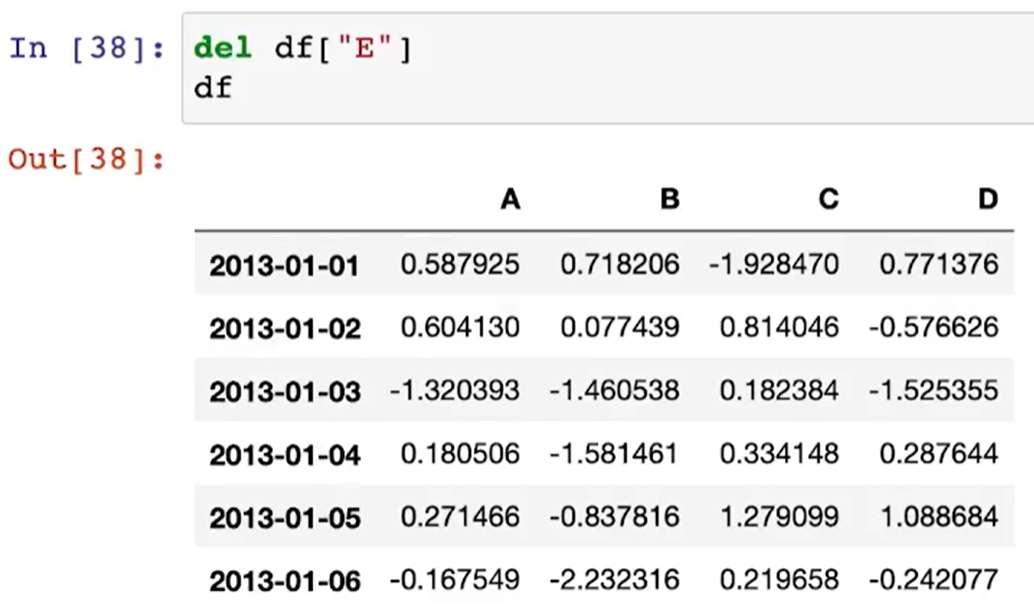
del df[" "]
- 특정 컬럼 제거
df.apply(함수)
- 함수 적용

