http://cislmu.org 와 학교 수업을 토대로 정리합니다.
1. Introduction
information retrieval
Information retrieval(정보검색, IR)은 문서 등 다양한 형태의 데이터 (비정형 데이터) 저장소로부터 사용자가 원하는 데이터를 찾아내는 것을 의미한다.
정형 데이터를 많이 다뤘던 옛날(90년대)과 달리 최근에는 비정형 데이터를 점차 많이 쓰는 추세이다.
과정
1. 질의 처리: 사용자가 입력한 검색어를 시스템이 이해할 수 있는 형태로 변환 (2에서 나오는 tokenization)
2. 문서 처리: 저장된 데이터를 인덱싱하여 검색이 용이하도록 구조화 (2에서 나오는 inverted index construction)
3. 검색 및 순위 매김: 사용자의 질의와 관련성이 높은 문서를 검색하고 가장 관련성 높은 문서부터 순서대로 나열
비정형 데이터 vs 정형 데이터
- 정형 데이터: 미리 정해진 데이터 모델에 따라 엄격하게 조직된 데이터. 데이터베이스로 SQL 사용
- 비정형 데이터: 텍스트 파일, 이미지 등 다양한 형태의 데이터. 데이터베이스로 NoSQL 사용
🔔 NoSQL이 비정형 데이터를 다루는 용도로 사용된다는데, 그러면 사진같은 것도 저장하는가?
-> 그건 아니다. 사진, 비디오 등의 BLOB 데이터는 S3 Storage 등의 외부 스토리지에 따로 저장하는 게 보통이고, 비정형 데이터라고 해도 소셜 미디어 글 정도의 용량이 그렇게 크지 않은 데이터들을 저장한다.
Boolean retrieval
- IR에서 가장 간단한 모델
- boolean expression을 써서 검색 질의를 수행한다.
- 예시: Caesar and Brutus => Caesar, Brutus 둘 다 포함된 문서를 모두 찾아달라
Does Google use the Boolean model?
구글은 진보된 형태의 Boolean model을 사용한다. (옛날 자료를 보고 공부 중이라 아직도 적용되는 건지는 모르겠다..)
-
단순히 검색 결과를 나열하는 것이 아니라, 관련성 등을 측정해서 그걸 기준으로 랭킹을 매겨 사용자에게 전달한다.
-
사용자가 w1 w2라고 입력했을 때 => w1 AND w2 라고 해석
-
만약 wi를 포함한 문서가 단 하나도 없다면?
그 wi는 아래와 같은 특성이 있을 수 있다. -
- anchor text(링크된 텍스트)
-
- 변형된 검색어 (형태 변경, 철자 수정, 동의어 등) 대체해서 제시
-
- 질의가 길어진 경우
-
- boolean expression은 매우 적은 검색 결과만을 제공할 수 있다.
2. Inverted index
셰익스피어 예시: grep
셰익스피어의 희곡 중 Brutus, Caesar은 들어있지만 Calpurnia는 들어있지 않은 것을 어떻게 찾을 수 있을까? (BRUTUS AND CAESAR AND NOT CALPURNIA)
-> Brutus, Caesar 같이 들어있는 거 찾은 후 Calpurnia 있는 거 제거
그러나 이러한 grep 방식에는 단점이 있다.
- collection이 커짐에 따라 너무 느려진다.
-grep은 라인지향적(line-oriented)지만 IR은 문서지향적(document-oriented)이다. - 예를 들어 NOT CALPURNIA라는 명령어를 수행하려면 한줄만 제거하면 되는 게 아니라 모든 문서에서 제거해야 하므로 비효율적이다.
- apple 옆에 있는 banana 같은 연산은 아예 불가능하다.
Term-document incidence matrix
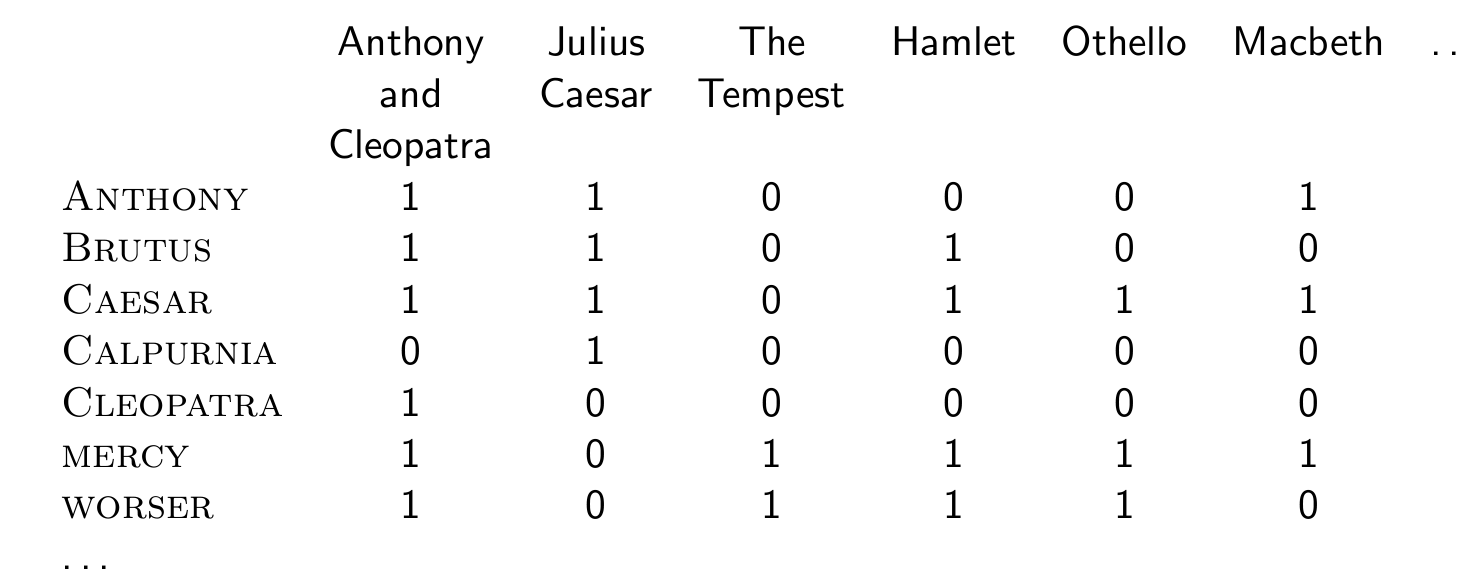
예를 들어 Hamlet에는 ANTHONY가 존재하지 않고, Macbeth에는 ANTHONY가 존재한다. (행은 찾을 단어, 열은 문서이다.)
Incidence vectors
위 행렬상에서 벡터는 0과 1이다.
만약 BRUTUS AND CAESAR AND NOT CALPURNIA를 수행하려면?
- BRUTUS, CAESAR, CALPURNIA 행의 벡터 정보를 가져온 후, CALPURNIA는 NOT이랬으니까 보수를 취한다.
- 세 단어의 벡터에 대해 AND 연산을 수행한다.
0/1 vectors and result of bitwise operations
상세 과정
BRUTUS => 110100
CAESAR => 110111
CALPURNIA => 010000
NOT CALPURNIA => 101111
AND 연산 => 100100 => 답
Answers to query
위 행렬에서 Anthony and Cleopatra, Hamlet이 답을 가지고 있다는 것을 알았으니 사용자에게 보여줄 응답은 아래와 같다.

Bigger collections -> Can't build the incidence matrix
grep에 비해서는 위처럼 행렬 적어서 벡터 계산하는 게 훨씬 편하고 빨라보인다. 그렇지만 여전히 문제가 있다.
-> 만약 10^6개의 문서가 있고, 각 문서가 1000개의 token을 가지고 있다고 하자.
- 총 10^9개의 토큰을 찾아야 한다.
- 공백, 구두점 포함해서 토큰당 6바이트라고 치면 document collection의 용량만 6GB 정도 된다.
- 이 컬렉션에 500000개의 term(용어)가 있다고 하자. (token과 term은 다른 말이다)
- 행렬은 0.5조개의 0과 1을 가지게 된다.
- 그러나 matrix는 10억개 이상의 1을 가지지 못하기 때문에(문서 집합에 있는 총 토큰 수가 10^9개기 때문), 행렬이 매우 sparse해진다.
=> 그럼 어떻게 해결하는가?
-> 1만 기록한다.
챗지피티의 보충 설명
해석:
1. 문서 집합의 크기:
N = 10^6 (1,000,000) 문서가 있으며, 각 문서에는 대략 1,000개의 토큰(단어나 구두점 등)이 있다고 합니다.
이는 전체 문서 집합에서 대략 10^9 (1,000,000,000)개의 토큰이 있다는 것을 의미합니다.
2. 문서 집합의 저장 크기:
각 토큰은 평균 6바이트의 공간을 차지합니다(공백과 구두점 포함).
따라서 문서 컬렉션의 총 크기는 약 6 10^9 바이트, 즉 6GB가 됩니다.
3. 용어의 수:
M = 500,000 (500,000)개의 고유 용어가 있다고 가정합니다. 용어와 토큰의 구분이 있음을 주의해야 합니다. 용어는 컬렉션에 있는 고유한 단어들을 나타내고, 토큰은 실제 문서에 나타나는 각 인스턴스를 말합니다.
4. 행렬의 크기:
M N 즉, 500,000개의 용어와 1,000,000개의 문서를 가진 행렬을 만들면, 500,000 1,000,000 = 5 10^11개의 셀이 필요합니다. 이는 반조(半兆, half a trillion) 개의 0과 1로 이루어진 매트릭스를 생성하게 됩니다.
5. 행렬의 희소성 (Sparsity):
이 행렬은 대부분의 셀이 0으로 채워지게 됩니다. 실제로 '1'인 셀은 10^9개 이하입니다. 왜냐하면 문서 집합에 있는 총 토큰 수가 10^9개이고, 각 토큰은 해당하는 용어에 대해 문서 하나에만 '1'로 표시될 수 있기 때문입니다.
문제점:
이와 같은 희소 행렬은 대부분의 값이 '0'이므로 매우 비효율적인 저장 공간 사용을 초래합니다. 이러한 행렬을 전체적으로 저장하는 것은 메모리 낭비가 크기 때문에, 실제 시스템에서는 다른 방법을 찾아야 합니다.
해결 방안:
희소 행렬의 표현: 행렬에서 '1'로 표시되는 셀만 저장하는 방식을 사용합니다. 이는 '역 인덱싱'이라고 불리며, 각 용어에 대해 해당 용어가 나타나는 문서의 목록만을 기록합니다.
Inverted Index
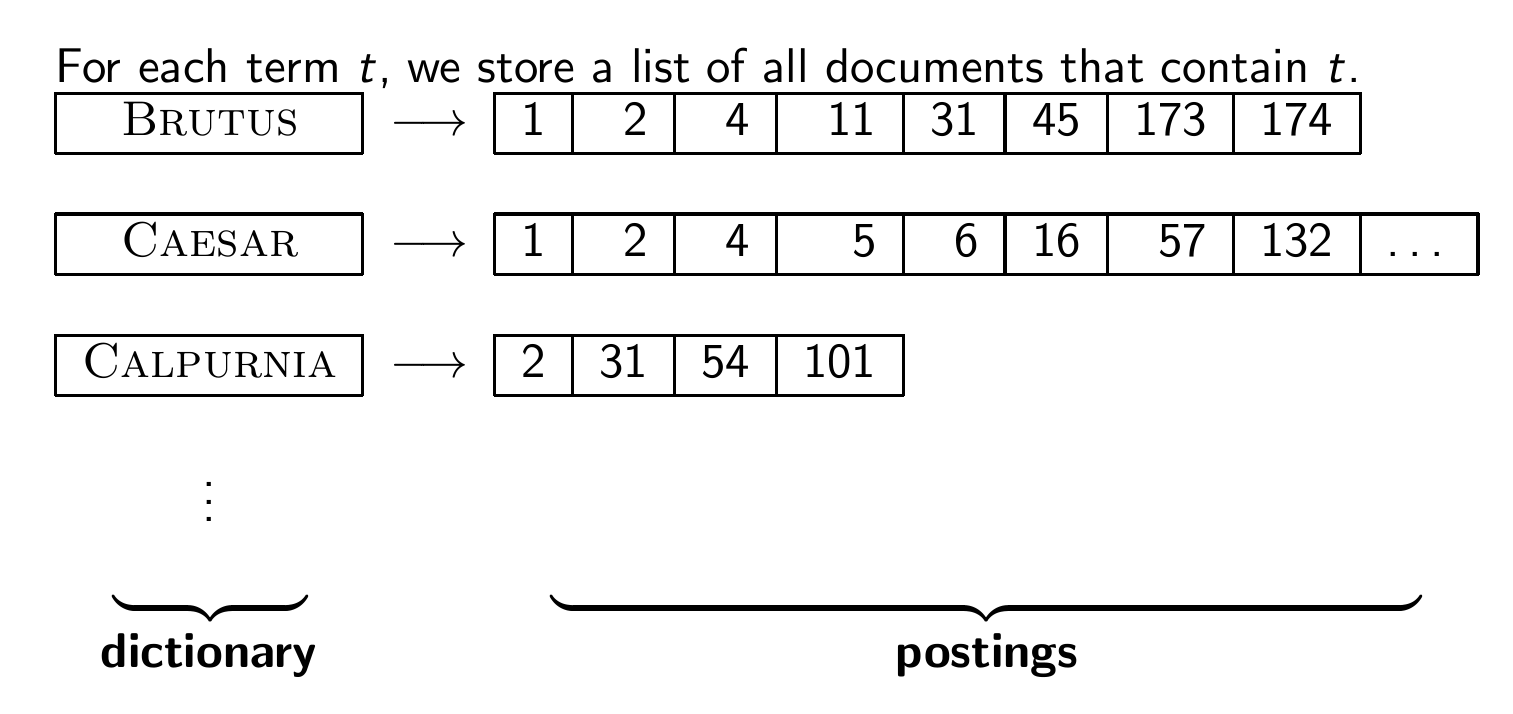
사진 자료처럼 각 용어에 대해서 그 용어를 포함하고 있는 문서들의 리스트를 저장한다.
Inverted index construction
- 색인될 문서를 모은다.
- 문서를 토큰화하고, 각 문서를 토큰들의 리스트로 바꾼다.
- 언어 전처리(linguistic preprocessing)을 수행하여 인덱싱 용어인 정규화된 토큰 목록 생성
- 예를 들어 Hello, this is Amy. 라는 문장을 [Hello, this, is, Amy] 라고 리스트화했다면 [hello, this, is, amy] 이렇게 바꾸는 것이다.
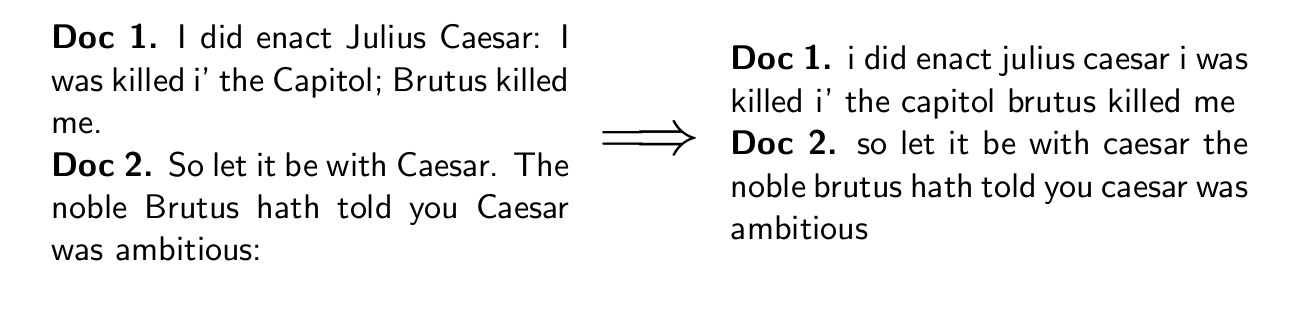
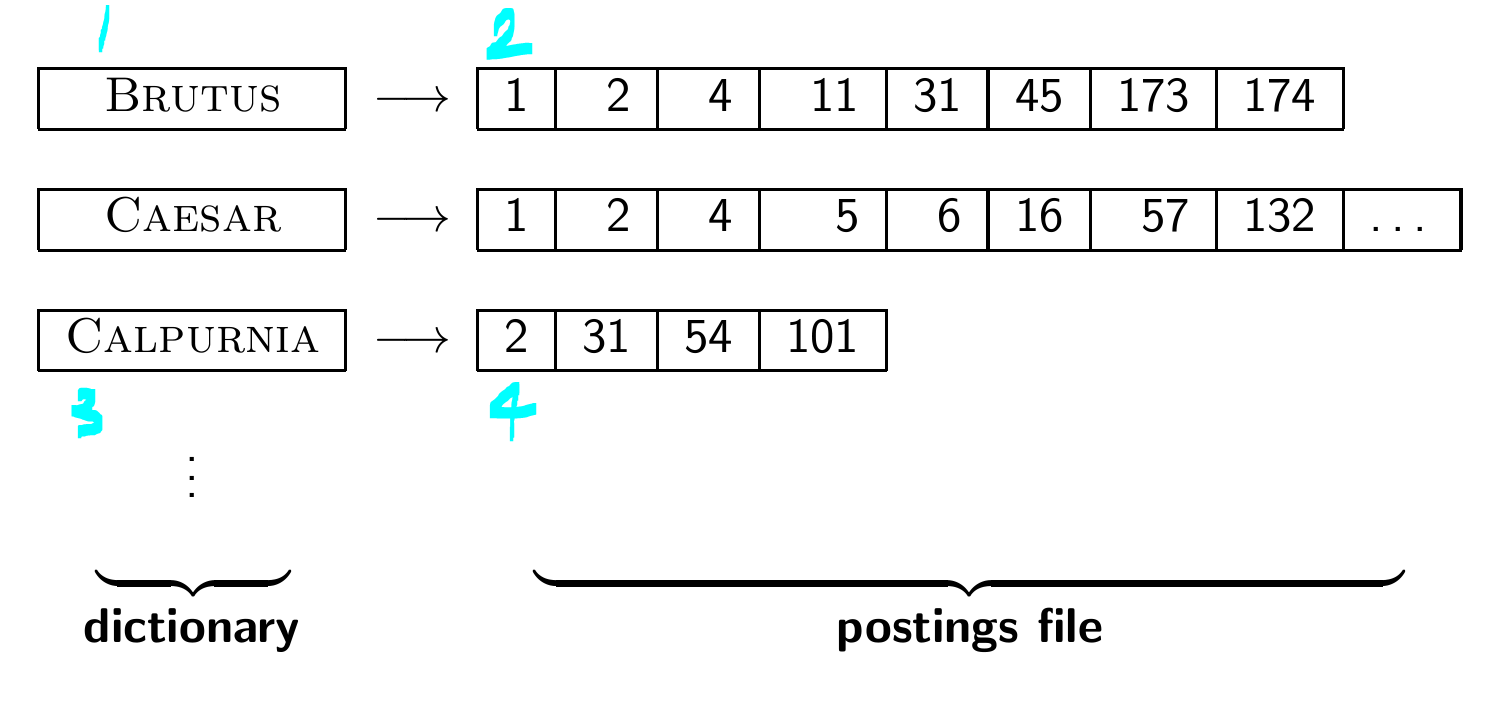
- 사전과 게시물로 구성된 inverted index를 만들어 각 용어가 등장하는 문서를 색인화한다.

-
오름차순 정렬 후 정리한다.

-
postings list를 만들고 document frequency를 결정한다. (사진상에서는 ambitious는 1번 나왔으니까 1, brutus는 2번 나왔으니까 2다.)

-
최종본
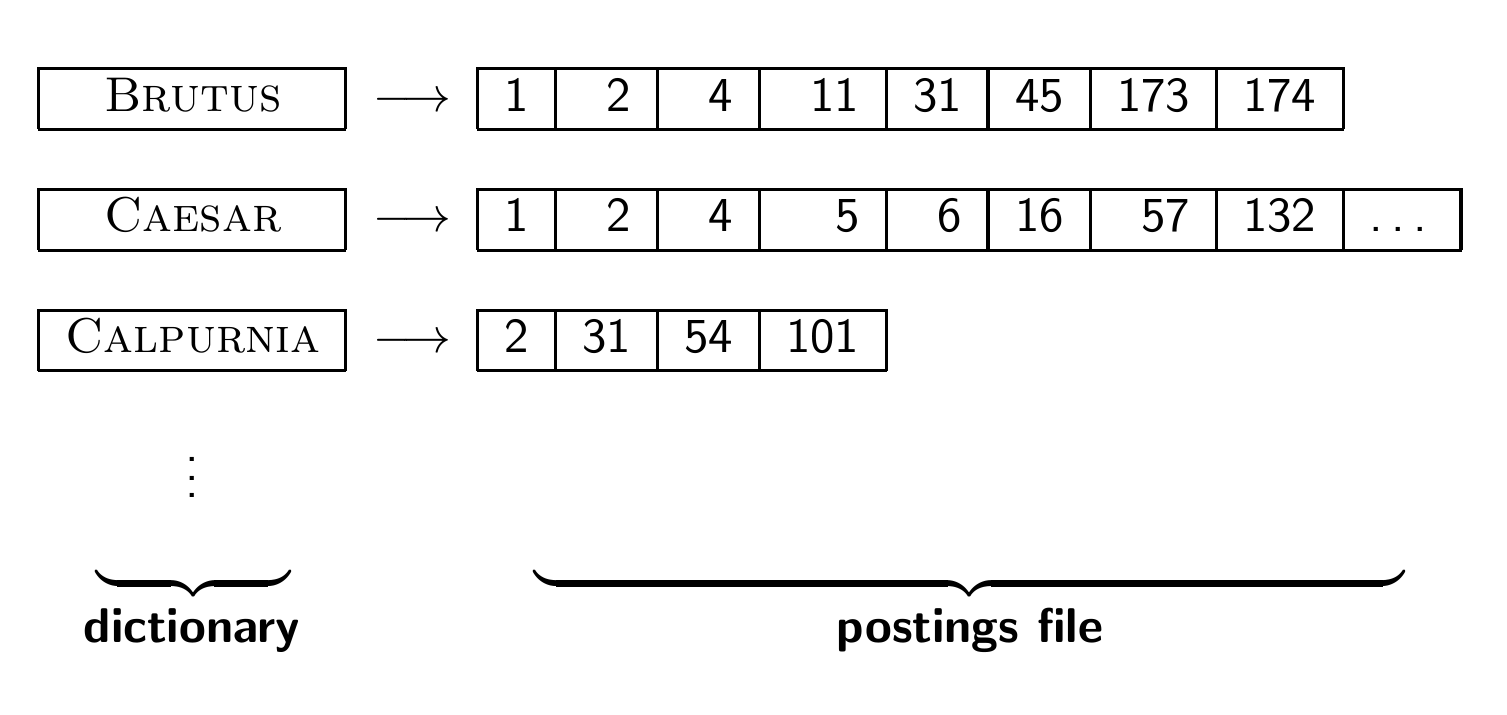
Later in this course
- 거대한 collection에서는 inverted indexes를 어떻게 만드는가?
- dictonary와 index를 위해 얼마나 공간이 필요한가?
- Index compression: 거대한 콜렉션에서 어떻게 효율적으로 인덱스를 저장하고 진행할 수 있는가?
- Ranked retrieval: "best" answer에 어울리는 inverted index의 모습?
3. Processing Boolean queries
2에서 inverted index를 만들었으면 이제 쿼리를 처리할 줄 알아야 한다.
Simple conjunctive query (two terms)
간단한 접속사 쿼리 생각해보기
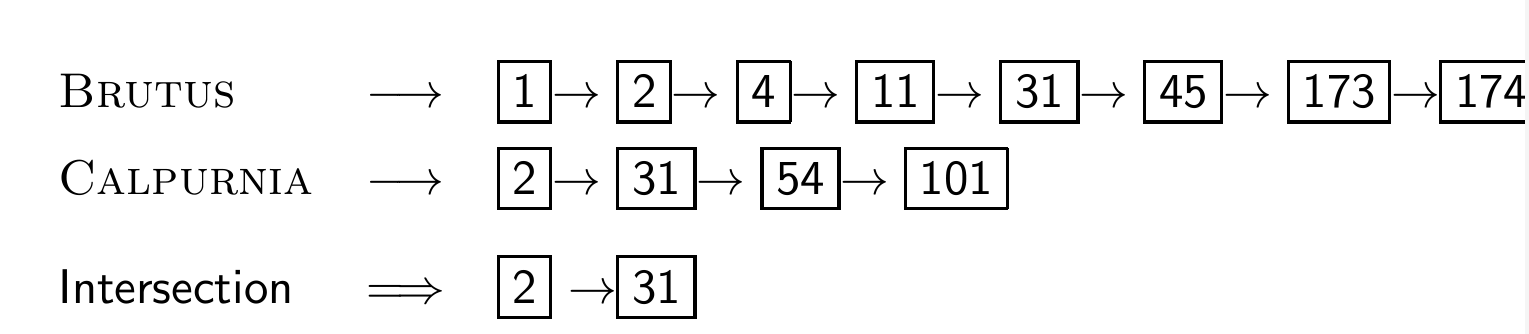
- BRUTUS AND CALPURNIA
- inverted index를 사용하여 일치하는 모든 문서를 찾으려면?
-
dictionary에서 Brutus 찾기
-
postings file에서 해당 게시글 목록 검색
-
dictionary에서 Calpurnia 찾기
-
postings file에서 해당 게시글 목록 검색
-
두 게시글 목록 교차(intersecting)
-
겹치는 부분(intersection)을 사용자에게 반환
※ 쿼리 처리 시간은 postings list의 길이에 linear하게 비례한다.
※ postings list가 정렬된 경우에만 사용 가능하다.
Intersecting two postings lists

Intersect(p1, p2): 두 개의 postings lists p1과 p2를 인터섹션(교차)하기 위한 함수를 시작합니다.
answer ← []: 공통으로 포함된 문서 ID를 저장할 새 리스트 answer를 초기화합니다.
while p1 != nil and p2 != nil: p1과 p2 두 리스트 모두 끝에 도달할 때까지 반복합니다.
do if docID(p1) = docID(p2): 현재 p1과 p2가 가리키는 문서 ID가 같다면,
Add(answer, docID(p1)): 같은 문서 ID를 answer 리스트에 추가합니다.
6-7. p1 ← next(p1): p1 리스트의 다음 문서 ID로 이동합니다.
p2 ← next(p2): p2 리스트의 다음 문서 ID로 이동합니다.
else if docID(p1) < docID(p2): 만약 p1의 문서 ID가 p2의 문서 ID보다 작다면,
p1 ← next(p1): p1만 다음 문서 ID로 이동하고, p2는 현재 위치를 유지합니다.
else: 그렇지 않고 p1의 문서 ID가 p2보다 크다면,
p2 ← next(p2): p2만 다음 문서 ID로 이동하고, p1은 현재 위치를 유지합니다.
return answer: 모든 일치하는 문서 ID를 찾은 후, answer 리스트를 반환합니다.
Query processing: Exercise

문제 풀어보기
Boolean retrieval model
- Boolean retrieval model은 부울 식인 모든 쿼리에 답변할 수 있다.
- 쿼리 용어를 AND OR NOT 셋 중 하나로 join한다.
- 각 문서를 term의 집합으로 본다.
- 문서가 조건과 일치하는지 보는데 아주 정확하다.
- 많은 전문 검색자들(변호사 등)은 Boolean queries를 선호한다. -> 정확히 무엇을 얻을 수 있는지 알기 때문
- spotlight, email, intranet 등의 검색 시스템도 Boolean을 사용한다.
Commercially successful Boolean retrieval: Westlaw
- 1975년에 시작된 서비스
- 유료 구독자 수 기준 최대 규모의 상업용 법률 검색 서비스
- 50만명 이상의 구독자가 수십 테라바이트의 텍스트 데이터로 매일 수백만 건의 검색 수행함
- 1992년에 ranked retrieval이 도입됐지만, 2005년 기준으로 Boolean search가 여전히 많이 사용된다.
예시1
- 필요한 정보: 경쟁 회사에서 근무했던 직원의 영업 비밀 공개를 방지하는 법적 이론
- 쿼리: “trade secret” /s disclos! /s prevent /s employe!
예시2
- 필요한 정보: 장애인이 직장에 접근하기 위한 요건
- 쿼리: disab! /p access! /s work-site work-place (employment /3 place)
예시3
- 필요한 정보: 취객에 대한 호스트의 책임에 대한 사례
- 쿼리: host! /p (responsib! liab!) /p (intoxicat! drunk!) /p guest
위 예시 부가 설명
- Proximity operators: /3 = 3단어 이내 /s = 문장 내 /p = 단락 내
- 공백은 결합(conjunction, AND)이 아니라 분리(disjunction, OR)
- 구글이 나오기 전에는 대부분 검색 엔진에서 공백을 OR로 처리했으나, 구글이 AND로 해석하기 시작하면서 다른 검색 엔진들도 유사한 방식을 채택하기 시작했다. - 점진적으로 길고 정확한 쿼리 개발
- 일반적인 웹 검색과 달리, 사용자는 처음에는 간단한 쿼리로 시작해서 필요에 따라 점차 쿼리를 수정 및 확장해나간다. -> 보다 정확한 검색 결과를 얻을 수 있다. - 전문 검색자가 Boolean search를 선호하는 이유: 정확성 투명성 제어력
- Boolean 쿼리가 가장 적합한 검색 방식: information need, searcher, document collection 등에 따라 다름
4. Query optimization
Query optimization
n 개의 term을 AND로 이은 쿼리가 있다고 하자 (n>2).
각 term에 대해 그것들의 postings list를 가지고 오고, 그것들을 AND 한다.
예: Brutus AND Calpurnia AND Caesar
질문: 이 쿼리를 processing하는 가장 좋은 순서는 무엇일까?
가장 간단한 해결: 빈도가 증가하는 순서대로 처리한다. 아래 사진같으면 CAESAR->CALPURNIA->BRUTUS 순서이다. 가장 짧은 것부터 시작해서 필요없는 것들을 컷하는 식이다.
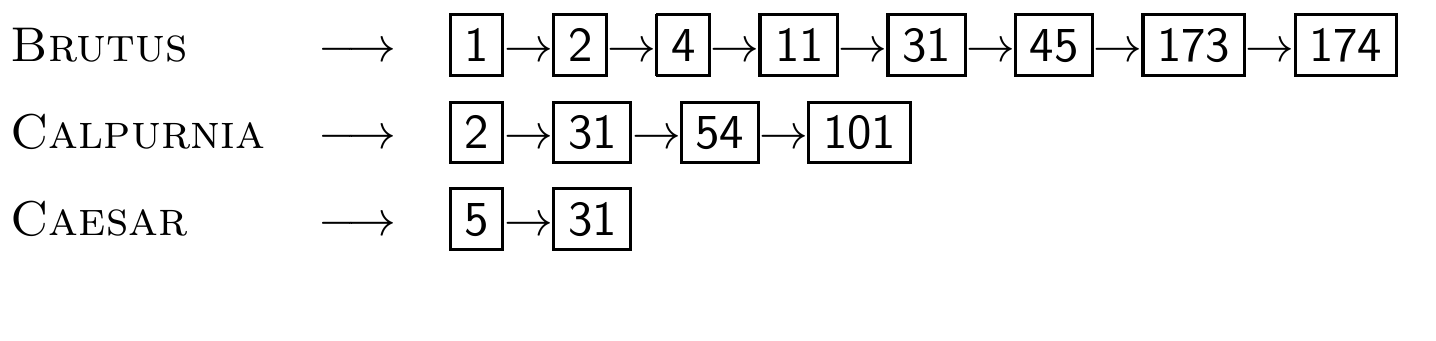
Optimized intersection algorithm for conjunctive queries

terms ←SortByIncreasingFrequency(t1,...,tn): 검색어들을 그 빈도수가 적은 순서대로 정렬합니다. 빈도가 낮은 검색어부터 처리하면 초기 단계에서 결과 집합의 크기를 줄일 수 있어 전체적인 처리 시간을 최적화할 수 있습니다.
result ← postings(first(terms)): 정렬된 리스트에서 가장 빈도수가 낮은 검색어의 postings list를 가져와서 결과 변수에 저장합니다. Postings list는 해당 검색어가 나타나는 모든 문서의 ID를 포함하고 있습니다.
terms ←rest(terms): 이미 처리한 첫 번째 검색어를 제외하고 나머지 검색어들의 리스트를 업데이트합니다.
while terms = nil and result = nil: 남은 검색어 리스트가 비어있지 않고, 현재 결과가 비어있지 않은 동안 반복합니다. 이 조건은 남은 모든 검색어를 처리하고 결과가 존재할 때까지 계속합니다.
do result ← Intersect(result, postings(first(terms))): 현재 결과와 다음 검색어의 postings list와의 교집합을 찾습니다. 이 과정은 결과 집합을 점점 더 좁혀나가며, 최종적으로 모든 검색어를 포함하는 문서만 남기게 됩니다.
terms ← rest(terms): 처리한 검색어를 제외하고 검색어 리스트를 다시 업데이트합니다.
return result: 최종 결과로 남은 문서 ID의 집합을 반환합니다. 이 집합은 쿼리에 포함된 모든 검색어를 포함하는 문서들의 ID입니다.
More general optimization
예시 쿼리: (MADDING OR CROWD) AND (IGNOBLE OR STRIFE)
1. 모든 term의 빈도 수집
- 각 OR 조건의 크기 추정 (madding or crowd, ignoble or strife의 크기를, 해당 조건을 구성하는 단어들의 빈도 합으로 추정 -- 모든 가능성을 고려하는 보수적 추정)
- OR 크기의 증가 순서로 처리 (더 작은 결과 집합을 생성하는 조건부터 처리하면 처리 속도 향상)
5. Course overview
IIR 02: The term vocabulary and postings lists
- Phrase queries: Standford University
- Proximity queries: Gates near Microsoft
- Phrase 쿼리와 Proximity 쿼리에 대한 position 정보를 캡처하는 인덱스가 필요하다.
IIR 03: Dictionaries and tolerant retrieval
IIR 04: Index construction
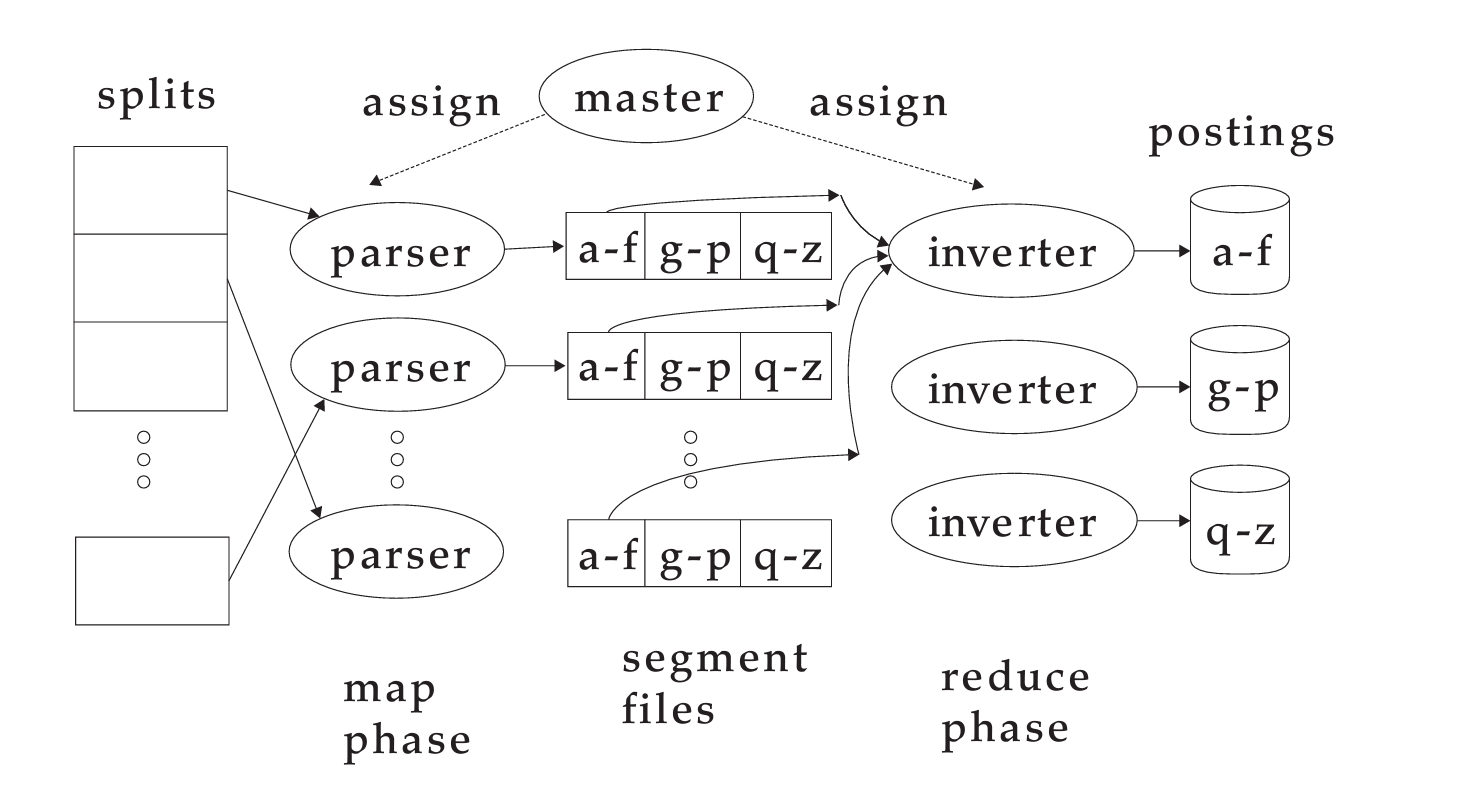
IIR 05: Index compression
IIR 06: Scoring, term weighting and the vector space model
IIR 07: Scoring in a complete search system
IIR 08: Evaluation and dynamic summaries
IIR 09: Relevance feedback & query expansion
IIR 12: Language models
IIR 13: Text classification & Naive Bayes
IIR 14: Vector classification
IIR 15: Support vector machines
IIR 16: Flat clustering
IIR 17: Hierarchical clustering
IIR 18: Latent Semantic Indexing
IIR 19: The web and its challenges
IIR 21: Link analysis / PageRank
※ 추가 공부
- 자료 보고 inverted index 실제로 해보기
- inverted index 가지고 processing query 문제 풀기
- 알고리즘들 이해 및 암기 (암기는 시험 때문에)
여기서부턴 시간이 나면 해보고 싶은 것들이다.,
- 리눅스로 grep 써보기
- 파이썬으로 inverted index + 쿼리 시스템 만들어보기
- 파이썬으로 boolean retrieval model 만들어보기
- 파이썬으로 알고리즘 구현해보기
