
- udemy (강의 링크), 총 7시간 과정





1-4. SW Program 개발 방법론의 변화
SW 1.0(규칙 기반 프로그래밍) -> SW 2.0(자동 프로그래밍=딥러닝 + 사전학습,미세조정) -> SW 3.0(초거대 모델&제로샷/퓨샷)
- SW 1.0 : 입력 값으로부터 원하는 출력이 나오도록 SW를 하나부터 열까지 사람이 직접 작성(데이터 정의, 연산식도 사람이 작성---> 이렇게 만들어낸 연산의 집합 중 최선의 것이 무엇인지도 사람이 판단)
- SW 2.0의 품질을 결정하는 요소 : 데이터, 인공지능 모델의 구조(=프로그램이 요구하는 연산의 틀/ 연산의 틀은 특징찾기 + 판단하기로 구성) 모델의 파라미터를 조정하며 최적의 값을 Machine이 찾는다(=연산 방식을 기계가 스스로 찾는다)
= 태스크별로 다른 모델 생성 - SW 3.0 " 모든 데이터를 제공, Machine이 알아서 학습(eg. chatGPT)
= 모든 태스크를 다룰 수 있는 하나의 만능 모델 생성
1-5. AI 기본 원리 이해
SW 2.0
-
[ 학습단계 1 ] 학습데이터 준비
(1) 데이터 수집 : 무엇이 좋은 데이터인가? 각각 몇 개의 샘플을 모아야 하는가?
(2) 학습 데이터 생성(라벨링/어노테이션) : 다수의 데이터라벨러가 공통된 기준으로 라벨링 작업을 할 수 있게 하는 가이드 라인은 무엇인가?
*"학습을 한다" = 최적의 프로그램을 찾는다 = 최적의 연산방법을 정한다 : 연산의 "결과값"과 데이터라벨러가 입력한 "정답값"이 일치하는 연산이 최적의 연산이며, 이를 반복하며 결과값과 정답값 차이의 오차를 줄여나가는 과정이 곧 학습임 -
[ 학습단계 2 ] 모델 학습(실질적인 학습 단계)
(1) 모델 구조를 만든다
(2) 모델 구조에 최적의 연산 집합을 찾아낸다(by. Try&Error 방식) : Try1에서 랜덤하게 연산들을 만들어냄 -> 랜덤하게 만든 연산의 예측값들(결과값)과 정답값들의 오차를 계산하여 Try1의 오차 평균을 구함...
(3) 같은 방식으로 TryN 시행한 후 오차(Error)가 가장 작은 Try'k'가 최적의 연산집함 = 최적의 모델 = 학습 완료된 모델 = 추론 시 사용되는 모델(서비스 사용시) -
[ 딥러닝 ] 모델 구조(기본)
(1) 딥러닝 연산의 틀은 레이어, 레이어는 복수의 레이어로 구성, Neural Network에서는 각각의 노드 단위로 연산이 수행
(2) 레이어가 많은 깊은 구조 = 딥뉴럴네트워크
(3) 딥뉴럴네트워크를 학습시키는 방식 = 딥러닝
(4) 주로 이미지 처리에서는 CNN, 자연어 처리에서는 RNN 방식이 효율적이며 효과적인 것으로 알려져있음(CNN, RNN과 같이 이미 여러 사람들을 통해 "검증된 연산 틀(모델)"이 많이 존재함)
자연어 처리 과정 : 텍스트 수집 -> 정의된 특징(토큰화) -> (토큰 단위로 특징값을 추출, 판단하면서)학습 데이터 생성
- 토큰 = 의미 단위의 기본 유닛(의미분석에 용의한 단위로 잘게 쪼개는 것 = 토큰화)
-
[ 딥러닝 방식의 변형(고도화) ] 사전학습 & 미세조정 (본 강의 26:00~)
(1) 학습 효율화를 높이기 위함 : 기존 방식의 비효율성(태스크 바뀔때마다 다른 모델이 필요)
(2) 학습을 사전학습(특징찾기), 미세조정(판단하기) 2단계로 나누어서 진행
= step 1(사전학습) : 판단하기를 배제한 채로 특징 찾기만 열심히 학습하기 -> 어떤 데이터가 입력되어도 특징을 잘 찾아내도록 훈련시키는 것이 목적(사전학습&미세조정 방식의 핵심)
= step 2(미세조정) : 사전학습 단계에서 완료한 "특징찾기"는 추가로 학습하지 않고(=frozen=이미 사전학습된 연산을 그대로 차용=미세조정 단계에서는 학습대상에서 제외시킴) -> 판단하기만 열심히 학습(이 모델로 내가 찾고자 하는 것이 무엇인지 판단하는 것만 새로 학습 = 판단기준만 바꿔기면 ok, 딥뉴럴네트워크 구조에서 판단하기는 말단에 존재하므로...)
(3) 그럼에도여전히 태스크마다 다른 모델이 필요하지만, 전체를 매번 다시 학습하는 것보다 모델이 연산해야 하는 양이 확연히 줄어드는 효과를 거둘 수 있음
(= 특정 태스크를 수행하는 모델 개발에 필요한 데이터의 양 축소 = 개발기간 축소 = 비용 축소 = 개발속도 급증 = 다양한 산업에서 AI를 널리 사용할 수 있는 발판 마련) -
사전학습 & 미세조정 text data 관점에서 살펴보기(eg. GPT1)
본 강의 32:50 ~
(1) 이미지와 달리 자연어는 자유도가 높고, 문장의 길이가 다양하며, 문장/맥락에 따라 문화에 따라 내포하는 의미가 달라짐
(2) 기존의 사전학습(사람의 라벨링 작업이 반영)과는 다른 방식의 학습이 필요 : 입력된 텍스트만을 보고도 모델이 바로 정답을 출력하는 방식이 필요하다!(= Un-supervised pre-training = Self-supervised pre-training
= Language Model : 앞에 나온 단어를 보고 바로 뒤에 나올 단어를 예측하라!(다음에 나올 단어로 가장 확률이 높은 단어가 무엇이지?)
(3) 사전학습 단계에서는 라벨링 작업이 없지만, 미세조정에서 라벨링 작업이 필요함 -> 긍정 or 부정 리뷰(by.윤리적 판단)
SW 3.0
- 본 강의 44:20 ~
(1) GPT 2.0 => GPT 3.0 과정에서 학습 데이터 양을 대폭 늘림
(2) 데이터 사이즈를 키웠더니(=초거대 모델) 미세조정 없이도 사전학습된 모델이 결과값을 잘 만들어내더라
=입력 텍스트 + 태스크 설명을 덧붙였더니 미제조정 없어도 원하는 결과가 나오네?
(3) 결국 태스크별로 모델 필요없음 = 태스크별로 학습데이터 준비할 필요 없음 + (미세조정 없이) 하나의 모델로 많은 태스크 대응 가능 - 제로샷 : 태스크 설명만 있고 초거대모델에 바로 지시
- 원샷 : 중간에 예제 하나 추가
- 퓨샷 : 중간에 예제 여러 개 추가(예제를 여러개 줄 수록 일종의 미세조정 효과가 나타나므로 성능이 높아지는 경향이 있음)
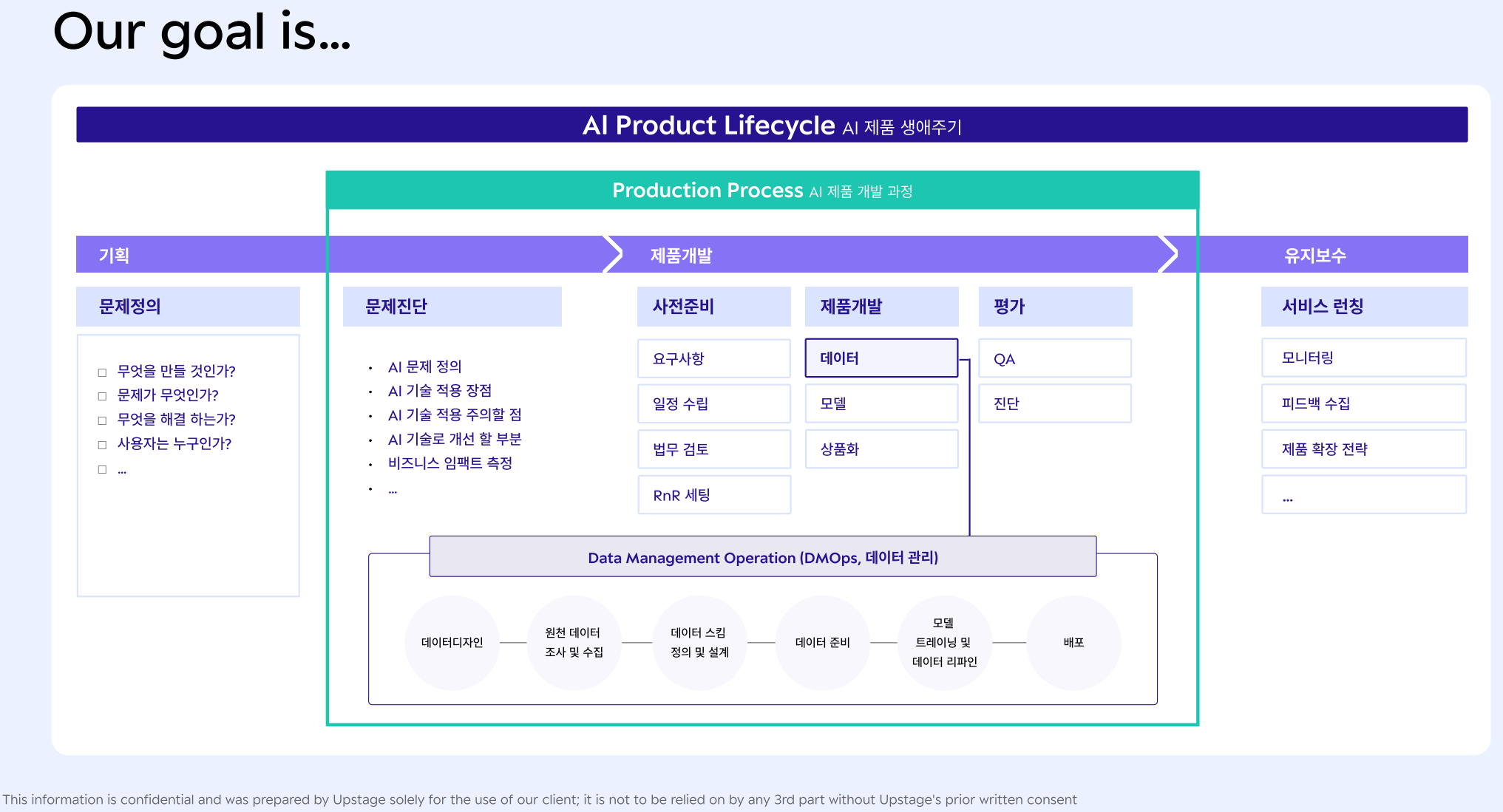
2-1. 제품기획, 어떻게 정의하고 진단할 것인가?
AI 기술 적용여부 판단
- AI가 서비스의 필요한 문제를 해결할 수 있을 때!
- AI 기술이 효율적으로 문제를 해결할 수 있을 때!
- AI를 적용하는 것이 실제로 서비스에 큰 임팩트를 줄 수 있다고 판단될 때!
-> AI가 잘 할 수 있는 영역인가? : AI를 적용하는 것이 비효율적인 경우도 고려할 것!
-> 현재의 AI기술로 실현 가능한가? : 쉽게 적용할 수 있는지? 어렵지만 해볼 수 있는 정도인지? 현실적으로 불가능한지? (개발팀과의 긴밀한 협의 필요)
- AI를 적용하는 것이 실제로 서비스에 큰 임팩트를 줄 수 있다고 판단될 때!
AI가 잘하는 것
자동화, 예측, 개인화, 자연어 이해
AI가 어려워하는 것 = Heuristics = SW 1.0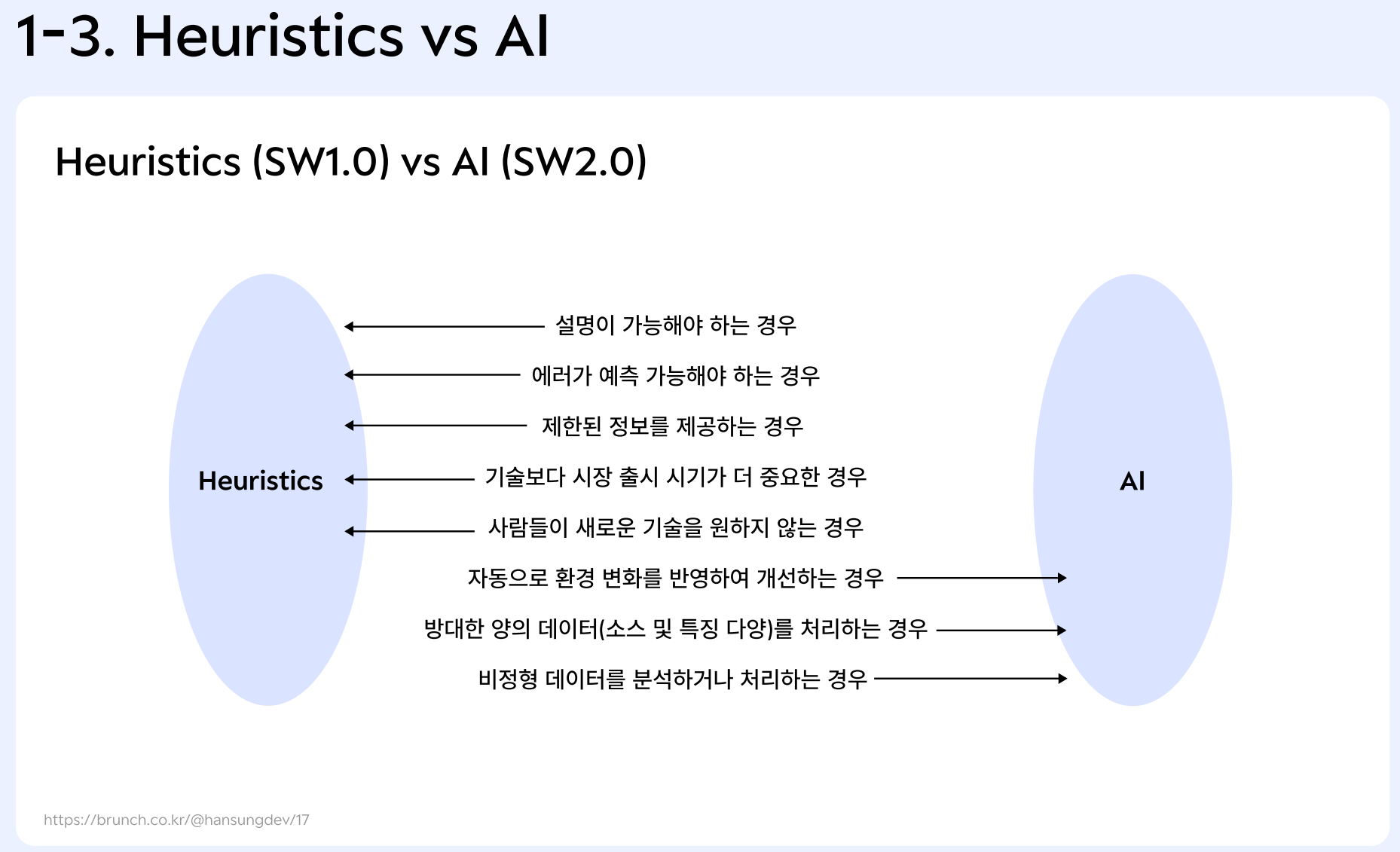

2-2. 모델 요구사항 구체화
[참고 1]
- OCR은 글자 인식만 가능
- 따라서 서비스에 활용할 땐 대체로 OCR과 parsing(의미분석 기술)을 함께 사용함.
- 그러나 서비스 내용에 따라서 의미분석은 AI보다 휴리스틱으로 하는 것이 비교적 더 간단한 경우도 많음(개발자 의견 청취 필요)
[참고 2]
- 서비스 개발 시 관련 외부 API가 있다면, API를 활용하고 디테일한 부분에 한하여 필요한 모델만 직접 개발하여 내재화하는 방향이 다수(단, 이 경우 외부 API비용 검토와 서비스 약관, 법무적인 이슈를 함께 파악해야 함)
- 라벨링 작업 = 어노테이션 / 자체적으로 라벨링툴을 활용하여 외부 인력(아르바이트)을 사용하여 작업하는 경우 다수
1. 제품 개발을 위한 사전 준비 사항
- 개발 과제 요구사항 파악
- 일정 수립
- 서비스 법무 검토
- R & R 세팅 등
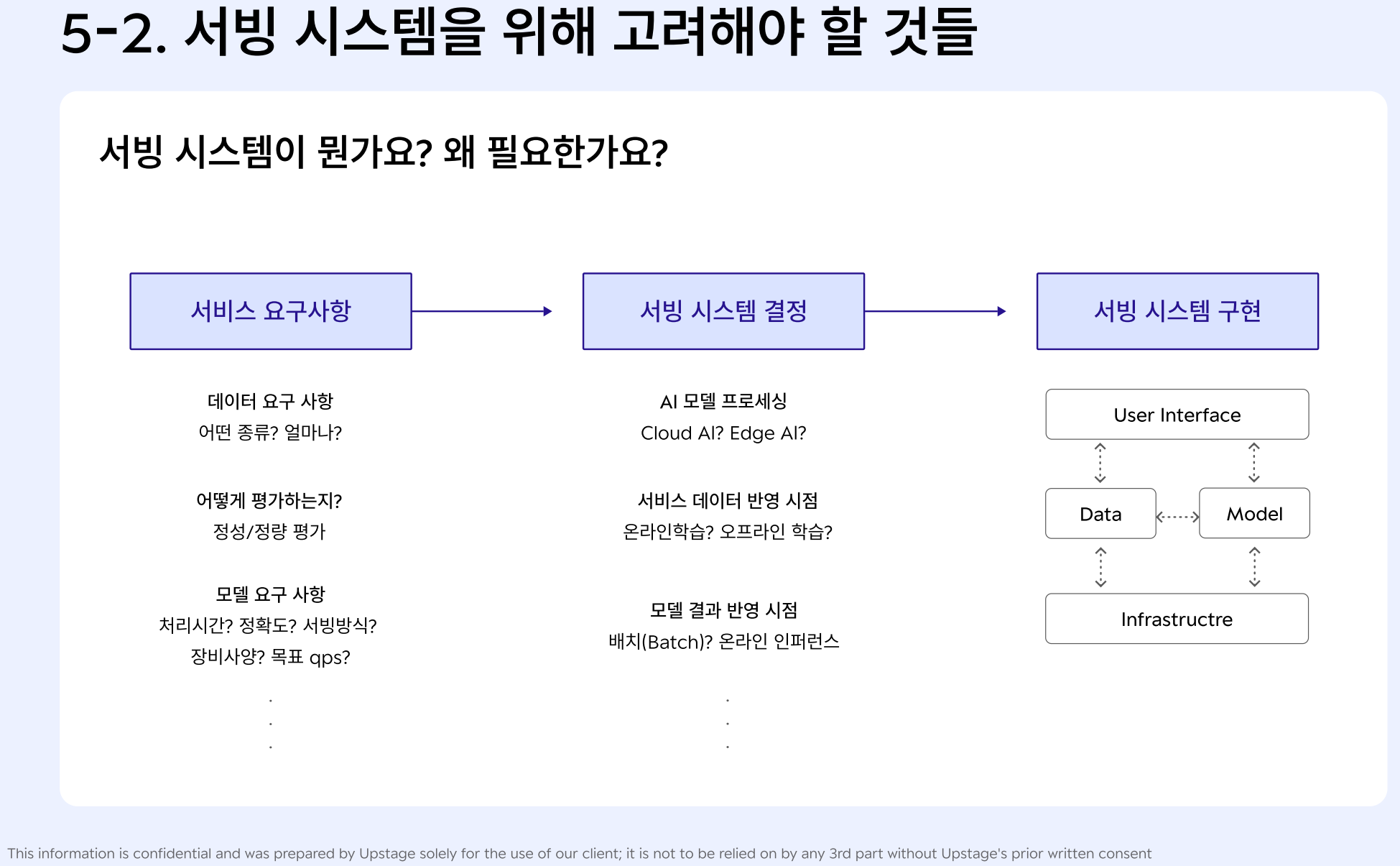
(1-1) 서비스 및 모델 개발 과제 요구사항 파악
= AI 모델 개발에 필요한 기준을 정립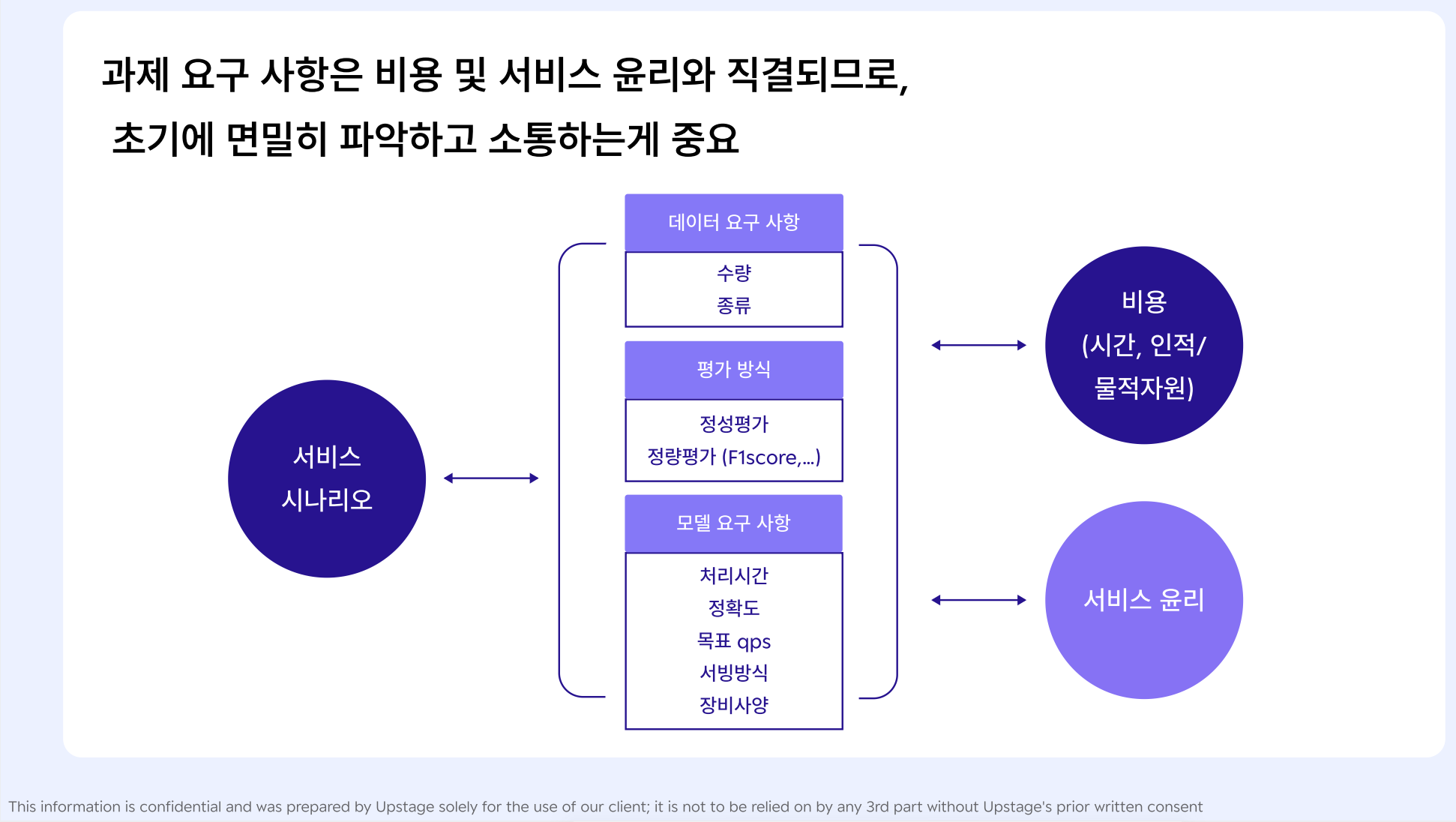
- 과제 요구사항 명확화 : 데이터 / 평가방식 / 모델측면
[ 데이터 ]
(1) 얼마만큼의 학습용 데이터(비용과 직결)와 테스트용 데이터(모델 평가와 직결)가 필요한가?
(2) 어떤 종류의 데이터가 필요하며(데이터 다양성), 필요한 데이터를 판별하는 기준이 명확해야 함
(3) 엣지 케이스도 충분히 확보해야 함('특이사항'을 의미하는 엣지케이스의 구체적인 정의도 필요함)
-> 엣지케이스(희귀 케이스)를 얼마나 커버하느냐가 성능 차별화, 개선 포인트가 됨
[ 평가방식 ]
(1) 사용 시나리오를 바탕으로 서비스의 평가방식을 도출
(2) 정확도, 재현율, F1 score ...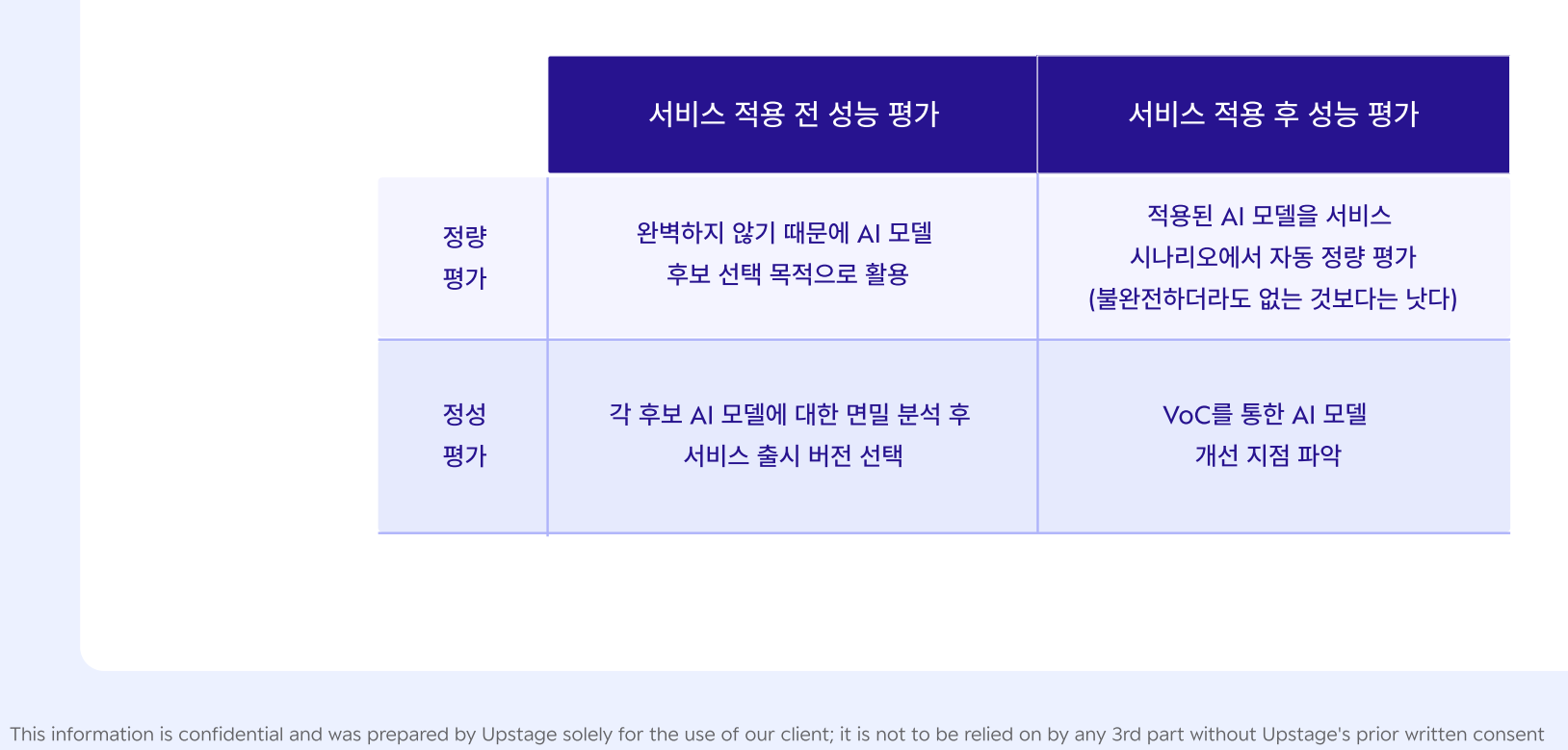
[ 모델 요구사항 ]
(1) 처리 시간 : 하나의 입력이 처리되어 출력이 나올 때까지 소요되는 시간
(2) 목표 정확도 : 해당 기술의 정량적인 정확도
(3) 목표 qps(Queries per second) : 초당 처리 가능한 요청 수
- 개발 관점에서 '하루 평균 사용량'은 크게 중요하지 않음, 중요한 건 QPS임
- 순간 최대 사용량이 어느 정도일 것인지 예상해야 함 -> 인프라와 모델 메모리 사양, 처리 시간을 고려하기 위함
-> 인프라(서버 갯수), 모델(모델이 차지하는 메모리의 크기, 처리 속도)
(4) 서빙 방식 : 모바일, 로컬 CPU/GPU server, cloud CPU/GPU server 등..
휴대폰에서 동작? 서버에서 동작? 서버라면 로컬 or 클라우드?
- 보안 측면 : 모바일이 가장 안전
- 비용 측면 : 데이터 이동으로 인한 비용 발생 예상
- 서비스 품질 : 서비스 관점에서의 속도
-> (AI 모델의 경우) 일반적으로 모바일> gpu 서버 > cpu 서버 순으로 속도가 빠름
(5) 장비 사양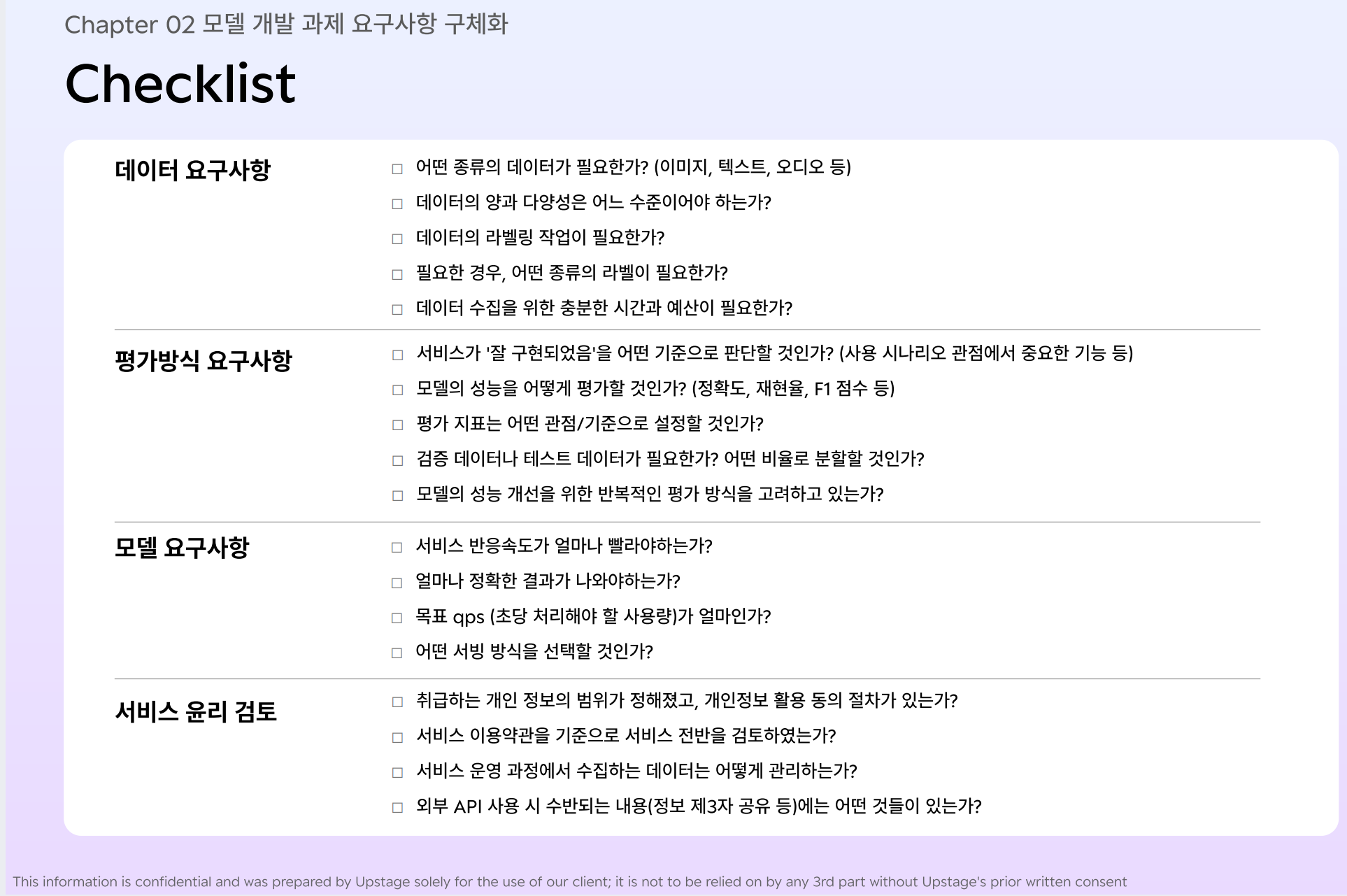
2-3. 중요한 것은 양질의 데이터
데이터 관련 업무가 어려운 이유
1) 어떻게 하면 좋을지에 대해서 알려져 있지 않다.
- 모델의 성능 = 데이터의 힘(양질의 충분한 데이터) + 모델의 힘(구조/학습방법)
-> 본 강의 4:30~ - 실제 출간되는 논문의 비율 데이터:모델 = 1:99 -> 모델링은 참고자료가 많지만 데이터는 매우 드물다(수집된 데이터의 상태에 따라 천차만별이기 때문)
2) 데이터 라벨링 작업은 생각보다 많이 어렵다
- 데이터가 많다고 모델 성능이 항상 올라가는 것은 아니다
-> "라벨링 노이즈"가 많으면 데이터가 많아도 성능은 오히려 떨어진다.
라벨링 노이즈 : 여러 사람에게 같은 라벨링 작업을 시켰을 때 작업 결과가 다른 정도
-> 잘못 라벨링된 샘플 하나를 무시하기 위해서는 두 배 이상의 데이터가 필요함
3) 데이터 불균형을 바로 잡기가 많이 어렵다
- 가능하면 데이터는 "골고루" + "일정하게" 라벨링된 데이터가 많아야 한다
-> "골고루" = 엣지케이스의 샘플 수도 일반적인 샘플 수에 준하도록 늘려야 한다
-> "일정하게" = 라벨링 노이즈가 적게 어노테이션 작업을 수행한다
데이터 준비 A to Z
-> 본 강의 31:10 ~
(각 단계별 상세 체크리스트는 교재ch.03 참고)
[ 데이터 ]
1) 데이터 디자인
- 사용자의 니즈를 인공지능 모델을 훈련하는 데 필요한 데이터 니즈로 변환하는 단계
2) 원천 데이터 조사 및 수집
- raw 데이터, 도메인 데이터 파악 및 수집방식 고려 + EDA & 데이터를 정성적으로 검토
- 데이터 요구조건에 영향을 미치는 요건
-> 데이터의 퀄리티
-> feature의 수 : feature가 많다 = 사전에 정해줘야 할 요건이 많다(도메인 지식이 필요)
3) 데이터 스킴 정의 및 설계
- 라벨링 계획 / 라벨링 작업 / 라벨링 작업 결과 검수
4) 데이터 준비
- 데이터 전처리* : 데이터 클리닝 / 데이터 증강(augmentation) / 데이터 정형화(formatting)
- 데이터 스플릿 : 학습용 데이터, 검증용 데이터, 평가용 데이터를 나눔
[ 모델 ]
5) 모델 트레이닝 및 데이터 리파인
- 데이터 평가(정량/정성), 데이터 시각화, 대응전략 수립, 클렌징 및 추가 구축
[ 상품화 ]
6) 배포
- 모델 배포, 서비스 운영 과정에서의 데이터 활용
7) 유지보수
Data Ethics
2-4. 모델 개발 단계에서 미리 정해야 할 것들
- 테스트 방법 설계 : ON/OFF line 테스트
- 정량평가 메트릭 : F1 score, BLEU score, accuracy, precision, recall
1) 테스트 방법 설계
- 서비스 요구사항으로부터 우리 모델을 어떻게 평가할 것인가?

OFF LINE test
- 서비스 적용 전 성능평가
- ONLINE 테스트와 최대한 유사한 테스트가 되어야 함
(실제로 성능평가가 중요한 것은 online 테스트이지만, 서비스 출시 전에는 확인할 수 없는 영역이므로 offline 테스트를 실시하는 것) - 평가 목적 : 서비스 관점에서의 품질을 보기 위한 것(모델 자체의 성능은 중요하지 않음)
ON LINE test
- 서비스 적용 후 성능 평가
- (offline 테스트에서 모델 성능을 확보하였더라도) online 테스트를 위해서 초기에는 베타테스트 기간 확보가 필요함
2) 정량평가 메트릭
모델의 정확도는 얼마인가? (for 최적화)
-
Accuracy (정확도)
-> 클래스 불균형(class imbalance) 시 학습 데이터에 대한 정확도에 문제가 발생할 수 있음 -
Precision (정밀도)
-> eg) 분류기가 o이라고 예측한 것이 실제로 모두 o으로 판별하도록 (적중률이 100에 가깝도록, 조금의 오차도 없도록)
- Recall (재현율)
-> eg) 분류기가 모든 o을 놓치지 않고 판별하도록 (조금 틀리더라도 괜찮,,)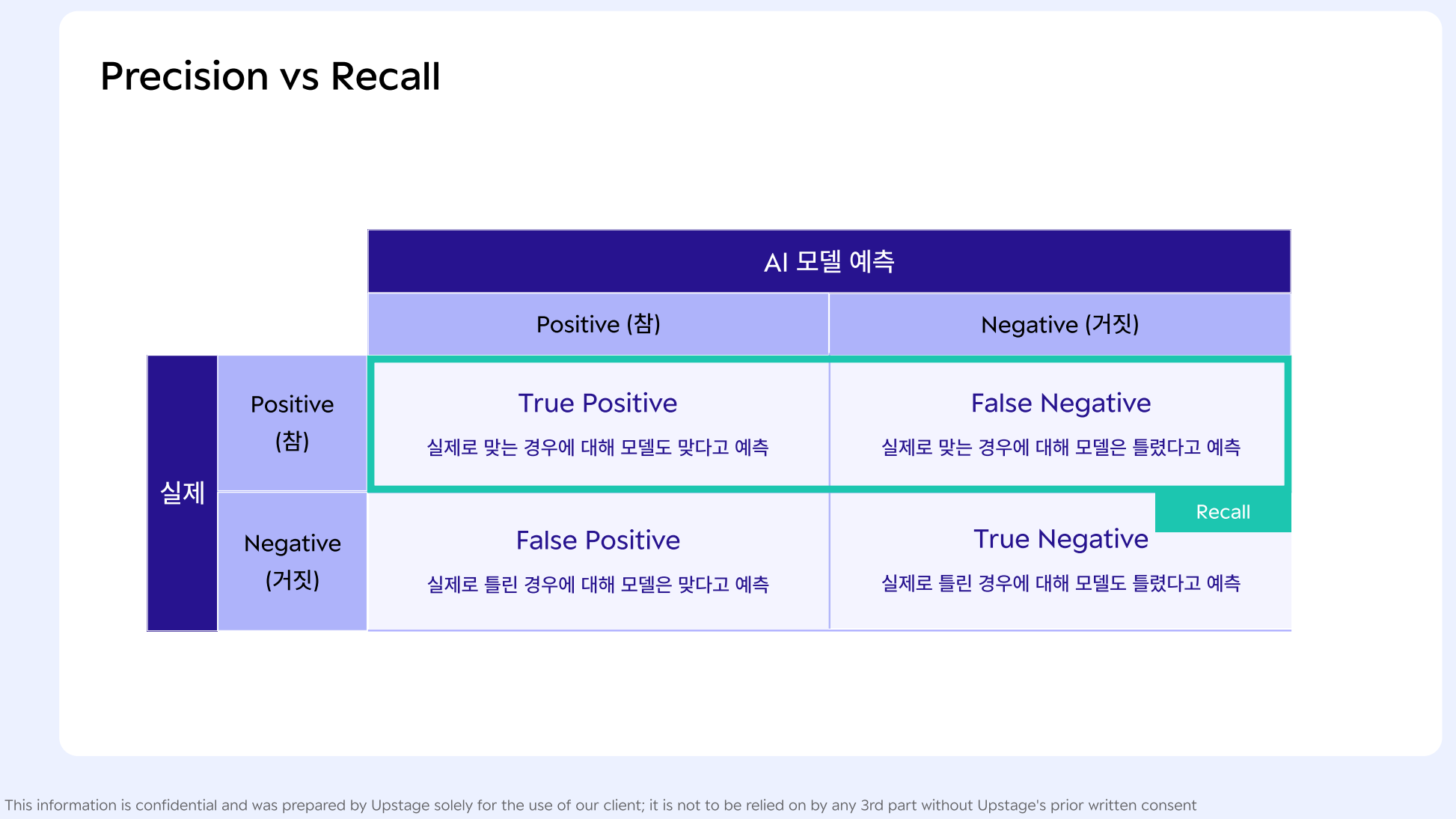
- 오인식을 줄일 것이냐 (precision) vs 미발견을 줄일 것이냐 (recall)
-> preicision / recall 은 서비스 품질과 직결
-> 모델러가 어디에 집중하게 할 것인지 판단하는 기준이 되기 때문
-> 암 진단, 알러지 성분 탐지의 경우 recall이 precision 보다 더 중요 : 놓치지 않을 거야!
-> 상품 추천의 경우 precision이 recall 보다 더 중요 : 틀리지 않을 거야!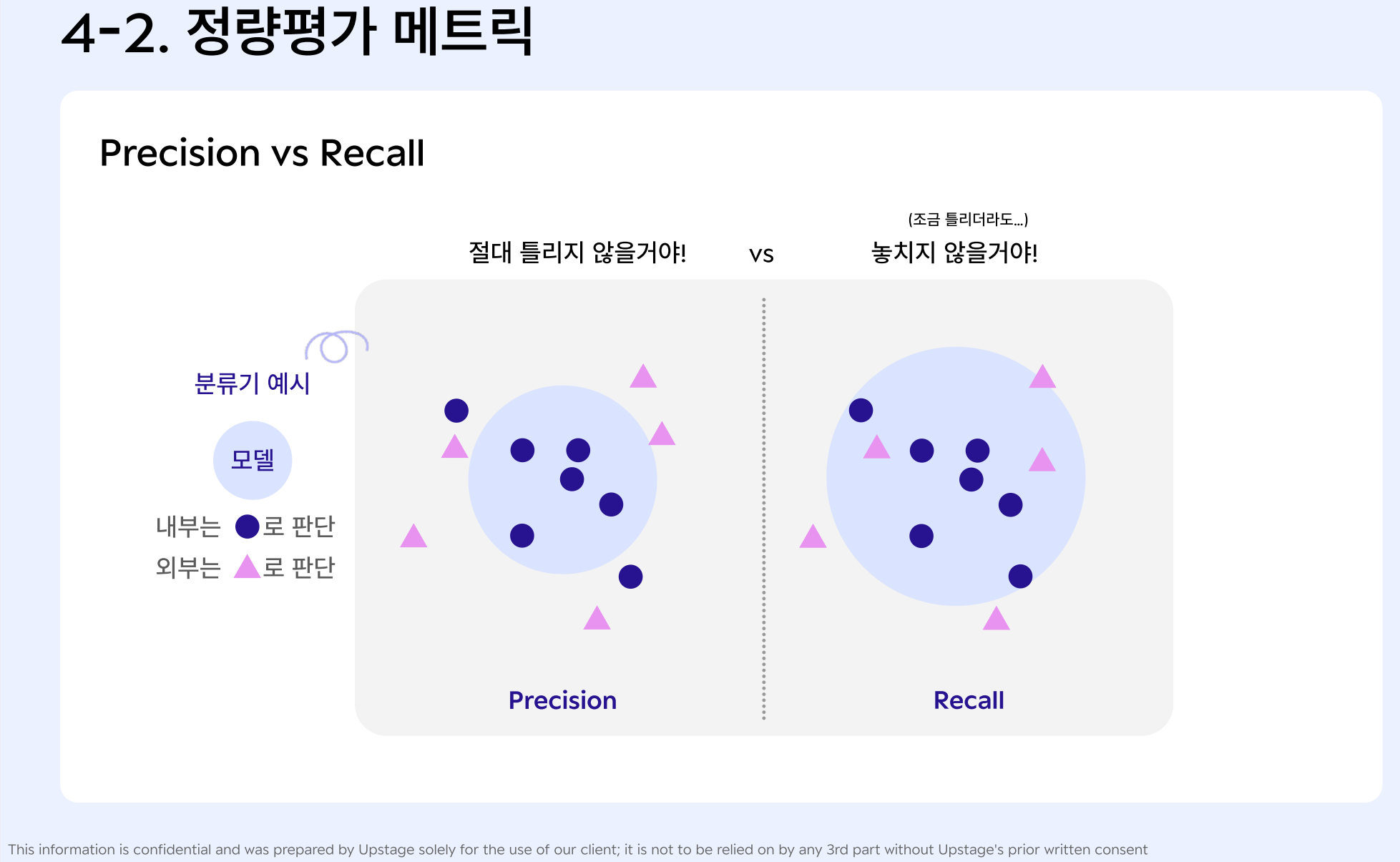
-
F1 score
-> precision과 recall을 한 번에 보는 수치, 일종의 평균 -
BLEU score (본 강의 19:15~) / Bilingual Evaluation Understudy
-> 기계번역 시스템이 생성한 번역문이 얼마나 자연스럽고 정확한지 평가할 때 사용하는 지표 : 연속된 precision의 가중 평균
-> BLEU가 높다고 반드시 자연스러운 번역을 의미하는 것은 아니지만(문맥, 문장구조, 의미 등을 고려하지 않음) 성능 평가에 유용한 도구로 널리 사용중
2-5. 잘 만든 모델, 그 다음은 어떻게?(상품화)
1) 모델이 서비스에 올라가는 과정
- 서빙 상황에 맞게 모델을 최적화
- 모델 엔지니어링 : (예시) mobile 또는 GPU server에서 구동시키기 / 경량화 작업(메모리=모델의 크기 줄이기=qps 관련) / GPU 고속처리(속도 최적화) 등
- target device에 맞춰 모델을 서빙하기 위한 작업
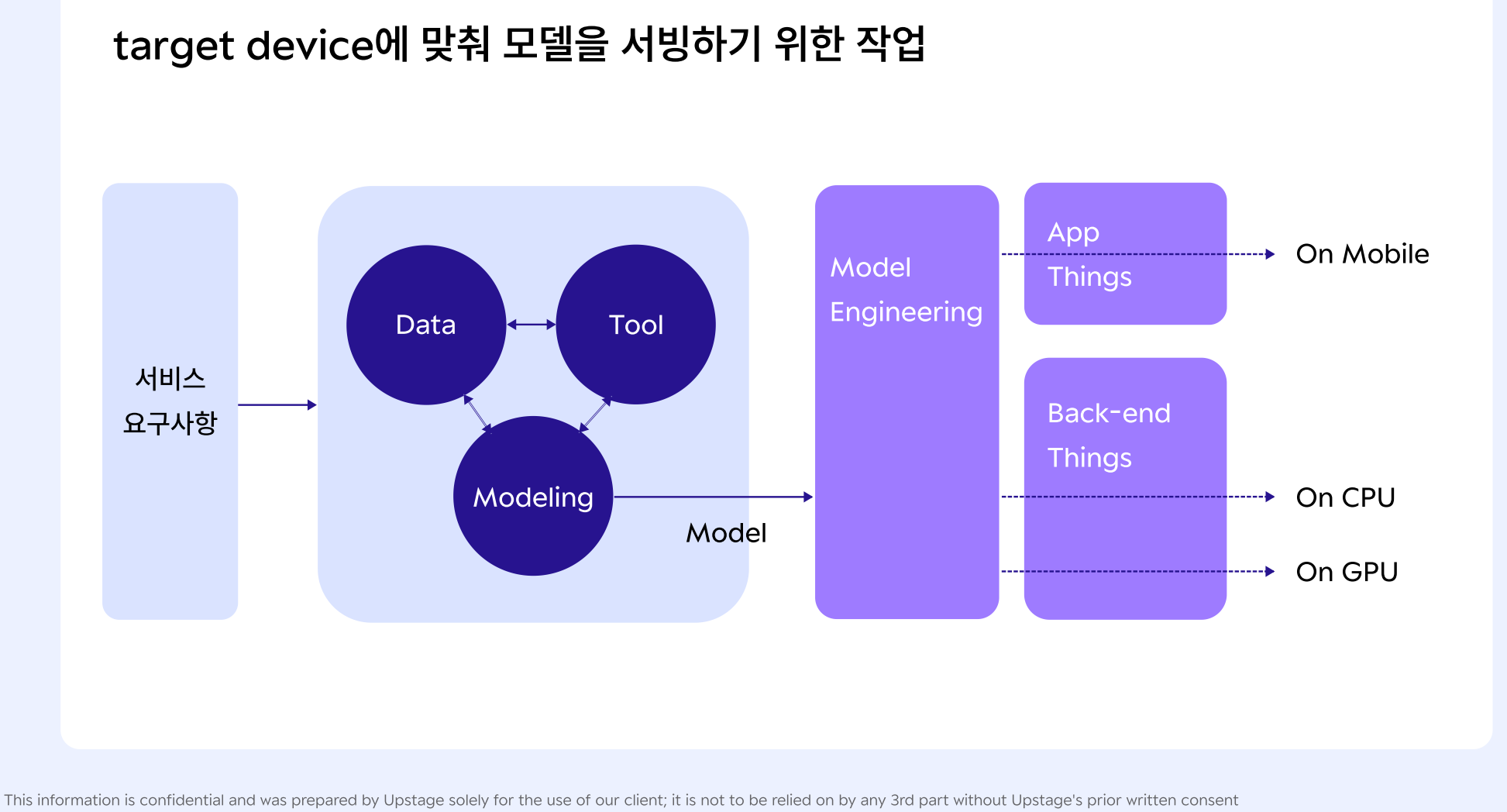
대표적으로 고려해야 할 사항들
Cloud AI vs Edge AI(모든 것이 장비 안에서 이루어짐 로컬 디바이스)
- AI 모델 운용을 어떤 디바이스에서 진행할 것인가?
[모델 업데이트 주기] Offline learning(긴 주기) vs Online learning(짧은 주기)
- 모델 성능향상 및 유지보수 목적으로 모델을 다시 학습(=업데이트)시킬 필요가 있는데, 해당 모델의 학습주기를 어떻게 잡을 것인가? = 재학습을 얼마나 자주 할 것인가?
[결과값 업데이트 주기] Batch(offline) inference vs Online inference
- 모델 결과값을 적재했다가 한 번에 여러 개를 출력할 것인가, 실시간으로 출력할 것인가?
- 단 실시간일 수록 모델 요구사항이 까다로워짐(=고려할 사항 많다)
서빙 시스템 디자인 예시 : 본 강의 18:30 ~
비용과 직결되는 서빙 시스템 : 본 강의 20:45 ~

2-6. 서비스가 기대만큼 작동하지 않는 이유(유지보수)
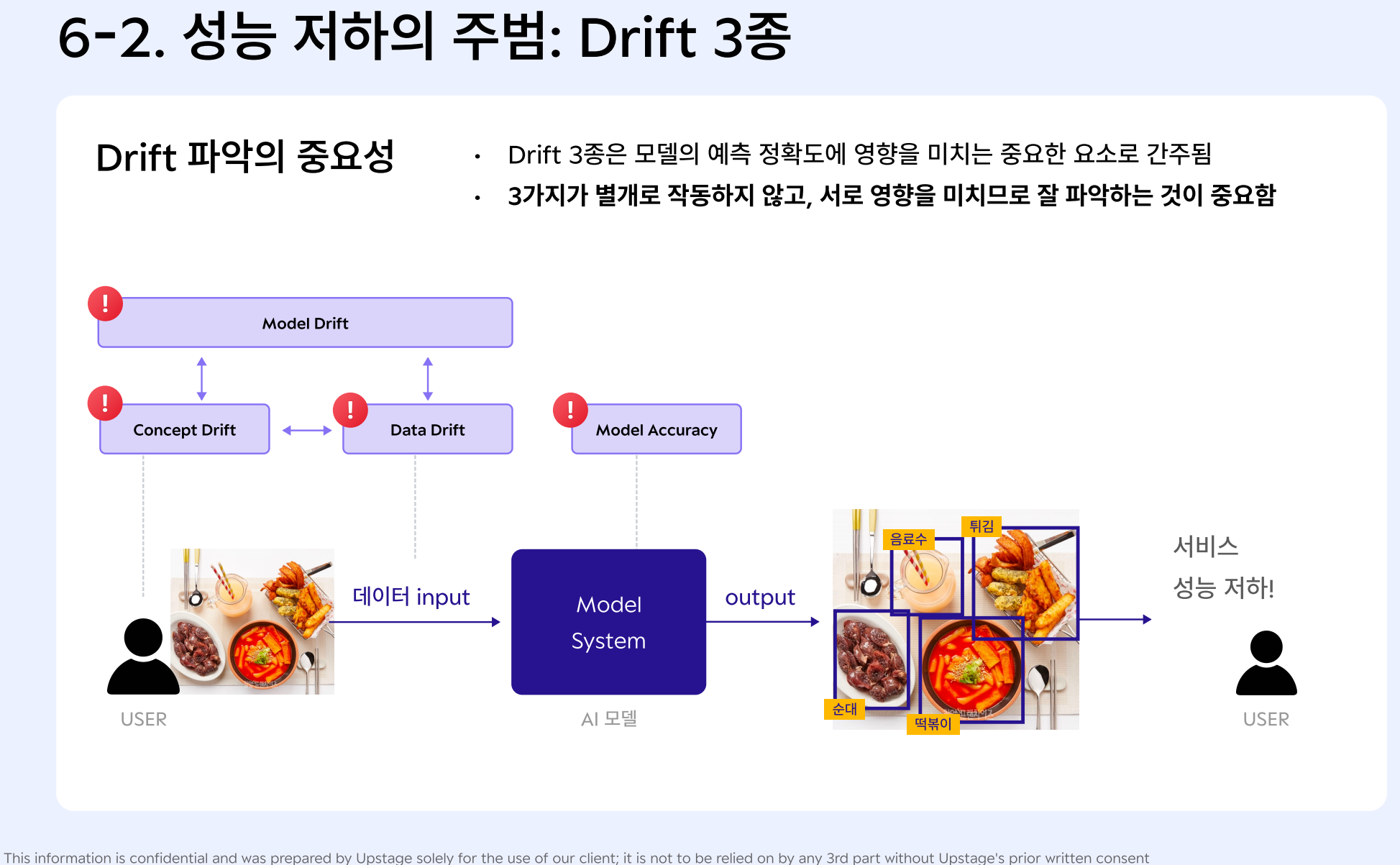
- Model Accuracy 모델 성능
- 모델의 성능 저하 주범 = Drift 3종 [ 본 강의 18:10~ ]
(참고 링크)
1) Data drift : 그때는 맞고 지금은 틀리다
2) Concept drift : 이걸 이렇게 쓴다고?
3) Model drift : 못 본 것은 못한다
(각 드리프트별 체크리스트 참고)
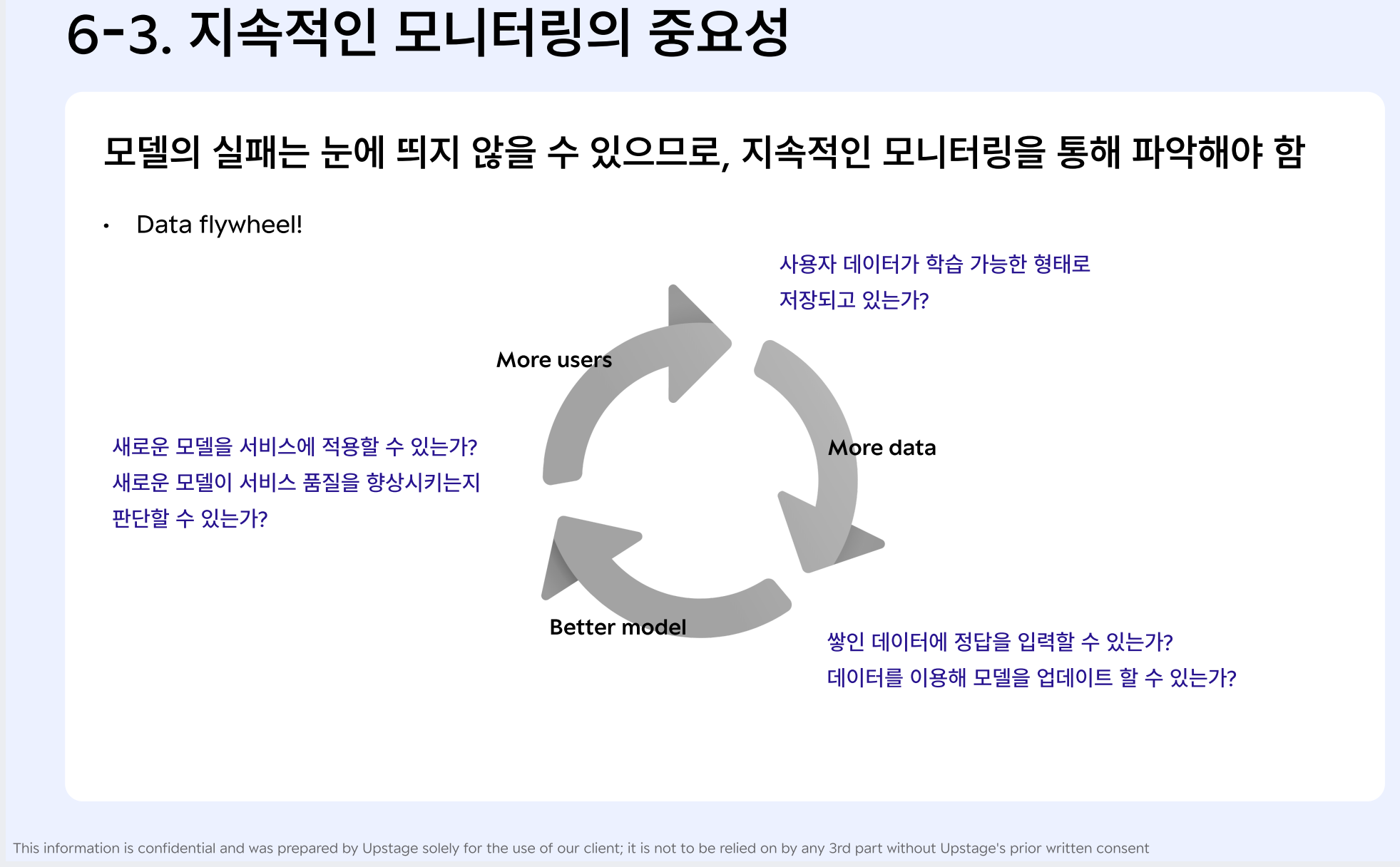
- 모니터링 -> 3대 드리프트를 중심으로 살펴보면 좋다
2-7. 우리 서비스는 계속 발전하고 있어요
1) 지속가능한 AI 서비스 만들기
- 사용자의 피드백 중 "우리의 모델 개선에 도움이 되는 피드백인가?"를 중점적으로 고려하여 판단할 것
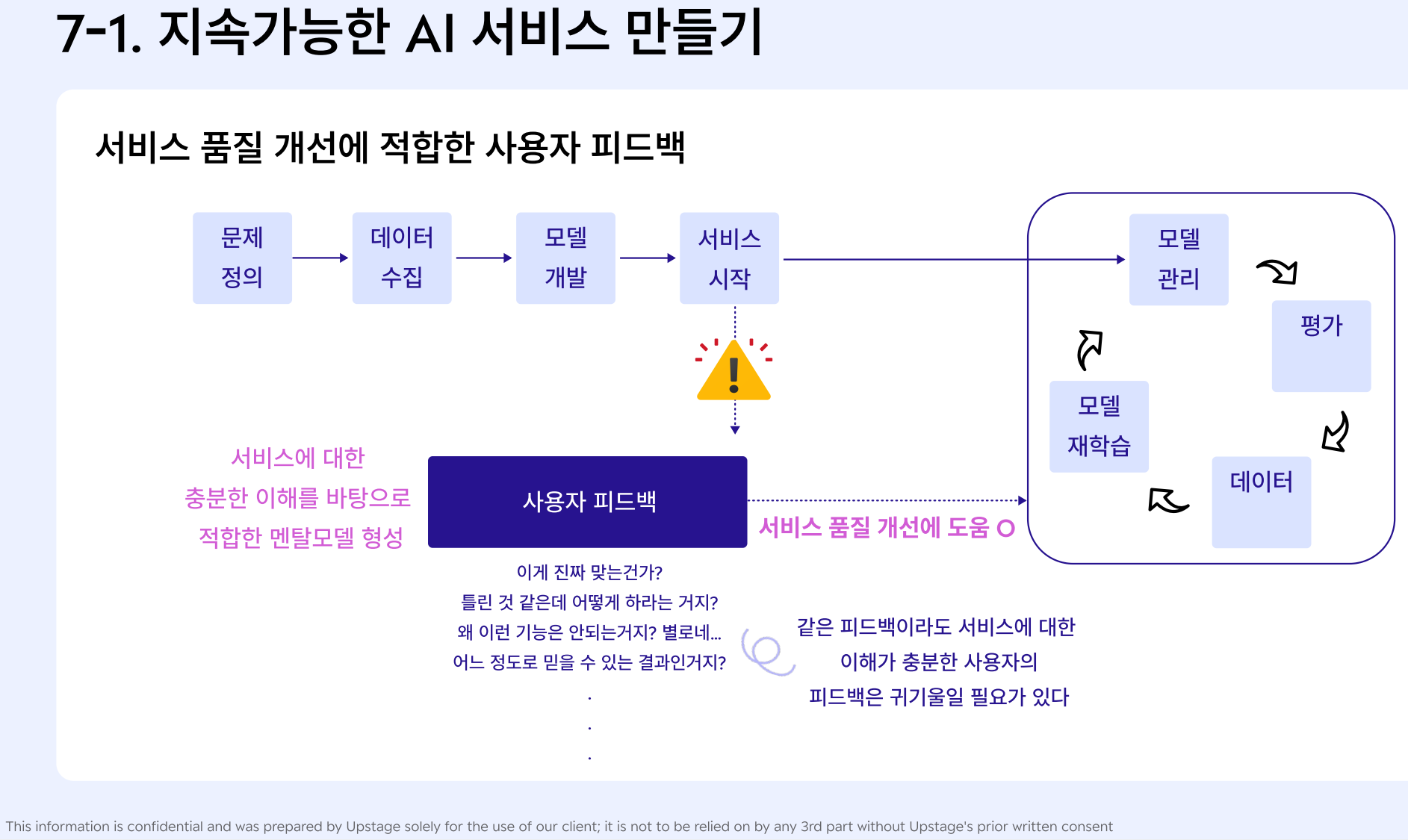
2) 서비스에 적합한 "멘탈 모델" 형성 돕기
- 피드백을 제공한 사용자가 우리 제품에 대한 이해도가 높다 = 사용자에게 우리 서비스에 적합한 멘탈모델이 형성되어 있다
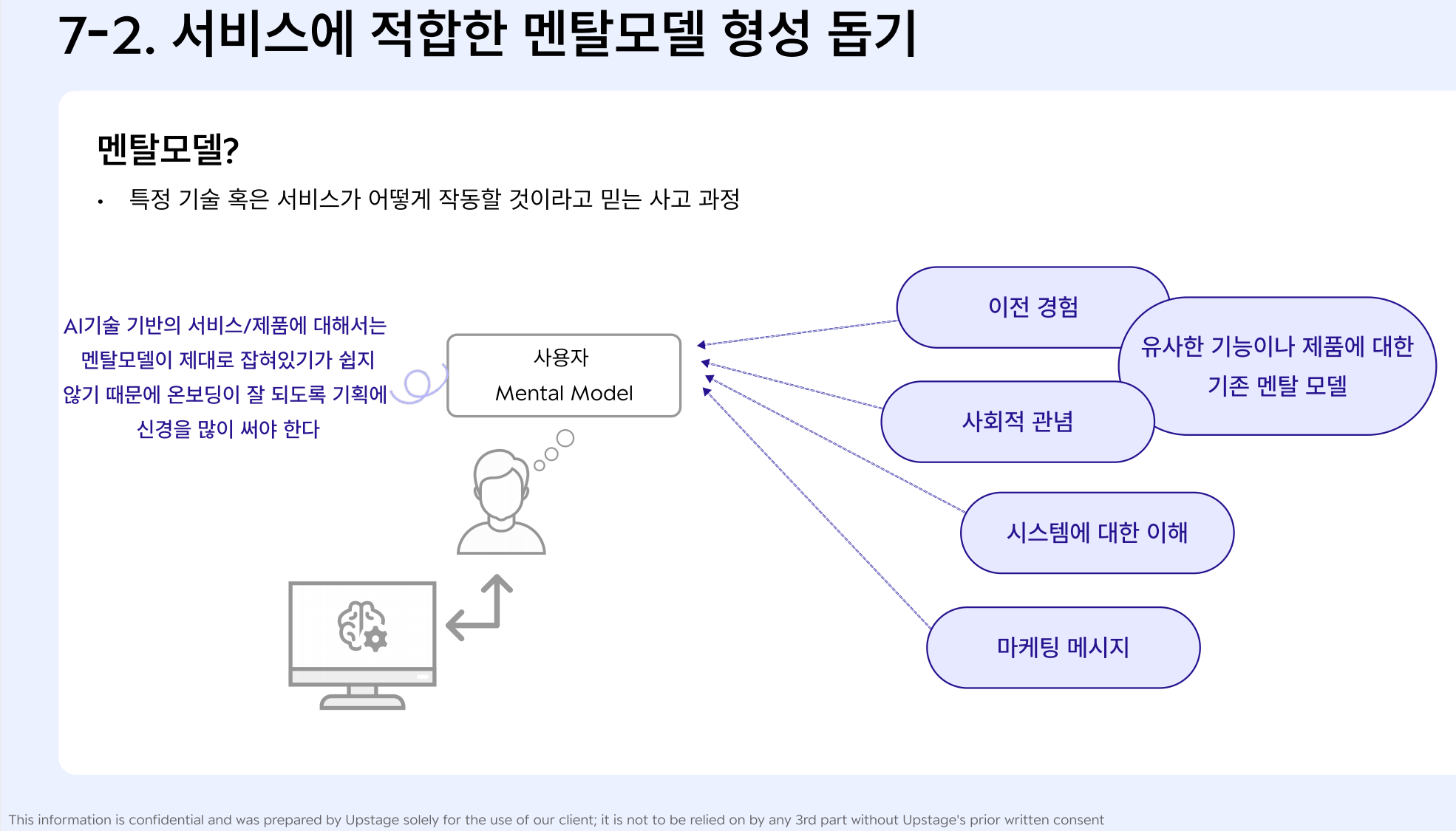
- 멘탈 모델 : 특정 기술 혹은 서비스가 어떻게 작동할 것이라도 믿는 사고 과정
-> 주로 이전의 경험에 기반한 경우가 다수(이전 경험, 유사한 기능 또는 제품에 대한 기존 멘탈 모델, 사회적 관념, 시스템에 대한 이해, 마케팅 메시지 등)멘탈모델 형성이 중요한 이유
- 특히 AI기술은 기존에 없던 새로운 경험이 많으므로, 사용자가 서비스를 어떻게 사용해야 할지 모르거나 or 서비스에서 의도하지 않은 방식으로 사용할 수 있음
(=기존의 멘탈모델이 방해가 될 경우도 많음) - 결국 AI 서비스는 온보딩 설계가 중요하다
(그러나 과도한 기술 설명은 생략한다=사용자 부담 가중) - AI 서비스가 할 수 있는 것과 할 수 없는 것을 사용자에게 명확하게 전달하기
멘탈 모델 체크리스트

